Home
Welcome to the FfDL wiki!
Create and Deploy a Deep Learning platform on Kubernetes
Deploy a Deep Learning Platform on Kubernetes, offering TensorFlow, Caffe, PyTorch etc. as a Service.
Cognitive
This Code provides a fabric for a scalable Deep Learning on Kubernetes, by giving users to to leverage deep learning libraries such as Caffe, Torch and TensorFlow, in the cloud in a scalable and resilient manner with minimal effort. The platform uses a distribution and orchestration layer that facilitates learning from a large amount of data in a reasonable amount of time across compute nodes. A resource provisioning layer enables flexible job management on heterogeneous resources, such as graphics processing units (GPUs) and central processing units (CPUs), in an infrastructure as a service (IaaS) cloud.
By Animesh Singh, Scott Boag, Tommy Li, Waldemar Hummer
N/A
Training deep neural networks, known as deep learning, is currently highly complex and computationally intensive. A typical user of deep learning is unnecessarily exposed to the details of the underlying hardware and software infrastructure, including configuring expensive GPU machines, installing deep learning libraries, and managing the jobs during execution to handle failures and recovery. Despite the ease of obtaining hardware from infrastructure as a service (IaaS) clouds and paying by the hour, the user still needs to manage those machines, install required libraries, and ensure resiliency of the deep learning training jobs.
This is where the opportunity of deep learning as a service lies. In this code pattern we are going to show how to deploy Deep Learning fabric on Kubernetes. By using Cloud native architectural artifacts like Kubernetes, Microservices, Helm charts, Object storage etc. we show to deploy and use a deep learning fabric which spans across multiple deep learnign engines like TensorFlow, Caffe, PyTorch etc. like It combines the flexibility, ease-of-use, and economics of a cloud service with the power of deep learning: It is easy to use using the REST APIs, one can train with different amounts of resources per user requirements or budget, it is resilient (handles failures), and it frees users so that they can spend time on deep learning and its applications.
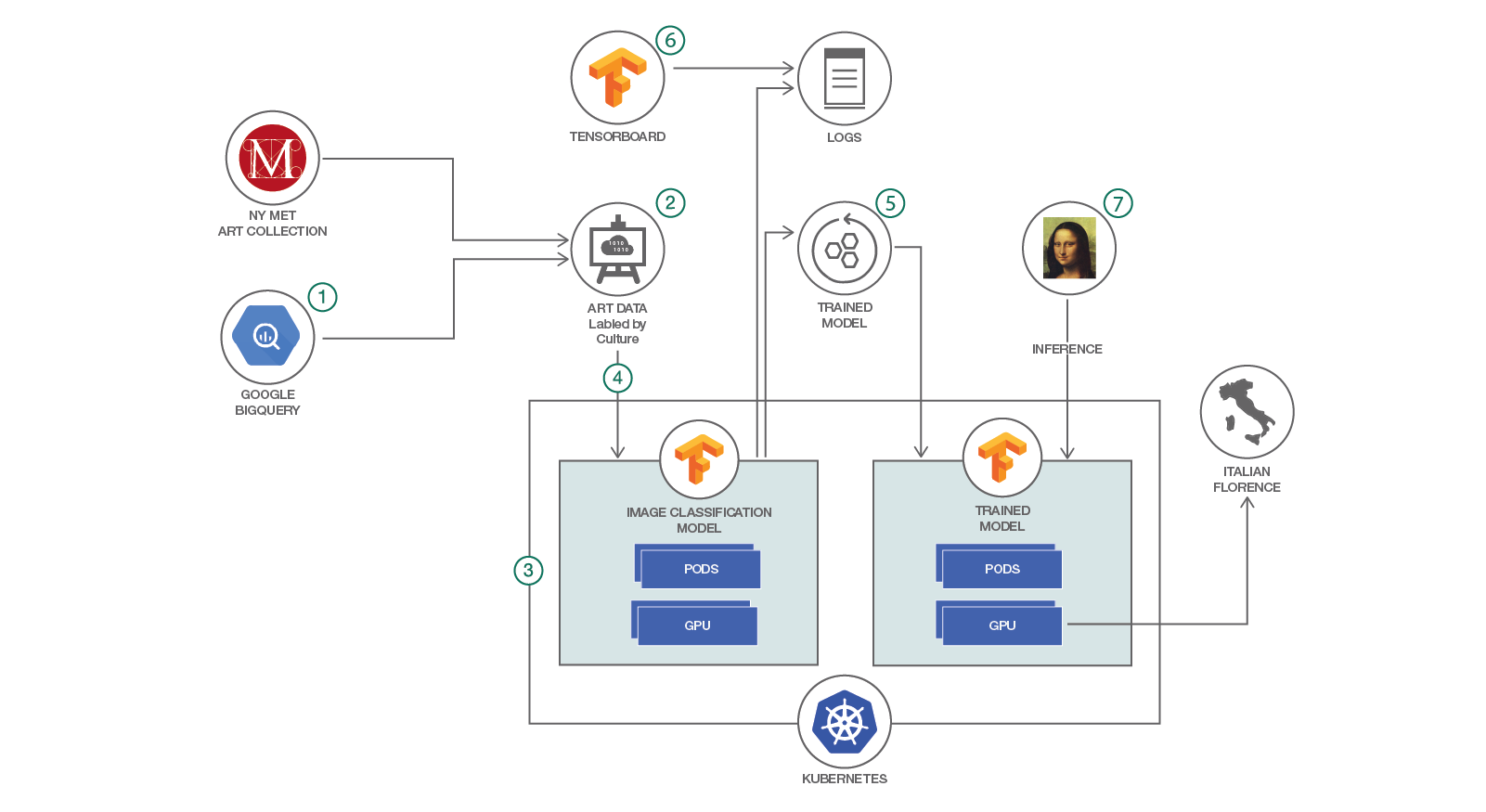
- Inspect the available attributes in the Google BigQuery database for the Met art collection
- Create the labeled dataset using the attribute selected
- Select a model for image classification from the set of available public models and deploy to IBM Cloud
- Run the training on Kubernetes, optionally using GPU if available
- Save the trained model and logs
- Visualize the training with TensorBoard
- Load the trained model in Kubernetes and run an inference on a new art drawing to see the classification
- TensorFlow: An open-source library for implementing Deep Learning models
- Image classification models: A set of models for image classification implemented using the TensorFlow Slim high level API
- New York Metropolitan Museum of Art: The museum hosts a collection of over 450,000 public art artifacts, including paintings, books, etc.
- Google metadata for the Met Art collection: a database containing metadata for over 200,000 items from the art collection at the New York Metropolitan Museum of Art
- Kubernetes cluster: An open-source system for orchestrating containers on a cluster of servers
- IBM Cloud Container Service: A public service from IBM that hosts users applications on Docker and Kubernetes
- TensorFlow: Deep Learning library
- TensorFlow models: public models for Deep Learning
- Kubernetes: Container orchestration
Visualizing High Dimension data for Deep Learning
- IBM Cloud Container Service: A public service from IBM that hosts users applications on Docker and Kubernetes
- TensorFlow: An open-source library for implementing Deep Learning models
- Kubernetes cluster: An open-source system for orchestrating containers on a cluster of servers
- New York Metropolitan Museum of Art: The museum hosts a collection of over 450,000 public art artifacts, including paintings, books, etc.
- Google metadata for Met Art collection: A database containing metadata for over 200,000 items from the art collection at the New York Metropolitan Museum of Art
- Google BigQuery: a web service that provides interactive analysis of massive datasets
- Image classification models: A set of models for image classification implemented using the TensorFlow Slim high level API.