OneFlow Eager自动量化调研和思考 #88
Description
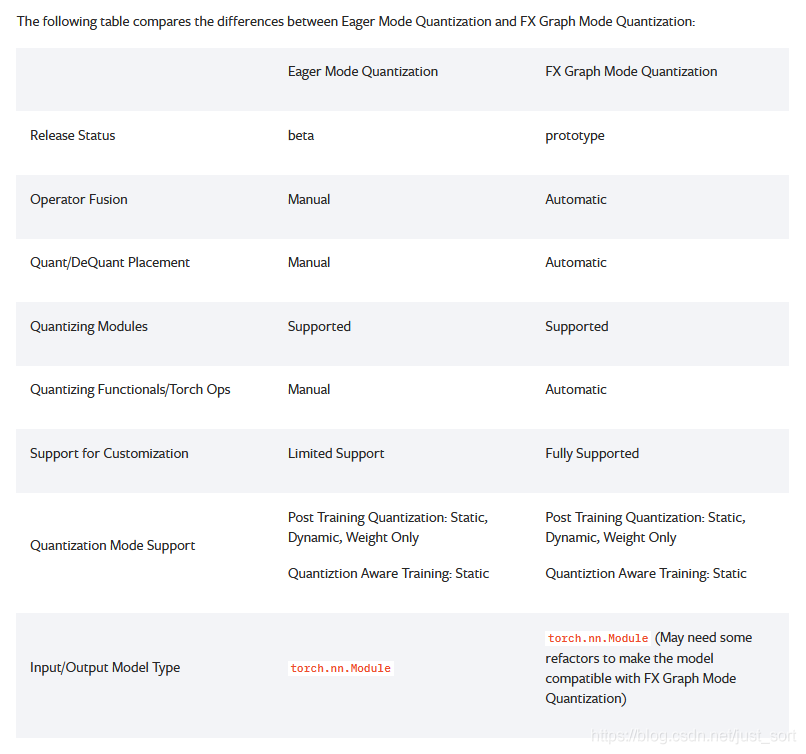
- 调研报告主要参考了这篇Pytorch的官方文档:https://pytorch.org/docs/1.9.0/quantization.html 。Pytorch第一代量化叫作Eager Mode Quantization,然后从1.8开始推出FX Graph Mode Quantization。Eager Mode Quantization需要用户手动更改模型,并手动指定需要融合的Op。FX Graph Mode Quantization解放了用户,一键自动量化,无需用户修改模型和关心内部操作。这个改动具体可以体现在下面的图中。
下面以一段代码为例解释一下Pytorch这两种量化方式的区别。
Eager Mode Quantization
class Net(nn.Module):
def __init__(self, num_channels=1):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 40, 3, 1)
self.conv2 = nn.Conv2d(40, 40, 3, 1)
self.fc = nn.Linear(5*5*40, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.reshape(-1, 5*5*40)
x = self.fc(x)
return xPytorch可以在Module的foward里面随意构造网络,可以调用Module,也可以调用Functional,甚至可以在里面写If这种控制逻辑。但这也带来了一个问题,就是比较难获取这个模型的图结构。因为在Eager Mode Quantization中,要量化这个网络必须做手动修改:
class NetQuant(nn.Module):
def __init__(self, num_channels=1):
super(NetQuant, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 40, 3, 1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(40, 40, 3, 1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(5*5*40, 10)
self.quant = torch.quantization.QuantStub()
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.relu1(self.conv1(x))
x = self.pool1(x)
x = self.relu2(self.conv2(x))
x = self.pool2(x)
x = x.reshape(-1, 5*5*40)
x = self.fc(x)
x = self.dequant(x)
return x也就是说,除了Conv,Linear这些含有参数的Module外,ReLU,MaxPool2d也要在__init__中定义,Eager Mode Quantization才可以处理。
除了这一点,由于一些几点是要Fuse之后做量化比如Conv+ReLU,那么还需要手动指定这些层进行折叠,目前支持ConV + BN、ConV + BN + ReLU、Conv + ReLU、Linear + ReLU、BN + ReLU的折叠。
model = NetQuant()model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
modules_to_fuse = [['conv1', 'relu1'], ['conv2', 'relu2']] # 指定合并layer的名字
model_fused = torch.quantization.fuse_modules(model, modules_to_fuse)
model_prepared = torch.quantization.prepare(model_fused)
post_training_quantize(model_prepared, train_loader) # 这一步是做后训练量化
model_int8 = torch.quantization.convert(model_prepared)整个流程比较逆天,不知道有没有人用。
FX Graph Mode Quantization
由于 FX 可以自动跟踪 forward 里面的代码,因此它是真正记录了网络里面的每个节点,在 fuse 和动态插入量化节点方面,比 Eager 模式强太多。对于前面那个模型代码,我们不需要对网络做修改,直接让 FX 帮我们自动修改网络即可:
from torch.quantization import get_default_qconfig, quantize_jit
from torch.quantization.quantize_fx import prepare_fx, convert_fx
model = Net()
qconfig = get_default_qconfig("fbgemm")
qconfig_dict = {"": qconfig}
model_prepared = prepare_fx(model, qconfig_dict)
post_training_quantize(model_prepared, train_loader) # 这一步是做后训练量化
model_int8 = convert_fx(model_prepared)但目前FX似乎还无法处理控制流问题,但无伤大雅,大多数经典模型的定义中不存在控制流,并且Pytorch也在计划支持中。
思考
目前我已经完成了一些量化组件的构造,比如Conv,Linear,Conv+ReLU等等,但目前搭建模型的方案和Eager Mode Quantization类似需要用户来手动操作,这是不可以接受的,所以需要探索如何做自动量化。
我想了一种办法,基于Hook技术,通过构建 Hook 类, 重写 op, 并替换原 op 操作来获取foward过程中的所有的可能调用的API,现在实现了一个native版本:
import oneflow as flow
import oneflow.F as F
import oneflow.nn as nn
class Net(nn.Module):
def __init__(self, num_channels=3):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 40, 3, 1)
self.conv2 = nn.Conv2d(40, 40, 3, 1)
self.pool1 = nn.MaxPool2d(2, 2)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(5*5*40, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.pool2(x)
x = x.reshape((-1, 5*5*40))
x = self.fc(x)
return x
res = []
class Hook(object):
hookInited = False
def __init__(self,raw,replace,**kwargs):
self.obj=replace
self.raw=raw
def __call__(self,*args,**kwargs):
if not Hook.hookInited:
return self.raw(*args,**kwargs)
else:
out=self.obj(self.raw,*args,**kwargs)
return out
def _conv2d(raw,inData, weight, bias=None, stride=1, padding=0, dilation=1, groups=1):
x=raw(inData,weight,bias,stride,padding,dilation,groups)
res.append(raw)
return x
def _max_pool2d(raw,inData, kernel_size, stride, padding, padding_before,
padding_after, channels_first, ceil_mode):
x = raw(inData, kernel_size, stride, padding, padding_before, padding_after, channels_first, ceil_mode)
res.append(raw)
return x
def _relu(raw, inData, inplace=False):
x = raw(inData,False)
res.append(raw)
return x
def _reshape(inData, *args):
x=raw_reshape(inData, *args)
res.append(raw_reshape)
return x
F.conv2d = Hook(F.conv2d,_conv2d)
F.max_pool_2d = Hook(F.max_pool_2d, _max_pool2d)
F.relu = Hook(F.relu,_relu)
for t in [flow.Tensor]:
raw_reshape = t.reshape
t.reshape = _reshape
import numpy as np
net = Net()
Hook.hookInited = True
input = flow.Tensor(np.random.random((1, 3, 26, 26)))
output = net.forward(input)
Hook.hookInited = False
for x in res:
try:
print(x.func_name)
except:
pass输入如下:
conv2d
relu
conv2d
relu可以看到通过Hook拿到了fowward中通过flow.F定义的所有Op,基于这种思路或许可以做一个自动量化的API出来。