Extended vox format not supported #6
Comments
|
@destrosvet I ran into the same issue. It's because the file format of MagicaVoxel has undergone some revisions to allow for a world editor and this importer doesn't know how to handle that data. Additionally the old material data chunks were deprecated and a new MATL chunk is being used. A workaround I used was to google for an older version of MagicaVoxel with a compatible file version. |
|
Apologies for the delayed response. Current solution would be as @atomhax suggests; using an old version of MagicaVoxel, until I get around to updating this importer. |
|
@destrosvet, could you please attach a sample data that you can't load? Thanks for your help |
|
About new releases chunks, we have: nTRN, nGRP, nGRP, nSHP, rOBJ, LAYR, MATL @destrosvet, @atomhax, just to "skip" them and keep loading new VOX files (here there is an example using them chr_sword NEW.zip): Right before the "throw an error if unknow chunk" part: |
|
Sample data, for example: chr_sword NEW.zip Parser snippet for new chunks (just some random thoughts to keep track of them): As usual, in main loop: p.s. is it possible to change the issue title? |
|
Fantastic work so far 👏 I have updated issue title. |
|
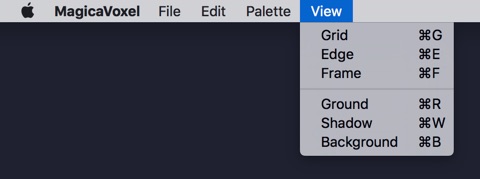
Always for the "random thoughts" series... about rOBJ chunk: I think MagicaVoxel uses them to store some additional data we can skip in Blender, e.g. View menu options? Rendering mode: path tracking renderer, camera, bloom and light info? Credits go to Interface · MagicaVoxel User Reference Manual |
|
Oh wow. I'm happy for all that detail to be skipped, though I suppose there is the possibility of including them in the future. The ground color, lighting, and camera position all jump out to me as something potentially useful. These would be fairly easy to replicate in Blender too, I would imagine. |
|
Yeah, but my doubt is: Is it better to work with overall scene setup, animations, camera, lights, global parameters (like fov, fog, ...) directly in Blender, after importing objects I mean, or in MagicaVoxel editor importing those settings? Anyhow, now we briefly know info about other chunks and we can handle them (or just skip) if needed. My personal opinion about new chunks (in some sort of "priority" order for next implementations):
Thanks again! |
|
Absolutely, I don't think they should be a priority in any sense. |
|
Starting from your Materials branch, I'm going to implement MATT and MATL here. Still immature for a pull request, but if you have time to review and give me some hints... especially, as I am not a Python programmer, I'm afraid of making mistakes. Have a nice weekend. Bye bye |
|
To supply "default values" to namedtuples, I defined a new class: |
|
That linked page is quite dated. Expanded out here, for the sake of commenting. |
|
Oh, thanks, very nice. But I read that tuples are "immutable", so I cannot modify values later. Here it is the full updated script: https://github.com/wizardgsz/MagicaVoxel-VOX-importer/blob/MATT_MATL/io_scene_vox.py Having That is: |
|
Hmm. Honestly, it might just be easier to use a bare dictionary, and forgo the namedtuple plan altogether. |
|
About MATT chunk and isTotalPower flag (property bit(7) set to 1): I just discovered that sometimes, but not always, MagicaVoxels adds 4 bytes for it! It is better to save current offset and skip entirely the chunk at the end: |
After import *.vox nothing happend and got "Unknown Chunk id nTRN" in console.
The text was updated successfully, but these errors were encountered: