Agent是一种能够自主感知环境并根据感知结果采取行动的实体,以感知序列为输入,以动作作为输出的函数。它可以以软件形式(如聊天机器人、推荐系统)存在,也可以是物理形态的机器(如自动驾驶汽车、机器人)。
基本特性:
- 自主性:能够在没有外部干预的情况下做出决策。
- 交互性:能够与环境交换信息。
- 适应性:根据环境变化调整自身行为。
- 目的性:所有行为都以实现特定目标为导向。
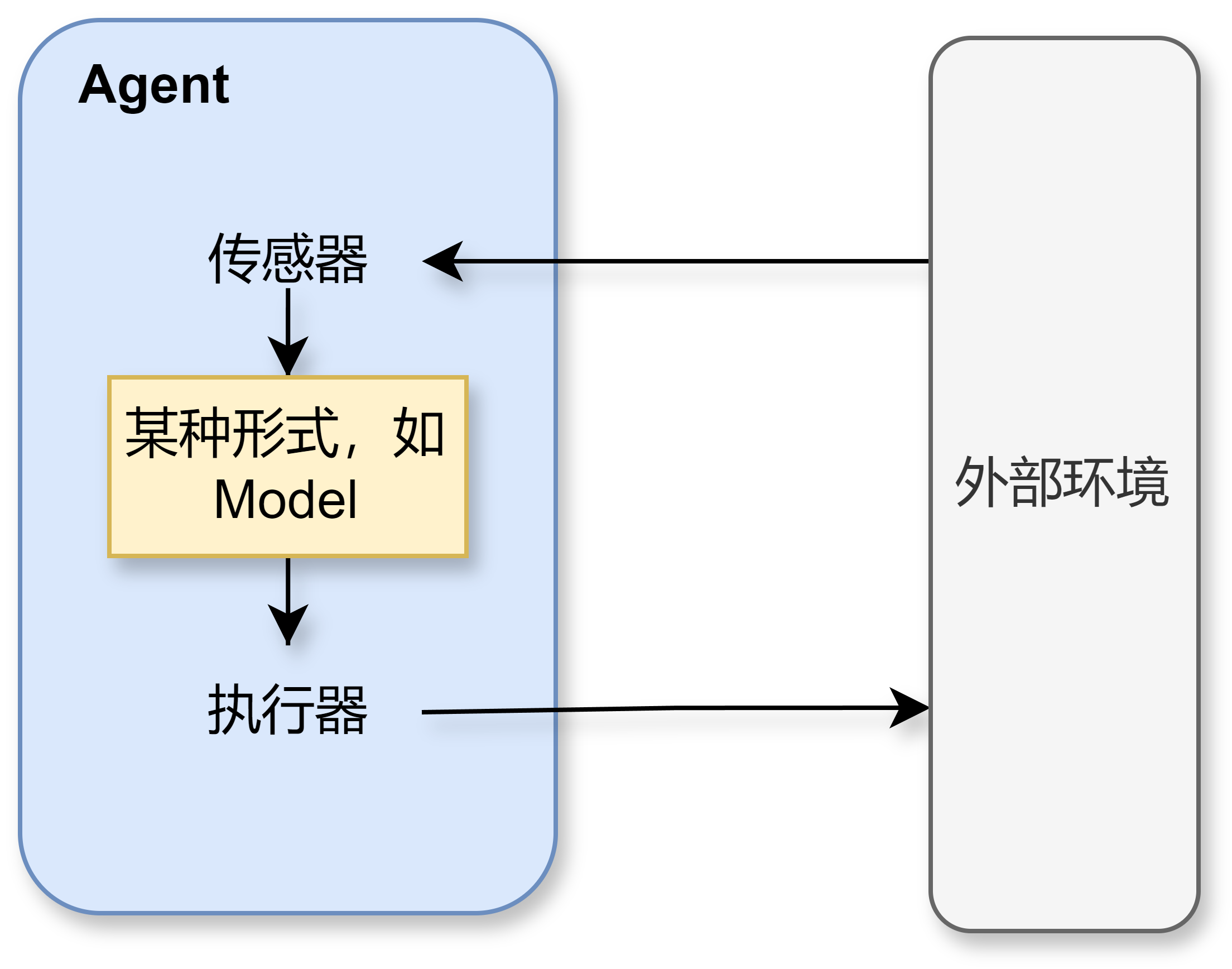
Agent技术的应用领域其实十分广泛,涵盖了从交通、医疗到教育、家居和娱乐等生活的方方面面,以下列举2个实际例子。
(1)自动驾驶系统
- 应用:自动驾驶汽车、出租车等。
- 目标:安全、快捷、守法、舒适和高效。
- 传感器:摄像头、雷达、定位系统等。
- 执行器:方向盘、油门、刹车、信号灯。
(2)医疗诊断系统
- 应用:医院诊断、病情监控。
- 目标:精准诊断、降低费用。
- 传感器:症状输入、患者自述。
- 执行器:检测、诊断、处方。
Lagent 是一个轻量级开源智能体框架,旨在让用户可以高效地构建基于大语言模型的智能体。同时它也提供了一些典型工具以增强大语言模型的能力。
Lagent 目前已经支持了包括 AutoGPT、ReAct 等在内的多个经典智能体范式,也支持了如下工具:
- Arxiv 搜索
- Bing 地图
- Google 学术搜索
- Google 搜索
- 交互式 IPython 解释器
- IPython 解释器
- PPT
- Python 解释器
其基本结构如下所示:

这种范式强调模型无需依赖特定的特殊标记(special token)来定义工具调用的参数边界。模型依靠其强大的指令跟随与推理能力,在指定的system prompt框架下,根据任务需求自动生成响应。这种方式让模型在推理过程中能更灵活地适应多种任务,不需要对Tokenizer进行特殊设计。
优势:
- 灵活适应不同任务,无需设计和维护复杂的标记系统。
- 适合快速迭代,降低微调和部署的复杂性。
- 更易与多模态输入(如文本和图像)结合,扩展模型的通用性。
劣势:
- 由于没有明确标记,调用工具时的错误难以捕捉和纠正。
- 在复杂任务中,模型生成可能不够精准,导致工具调用的准确性下降。
(1)ReAct:将模型的推理分为Reason和Action两个步骤,并让它们交替执行,直到得到最终结果:
- Reason:生成分析步骤,解释当前任务的上下文或状态,帮助模型理解下一步行动的逻辑依据。
- Action:基于Reason的结果,生成具体的工具调用请求(如查询搜索引擎、调用API、数据库检索等),将模型的推理转化为行动。
(2)ReWoo:全称为Reason without Observation,是在ReAct范式基础上进行改进的Agent架构,针对多工具调用的复杂性与冗余性提供了一种高效的解决方案。相比于ReAct中的交替推理和行动,ReWoo直接生成一次性使用的完整工具链,减少了不必要的Token消耗和执行时间。同时,由于工具调用的规划与执行解耦,这一范式在模型微调时不需要实际调用工具即可完成。
- Planner:用户输入的问题或任务首先传递给Planner,Planner将其分解为多个逻辑上相关的计划。每个计划包含推理部分(Reason)以及工具调用和参数(Execution)。Task List按顺序列出所有需要执行的任务链。
- Worker:每个Worker根据Task List中的子任务,调用指定工具并返回结果。所有Worker之间通过共享状态保持任务执行的连续性。
- Solver阶段:Worker完成任务后,将所有结果同步到Solver。Solver会对这些结果进行整合,并生成最终的答案或解决方案返回给用户。
在这种范式下,模型的工具调用必须通过特定的special token明确标记。如InternLM2使用<|action_start|>和<|action_end|>来定义调用边界。这些标记通常与模型的Tokenizer深度集成,确保在执行特定任务时,能够准确捕捉调用信息并执行。
优势:
- 特定标记明确工具调用的起止点,提高了调用的准确性。
- 有助于模型在部署过程中避免误调用,增强系统的可控性。
- 提高对复杂调用链的支持,适合复杂任务的场景。
劣势:
- 需要对Tokenizer和模型架构进行定制,增加开发和维护成本。
- 调用流程固定,降低了模型的灵活性,难以适应快速变化的任务。
(1)InternLM2案例分析: 工具调用使用了如<|plugin|>、<|interpreter|>、<|action_start|>和<|action_end|>等特殊标记,确保每个调用都符合指定的格式。模型在执行任务时,依靠这些标记与系统紧密协作,保障任务的精准执行。文档链接:InternLM-Chat Agent
开发机选择 30% A100,镜像选择为 Cuda12.2-conda。

首先来为 Lagent 配置一个可用的环境。
# 创建环境
conda create -n lagent python=3.10 -y
# 激活环境
conda activate lagent
# 安装 torch
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
# 安装其他依赖包
pip install termcolor==2.4.0
pip install streamlit==1.39.0
pip install class_registry==2.1.2
pip install datasets==3.1.0等待安装完成~

接下来,我们通过源码安装的方式安装 lagent。
# 创建目录以存放代码
mkdir -p /root/agent_camp4
cd /root/agent_camp4
git clone https://github.com/InternLM/lagent.git
cd lagent && git checkout e304e5d && pip install -e . && cd ..
pip install griffe==0.48.0接下来,我们将使用 Lagent 框架,一步步搭建并使用基于 InternLM2.5 的 Web Demo,体验其强大的智能体功能。
首先,需要申请 API 授权令牌 ,请前往 书生·浦语 API 文档 申请并获取 Authorization 令牌,将其填入后续代码的 YOUR_TOKEN_HERE 变量中。
创建一个代码example,创建agent_api_web_demo.py,在里面实现我们的Web Demo:
conda activate lagent
cd /root/agent_camp4/lagent/examples
touch agent_api_web_demo.pyAction,也称为工具,Lagent中集成了很多好用的工具,提供了一套LLM驱动的智能体用来与真实世界交互并执行复杂任务的函数,包括谷歌文献检索、Arxiv文献检索、Python编译器等。具体可以查看文档
让我们来体验一下,让LLM调用Arxiv文献检索这个工具:
在agent_api_web_demo.py中写入下面的代码,这里利用 GPTAPI 类,该类继承自 BaseAPILLM,封装了对 API 的调用逻辑,然后利用Streamlit启动Web服务:
import copy
import os
from typing import List
import streamlit as st
from lagent.actions import ArxivSearch
from lagent.prompts.parsers import PluginParser
from lagent.agents.stream import INTERPRETER_CN, META_CN, PLUGIN_CN, AgentForInternLM, get_plugin_prompt
from lagent.llms import GPTAPI
class SessionState:
"""管理会话状态的类。"""
def init_state(self):
"""初始化会话状态变量。"""
st.session_state['assistant'] = [] # 助手消息历史
st.session_state['user'] = [] # 用户消息历史
# 初始化插件列表
action_list = [
ArxivSearch(),
]
st.session_state['plugin_map'] = {action.name: action for action in action_list}
st.session_state['model_map'] = {} # 存储模型实例
st.session_state['model_selected'] = None # 当前选定模型
st.session_state['plugin_actions'] = set() # 当前激活插件
st.session_state['history'] = [] # 聊天历史
st.session_state['api_base'] = None # 初始化API base地址
def clear_state(self):
"""清除当前会话状态。"""
st.session_state['assistant'] = []
st.session_state['user'] = []
st.session_state['model_selected'] = None
class StreamlitUI:
"""管理 Streamlit 界面的类。"""
def __init__(self, session_state: SessionState):
self.session_state = session_state
self.plugin_action = [] # 当前选定的插件
# 初始化提示词
self.meta_prompt = META_CN
self.plugin_prompt = PLUGIN_CN
self.init_streamlit()
def init_streamlit(self):
"""初始化 Streamlit 的 UI 设置。"""
st.set_page_config(
layout='wide',
page_title='lagent-web',
page_icon='./docs/imgs/lagent_icon.png'
)
st.header(':robot_face: :blue[Lagent] Web Demo ', divider='rainbow')
def setup_sidebar(self):
"""设置侧边栏,选择模型和插件。"""
# 模型名称和 API Base 输入框
model_name = st.sidebar.text_input('模型名称:', value='internlm2.5-latest')
# ================================== 硅基流动的API ==================================
# 注意,如果采用硅基流动API,模型名称需要更改为:internlm/internlm2_5-7b-chat 或者 internlm/internlm2_5-20b-chat
# api_base = st.sidebar.text_input(
# 'API Base 地址:', value='https://api.siliconflow.cn/v1/chat/completions'
# )
# ================================== 浦语官方的API ==================================
api_base = st.sidebar.text_input(
'API Base 地址:', value='https://internlm-chat.intern-ai.org.cn/puyu/api/v1/chat/completions'
)
# ==================================================================================
# 插件选择
plugin_name = st.sidebar.multiselect(
'插件选择',
options=list(st.session_state['plugin_map'].keys()),
default=[],
)
# 根据选择的插件生成插件操作列表
self.plugin_action = [st.session_state['plugin_map'][name] for name in plugin_name]
# 动态生成插件提示
if self.plugin_action:
self.plugin_prompt = get_plugin_prompt(self.plugin_action)
# 清空对话按钮
if st.sidebar.button('清空对话', key='clear'):
self.session_state.clear_state()
return model_name, api_base, self.plugin_action
def initialize_chatbot(self, model_name, api_base, plugin_action):
"""初始化 GPTAPI 实例作为 chatbot。"""
token = os.getenv("token")
if not token:
st.error("未检测到环境变量 `token`,请设置环境变量,例如 `export token='your_token_here'` 后重新运行 X﹏X")
st.stop() # 停止运行应用
# 创建完整的 meta_prompt,保留原始结构并动态插入侧边栏配置
meta_prompt = [
{"role": "system", "content": self.meta_prompt, "api_role": "system"},
{"role": "user", "content": "", "api_role": "user"},
{"role": "assistant", "content": self.plugin_prompt, "api_role": "assistant"},
{"role": "environment", "content": "", "api_role": "environment"}
]
api_model = GPTAPI(
model_type=model_name,
api_base=api_base,
key=token, # 从环境变量中获取授权令牌
meta_template=meta_prompt,
max_new_tokens=512,
temperature=0.8,
top_p=0.9
)
return api_model
def render_user(self, prompt: str):
"""渲染用户输入内容。"""
with st.chat_message('user'):
st.markdown(prompt)
def render_assistant(self, agent_return):
"""渲染助手响应内容。"""
with st.chat_message('assistant'):
content = getattr(agent_return, "content", str(agent_return))
st.markdown(content if isinstance(content, str) else str(content))
def main():
"""主函数,运行 Streamlit 应用。"""
if 'ui' not in st.session_state:
session_state = SessionState()
session_state.init_state()
st.session_state['ui'] = StreamlitUI(session_state)
else:
st.set_page_config(
layout='wide',
page_title='lagent-web',
page_icon='./docs/imgs/lagent_icon.png'
)
st.header(':robot_face: :blue[Lagent] Web Demo ', divider='rainbow')
# 设置侧边栏并获取模型和插件信息
model_name, api_base, plugin_action = st.session_state['ui'].setup_sidebar()
plugins = [dict(type=f"lagent.actions.{plugin.__class__.__name__}") for plugin in plugin_action]
if (
'chatbot' not in st.session_state or
model_name != st.session_state['chatbot'].model_type or
'last_plugin_action' not in st.session_state or
plugin_action != st.session_state['last_plugin_action'] or
api_base != st.session_state['api_base']
):
# 更新 Chatbot
st.session_state['chatbot'] = st.session_state['ui'].initialize_chatbot(model_name, api_base, plugin_action)
st.session_state['last_plugin_action'] = plugin_action # 更新插件状态
st.session_state['api_base'] = api_base # 更新 API Base 地址
# 初始化 AgentForInternLM
st.session_state['agent'] = AgentForInternLM(
llm=st.session_state['chatbot'],
plugins=plugins,
output_format=dict(
type=PluginParser,
template=PLUGIN_CN,
prompt=get_plugin_prompt(plugin_action)
)
)
# 清空对话历史
st.session_state['session_history'] = []
if 'agent' not in st.session_state:
st.session_state['agent'] = None
agent = st.session_state['agent']
for prompt, agent_return in zip(st.session_state['user'], st.session_state['assistant']):
st.session_state['ui'].render_user(prompt)
st.session_state['ui'].render_assistant(agent_return)
# 处理用户输入
if user_input := st.chat_input(''):
st.session_state['ui'].render_user(user_input)
# 调用模型时确保侧边栏的系统提示词和插件提示词生效
res = agent(user_input, session_id=0)
st.session_state['ui'].render_assistant(res)
# 更新会话状态
st.session_state['user'].append(user_input)
st.session_state['assistant'].append(copy.deepcopy(res))
st.session_state['last_status'] = None
if __name__ == '__main__':
main()在终端中记得先将获取的API密钥写入环境变量,然后再输入启动命令:
export token='your_token_here'
streamlit run agent_api_web_demo.py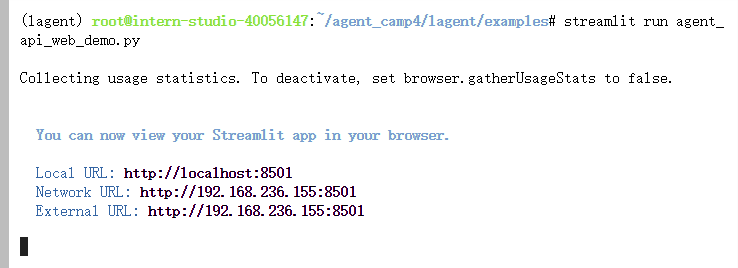
在等待server启动成功后,我们在 本地 的 PowerShell 中输入如下指令来进行端口映射:
ssh -CNg -L 8501:127.0.0.1:8501 [email protected] -p <你的 SSH 端口号>接下来,在本地浏览器中打开 http://localhost:8501/:
当然,如果忘记输入环境变量,启动时会报错❌,比如下面这个错误示例:
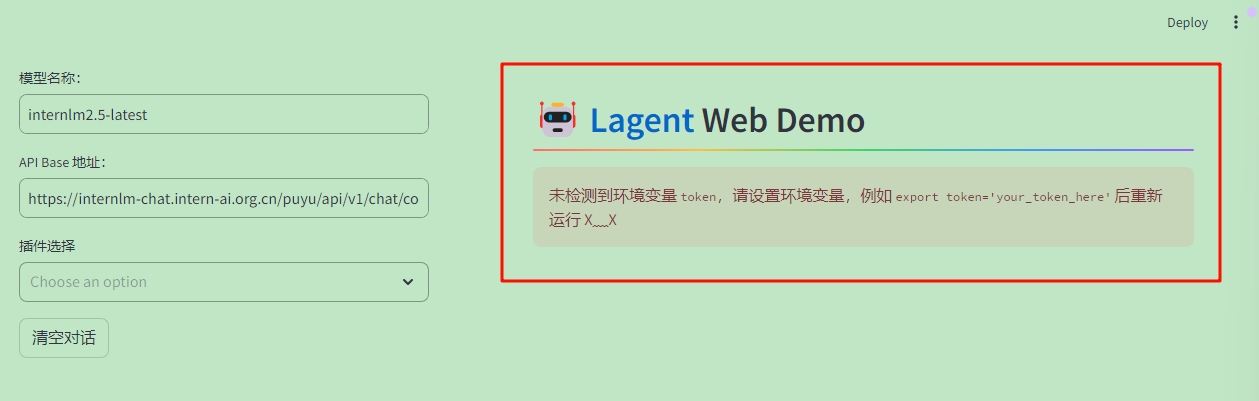
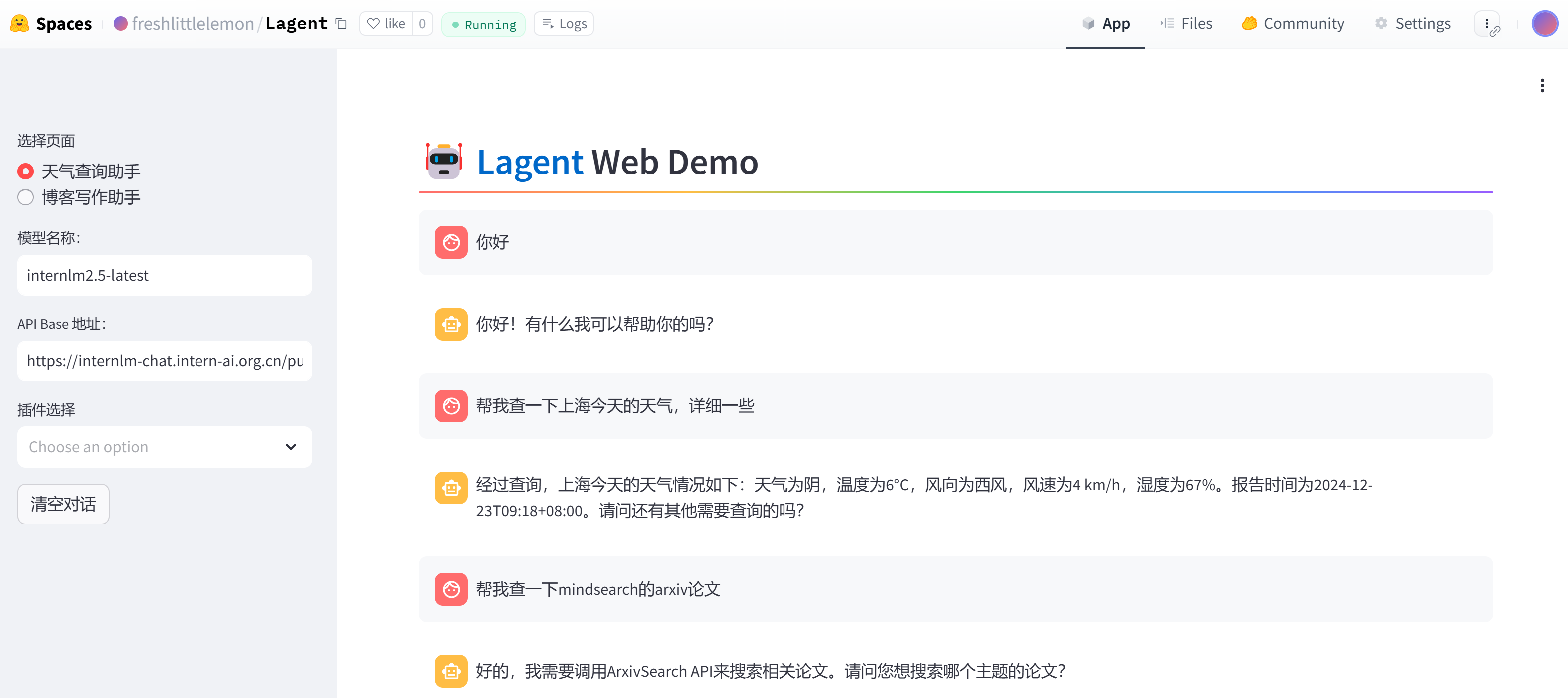
如果正确输入密钥,可以看到页面如下。
页面的侧边栏有三个内容,分别是模型名称、API Base地址和插件选择,其中如果采用浦语的API,模型名称可以选择internlm2.5-latest,默认指向最新发布的 InternLM2.5 系列模型,当前指向internlm2.5-20b-0719,窗口长度是32K,最大输出4096Tokens。
备注: 如果采用硅基流动API,模型名称需要更改为:internlm/internlm2_5-7b-chat 或者 internlm/internlm2_5-20b-chat。

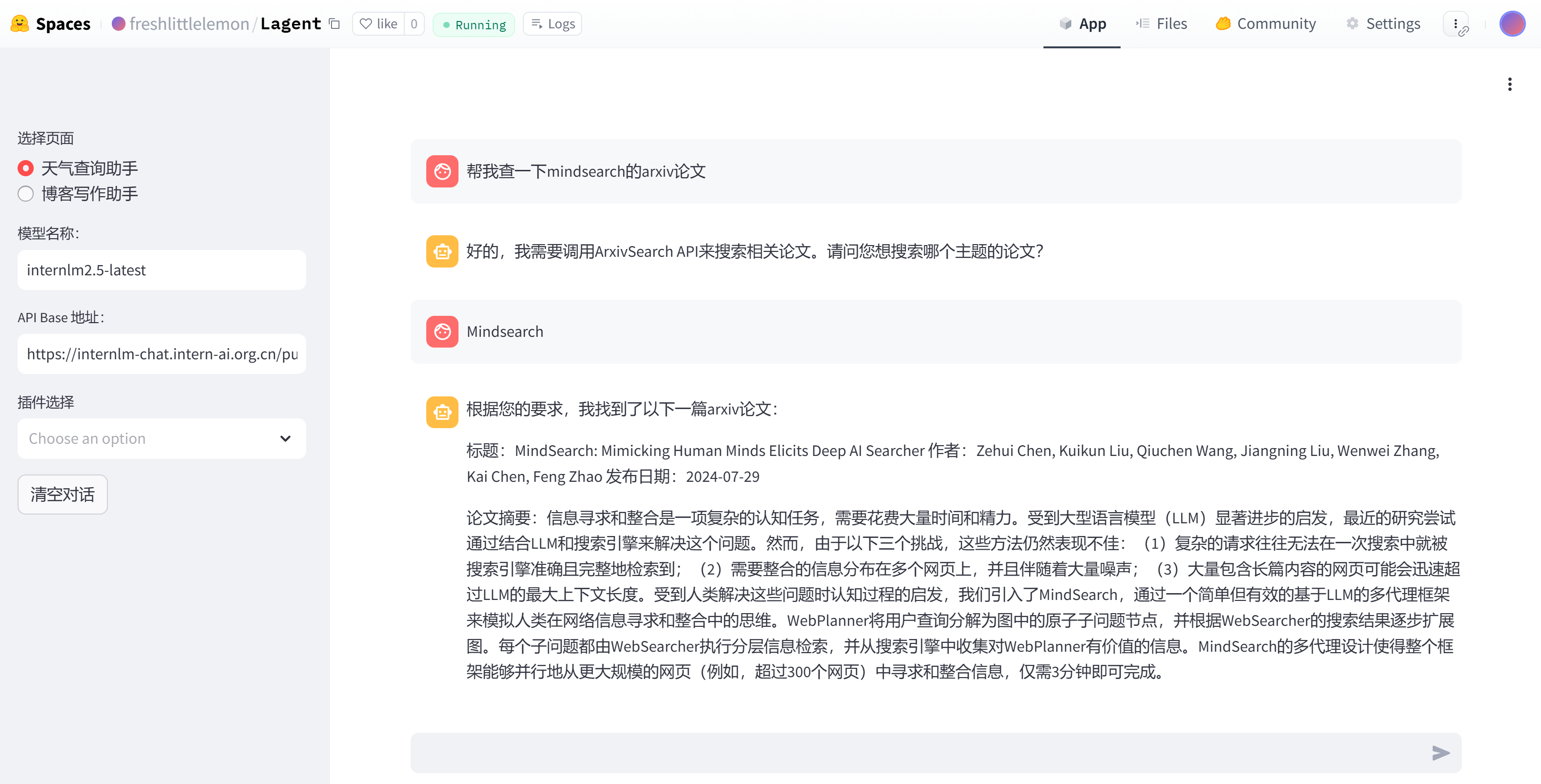
可以尝试进行几轮简单的对话,并让其搜索文献,会发现大模型现在尽管有比较好的对话能力,但是并不能帮我们准确的找到文献,例如输入指令“帮我搜索一下最新版本的MindSearch论文”,会提示没有这方面的能力:
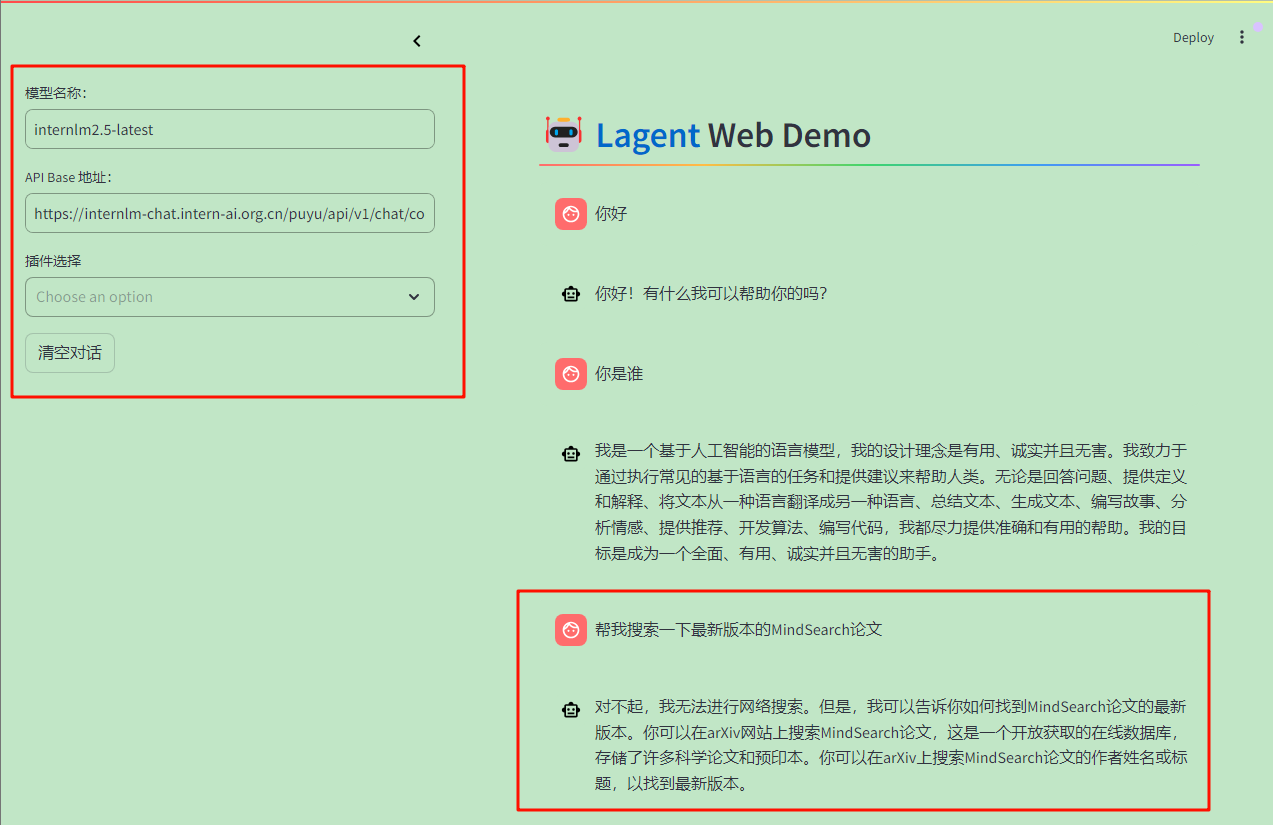
现在将ArxivSearch插件选择上,再次输入指令“帮我搜索一下最新版本的MindSearch论文”,可以看到,通过调用外部工具,大模型成功理解了我们的任务,得到了我们需要的文献:

在完成了上面的内容后,可能就会同学好奇了,那么我应该如何基于Lagent框架实现一个自己的工具,赋予LLM额外的能力? 本节将会以实时天气查询为例子,通过调用和风天气API,介绍如何自定义一个自己的Agent。
Lagent 框架的工具部分文档可以在此处查看:Lagent 工具文档。
使用 Lagent 自定义工具主要分为以下3步:
(1)继承 BaseAction 类
(2)实现简单工具的 run 方法;或者实现工具包内每个子工具的功能
(3)简单工具的 run 方法可选被 tool_api 装饰;工具包内每个子工具的功能都需要被 tool_api 装饰
首先,为了使用和风天气的 API 服务,你需要获取一个 API Key。请按以下步骤操作:
(1)访问 和风天气 API 文档(需要注册账号)。
(2)点击页面右上角的“控制台”。
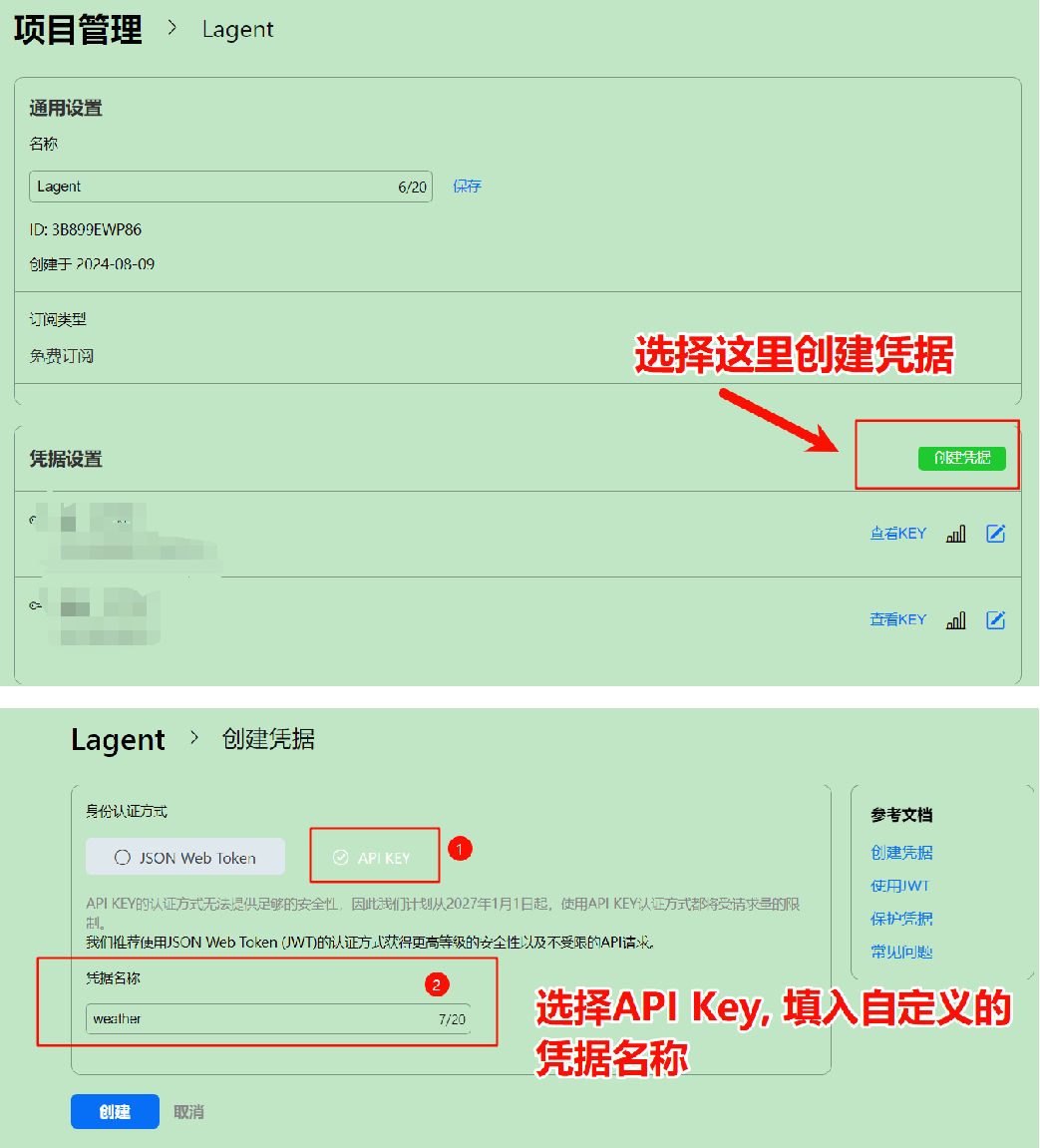
(3)在控制台中,点击左侧的“项目管理”,然后点击右上角“创建项目”。
(4)输入项目名称(可以使用“Lagent”),选择免费订阅,并在凭据设置中创建新的凭据。
(5)创建后,回到“项目管理”页面,找到你的 API Key 并复制保存。

接着,我们需要在laegnt/actions文件夹下面创建一个天气查询的工具程序。
conda activate lagent
cd /root/agent_camp4/lagent/lagent/actions
touch weather_query.py将下面的代码复制进去,注意要将刚刚申请的API Key在终端中输入进去:
export weather_token='your_token_here'import os
import requests
from lagent.actions.base_action import BaseAction, tool_api
from lagent.schema import ActionReturn, ActionStatusCode
class WeatherQuery(BaseAction):
def __init__(self):
super().__init__()
self.api_key = os.getenv("weather_token")
print(self.api_key)
if not self.api_key:
raise EnvironmentError("未找到环境变量 'token'。请设置你的和风天气 API Key 到 'weather_token' 环境变量中,比如export weather_token='xxx' ")
@tool_api
def run(self, location: str) -> dict:
"""
查询实时天气信息。
Args:
location (str): 要查询的地点名称、LocationID 或经纬度坐标(如 "101010100" 或 "116.41,39.92")。
Returns:
dict: 包含天气信息的字典
* location: 地点名称
* weather: 天气状况
* temperature: 当前温度
* wind_direction: 风向
* wind_speed: 风速(公里/小时)
* humidity: 相对湿度(%)
* report_time: 数据报告时间
"""
try:
# 如果 location 不是坐标格式(例如 "116.41,39.92"),则调用 GeoAPI 获取 LocationID
if not ("," in location and location.replace(",", "").replace(".", "").isdigit()):
# 使用 GeoAPI 获取 LocationID
geo_url = f"https://geoapi.qweather.com/v2/city/lookup?location={location}&key={self.api_key}"
geo_response = requests.get(geo_url)
geo_data = geo_response.json()
if geo_data.get("code") != "200" or not geo_data.get("location"):
raise Exception(f"GeoAPI 返回错误码:{geo_data.get('code')} 或未找到位置")
location = geo_data["location"][0]["id"]
# 构建天气查询的 API 请求 URL
weather_url = f"https://devapi.qweather.com/v7/weather/now?location={location}&key={self.api_key}"
response = requests.get(weather_url)
data = response.json()
# 检查 API 响应码
if data.get("code") != "200":
raise Exception(f"Weather API 返回错误码:{data.get('code')}")
# 解析和组织天气信息
weather_info = {
"location": location,
"weather": data["now"]["text"],
"temperature": data["now"]["temp"] + "°C",
"wind_direction": data["now"]["windDir"],
"wind_speed": data["now"]["windSpeed"] + " km/h",
"humidity": data["now"]["humidity"] + "%",
"report_time": data["updateTime"]
}
return {"result": weather_info}
except Exception as exc:
return ActionReturn(
errmsg=f"WeatherQuery 异常:{exc}",
state=ActionStatusCode.HTTP_ERROR
)其中,WeatherQuery 类继承自 BaseAction,这是 Lagent 的基础工具类,提供了工具的框架逻辑。tool_api 是一个装饰器,用于标记工具中具体执行逻辑的函数,使得 Lagent 智能体能够调用该方法执行任务。run 方法是工具的主要逻辑入口,通常会根据输入参数完成一项任务并返回结果。
在具体函数实现上,利用GeoAPI 获取 LocationID,当用户输入的 location 不是经纬度坐标格式(如 116.41,39.92),则使用和风天气的 GeoAPI 将位置名转换为 LocationID,并通过 Weather API 获取目标位置的实时天气数据。最后,解析返回的 JSON 数据,并格式化为结构化字典:
在/root/agent_camp4/lagent/lagent/actions/__init__.py中加入下面的代码,用以初始化WeatherQuery方法:
from .weather_query import WeatherQuery
__all__ = [
'BaseAction', 'ActionExecutor', 'AsyncActionExecutor', 'InvalidAction',
'FinishAction', 'NoAction', 'BINGMap', 'AsyncBINGMap', 'ArxivSearch',
'AsyncArxivSearch', 'GoogleSearch', 'AsyncGoogleSearch', 'GoogleScholar',
'AsyncGoogleScholar', 'IPythonInterpreter', 'AsyncIPythonInterpreter',
'IPythonInteractive', 'AsyncIPythonInteractive',
'IPythonInteractiveManager', 'PythonInterpreter', 'AsyncPythonInterpreter',
'PPT', 'AsyncPPT', 'WebBrowser', 'AsyncWebBrowser', 'BaseParser',
'JsonParser', 'TupleParser', 'tool_api', 'WeatherQuery' # 这里
]接下来,我们将修改 Web Demo 脚本来集成自定义的 WeatherQuery 插件。
打开agent_api_web_demo.py, 修改内容如下,目的是将该工具注册进大模型的插件列表中,使得其可以知道。
- from lagent.actions import ArxivSearch
+ from lagent.actions import ArxivSearch, WeatherQuery
- # 初始化插件列表
- action_list = [
- ArxivSearch(),
- ]
+ action_list = [
+ ArxivSearch(),
+ WeatherQuery(),
+ ]再次启动Web程序,streamlit run agent_api_web_demo.py。
可以看到左侧的插件栏多了天气查询插件,我们首先输入命令“帮我查询一下南京现在的天气”,可以看到模型无法知道现在的实时天气情况。

现在,我们将2个插件同时勾选上,用以说明模型具备识别调用不同工具的能力,什么任务对应什么工具来解决。
这次我们查询一下南京(随便什么城市都行的☀️)的天气,输入命令“帮我查询一下南京现在的天气”。 现在,大模型通过天气查询的API准确地完成了这个任务:

如果我们再次询问,让其搜索文献,可以看到,模型具备了根据任务情况调用不同工具的能力。

在这一节中,我们将使用 Lagent 来构建一个多智能体系统 (Multi-Agent System),展示如何协调不同的智能代理完成内容生成和优化的任务。我们的多智能体系统由两个主要代理组成:
(1)内容生成代理:负责根据用户的主题提示生成一篇结构化、专业的文章或报告。
(2)批评优化代理:负责审阅生成的内容,指出不足,推荐合适的文献,使文章更加完善。
Multi-Agents博客写作系统的流程图如下:

首先,创建一个新的 Python 文件 multi_agents_api_web_demo.py,并进入 lagent 环境:
conda activate lagent
cd /root/agent_camp4/lagent/examples
touch multi_agents_api_web_demo.py将下面的代码填入multi_agents_api_web_demo.py:
import os
import asyncio
import json
import re
import requests
import streamlit as st
from lagent.agents import Agent
from lagent.prompts.parsers import PluginParser
from lagent.agents.stream import PLUGIN_CN, get_plugin_prompt
from lagent.schema import AgentMessage
from lagent.actions import ArxivSearch
from lagent.hooks import Hook
from lagent.llms import GPTAPI
YOUR_TOKEN_HERE = os.getenv("token")
if not YOUR_TOKEN_HERE:
raise EnvironmentError("未找到环境变量 'token',请设置后再运行程序。")
# Hook类,用于对消息添加前缀
class PrefixedMessageHook(Hook):
def __init__(self, prefix, senders=None):
"""
初始化Hook
:param prefix: 消息前缀
:param senders: 指定发送者列表
"""
self.prefix = prefix
self.senders = senders or []
def before_agent(self, agent, messages, session_id):
"""
在代理处理消息前修改消息内容
:param agent: 当前代理
:param messages: 消息列表
:param session_id: 会话ID
"""
for message in messages:
if message.sender in self.senders:
message.content = self.prefix + message.content
class AsyncBlogger:
"""博客生成类,整合写作者和批评者。"""
def __init__(self, model_type, api_base, writer_prompt, critic_prompt, critic_prefix='', max_turn=2):
"""
初始化博客生成器
:param model_type: 模型类型
:param api_base: API 基地址
:param writer_prompt: 写作者提示词
:param critic_prompt: 批评者提示词
:param critic_prefix: 批评消息前缀
:param max_turn: 最大轮次
"""
self.model_type = model_type
self.api_base = api_base
self.llm = GPTAPI(
model_type=model_type,
api_base=api_base,
key=YOUR_TOKEN_HERE,
max_new_tokens=4096,
)
self.plugins = [dict(type='lagent.actions.ArxivSearch')]
self.writer = Agent(
self.llm,
writer_prompt,
name='写作者',
output_format=dict(
type=PluginParser,
template=PLUGIN_CN,
prompt=get_plugin_prompt(self.plugins)
)
)
self.critic = Agent(
self.llm,
critic_prompt,
name='批评者',
hooks=[PrefixedMessageHook(critic_prefix, ['写作者'])]
)
self.max_turn = max_turn
async def forward(self, message: AgentMessage, update_placeholder):
"""
执行多阶段博客生成流程
:param message: 初始消息
:param update_placeholder: Streamlit占位符
:return: 最终优化的博客内容
"""
step1_placeholder = update_placeholder.container()
step2_placeholder = update_placeholder.container()
step3_placeholder = update_placeholder.container()
# 第一步:生成初始内容
step1_placeholder.markdown("**Step 1: 生成初始内容...**")
message = self.writer(message)
if message.content:
step1_placeholder.markdown(f"**生成的初始内容**:\n\n{message.content}")
else:
step1_placeholder.markdown("**生成的初始内容为空,请检查生成逻辑。**")
# 第二步:批评者提供反馈
step2_placeholder.markdown("**Step 2: 批评者正在提供反馈和文献推荐...**")
message = self.critic(message)
if message.content:
# 解析批评者反馈
suggestions = re.search(r"1\. 批评建议:\n(.*?)2\. 推荐的关键词:", message.content, re.S)
keywords = re.search(r"2\. 推荐的关键词:\n- (.*)", message.content)
feedback = suggestions.group(1).strip() if suggestions else "未提供批评建议"
keywords = keywords.group(1).strip() if keywords else "未提供关键词"
# Arxiv 文献查询
arxiv_search = ArxivSearch()
arxiv_results = arxiv_search.get_arxiv_article_information(keywords)
# 显示批评内容和文献推荐
message.content = f"**批评建议**:\n{feedback}\n\n**推荐的文献**:\n{arxiv_results}"
step2_placeholder.markdown(f"**批评和文献推荐**:\n\n{message.content}")
else:
step2_placeholder.markdown("**批评内容为空,请检查批评逻辑。**")
# 第三步:写作者根据反馈优化内容
step3_placeholder.markdown("**Step 3: 根据反馈改进内容...**")
improvement_prompt = AgentMessage(
sender="critic",
content=(
f"根据以下批评建议和推荐文献对内容进行改进:\n\n"
f"批评建议:\n{feedback}\n\n"
f"推荐文献:\n{arxiv_results}\n\n"
f"请优化初始内容,使其更加清晰、丰富,并符合专业水准。"
),
)
message = self.writer(improvement_prompt)
if message.content:
step3_placeholder.markdown(f"**最终优化的博客内容**:\n\n{message.content}")
else:
step3_placeholder.markdown("**最终优化的博客内容为空,请检查生成逻辑。**")
return message
def setup_sidebar():
"""设置侧边栏,选择模型。"""
model_name = st.sidebar.text_input('模型名称:', value='internlm2.5-latest')
api_base = st.sidebar.text_input(
'API Base 地址:', value='https://internlm-chat.intern-ai.org.cn/puyu/api/v1/chat/completions'
)
return model_name, api_base
def main():
"""
主函数:构建Streamlit界面并处理用户交互
"""
st.set_page_config(layout='wide', page_title='Lagent Web Demo', page_icon='🤖')
st.title("多代理博客优化助手")
model_type, api_base = setup_sidebar()
topic = st.text_input('输入一个话题:', 'Self-Supervised Learning')
generate_button = st.button('生成博客内容')
if (
'blogger' not in st.session_state or
st.session_state['model_type'] != model_type or
st.session_state['api_base'] != api_base
):
st.session_state['blogger'] = AsyncBlogger(
model_type=model_type,
api_base=api_base,
writer_prompt="你是一位优秀的AI内容写作者,请撰写一篇有吸引力且信息丰富的博客内容。",
critic_prompt="""
作为一位严谨的批评者,请给出建设性的批评和改进建议,并基于相关主题使用已有的工具推荐一些参考文献,推荐的关键词应该是英语形式,简洁且切题。
请按照以下格式提供反馈:
1. 批评建议:
- (具体建议)
2. 推荐的关键词:
- (关键词1, 关键词2, ...)
""",
critic_prefix="请批评以下内容,并提供改进建议:\n\n"
)
st.session_state['model_type'] = model_type
st.session_state['api_base'] = api_base
if generate_button:
update_placeholder = st.empty()
async def run_async_blogger():
message = AgentMessage(
sender='user',
content=f"请撰写一篇关于{topic}的博客文章,要求表达专业,生动有趣,并且易于理解。"
)
result = await st.session_state['blogger'].forward(message, update_placeholder)
return result
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(run_async_blogger())
if __name__ == '__main__':
main()运行streamlit run multi_agents_api_web_demo.py,启动Web服务
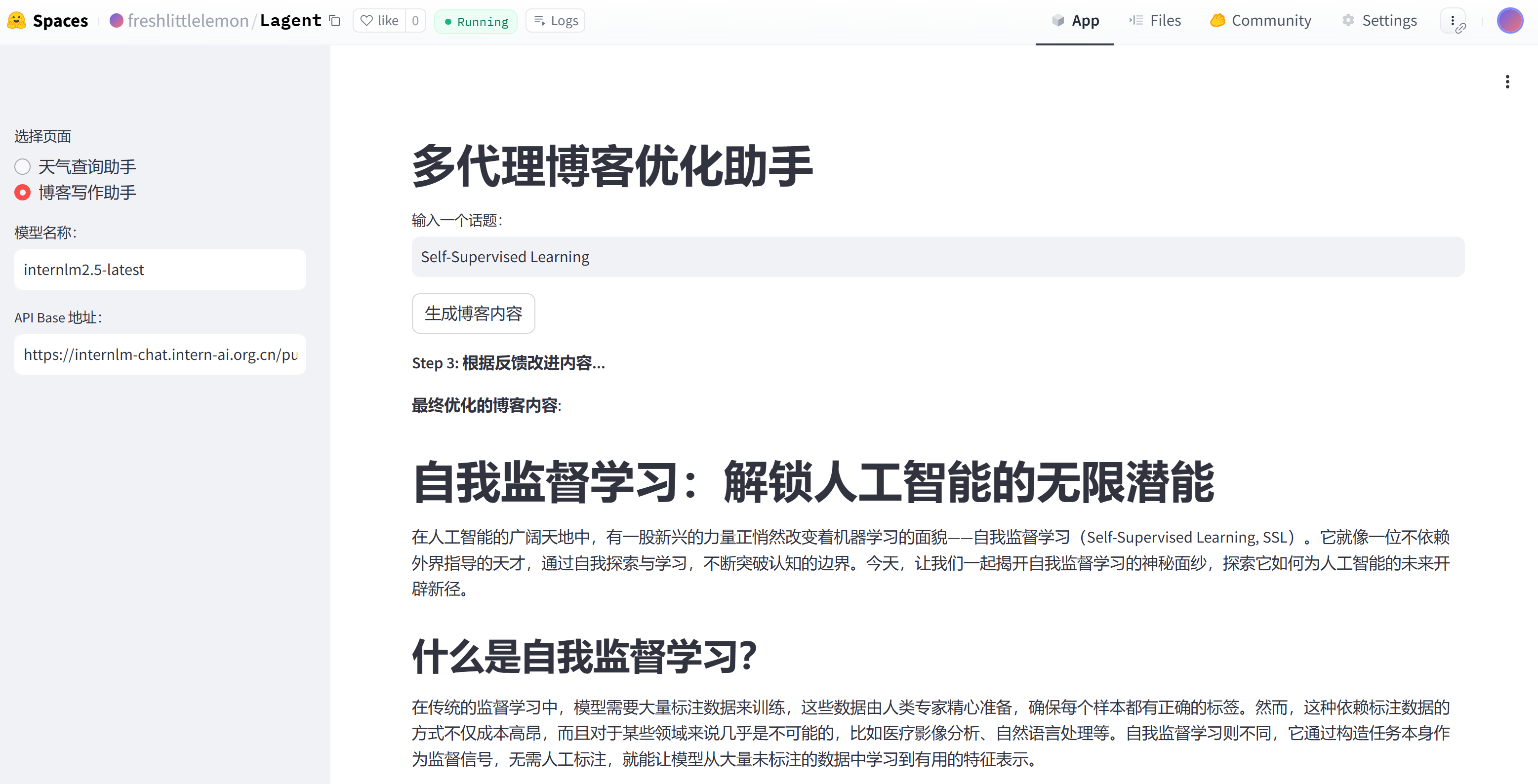
输入话题,比如Semi-Supervised Learning:
可以看到,Multi-Agents博客写作系统正在按照下面的3步骤,生成、批评和完善内容。
Step 1:写作者根据用户输入生成初稿。
Step 2:批评者对初稿进行评估,提供改进建议和文献推荐(通过关键词触发 Arxiv 文献搜索)。
Step 3:写作者根据批评意见对内容进行改进。
输入一个感兴趣的话题:

第一步生成的结果:

第二步批评和文献检索的结果:

第三步最后完善的内容,可以看到其中包括了检索得到的文献,使得博客内容更加具有可信度。

至此,我们完成了本节课所有内容。 希望大家通过今天的学习,能够更加系统地掌握Agent和Multi-Agents的核心思想和实现方法,并在实际开发中灵活运用。🎉🎉🎉
本部分由社区甘施羽同学贡献🎉🎉
小伙伴们可能在将 agent 的代码部署到 Huggingface Spaces 时遇到了一些困难,比如我不想让别人看到我的 api_key 但我又不知道环境变量怎么设?agent 的 demo 里引用了别的代码的内容,有没有比较方便的办法保留原本的文档结构,直接把天气和博客两个代码一锅端一块儿提交?接下来将手把手教大家解决上面两个痛点。
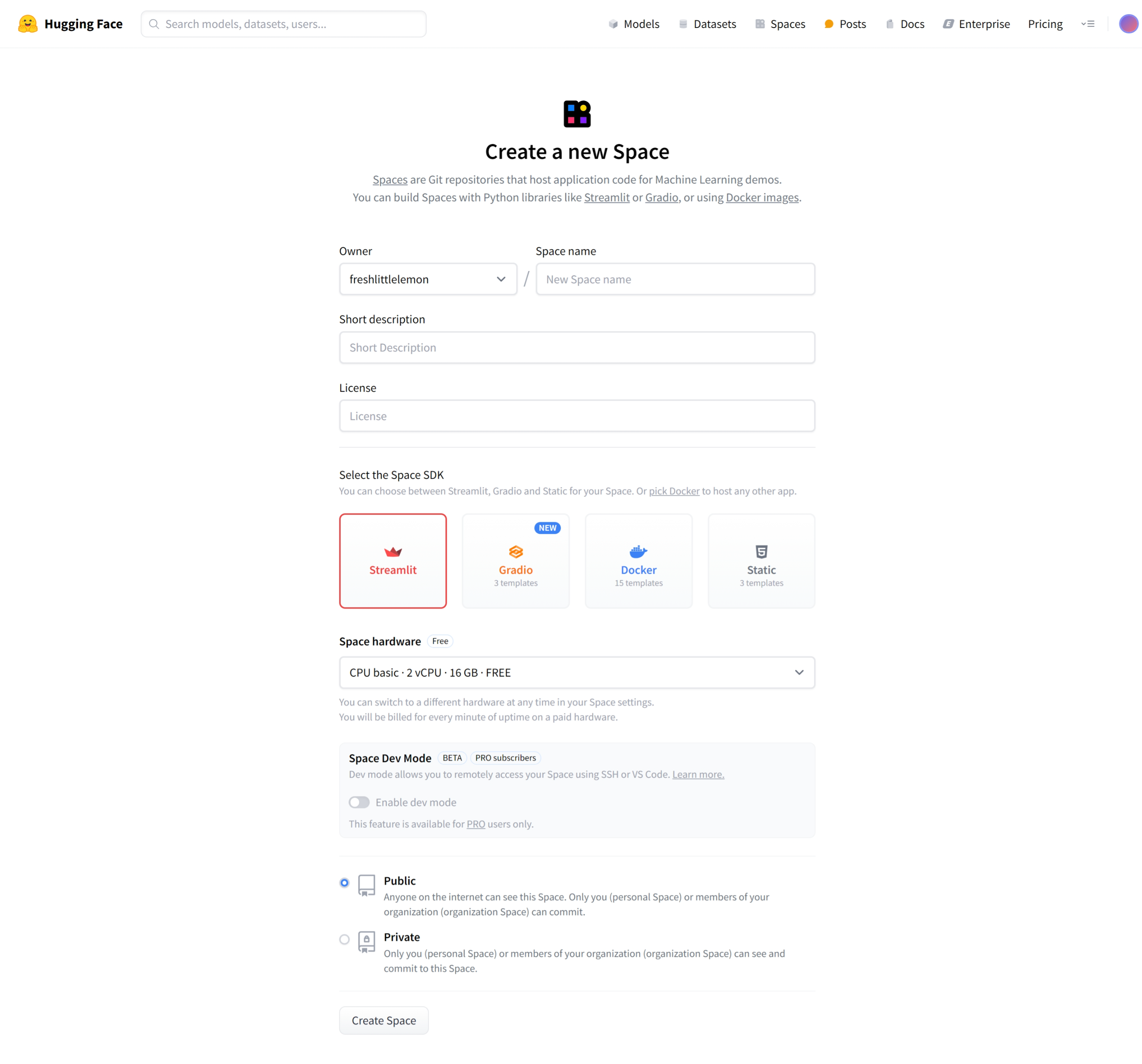
首先创建一个新的Spaces,SDK 选择 Streamlit,你会发现在创建的页面中我们并没有关于环境变量或者密钥的选项,不急,先点击 Create Spaces
然后就会跳转到如下页面,点击右上角 Settings
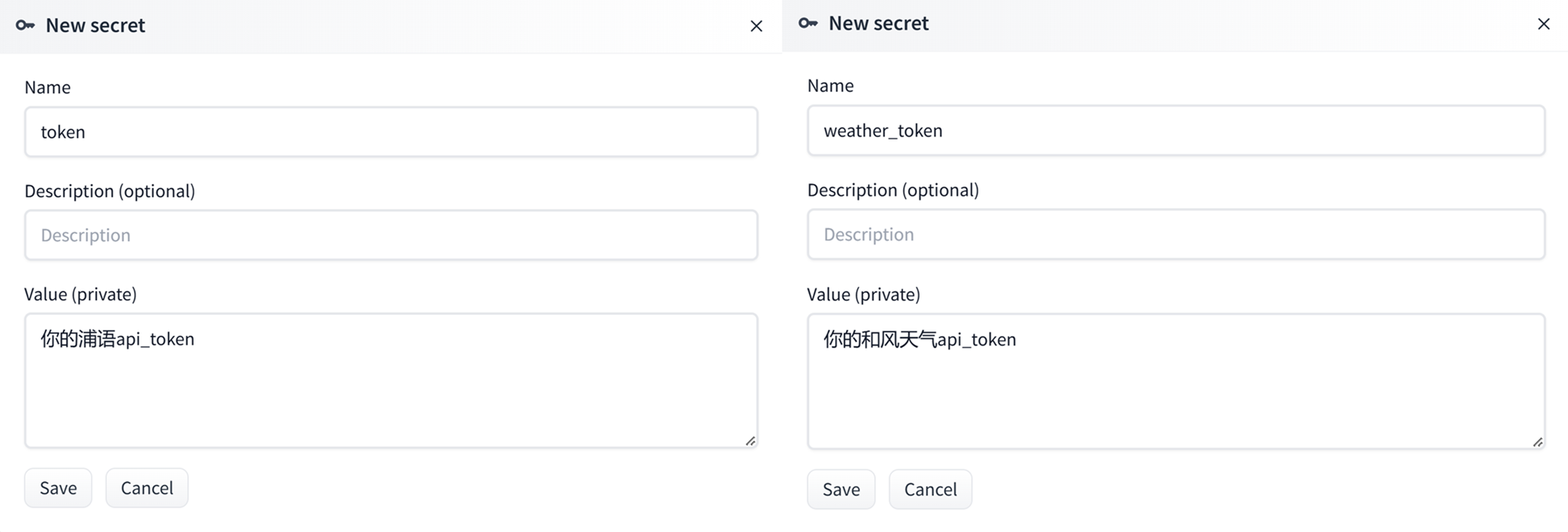
然后往下翻,找到 Variables and secrets,找到右上角创建 New secret
 这里我们输入两个 api_key,一个是
这里我们输入两个 api_key,一个是 token ——你的浦语/硅基流动 api,一个是 weather_token ——你的和风天气 api,要注意名称不要写错。
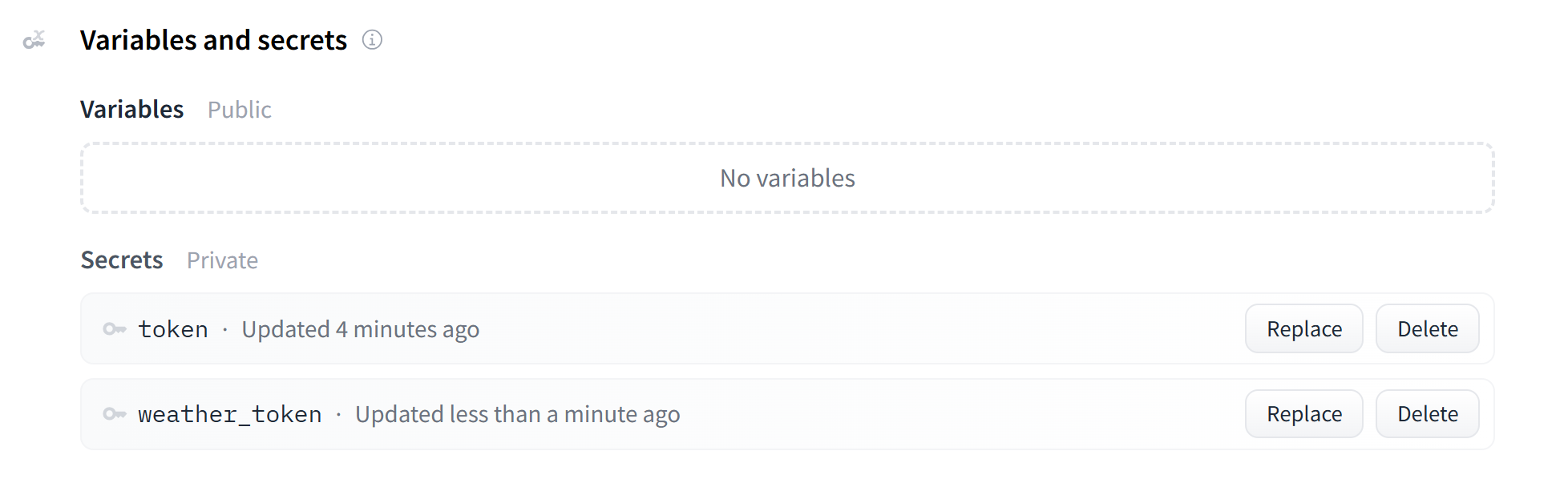
然后点击 Save 就保存好你的密钥了。
你可能会问为什么用 Secret 不用 Variable 呢,我们根据 huggingface 的官方文档 Spaces Overview 的解释
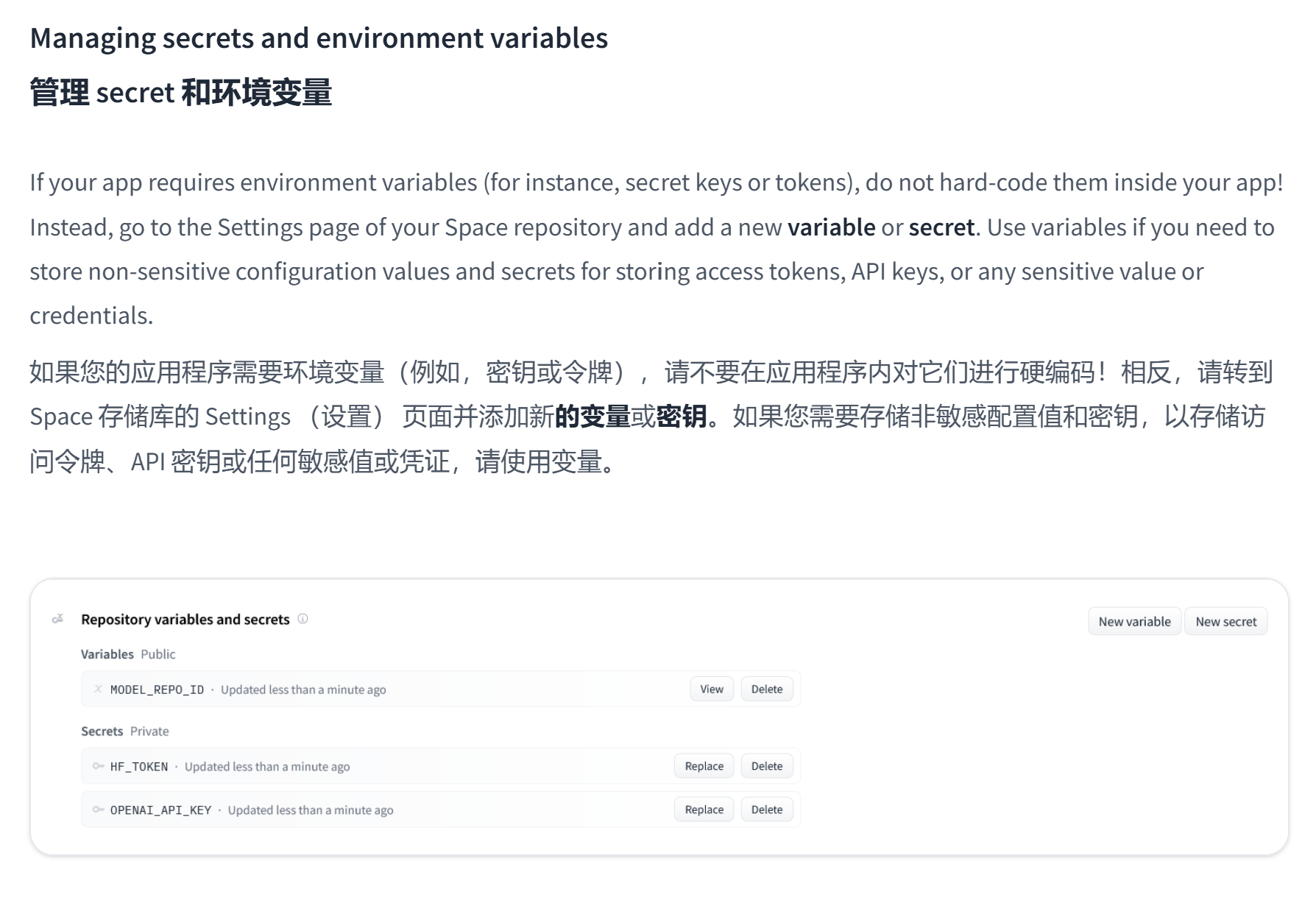

 虽然根据官方文档的描述,Secret 比 Variable 更保险,
虽然根据官方文档的描述,Secret 比 Variable 更保险, Spaces Secrets Scanner 会对 os.getenv() 方法报警,但从下面的小实验中可以看到,在 streamlit 页面中两者其实并无区别(当然官方文档也提到了:For Streamlit Spaces, secrets are exposed to your app through Streamlit Secrets Management, and public variables are directly available as environment variables)
首先我们创建一个 Variable 做对比
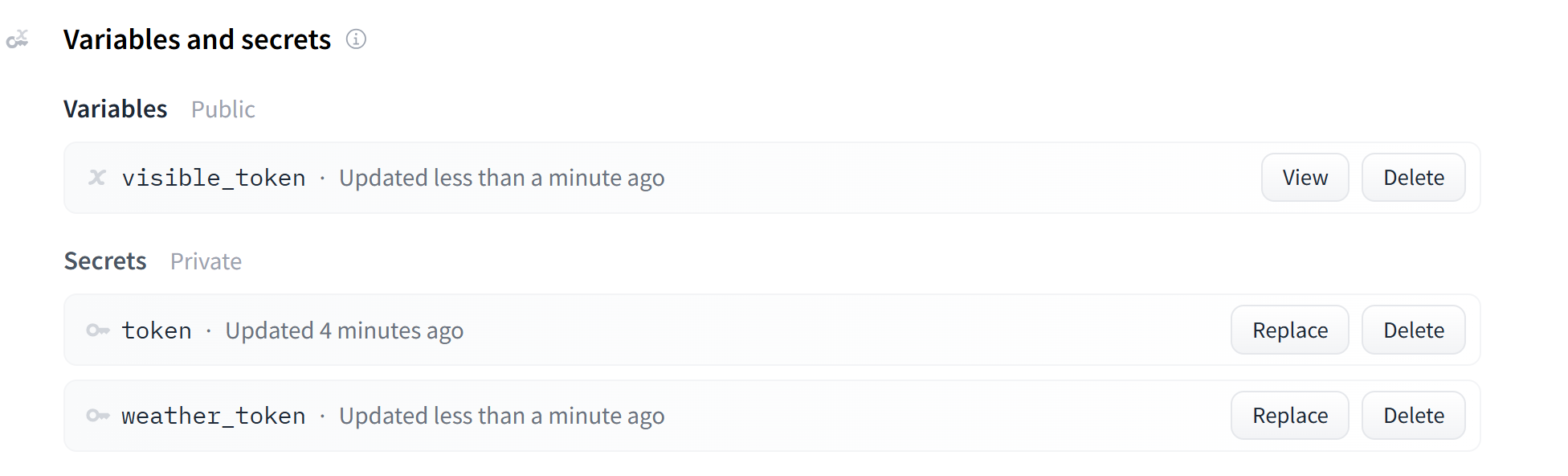
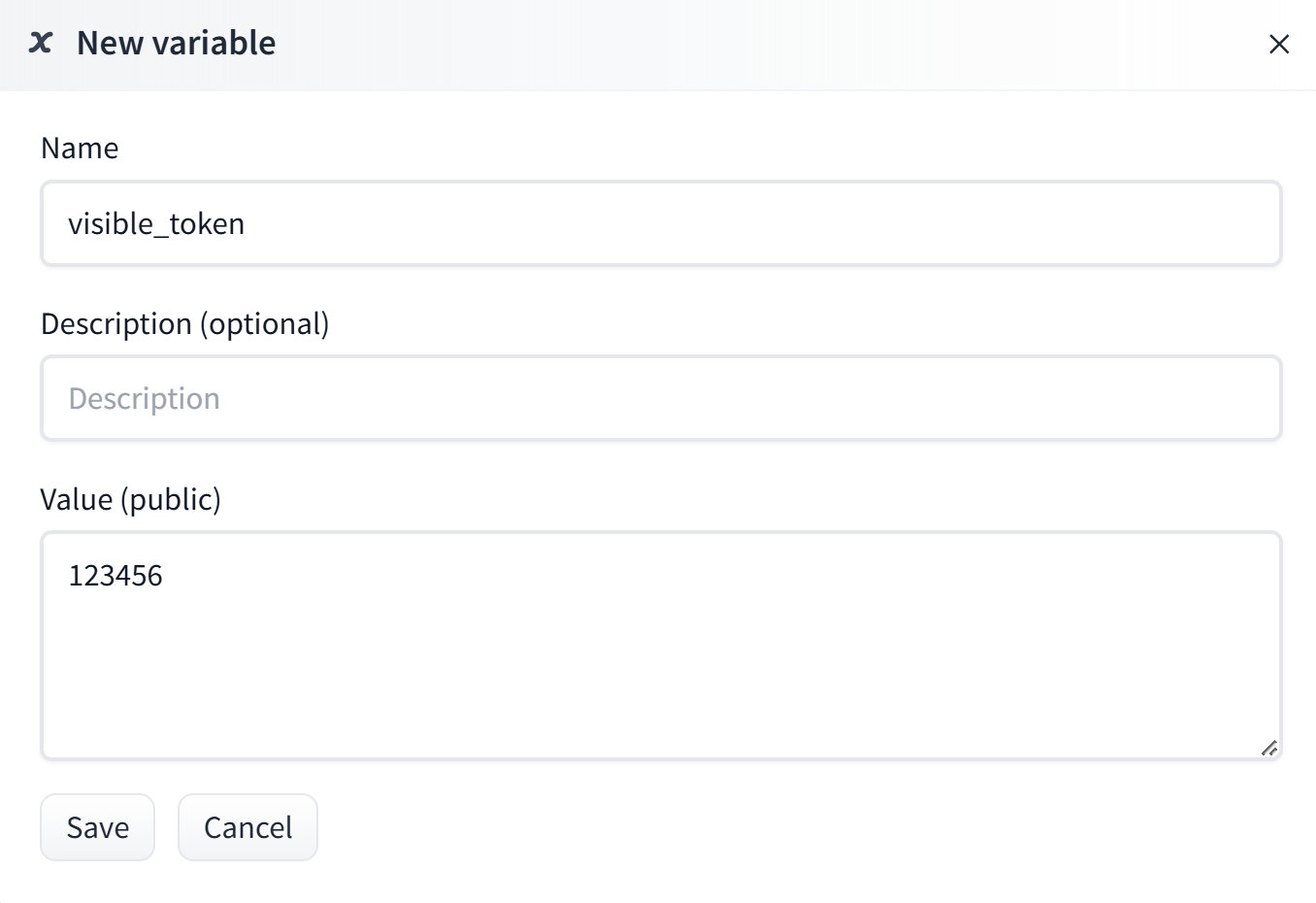 然后我们现在就有三个环境变量了
然后我们现在就有三个环境变量了
 我们用下面这段代码测试,这三个环境变量是否可见,先测试 Variable
我们用下面这段代码测试,这三个环境变量是否可见,先测试 Variable
import streamlit as st
import os
# 获取环境变量
visible_token = os.getenv('visible_token')
# 创建Streamlit页面
st.title('环境变量展示')
# 显示环境变量
st.write('visible_token:', visible_token)
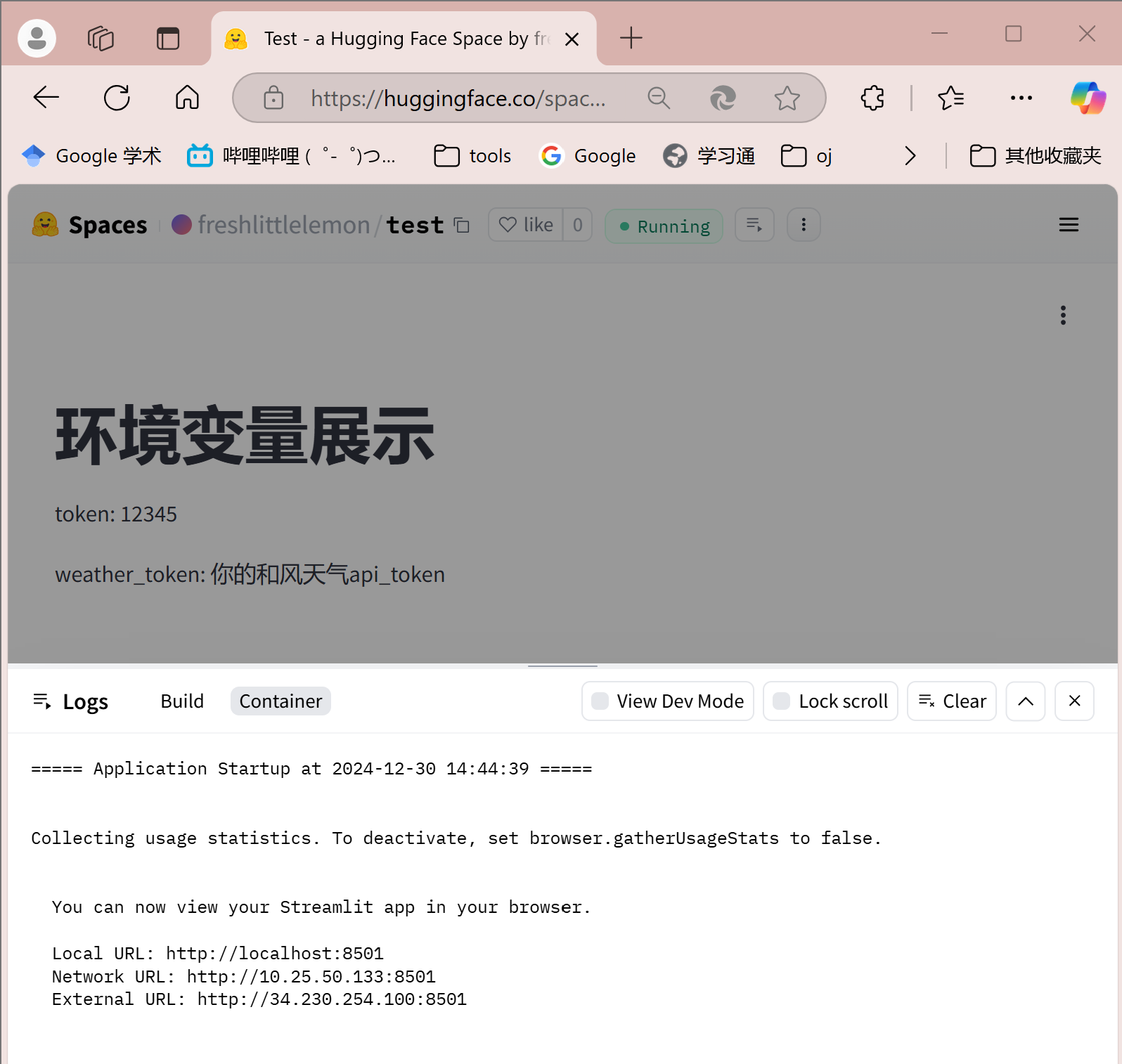
可以看到,就这么水灵灵的就暴露出来了 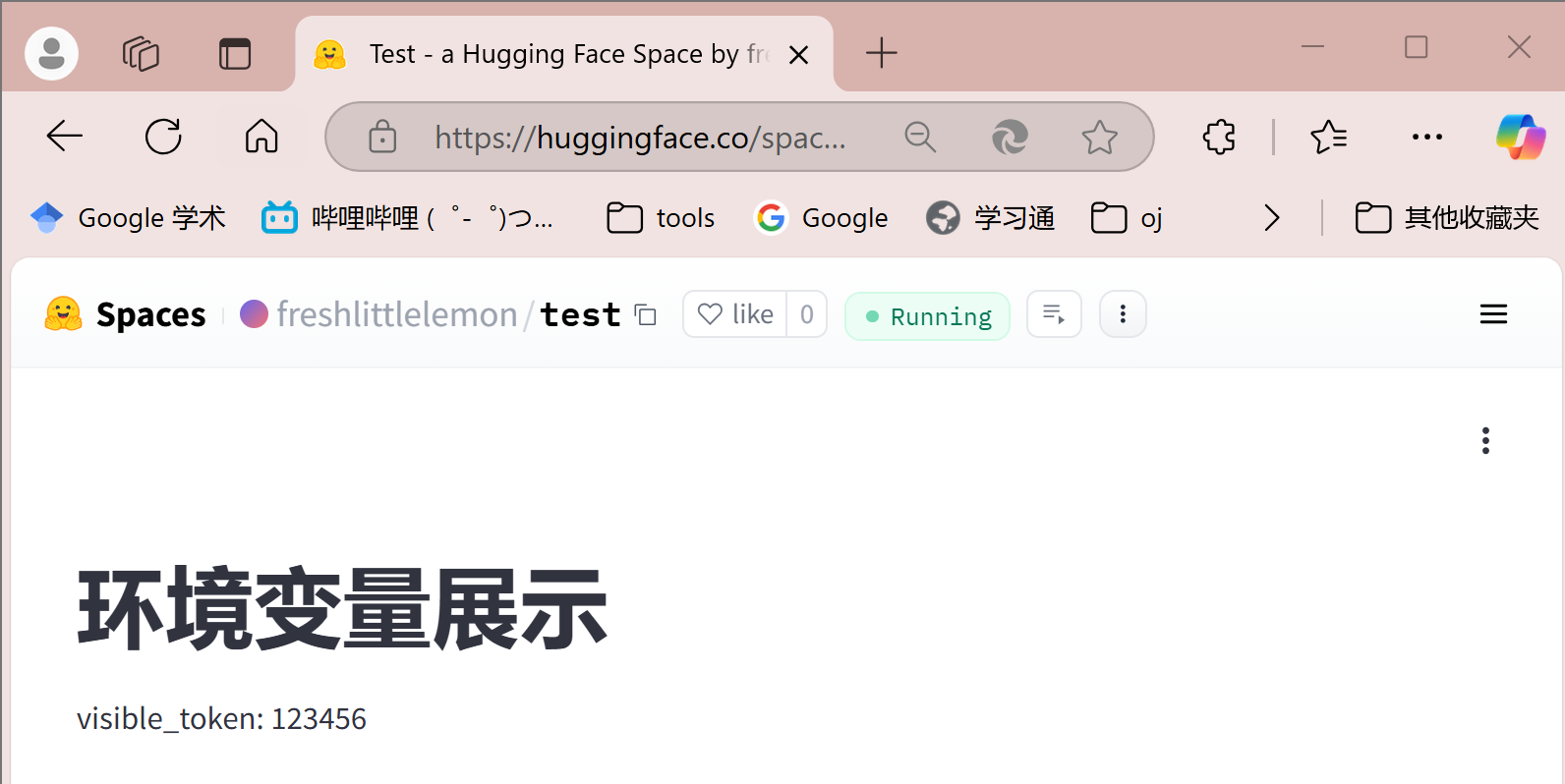 那么 Secret 呢
那么 Secret 呢
import streamlit as st
import os
token = os.getenv('token')
weather_token = os.getenv('weather_token')
st.title('环境变量展示')
st.write('token:', token)
st.write('weather_token:', weather_token)
很遗憾,仍然是可以暴露的
 但可不可以用呢,答案是放心用,没问题的,因为只要你不傻傻地自己写代码暴露 api 别人是没办法获取你写在 Huggingface Spaces 环境变量中的 api_token 的,所以放心大胆的使用就好了。当然如果你对这种办法有些膈应,觉得可能有暴露的风险,或者单纯不想让别人用你的 api,我们下面将介绍另一种方法来解决这个问题。
但可不可以用呢,答案是放心用,没问题的,因为只要你不傻傻地自己写代码暴露 api 别人是没办法获取你写在 Huggingface Spaces 环境变量中的 api_token 的,所以放心大胆的使用就好了。当然如果你对这种办法有些膈应,觉得可能有暴露的风险,或者单纯不想让别人用你的 api,我们下面将介绍另一种方法来解决这个问题。
首先因为 Huggingface Spaces在初始化时需要提供 python 环境的清单,因此我们修改 /root/agent_camp4/lagent/requirements.txt ,在其中添加如下 python 包
torch==2.1.2
torchvision==0.16.2
torchaudio==2.1.2
termcolor==2.4.0
streamlit==1.39.0
class_registry==2.1.2
datasets==3.1.0
griffe==0.48.0
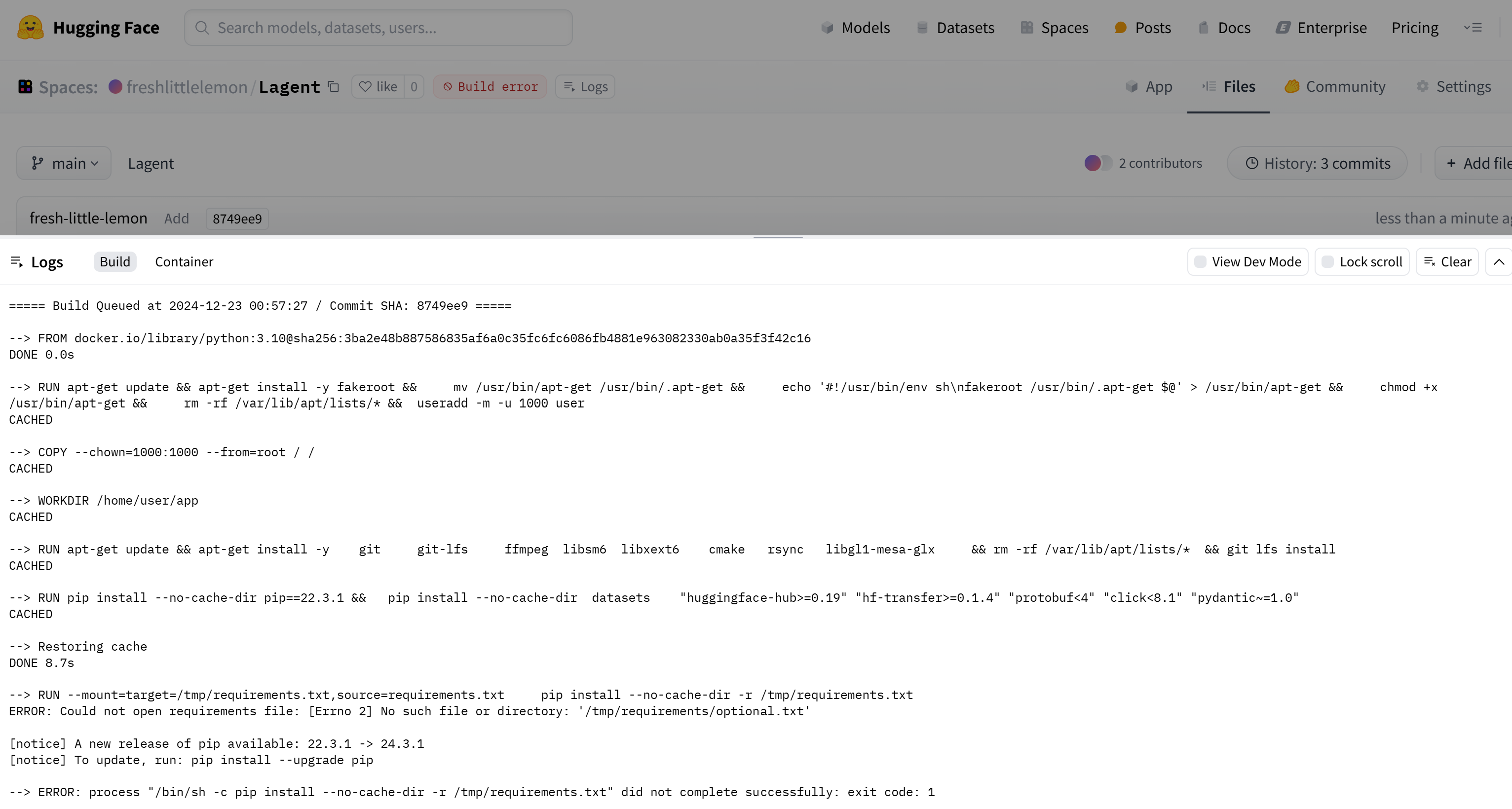
不过实测发现 huggingfaces 上的 docker 找不到 requirements/optional.txt 和 requirements/runtime.txt
我们将其手动添加至 requirements.txt 中,拷贝下面这段代码:
torch==2.1.2
torchvision==0.16.2
torchaudio==2.1.2
termcolor==2.4.0
streamlit==1.39.0
class_registry==2.1.2
datasets==3.1.0
# -r requirements/optional.txt
google-search-results
lmdeploy>=0.2.5
pillow
python-pptx
timeout_decorator
torch
transformers>=4.34,<=4.40
vllm>=0.3.3
# -r requirements/runtime.txt
aiohttp
arxiv
asyncache
asyncer
distro
duckduckgo_search==5.3.1b1
filelock
func_timeout
griffe<1.0
json5
jsonschema
jupyter==1.0.0
jupyter_client==8.6.2
jupyter_core==5.7.2
pydantic==2.6.4
requests
termcolor
tiktoken
timeout-decorator
typing-extensions
griffe==0.48.0
由于 Huggingface Spaces 要求 file 中必须有一个名称为 app.py 的文件,否则会出现 No application file 错误。
我们当然可以把 agent_api_web_demo.py 和 multi_agents_api_web_demo.py 更名为 app.py,然而考虑到这两个页面文件会调用到其他代码,我们又不希望把时间浪费在找依赖上,于是我们直接在 agent_camp4/lagent 文件夹下做一个 app.py 的入口文件当作 HomePage,编写一个多页面的 streamlit 首页实现对天气查询小助手和博客写作小助手两个 agent 的导航,代码如下(我们这里采用代码写入环境变量的方式,这样子别人来访问的时候可以不用消耗你自己的 api_token,而是让他们自己填写)
import streamlit as st
import os
import runpy
st.set_page_config(layout="wide", page_title="My Multi-Page App")
def set_env_variable(key, value):
os.environ[key] = value
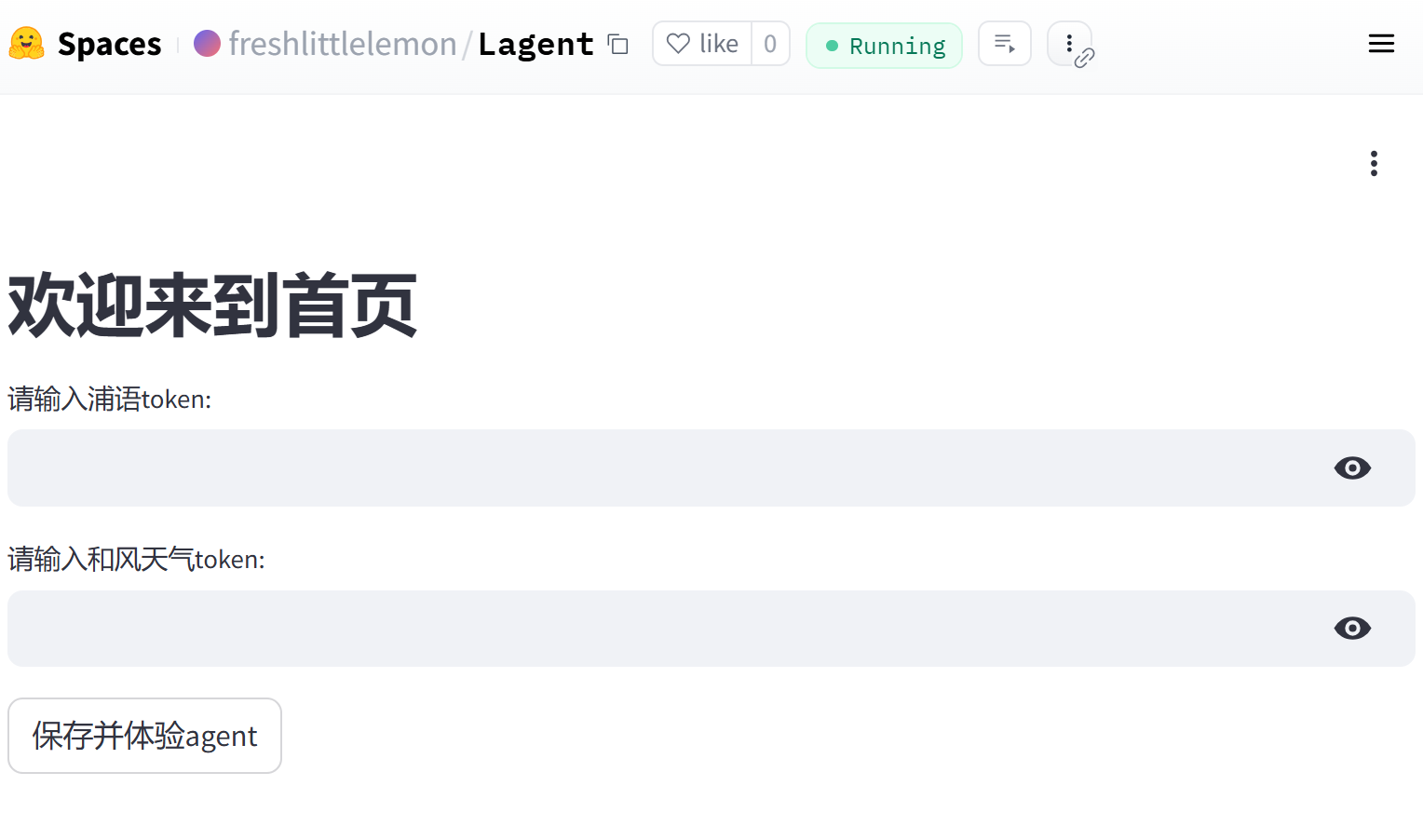
def home_page():
st.header("欢迎来到首页")
# 设置输入框为隐私状态
token = st.text_input("请输入浦语token:", type="password", key="token")
weather_token = st.text_input("请输入和风天气token:", type="password", key="weather_token")
if st.button("保存并体验agent"):
if token and weather_token:
set_env_variable("token", token) # 设置环境变量为 'token'
set_env_variable("weather_token", weather_token) # 设置环境变量为 'weather_token'
st.session_state.token_entered = True
st.rerun()
else:
st.error("请输入所有token")
if 'token_entered' not in st.session_state:
st.session_state.token_entered = False
if not st.session_state.token_entered:
home_page()
else:
# 动态加载子页面
page = st.sidebar.radio("选择页面", ["天气查询助手", "博客写作助手"])
if page == "天气查询助手":
runpy.run_path("examples/agent_api_web_demo.py", run_name="__main__")
elif page == "博客写作助手":
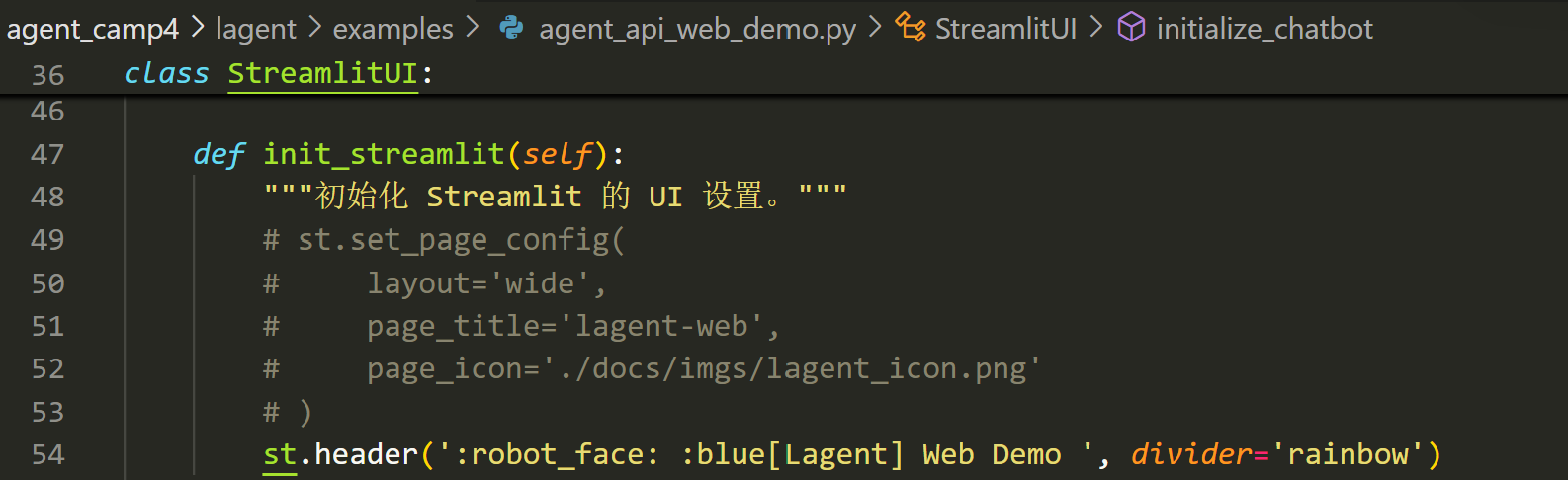
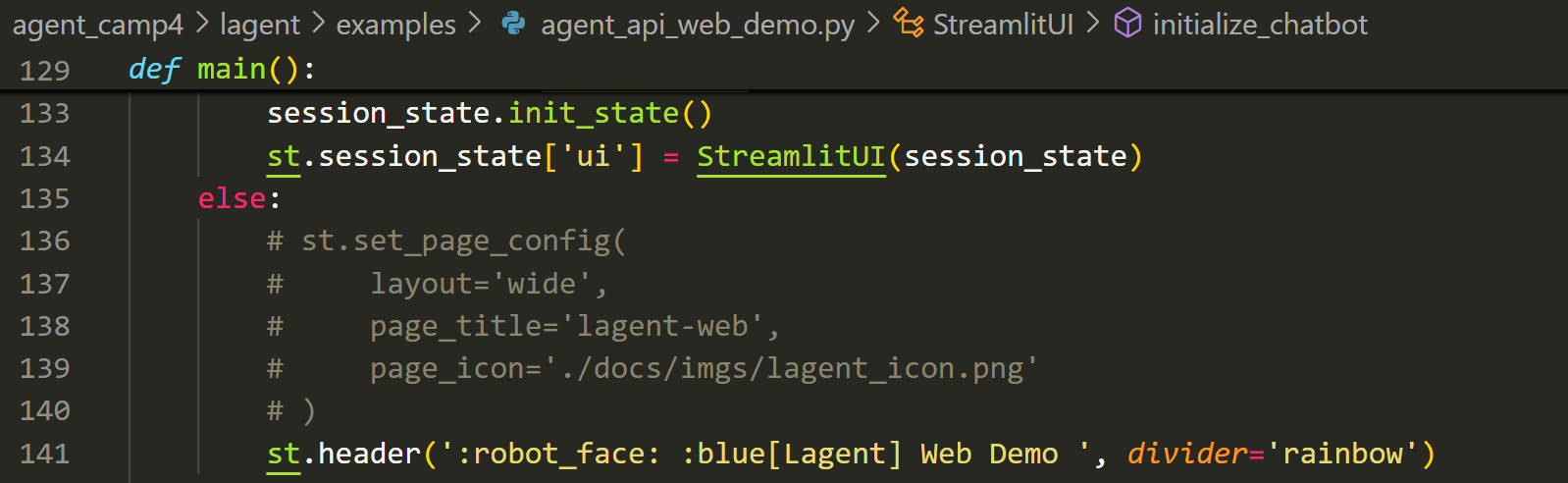
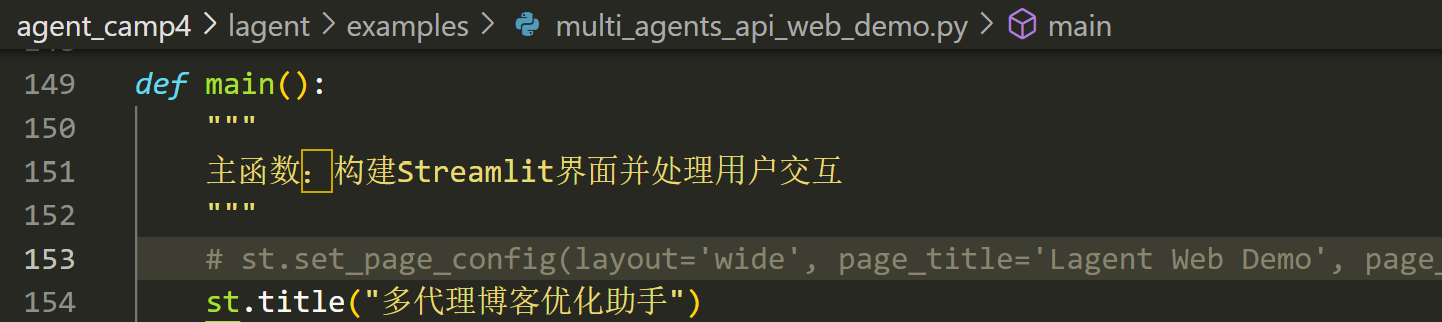
runpy.run_path("examples/multi_agents_api_web_demo.py", run_name="__main__")此外由于 streamlit 要求一个页面内只能有一个 st.set_page_config() 函数,因此需要把 agent_api_web_demo.py 和 multi_agents_api_web_demo.py 中的相应代码注释掉,不然会报错
agent_api_web_demo.py 第 49~53 行和第 136~140 行
multi_agents_api_web_demo.py 第 153 行
然后我们就可以将 agent_camp4/lagent 文件夹下需要的文件用 rsync 全都拷贝到自己新建的 huggingface Spaces 仓库下了(注意!由于 git 文件和 README 中有仓库的配置信息,一定要警惕不能被覆盖掉,保持原来的就行,然后别忘了把 {your_huggingface_name} 替换成自己的 huggingface 用户名)
git clone https://hf-mirror.com/spaces/{your_huggingface_name}/Lagent
cd Lagent/
rsync -av -o -t --exclude='.git*' --exclude='README.md' /root/agent_camp4/lagent/ /root/Lagent/
git add .
git commit -m "Add files"
git push
这样我们就在 huggingface 上部署成功了~~