This project is a FastAPI application designed for document management using Chroma for vector storage and retrieval. It provides several endpoints to load and store documents, peek at stored documents, perform searches, and handle queries with and without retrieval, leveraging OpenAI's API for enhanced querying capabilities.
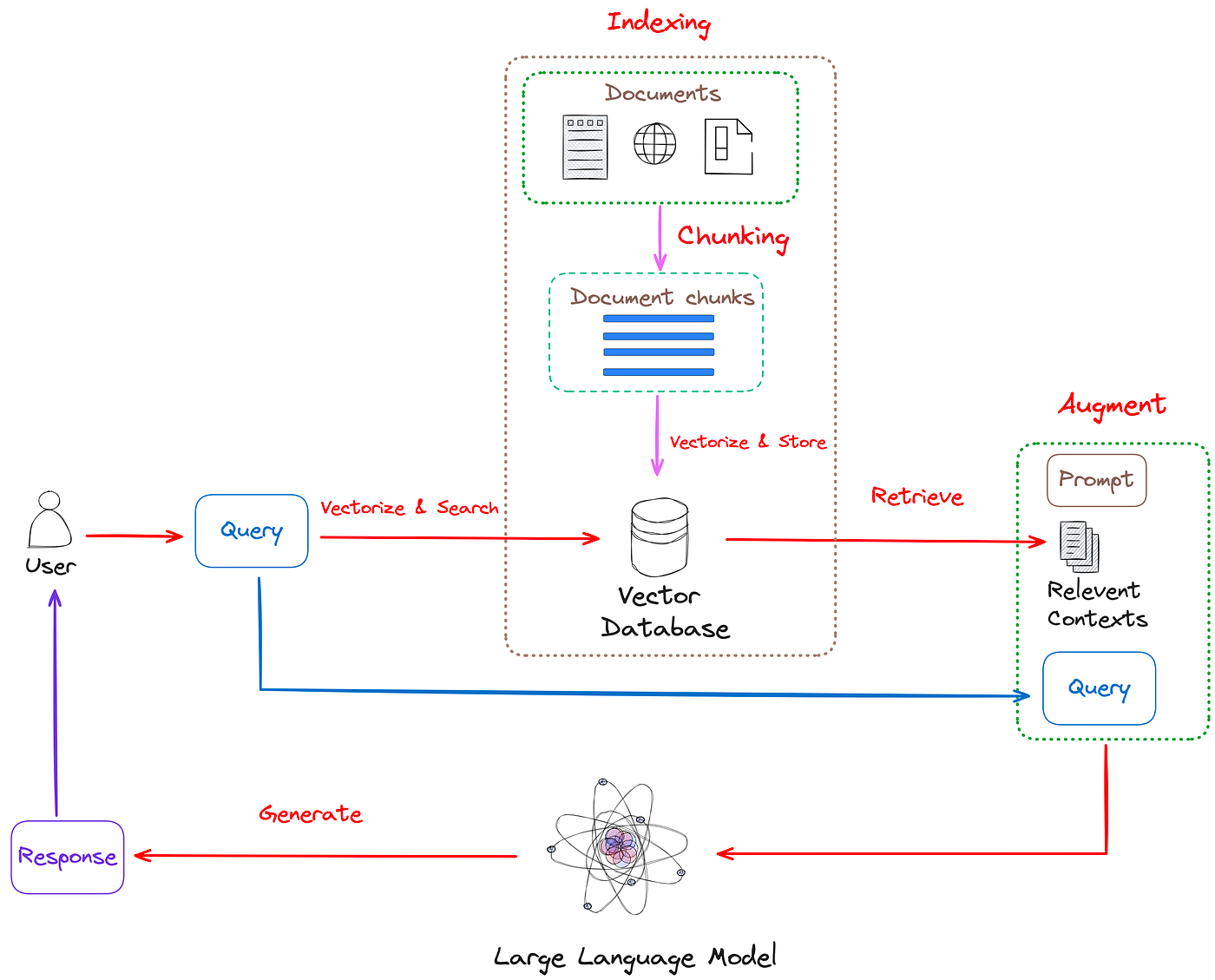
The application combines large language models (LLMs) with vector storage for efficient document retrieval, demonstrating the benefits of using Retrieval-Augmented Generation (RAG) for document management.
- Load and store documents in Chroma’s vector storage.
- Verify document completeness using a peek functionality.
- Search for documents based on query relevance.
- Perform RAG queries using OpenAI's GPT-3.5-turbo.
- Compare query results with and without retrieval to assess accuracy.
- Configurable environment variables for API keys and database settings.
- FastAPI: A modern Python web framework for building APIs.
- Chroma: A vector database used for storing and querying embeddings.
- OpenAI API: A powerful API for interacting with OpenAI models.
- Hugging Face Transformers: A library for state-of-the-art NLP models.
- SQLite: A lightweight database for storing vector data.
- Langchain: Build context-aware, reasoning applications with LangChain's flexible framework that leverages your company's data and APIs.
app/: Contains the FastAPI application code.api/: Defines API routes for handling requests.services/: Business logic for document handling, Chroma interactions, and LLM queries.utils/: Utility functions, including configuration settings.main.py: Entry point for the FastAPI application.
chroma_db/: Directory for Chroma's vector storage..env: Environment variables for configuring the application.dev.sh: Shell script for setting up the development environment and running the application.requirements.txt: Lists the Python dependencies for the project.README.md: Project documentation.
git clone https://github.com/AnuwatThisuka/Building-RAG-with-Langchain-and-Chroma
cd Building-RAG-with-Langchain-and-ChromaMake the dev.sh script executable and run it to set up the environment:
chmod +x dev.sh
./dev.shCreate a .env file in the root directory with the following content, replacing placeholders:
APP_ENV=development
DEBUG=true
DATABASE_URL=sqlite:///./chroma_db/chroma.db
OPENAI_API_KEY=your_openai_api_key
OTHER_API_KEY=other_api_key_if_neededAfter setting up, start the FastAPI server:
uvicorn app.main:app --reloadThe application will be available at http://127.0.0.1:8000.
- Endpoint:
/load-and-store - Method:
POST - Request Body:
LoadAndStoreRequest - Description: Loads data from a URL, splits text into chunks (up to 1024 tokens), embeds using OpenAI’s Ada v2 model, and stores the vectors in the Chroma vector database.
- Endpoint:
/peek-document - Method:
POST - Request Body:
PeekDocumentRequest - Description: Retrieves the 10 most recent documents to verify completeness of stored data.
- Endpoint:
/search - Method:
POST - Request Body:
SearchRequest - Description: Searches for the most relevant document in Chroma. The query is converted into a vector and matched with stored vectors, returning the closest result.
- Endpoint:
/query-with-retrieval - Method:
POST - Request Body:
QueryWithRetrievalRequest - Description: Performs RAG queries by combining OpenAI’s GPT-3.5-turbo and Chroma's vector database.
- Endpoint:
/query-without-retrieval - Method:
POST - Request Body:
QueryWithoutRetrievalRequest - Description: Tests querying without using retrieval for comparison of accuracy with RAG.
- Ensure that
chroma_db/exists for storing vector data. - Double-check the
.envfile for correct API keys and database settings.
Contributions are welcome! Please ensure your code is well-tested and follows coding guidelines.
This project is licensed under the MIT License. See the LICENSE file for details.