参考资料:JVM常见线上问题:CPU飙升100%、GC频繁、内存溢出等常见问题排查思路
实战案例:记一次dump文件分析历程 | HeapDump性能社区
JavaGuide 经验贴汇总:JVM线上问题排查和性能调优案例 | JavaGuide
1)通过 jmap 工具生成可以生成任意Java进程的dump文件
# 先找到PID
ps -ef | grep java
# jmap 转存快照
jmap -dump:format=b,file=/opt/dump/test.dump {PID}2)通过配置JVM启动参数
# 当程序出现OutofMemory时,将会在相应的目录下生成一份dump文件,如果不指定选项HeapDumpPath则在当前目录下生成dump文件
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/dumps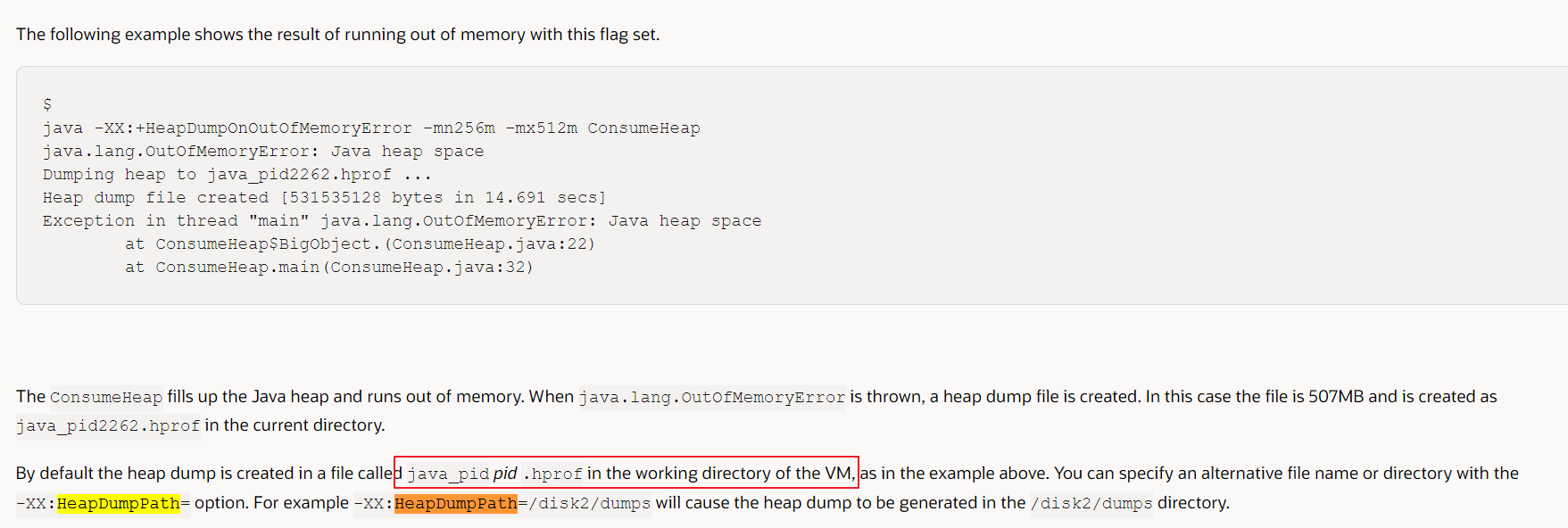
分析dump文件的两种工具:MAT(Memory Analyzer)、jvisualvm
一些问题及经验总结:
1. MAT需要JDK11才能运行
解决办法是,打开MAT的安装目录,有一个配置文件MemoryAnalyzer.ini。打开这个文件,在文件中指定JDK版本即可。新增两行配置:
-vm D:/jdkPath/bin/javaw.exe2.在使用jvisualvm分析大的dump文件时,堆查器使用的内存不足
修改JAVA_HOME/lib/visualvm/etc/visualvm.conf文件中 visualvm_default_options="-J-client -J-Xms24 -J-Xmx256m",然后重启jvisualVM即可
3. MAT修改内存空间
分析堆转储文件需要消耗很多的堆空间,为了保证分析的效率和性能,在有条件的情况下,建议分配给 MAT 尽可能多的内存资源。两种方式分配内存资源给 MAT: 1)修改启动参数 MemoryAnalyzer.exe -vmargs -Xmx4g 2)编辑文件 MemoryAnalyzer.ini 添加 -vmargs – Xmx4g
参考的一些文章:
- jvisualvm分析:https://zhuanlan.zhihu.com/p/163774290
- MAT定位大对象:https://www.cnblogs.com/rb2010/p/14741674.html
- MAT详细:https://blog.csdn.net/Jin_Kwok/article/details/80326088
- https://www.jianshu.com/p/82b25cf8cfde
cpu突然大幅上涨,常见的有这几种原因:1、业务访问量激增,体现在QPS增多以及接口耗时上升,现有机器性能无法支撑 2、代码出现bug,导致死锁、空消耗,常见的有while(true){}、正则表达式解析陷入死循环 3、内存溢出导致GC频繁,消耗cpu
其中原因1无法避免,线上做好告警以及自动扩容通常可以应对流量的突增,而原因2和原因3通常由于代码bug导致,需要人工介入及时解决。
通常使用top命令找到对应的java线程,使用jstack找出对应线程的运行情况,从而判断问题原因。具体步骤:
- 执行top命令,找到cpu最高的进程的id
- 执行top -H -p pid显示这个pid进程的所有线程消耗情况,找到cpu消耗最大的线程id,tid
- jstack pid获取该进程的线程dump文件,由于dump文件里线程的打印都是使用十六进制,所有要将上面的tid转成十六进制,并找到该线程的相关日志。
jstack dump文件结构如下
一般情况,可以看到dump日志里有多种线程状态,如RUNNABLE、WAITING、TIMEDWAITING、BLOCKED,后者通常不是引发CPU上升的主要原因,处于WAITIN、TIMEDWAITING和BLOCKED状态的线程都不会消耗CPU,但是如果有线程频繁地挂起和唤醒是需要消耗CPU。
以下介绍两种常见的情况
通常需要根据实际内容判断对应的线程产生的代码是否有bug。如下是使用jstack显示的占用cpu最高线程的日志。
"VM Thread" prio=10 tid=0x0000000049516000 nid=0x5870 runnable
该线程处于runnable 状态
- prio=10为线程优先级:默认为5,数字越大优先级越高;
- tid=0x0000000049516000 JVM线程的id:JVM内部线程的唯一标识,其实就是 java.lang.Thread.getId()的值
- nid=0x5870 系统线程id:对应的系统线程id(Native Thread ID),十六进制的数字
该线程前缀是VM Thread,是JVM内部线程,会进行一些JVM内部操作如垃圾回收,所以这里很可能是因为进行频繁的垃圾回收而导致占用大量cpu资源,我们在后文详细分析。
除此之外,一些空循环也会导致cpu 100%,虽然实际代码我们很少会故意写出类似while(true){}这样的空循环结构,但是在实现一些自旋逻辑时,很容易产生无限等待。例如我们有业务使用了Disruptor框架,当我们选择YieldingWaitStrategy等待策略时,框架内部使用自旋 + yield的方式来消费信息以提高消费性能,配置不当时很容易出现100%忙等待,后续会专门写一篇文章介绍Disruptor框架的使用场景和坑。
死锁的解释,我这里摘抄百科里的一段话
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去
一般情况下死锁是不会直接导致CPU飙升的,通常是由于死锁导致其它代码逻辑占用了大量CPU,所以死锁也需要密切关注,如下是使用jstack检查到死锁后的例子,通常会直接显示Found one Java-level deadlock这一字样
Found one Java-level deadlock:
"pool-1-thread-2":
waiting to lock monitor 0x00007fb42c020cc8 (object 0x00000007956f8a10, a java.lang.Class),
which is held by "pool-1-thread-1"
"pool-1-thread-1":
waiting to lock monitor 0x00007fb42c0234a8 (object 0x00000007956f4cb8, a java.lang.Class),
which is held by "pool-1-thread-2"通过上述的dump日志通常可以定位到具体的代码,从而排查到死锁的产生原因,或者还可以使用JDK自带的jvisualvm工具,在可视化工具里更清晰的排查死锁
很多工具都有死锁检测的功能,通过都是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。
上面的排查CPU负载最高的流程还是有点繁琐,有人写了一键脚本可以直接运行脚本揪出有问题的线程,参考快速排查Java的CPU性能问题,也可以使用arthas等排查工具
上述也提到,GC频繁通常会导致CPU飙升,可以根据以下步骤快速排查问题
- 使用上述的jstack工具查看是否有gc线程频繁消耗cpu
- 使用jstat工具查看各部分的内存占用
- 使用jmap工具查看内存结构(jmap -histo pid)或者直接dump日志到MAT分析(jmap -dump:format=b,file=文件名 pid,也可以使用jvisualvm,但是jvisualvm信息不够详细)
- 根据具体情况分析是JVM内存配置问题还是代码bug
分析出问题后,通常这样处理
- 给予足够的JVM内存,如果给的内存太少,而代码中又会产生大量内存碎片,自然而然会频繁gc,e.g. -Xmx2G
- 假如内存不能盲目增加,通过MAT或者jvisualvm分析后,优化代码
- 使用性能更好的垃圾回收器,如-XX:+UseConcMarkSweepGC -XX:+UseParNewGC更换年轻代和老年代的垃圾回收器使并行收集
- 打印gc日志详细分析 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log
jstat的使用方法可以参考文末的链接,通常我们使用jstat -gcutil pid查看jvm内存状况如上图,可以看到年轻代和老年代内存都已经满了,内存已经不够用,出现频繁gc,接下来我们需要分析内存存储了什么,确定是jvm参数配置不当导致内存不足还是出现了内存泄漏。首先使用jmap -heap显示Java堆详细信息,该命令可以快速打印内存结构
num #instances #bytes class name
----------------------------------------------
1: 6941882 2374727080 [C
2: 38795 464004792 [Ljava.lang.Object;
3: 6929855 166316520 java.lang.String
4: 2191026 70112832 java.util.HashMap$Node
5: 2107729 67447328 com.tencent.ack.Identifier
6: 1380442 44174144 java.util.concurrent.ConcurrentHashMap$Node
7: 24301 18917152 [Ljava.util.HashMap$Node;可以发现这个信息不够详细,虽然String等对象占用很多,但有可能是其它对象产生的,此时最好是使用jmap -dump:format=b,file=文件名 pid把整个内存结构dump下来,使用Memory Analyzer (MAT)这个工具进行分析
上图可以看到是AckKnowledger这个对象大量产生导致内存溢出,我们在代码里顺着逻辑,就能找到溢出原因从而解决。一般可以重点看以下变量是否没有及时被回收
变量属于类变量(静态变量),那么永远不会被回收,原因是方法区中的类静态属性引用的对象是GC Roots,不会被回收。变量属于实例(成员变量,包括final),则实例被回收才会被顺便回收(和实例一起存在堆中,栈帧中的局部变量区(GC Root)中不再引用,就回收) 变量属于实例的方法(局部变量),那么他是在栈中临时的(栈帧中的局部变量区(GC Root),GC的区域在堆和方法区,而不在栈),随着方法结束了,栈自动释放了,无需回收。MAT的使用教程网上很多,我在文末链接里附带了一个写的比较详细与清楚的,就不详细展开了。
文章简单总结了常见的排查思路,如果对某个点想更深入的了解,欢迎评论留言,我会继续补充或者专门开一篇文章细述
附一张系统问题排查流程图