人工智能主要分为三个学派:
连接学派,模拟人大脑的工作过程
控制学派,模拟人工作的策略
表示学派,模拟人的知识组织结构
其中,连接学派在近年发展迅速,代表为深度学习。
深度学习同时也为控制学派和表示学派带来了深远影响
其中控制学派表现为强化学习
表示学派表现为知识图谱
在本文中,主要关注深度学习
深度学习的基本问题是:学习一个由x到y的映射f
如果y是连续向量,则为回归问题
如果y是离散值,则为分类问题
如果y是随机变量,则为生成问题
为了学习这个映射f,首先要准备好一个映射库
然后依据大量的数据,从映射库中搜索最接近目标映射f的假设h
这个搜索方法往往称为机器学习算法

在寻找目标函数这一基本问题下,又有三个子问题:
容量问题、收敛问题和优化问题
早期机器学习算法非常关注的一个问题是容量
即要从函数库中搜索合适的目标函数,前提是函数库中要包含目标函数
这里不得不提到上世纪八十年代提出的人工神经网络算法
神经网络算法是目前所有深度学习算法的基础
由于网上教程过多,所以不对算法细节赘述
神经网络有三个要点:
-
将目标函数的搜索过程转化为损失函数的优化问题
这是判别式机器学习算法的一个重要特点
即先设定合适的损失函数,然后通过梯度下降算法
搜索使损失函数最小的函数
-
反向传播
反向传播算法是梯度下降算法在多层网络结构中的实现算法
反向传播使网络中的每个运算只需考虑自身的前向和后向运算
而不需要考虑和其他op之间的联系
这不仅简化了计算而且简化了神经网络的实现
-
普适逼近定理
神经网络采用全连接的结构,配合非线性的激活函数
可以通过普适逼近原理证明,在隐藏层神经元足够多的情况下,神经网络可以拟合任意函数
神经网络在理论上似乎已经解决了容量问题
但实验中发现,一味增加隐藏层个数是非常低效的:
大幅增加了计算难度,容量提高却有限,还增加了陷入局部最优的风险
而更加有效的方式是增加神经网络的深度
限于当时的硬件条件,深度神经网络直到2006年才取得了实质性进展
假设增加神经网络的深度可以有效提高网络的容量
下一个问题是,如何在大容量的模型中,收敛到loss的最低点
这里将这个问题称为收敛问题
造成收敛困难主要有两个因素:梯度消失/爆炸 和 局部最优
梯度爆炸/消失主要由激活函数引起
激活函数几乎分布在每一层网络中
根据链式法则,在计算网络的底层的梯度时
都会乘以若干次激活函数的梯度
如果激活函数的梯度在0到1之间,那么网络越深,梯度会越消失
如果激活函数的梯度在1以上,那么网络越深,梯度会越爆炸
针对这两个问题,有如下关键技术
-
optimizer
优化器(optimizer)是指在梯度下降算法的基础上提出的改进算法
主要有两个改进方向:提高收敛速度,自适应学习率
这篇博客基于Sebastian Ruder的论文对优化器有一个不错的总结,作者是”郭耀华“

-
Batch normalization + ReLU
批归一化(BN)可以抑制梯度爆炸/消失并加快训练速度
原论文认为批归一化的原理是:通过归一化操作使网络的每层特征的分布尽可能的稳定,从而减少Internal Covariate Shift(更详细的内容可以参考”天雨粟“的专栏文章)
relu是目前应用最为广泛的激活函数,
由于其梯度要么是1,要么是0,可以有效抑制梯度爆炸/消失
通过BN和ReLU,目前的网络已经可以达到非常深
(记得17年商汤弄了一个一千多层的卷积神经网络,供测试性能用)
-
残差结构
2015年,ResNet的提出基本给经典的图像识别问题画上了句号
而ResNet提出的残差结构,则被广泛的应用在各类网络模型中
ResNet解决了一个典型的优化问题:网络越深,并不一定效果越好(不是过拟合)
网络越深,提取的特征往往越抽象,过渡抽象的特征可能并不适合相对简单的任务
举一个并不特别恰当的例子:
我可以从鼻子,眼睛,眉毛这些特征认出一个人,
但是很难根据毛孔的大小,眼睫毛的长短这些特征去识别一个人
为了解决这个问题,ResNet设计了short cut结构,
short cut可以保证深层网络的输出有能力和浅层网络的输出相一致
从而保证了过深的网络不会发生劣化
假设深度学习网络可以收敛到全局的最优点
是否全局最优点就是我们想要的结果?
事实上,全局最优往往意味着严重的过拟合
我们真正需要学习的,是一个“适度”的点
“适度”体现了深度学习的玄学性质
暂没有理论能够严格解释究竟什么叫做“适度”
但可以通过下图定性的理解一下“适度”的含义
假设学习一个映射$$f(\theta)$$且只有一个参数
可以看到 loss最低时并不是所要的最优点
而loss的值比较适中时,也不一定是loss的最优点(同一个loss值对应多个$$\theta$$,但只有一个是目标点)
所以“适度”的关键是loss下降的方向比较合适,选的“坑”比较合适
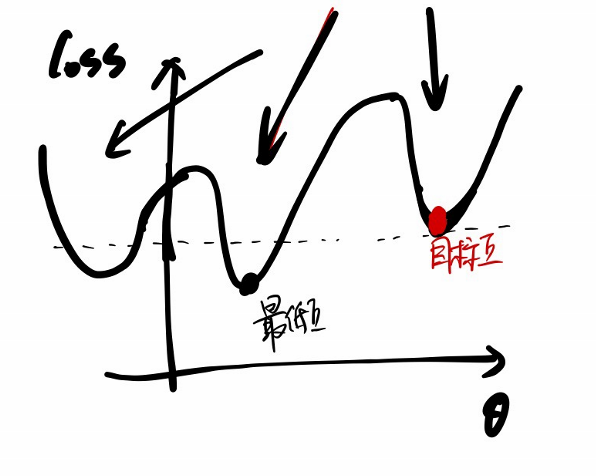
这里将如何“寻找合适的下降方向”的问题称作优化问题
优化问题目前主要靠优化网络结构来解决
-
CNN RNN 以及 GNN
卷积神经网络(CNN)特别适合处理矩阵数据,比如图像。
CNN中的卷积实际可以看作图像处理中的滤波器,可以有效提取图像特征
而卷积神经网络这种由局部到全局,逐层提取特征的模式,也非常符合人的观察习惯
所以卷积神经网络本身就带着一种“方向”,而不是杂乱无章的搜索
同样道理,循环神经网络 (RNN) 适合处理序列数据,比如文本和语音
RNN(主要是指LSTM)会有选择的记忆序列之中的数据,
就像人去处理文本时,会观察前后文并记录重点信息一样
所以循环神经网络本身也带着一种特定的搜索“方向”
图神经网络(GNN)是用来处理图类型的数据的
目前刚刚起步,不过有广泛的应用前景
我们可以从这几种主流网络结构中看出:不同数据适合于不同的网络结构
这并不是说传统的全连接神经网络没有办法处理图像、文本或者图
而是特定的网络结构处理对应的数据更加合适,更有方向性,更有助于网络的优化
-
attention
attention指的是注意力机制
2018年,Bert的横空出世让注意力机制站到了和卷积几乎并行的平台上
让人们开始怀疑RNN存在的必要性
注意力机制也是模仿人观察事物的方式
让网络更加侧重数据中感兴趣的部分,给感兴趣的部分提供更加高的权重
显然,有没有注意力机制并不会影响网络的容量,改变的是网络的搜索方向
关于attention的更多细节可以参考”attention is all you need“这篇论文
或者苏剑林的这篇博客
-
多层级联
深度学习领域非常流行一个概念:端到端
其基本思路是将传统机器学习算法的各个模块依次替换成深度学习网络
组成一个端到端的级联网络,这样可以整体训练,整体优化
比如检测网络(faster rcnn)由区域检测网络(rpn)和识别网络(rcnn)级联而成
这种级联的方式使网络结构蕴含着一种”方向“
即网络应该先挑出一些候选框,然后再识别
-
对抗网络
生成网络的目的是对随机变量施加变换以拟合一个分布
分布之间的距离往往用散度来表示
但是直接用散度作为损失函数是难以训练的(由于散度是通过采样进行计算的,散度几乎为零)
生成对抗网络非常巧妙的解决了这个问题
它将网络分成生成网络和判别网络两个部分
生成网络负责模仿样本数据,判别网络负责区分生成数据和真实数据
两个网络相互对抗,最终收敛
可以证明,原始的GAN网络的损失等效于最小化JS散度

深度学习算法基于一个并不十分准确的假设:将目标函数的搜索问题等价于目标函数的最小化问题
以至于做需要大量的结构优化工作去修正假设和真实情况之间的差距
我认为,这些结构优化工作只是一种权益之计,
无论是CNN,还是RNN,还是attention,它们本质上都在做一件事情:缩小搜索的范围
而也许只有两种办法可以从根本解决问题:更多的数据,更强的算力
深度学习的下一波繁荣,可能与计算的下一波革命以及数据的长期积累有关