B=torch.arange(24).reshape(4,3,2) B 如何理解B.sum(axis=0)的计算过程
好的,我们来由浅入深地讲解 B.sum(axis=0) 的计算过程。这是一个在 PyTorch 和 NumPy 中都非常核心且常见的操作。
首先,我们创建并看一下你的张量 B。
为了更好地解释,我们先手动生成这个张量并展示其结构。
import torch
# 创建张量 B
B = torch.arange(24).reshape(4, 3, 2)B 是一个三维张量,其形状 (shape) 是 (4, 3, 2)。我们可以这样来形象化地理解它:
- 最外层 (axis=0): 有 4 个元素。你可以把它想象成一个书架,上面有4本书。
- 中间层 (axis=1): 每个元素 (每本书) 是一个 3x2 的矩阵。你可以把它想象成每本书有3行。
- 最内层 (axis=2): 每个矩阵的每一行有 2 个元素。你可以把它想象成每行有2个单词。
所以,B 的完整形态是这样的:
B =
[[[ 0, 1], # 第0个 3x2 矩阵
[ 2, 3],
[ 4, 5]],
[[ 6, 7], # 第1个 3x2 矩阵
[ 8, 9],
[10, 11]],
[[12, 13], # 第2个 3x2 矩阵
[14, 15],
[16, 17]],
[[18, 19], # 第3个 3x2 矩阵
[20, 21],
[22, 23]]]
在 PyTorch 或 NumPy 中,axis 参数指定了我们“沿着”哪个轴(维度)进行操作。
axis=0指的是第一个维度(最外层的维度)。在B中,这就是那个大小为 4 的维度。axis=1指的是第二个维度,即大小为 3 的维度(每个矩阵的“行”)。axis=2指的是第三个维度,即大小为 2 的维度(每个矩阵的“列”)。
执行 sum(axis=0) 的意思是:“消除”第 0 轴,并将该轴上的所有元素相加。
换一种更直观的说法:将所有 4 个 3x2 的矩阵,对应位置的元素相加。
我们可以把这 4 个矩阵拿出来,像做加法一样把它们对齐:
[ 0, 1]
[ 2, 3]
[ 4, 5]
+
[ 6, 7]
[ 8, 9]
[10, 11]
+
[12, 13]
[14, 15]
[16, 17]
+
[18, 19]
[20, 21]
[22, 23]
-----------------
= [?, ?]
[?, ?]
[?, ?]
现在我们来计算结果矩阵中每个位置的值:
- 位置 (0, 0):
0 + 6 + 12 + 18 = 36 - 位置 (0, 1):
1 + 7 + 13 + 19 = 40 - 位置 (1, 0):
2 + 8 + 14 + 20 = 44 - 位置 (1, 1):
3 + 9 + 15 + 21 = 48 - 位置 (2, 0):
4 + 10 + 16 + 22 = 52 - 位置 (2, 1):
5 + 11 + 17 + 23 = 56
计算完成后,我们得到一个新的二维张量(矩阵):
[[36, 40],
[44, 48],
[52, 56]]
观察其形状:
- 原张量
B的形状是(4, 3, 2)。 - 我们对
axis=0(大小为4的维度)进行了求和,所以这个维度被“压缩”掉了。 - 新张量的形状变成了
(3, 2)。
我们可以用代码验证一下:
import torch
B = torch.arange(24).reshape(4, 3, 2)
result = B.sum(axis=0)
print("计算结果:\n", result)
# tensor([[36, 40],
# [44, 48],
# [52, 56]])
print("结果的形状:", result.shape)
# torch.Size([3, 2])结果和我们的手动推导完全一致。
- 核心思想:
sum(axis=n)就是将张量在第n个维度上的所有元素进行相加,从而“消掉”这个维度。 - 类比:
B.sum(axis=0):将4个矩阵(“书本”)叠在一起做加法。B.sum(axis=1):在每个矩阵内部,将所有的“行”相加。结果形状会是(4, 2)。B.sum(axis=2):在每个矩阵内部,将所有的“列”相加。结果形状会是(4, 3)。
希望这个由浅入深的分解过程能帮助你彻底理解 sum 在多维张量上的操作!
那么如何理解B.sum(axis=1)呢
当然,我们继续用同样的方法来剖析 B.sum(axis=1)。
我们还是从这个熟悉的 (4, 3, 2) 张量开始:
B =
[[[ 0, 1], # 矩阵 0
[ 2, 3],
[ 4, 5]],
[[ 6, 7], # 矩阵 1
[ 8, 9],
[10, 11]],
[[12, 13], # 矩阵 2
[14, 15],
[16, 17]],
[[18, 19], # 矩阵 3
[20, 21],
[22, 23]]]
axis=0: "书架"的维度,包含4个矩阵。axis=1: 每个矩阵内部"行"的维度,包含3行。axis=2: 每个矩阵内部"列"的维度,包含2列。
执行 sum(axis=1) 的意思是:“消除”第 1 轴,并将该轴上的所有元素相加。
在我们 (4, 3, 2) 的例子中,axis=1 是那个大小为 3 的维度。这意味着,求和操作将会在这个维度上进行。
关键点:这个求和操作是独立地在 axis=0 的每一个元素上进行的。 也就是说,我们会分别对 矩阵 0、矩阵 1、矩阵 2 和 矩阵 3 进行内部的行求和。
我们可以把这个过程分解成 4 个独立的计算:
-
处理第一个矩阵 (索引0):
[[ 0, 1], [ 2, 3], [ 4, 5]]沿着
axis=1(行方向) 求和,意味着把这三行加起来:[0, 1] + [2, 3] + [4, 5] = [0+2+4, 1+3+5] = [6, 12] -
处理第二个矩阵 (索引1):
[[ 6, 7], [ 8, 9], [10, 11]]同样,把这三行加起来:
[6, 7] + [8, 9] + [10, 11] = [6+8+10, 7+9+11] = [24, 27] -
处理第三个矩阵 (索引2):
[[12, 13], [14, 15], [16, 17]]把这三行加起来:
[12, 13] + [14, 15] + [16, 17] = [12+14+16, 13+15+17] = [42, 45] -
处理第四个矩阵 (索引3):
[[18, 19], [20, 21], [22, 23]]把这三行加起来:
[18, 19] + [20, 21] + [22, 23] = [18+20+22, 19+21+23] = [60, 63]
现在,我们把这 4 个计算结果组合起来,就得到了最终的答案:
[[ 6, 12],
[24, 27],
[42, 45],
[60, 63]]
观察其形状:
- 原张量
B的形状是(4, 3, 2)。 - 我们对
axis=1(大小为3的维度)进行了求和,所以这个维度被“压缩”掉了。 - 剩下的维度是
axis=0(大小为4) 和axis=2(大小为2)。 - 新张量的形状变成了
(4, 2)。
用代码验证一下:
import torch
B = torch.arange(24).reshape(4, 3, 2)
result = B.sum(axis=1)
print("计算结果:\n", result)
# tensor([[ 6, 12],
# [24, 27],
# [42, 45],
# [60, 63]])
print("结果的形状:", result.shape)
# torch.Size([4, 2])结果和我们的手动推导完全一致。
B.sum(axis=0):跨矩阵相加。将4个矩阵像一叠纸一样拍扁,对应位置加起来。shape (4, 3, 2) -> (3, 2)。B.sum(axis=1):矩阵内行相加。对4个矩阵中的每一个,独立地将其内部的行向量加起来。shape (4, 3, 2) -> (4, 2)。
联网搜索下pytorch的sum函数是不是把keepdims改为keepdim了
您好!关于 PyTorch 中 sum 函数的参数,这是一个很好的问题,涉及到 PyTorch 版本迭代中的一些细节变化。
根据最新的 PyTorch 文档和社区讨论,torch.sum 函数现在使用的参数是 keepdim。
-
当前官方文档:目前的 PyTorch 官方文档中明确指出,用于在计算后保持维度不变的参数是
keepdim。 当keepdim设置为True时,输出张量的维度将与输入张量保持一致,只是被求和的维度大小变为 1。 如果设置为False(默认值),则会压缩这些维度。 -
历史沿革:
- 在 NumPy 中,对应的参数名是
keepdims(带 "s")。由于 PyTorch 在设计上很大程度借鉴了 NumPy,早期关于是否统一参数名的讨论是存在的。 - 在 2017 年的一些 GitHub 讨论中,有开发者提出为了与 NumPy 保持一致,应将
keepdim重命名为keepdims。 - 然而,从现有稳定的文档和用法来看,PyTorch 最终标准化了
keepdim(不带 "s") 作为其 reducción 操作(如sum,mean,max等)的官方参数。
- 在 NumPy 中,对应的参数名是
-
兼容性情况:
- 有趣的是,在一个 GitHub issue 的讨论中提到,
keepdims和keepdim在某些版本(如 1.7)中作为关键字都是有效的,但使用keepdims可能会在 JIT (Just-In-Time) 编译时出现问题。 - 这表明 PyTorch 为了向后兼容或用户习惯,可能在一段时间内同时接受了两种写法,但
keepdim是官方推荐和支持得更好的版本。
- 有趣的是,在一个 GitHub issue 的讨论中提到,
为了清晰地展示 keepdim 的作用,我们来看一个简单的例子。假设我们有一个 2x3 的张量,我们想沿着第 1 维(列方向)求和。
import torch
# 创建一个张量
x = torch.tensor([[1, 2, 3],
[4, 5, 6]])
# keepdim=False (默认情况)
# 求和后,维度被压缩,输出从 (2, 3) 变为 (2,)
sum_no_keepdim = torch.sum(x, dim=1, keepdim=False)
print(f"不使用 keepdim: {sum_no_keepdim}")
print(f"形状: {sum_no_keepdim.shape}\n")
# keepdim=True
# 求和后,维度被保留,输出从 (2, 3) 变为 (2, 1)
sum_with_keepdim = torch.sum(x, dim=1, keepdim=True)
print(f"使用 keepdim: \n{sum_with_keepdim}")
print(f"形状: {sum_with_keepdim.shape}")在这个例子中,keepdim=True 的输出形状是 [2, 1],这在进行广播(broadcasting)等后续计算时非常有用。
虽然您可能在一些旧的代码或讨论中看到过 keepdims,但在当前和未来的 PyTorch 版本中,您应当使用 keepdim。这是官方文档确认的、并且在 JIT 等高级功能中兼容性最好的标准参数。
pytorch中的AB 好像和线性代数课本上的那个AB不一样唉
你观察得非常仔细!你说得完全正确。在 PyTorch(以及 NumPy)中,A * B 所代表的运算和我们在线性代数课本上学到的标准矩阵乘法是两种不同的运算。
这是一个非常重要且常见的区分点,我们来深入解析一下。
这正是你图片里展示的运算,也是 PyTorch 中 * 运算符执行的操作。
- 数学名称: 哈达玛积 (Hadamard Product)。
- 数学符号: 通常用 ⊙ 表示,即 A ⊙ B。
- 运算规则: 两个形状(shape)完全相同的矩阵,对应位置的元素相乘,得到一个形状相同的新矩阵。
- PyTorch 实现:
- 使用
*运算符:A * B - 使用
torch.mul()函数:torch.mul(A, B)
- 使用
要求: 参与运算的两个张量(矩阵)A 和 B 必须具有相同的形状,或者是可以通过广播 (Broadcasting)机制变得形状兼容。
这是我们在线性代数中最常学习的矩阵乘法。
- 数学名称: 矩阵乘法 (Matrix Multiplication)。
- 数学符号: 通常直接写作 AB,或者用 ⋅ 表示 A ⋅ B。
- 运算规则: 对于矩阵 A (形状为
m x n) 和矩阵 B (形状为n x p),它们的乘积 C (形状为m x p) 中第i行第j列的元素是 A 的第i行与 B 的第j列对应元素的乘积之和。 - PyTorch 实现:
- 使用
@运算符:A @ B(这是 Python 3.5+ 推荐的现代写法) - 使用
torch.matmul()函数:torch.matmul(A, B) - 使用
torch.mm()函数:torch.mm(A, B)(注意:mm只适用于二维矩阵,而matmul更通用,可以处理更高维度的张量)。
- 使用
要求: 第一个矩阵的列数 (n) 必须等于第二个矩阵的行数 (n)。
让我们用 PyTorch 代码来清晰地展示这两者的区别。
import torch
# 1. 定义两个 2x2 的张量 (矩阵)
A = torch.tensor([[1, 2],
[3, 4]])
B = torch.tensor([[5, 6],
[7, 8]])
print("Tensor A:\n", A)
print("Tensor B:\n", B)
print("-" * 30)
# 2. 按元素乘法(Hadamard Product)
# 使用 * 运算符
C_element_wise = A * B
# 计算过程:
# [[1*5, 2*6],
# [3*7, 4*8]]
# 结果:
# [[ 5, 12],
# [21, 32]]
print("按元素乘法 (A * B):\n", C_element_wise)
print("torch.mul(A, B) 得到相同结果:\n", torch.mul(A, B))
print("-" * 30)
# 3. 矩阵乘法(Matrix Multiplication)
# 使用 @ 运算符
C_matrix_mul = A @ B
# 计算过程:
# [[1*5 + 2*7, 1*6 + 2*8], -> [[5 + 14, 6 + 16], -> [[19, 22],
# [3*5 + 4*7, 3*6 + 4*8]] -> [15 + 28, 18 + 32]] -> [43, 50]]
print("矩阵乘法 (A @ B):\n", C_matrix_mul)
print("torch.matmul(A, B) 得到相同结果:\n", torch.matmul(A, B))你可能会问,为什么在数据科学和深度学习库中,更简单的 * 符号被赋予了“哈达玛积”的含义,而不是更经典的“矩阵乘法”?
这主要是出于实用性的考虑。在神经网络的计算中,按元素的操作极其频繁。例如:
- 激活函数: 将激活函数(如 ReLU, Sigmoid)应用到一批数据上,本质上就是对矩阵中的每个元素独立进行运算。
- 应用遮罩 (Masking): 在自注意力机制 (Self-Attention) 或 Dropout 中,我们经常需要生成一个和数据形状相同的“遮罩”矩阵(由0和1组成),然后通过按元素相乘来“关闭”或“保留”某些神经元的输出。
- 梯度更新: 在优化算法中,梯度是一个与参数形状相同的张量,我们用学习率(一个标量)乘以梯度(通过广播机制的按元素乘法)来更新参数。
这些按元素的操作构成深度学习计算的基石,因此,为它们分配最简洁的 * 运算符,可以使代码更简洁、直观。而更为专业的线性代数矩阵乘法,则使用一个专门的 @ 运算符来表示,避免混淆。
为了方便你记忆,这里有一个快速参考的表格:
| 特性 | 按元素乘法 (Element-wise) | 矩阵乘法 (Matrix Multiplication) |
|---|---|---|
| 数学名称 | 哈达玛积 (Hadamard Product) | 矩阵乘积 (Matrix Product) |
| PyTorch 运算符 | * |
@ |
| PyTorch 函数 | torch.mul() |
torch.matmul(), torch.mm() |
| 运算规则 | 对应位置元素相乘 | 行与列的点积 |
| 形状要求 | 形状相同 (或可广播) | A的列数 == B的行数 |
| 常见用途 | 应用遮罩、激活函数、特征融合 | 线性变换 (如全连接层)、坐标变换 |
总之,你的发现非常关键。在 PyTorch 和 NumPy 中,请牢记:
*是按元素操作。@是真正的线性代数矩阵乘法。
以X = torch.arange(24).reshape(2, 3, 4)为例,哪个是轴0,哪个是1 哪个是2
这是一个非常好的问题,也是理解多维数据处理(无论是 PyTorch还是 NumPy)的基石。对于 X = torch.arange(24).reshape(2, 3, 4),我们可以从外到内地理解它的轴(axis)。
简单直接的答案:
- 轴 0 (Axis 0): 对应形状中的第一个数字
2。 - 轴 1 (Axis 1): 对应形状中的第二个数字
3。 - 轴 2 (Axis 2): 对应形状中的第三个数字
4。
轴的编号总是从 0 开始,并与 tensor.shape 元组中的维度一一对应。
想象一个三维的“数据大楼”,这个大楼的形状是 (2, 3, 4)。
- 大小: 2
- 含义: 这是最外层的维度。你可以把整个
X看作是由 2 个独立的单元组成的。每个单元都是一个3x4的矩阵。 - 如何访问: 当你沿着轴 0 进行索引时,你是在选择这 2 个单元中的一个。
X[0]会给你第一个3x4的矩阵。X[1]会给你第二个3x4的矩阵。
- 大小: 3
- 含义: 这是中间的维度。在我们选定了某个区块(比如
X[0])之后,这个区块内部又由 3 个单元(行)组成。每个单元是一个长度为 4 的向量。 - 如何访问: 当你沿着轴 1 进行索引时,你是在选择某个区块内的某一行。
X[0, 1]会给你第一个区块 (X[0]) 中的第二行。
- 大小: 4
- 含义: 这是最内层的维度。在我们选定了某个区块的某一行(比如
X[0, 1])之后,这个行向量内部由 4 个独立的数值组成。 - 如何访问: 当你沿着轴 2 进行索引时,你是在选择一行中的具体某个元素。
X[0, 1, 2]会给你第一个区块、第二行中的第三个元素。
让我们用代码来验证这个“大楼”的比喻。
import torch
# 创建张量
X = torch.arange(24).reshape(2, 3, 4)
print("完整的张量 X (shape: {}):\n{}".format(X.shape, X))
print("\n" + "="*40 + "\n")
# --- 沿着 轴 0 进行探索 ---
print("访问 轴 0 (选择 '区块')")
block_0 = X[0]
print("X[0] (shape: {}):\n{}".format(block_0.shape, block_0))
# 输出是一个 3x4 的矩阵
# tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
print("-" * 20)
block_1 = X[1]
print("X[1] (shape: {}):\n{}".format(block_1.shape, block_1))
# 输出是另一个 3x4 的矩阵
# tensor([[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]])
print("\n" + "="*40 + "\n")
# --- 沿着 轴 1 进行探索 ---
print("访问 轴 1 (在第一个'区块' X[0] 中选择 '行')")
row_1_of_block_0 = X[0, 1] # 或者 X[0][1]
print("X[0, 1] (shape: {}):\n{}".format(row_1_of_block_0.shape, row_1_of_block_0))
# 输出是一个长度为 4 的向量
# tensor([4, 5, 6, 7])
print("\n" + "="*40 + "\n")
# --- 沿着 轴 2 进行探索 ---
print("访问 轴 2 (在第一个'区块'的第二'行'中选择'元素')")
element_2_of_row_1_of_block_0 = X[0, 1, 2] # 或者 X[0][1][2]
print("X[0, 1, 2] (shape: {}):\n{}".format(element_2_of_row_1_of_block_0.shape, element_2_of_row_1_of_block_0))
# 输出是一个标量(0维张量)
# tensor(6)理解轴至关重要,因为深度学习中充满了多维张量,并且每个轴都有特定的含义。一个常见的例子是处理一批图像数据,其形状通常是 (N, C, H, W):
- 轴 0 (
N): Batch Size。批次中的图像数量。 - 轴 1 (
C): Channels。每个图像的通道数(例如,灰度图是1,RGB彩色图是3)。 - 轴 2 (
H): Height。图像的高度(像素)。 - 轴 3 (
W): Width。图像的宽度(像素)。
对于你的例子 X(形状为 (2, 3, 4)),我们可以把它想象成一个批处理的文本数据:
- 轴 0 (
N=2): 批次里有2条句子。 - 轴 1 (
S=3): 每条句子的最大长度是3个词。 - 轴 2 (
E=4): 每个词都被表示成一个4维的词向量(Embedding)。
在这种情况下,X[0, 1, :] 就代表了“第一句话的第二个词的词向量”。
希望这个由浅入深的讲解能帮助你彻底弄清轴的概念!
A.sum(axis=[0, 1]) 怎么理解呢,当这个axis是数组的时候
Excellent question! This is a powerful feature that allows for more complex and efficient data aggregation. Let's break down A.sum(axis=[0, 1]) step-by-step, using our familiar example.
The Core Idea:
When axis is a list or tuple (like [0, 1]), you are telling PyTorch to perform the summation operation simultaneously across all the specified axes. The dimensions corresponding to these axes are "collapsed" or "removed," and the remaining axes are kept.
Let's use our (2, 3, 4) tensor to make this concrete.
import torch
# Our familiar 3D tensor
X = torch.arange(24).reshape(2, 3, 4)
print("Original Tensor X (shape: {}):".format(X.shape))
print(X)
print("\n" + "="*50 + "\n")
# The operation in question
result = X.sum(axis=[0, 1])
print("Result of X.sum(axis=[0, 1]) (shape: {}):".format(result.shape))
print(result)Output:
Original Tensor X (shape: torch.Size([2, 3, 4])):
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
==================================================
Result of X.sum(axis=[0, 1]) (shape: torch.Size([4])):
tensor([60, 66, 72, 78])
- Original Shape:
(2, 3, 4) - Axes to Sum Over: Axis 0 (size 2) and Axis 1 (size 3).
- Action: We "remove" or "collapse" these two dimensions.
- Resulting Shape: We are left with only the dimension from Axis 2, which has a size of 4. So the final shape is
(4,).
This explains why the result is a 1D tensor of length 4.
This is the most intuitive way to understand it. The operation collapses both Axis 0 (the "blocks") and Axis 1 (the "rows") and sums everything up, but it keeps Axis 2 separate.
Think of it like this: "For each position along the remaining axis (Axis 2), sum up all the numbers in the original tensor at that position."
Let's calculate the first element of the result, which corresponds to index 0 on Axis 2:
- We need to find all elements in
Xthat have0as their last index. These are:- From
X[0](first block):X[0,0,0],X[0,1,0],X[0,2,0]=>0,4,8 - From
X[1](second block):X[1,0,0],X[1,1,0],X[1,2,0]=>12,16,20
- From
- Sum them all up:
0 + 4 + 8 + 12 + 16 + 20 = 60
Let's do the second element (index 1 on Axis 2):
- Find all elements with
1as the last index:1, 5, 9and13, 17, 21 - Sum them up:
1 + 5 + 9 + 13 + 17 + 21 = 66
And so on...
- For index
2on Axis 2:2 + 6 + 10 + 14 + 18 + 22 = 72 - For index
3on Axis 2:3 + 7 + 11 + 15 + 19 + 23 = 78
This perfectly matches our result: tensor([60, 66, 72, 78]).
The operation effectively slices the 3D tensor into vertical "columns" along Axis 2 and sums up all the numbers within each column.
Yes, it is! Applying the sum over the axes one by one gives the same result and can be another way to build your intuition.
-
First, sum over Axis 0:
intermediate = X.sum(axis=0) print("After summing over Axis 0 (shape: {}):\n{}".format(intermediate.shape, intermediate)) # Original shape (2, 3, 4) -> collapses axis 0 -> New shape (3, 4) # [[ 0, 1, 2, 3], + [[12, 13, 14, 15], -> [[12, 14, 16, 18], # [ 4, 5, 6, 7], [16, 17, 18, 19], [20, 22, 24, 26], # [ 8, 9, 10, 11]] [20, 21, 22, 23]] [28, 30, 32, 34]]
-
Now, sum the intermediate result over its new Axis 0 (which was the original Axis 1):
final_result_sequential = intermediate.sum(axis=0) print("\nAfter summing the result over its new Axis 0 (shape: {}):\n{}".format(final_result_sequential.shape, final_result_sequential)) # Original shape (3, 4) -> collapses axis 0 -> New shape (4,) # [12+20+28, 14+22+30, 16+24+32, 18+26+34] -> [60, 66, 72, 78]
The result is identical. Using axis=[0, 1] is just more direct, efficient, and often more readable than chaining multiple .sum() calls.
A.sum(axis=N): Collapses only dimensionN.A.sum(axis=[M, N]): Collapses dimensionsMandNsimultaneously.- General Rule: Any dimensions specified in the
axislist are "summed away," and the dimensions not in the list are preserved in the final output tensor.
用中文输出
好的,我们用中文来详细解释 A.sum(axis=[0, 1]) 的工作原理。
这是一个非常强大的功能,它允许你进行更复杂、更高效的数据聚合。让我们一步步把它讲清楚。
核心思想:
当 axis 参数是一个列表或元组(比如 [0, 1])时,你是在告诉 PyTorch:请同时对所有指定的轴进行求和操作。这些被指定的轴所对应的维度会被“压缩”或“移除”,而剩下的轴会被保留下来。
让我们用之前熟悉的 (2, 3, 4) 张量来具体说明。
import torch
# 我们熟悉的三维张量
X = torch.arange(24).reshape(2, 3, 4)
print("原始张量 X (形状: {}):".format(X.shape))
print(X)
print("\n" + "="*50 + "\n")
# 我们要研究的操作
result = X.sum(axis=[0, 1])
print("X.sum(axis=[0, 1]) 的结果 (形状: {}):".format(result.shape))
print(result)输出结果:
原始张量 X (形状: torch.Size([2, 3, 4])):
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
==================================================
X.sum(axis=[0, 1]) 的结果 (形状: torch.Size([4])):
tensor([60, 66, 72, 78])
- 原始形状:
(2, 3, 4) - 要进行求和的轴: 轴 0 (大小为 2) 和 轴 1 (大小为 3)。
- 操作: 我们将这两个维度“移除”或“压扁”。
- 结果形状: 我们只剩下了轴 2 对应的维度,其大小为 4。所以最终的形状是
(4,)。
这就解释了为什么结果是一个长度为 4 的一维张量。
这是最直观的理解方式。这个操作会同时“压扁”轴0(“区块”)和轴1(“行”),然后把所有数字加起来,但是它会保持轴2的独立性。
你可以这样想:“对于保留下来的轴(轴 2)上的每一个位置,将原始张量中所有处于该位置的元素全部加起来。”
让我们来计算结果中的第一个元素,它对应轴 2 上的索引 0:
- 我们需要找出
X中所有最后一个索引为0的元素。它们是:- 来自
X[0](第一个区块):X[0,0,0],X[0,1,0],X[0,2,0]=>0,4,8 - 来自
X[1](第二个区块):X[1,0,0],X[1,1,0],X[1,2,0]=>12,16,20
- 来自
- 把它们全部相加:
0 + 4 + 8 + 12 + 16 + 20 = 60
再来计算第二个元素 (对应轴 2 上的索引 1):
- 找出所有最后一个索引为
1的元素:1, 5, 9和13, 17, 21 - 把它们全部相加:
1 + 5 + 9 + 13 + 17 + 21 = 66
以此类推...
- 对于轴 2 上的索引
2:2 + 6 + 10 + 14 + 18 + 22 = 72 - 对于轴 2 上的索引
3:3 + 7 + 11 + 15 + 19 + 23 = 78
这与我们的计算结果 tensor([60, 66, 72, 78]) 完全吻合。
这个操作实际上是将三维张量沿着轴2切分成了多个“垂直列”,然后将每一“列”中的所有数字相加。
是的,完全一样!将求和操作逐个应用在不同的轴上会得到相同的结果,这也可以帮助你建立直观理解。
-
第一步,先对 轴 0 求和:
intermediate = X.sum(axis=0) print("对轴 0 求和后 (形状: {}):\n{}".format(intermediate.shape, intermediate)) # 原始形状 (2, 3, 4) -> 压扁轴 0 -> 新形状 (3, 4) # [[ 0, 1, 2, 3], + [[12, 13, 14, 15], -> [[12, 14, 16, 18], # [ 4, 5, 6, 7], [16, 17, 18, 19], [20, 22, 24, 26], # [ 8, 9, 10, 11]] [20, 21, 22, 23]] [28, 30, 32, 34]]
-
第二步,对中间结果的 轴 0 (也就是原始张量的 轴 1)求和:
final_result_sequential = intermediate.sum(axis=0) print("\n对中间结果的轴 0 求和后 (形状: {}):\n{}".format(final_result_sequential.shape, final_result_sequential)) # 形状 (3, 4) -> 压扁轴 0 -> 新形状 (4,) # [12+20+28, 14+22+30, 16+24+32, 18+26+34] -> [60, 66, 72, 78]
结果是完全相同的。使用 axis=[0, 1] 的写法只是更直接、更高效,并且通常可读性更强,因为它一步就表达了完整的意图。
A.sum(axis=N): 只压扁维度N。A.sum(axis=[M, N]): 同时压扁维度M和N。- 通用法则: 任何在
axis列表中指定的维度都会被“求和消化掉”,而没有在列表中的维度则会保留在最终的输出张量中。
那X.sum(axis=[0,2])呢
没问题!我们来剖析 X.sum(axis=[0, 2]),这是一个绝佳的例子,可以帮你巩固对轴操作的理解。
我们还是使用同一个张量 X。
import torch
X = torch.arange(24).reshape(2, 3, 4)
print("原始张量 X (形状: {}):".format(X.shape))
print(X)
print("\n" + "="*50 + "\n")
# 我们要研究的操作
result = X.sum(axis=[0, 2])
print("X.sum(axis=[0, 2]) 的结果 (形状: {}):".format(result.shape))
print(result)输出结果:
原始张量 X (形状: torch.Size([2, 3, 4])):
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
==================================================
X.sum(axis=[0, 2]) 的结果 (形状: torch.Size([3])):
tensor([ 60, 92, 124])
- 原始形状:
(2, 3, 4) - 要进行求和的轴: 轴 0 (大小为 2) 和 轴 2 (大小为 4)。
- 操作: 我们将这两个维度“移除”或“压扁”。
- 剩下的轴是哪个?: 轴 1。
- 结果形状: 我们只剩下了轴 1 对应的维度,其大小为 3。所以最终的形状是
(3,)。
根据通用法则:“没有在 axis 列表中指定的维度会被保留下来”。在这里,轴 1 是被保留的那个维度。
计算的逻辑就变成了:“对于被保留的轴(轴 1)上的每一个位置,将原始张量中所有处于该位置的元素全部加起来。”
让我们来拆解计算过程:
-
计算结果的第 1 个元素
result[0]:- 这对应的是在被保留的 轴 1 上索引为 0 的所有元素。
- 换句话说,我们要把所有
X[区块, 0, 元素]形式的数字加起来。 - 这相当于把 每个区块的第 1 行 拿出来相加。
- 第一个区块的第1行是:
[0, 1, 2, 3] - 第二个区块的第1行是:
[12, 13, 14, 15] - 全部相加:
(0 + 1 + 2 + 3) + (12 + 13 + 14 + 15) = 6 + 54 = 60
-
计算结果的第 2 个元素
result[1]:- 这对应的是在 轴 1 上索引为 1 的所有元素。
- 也就是把 每个区块的第 2 行 拿出来相加。
- 第一个区块的第2行是:
[4, 5, 6, 7] - 第二个区块的第2行是:
[16, 17, 18, 19] - 全部相加:
(4 + 5 + 6 + 7) + (16 + 17 + 18 + 19) = 22 + 70 = 92
-
计算结果的第 3 个元素
result[2]:- 这对应的是在 轴 1 上索引为 2 的所有元素。
- 也就是把 每个区块的第 3 行 拿出来相加。
- 第一个区块的第3行是:
[8, 9, 10, 11] - 第二个区块的第3行是:
[20, 21, 22, 23] - 全部相加:
(8 + 9 + 10 + 11) + (20 + 21 + 22 + 23) = 38 + 86 = 124
-
X.sum(axis=[0, 1]): 保留了轴 2。可以想象成把数据沿着轴 2 切成 4 根“垂直柱子”,然后分别计算每根柱子所有元素的和。 -
X.sum(axis=[0, 2]): 保留了轴 1。可以想象成把数据沿着轴 1 切成 3 个“水平切片”,然后分别计算每个切片所有元素的和。
这个例子完美地展示了 axis 参数的强大之处:通过指定不同的轴组合,你可以实现各种维度的数据聚合,这是数据分析和深度学习模型中非常常见的操作(例如,在计算批次损失、进行特征池化等场景)。
keepdim这个属性是做什么的
你问到了一个非常关键且实用的参数!keepdim (keep dimension 的缩写) 是 PyTorch 中聚合类操作(如 sum, mean, max 等)的一个布尔参数,它的作用是:
决定在聚合操作之后,是否保留被“压扁”的那个维度的“架子”。
简单来说:
keepdim=False(默认值): 操作完成后,被聚合的维度会彻底消失。keepdim=True: 操作完成后,被聚合的维度不会消失,而是其大小会变为 1,从而保持了原始张量的维度数量(或称“秩”)。
我们用具体的例子来看一下 keepdim 是如何改变结果的。
import torch
# 还是我们熟悉的张量
X = torch.arange(24).reshape(2, 3, 4)
print("原始张量 X\n形状: {}\n{}".format(X.shape, X))
print("\n" + "="*50 + "\n")
# --- 情况 1: keepdim=False (默认情况) ---
# 我们对 轴 0 (区块) 进行求和
sum_false = X.sum(axis=0)
# keepdim 默认为 False,所以这里可以省略不写
print("【keepdim=False】(默认)")
print("操作: X.sum(axis=0)")
print("结果形状: {}. (维度从 3 降到了 2)".format(sum_false.shape))
print("结果内容:\n", sum_false)
print("\n" + "-"*50 + "\n")
# --- 情况 2: keepdim=True ---
# 同样对 轴 0 进行求和,但保留维度
sum_true = X.sum(axis=0, keepdim=True)
print("【keepdim=True】")
print("操作: X.sum(axis=0, keepdim=True)")
print("结果形状: {}. (维度数量不变)".format(sum_true.shape))
print("结果内容:\n", sum_true)输出结果:
原始张量 X
形状: torch.Size([2, 3, 4])
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
==================================================
【keepdim=False】(默认)
操作: X.sum(axis=0)
结果形状: torch.Size([3, 4]). (维度从 3 降到了 2)
结果内容:
tensor([[12, 14, 16, 18],
[20, 22, 24, 26],
[28, 30, 32, 34]])
--------------------------------------------------
【keepdim=True】
操作: X.sum(axis=0, keepdim=True)
结果形状: torch.Size([1, 3, 4]). (维度数量不变)
结果内容:
tensor([[[12, 14, 16, 18],
[20, 22, 24, 26],
[28, 30, 32, 34]]])
观察关键区别:
- 形状 (Shape):
keepdim=False: 形状从(2, 3, 4)变成了(3, 4)。轴 0 直接消失了。keepdim=True: 形状从(2, 3, 4)变成了(1, 3, 4)。轴 0 的大小从 2 变成了 1,但这个轴本身被保留了下来。
- 内容 (Content): 计算出的数值是完全一样的。区别仅仅在于包裹这些数值的“括号”层级不同,这正反映了维度的不同。
你可能会问,保留一个大小为 1 的维度有什么用?答案是:为了利用广播(Broadcasting)机制。
keepdim=True 最大的作用就是使得聚合运算的结果能够直接和原始张量进行计算,而不需要手动 unsqueeze 或 reshape。
一个经典的例子:标准化
假设我们想让 X 中的每个元素除以它所在“区块”的平均值。
1. 错误的尝试(不使用 keepdim)
# 计算每个区块的平均值
mean_false = X.mean(axis=[1, 2]) # 对每个区块内的所有元素(行和列)求平均
print("不使用 keepdim,平均值的形状:", mean_false.shape) # 输出 torch.Size([2])
# X的形状是 (2, 3, 4),mean_false 的形状是 (2,)
# PyTorch 无法直接将这两个形状进行广播除法
try:
normalized_X = X / mean_false
except RuntimeError as e:
print("出错了:", e)输出:
不使用 keepdim,平均值的形状: torch.Size([2])
出错了: The size of tensor a (4) must match the size of tensor b (2) at non-singleton dimension 2
这个错误告诉我们,形状不匹配,无法广播。我们需要手动调整 mean_false 的形状为 (2, 1, 1) 才能进行计算。
2. 正确的做法(使用 keepdim=True)
# 计算每个区块的平均值,但保留维度
mean_true = X.mean(axis=[1, 2], keepdim=True)
print("使用 keepdim,平均值的形状:", mean_true.shape) # 输出 torch.Size([2, 1, 1])
# X的形状是 (2, 3, 4),mean_true 的形状是 (2, 1, 1)
# 这两个形状是可以通过广播兼容的!
normalized_X = X / mean_true
print("\n标准化成功!结果形状:", normalized_X.shape)
# print("标准化结果的一个区块:\n", normalized_X[0])输出:
使用 keepdim,平均值的形状: torch.Size([2, 1, 1])
标准化成功!结果形状: torch.Size([2, 3, 4])
这里,PyTorch 看到 (2, 3, 4) 和 (2, 1, 1),它会自动地将 mean_true 的大小为 1 的维度“拉伸”或“复制”,使其形状“看起来”像 (2, 3, 4),从而完成逐元素的除法。
| 特性 | keepdim=False (默认) |
keepdim=True |
|---|---|---|
| 结果形状 | 被聚合的维度消失 | 被聚合的维度大小变为 1 |
| 维度数量 | 减少(降维) | 保持不变 |
| 主要用途 | 只需要最终的聚合结果(例如,计算整个张量的总损失) | 为了后续与原张量进行广播计算(例如,标准化、softmax) |
在编写神经网络层(如 Layer Normalization, Softmax)时,keepdim=True 是一个不可或缺的工具,它可以让你的代码更简洁、更高效、更不易出错。
好的,这是图片内容的识别结果和您要求的示例。
User:
OCR之后再举个简单的例子说明这个公式
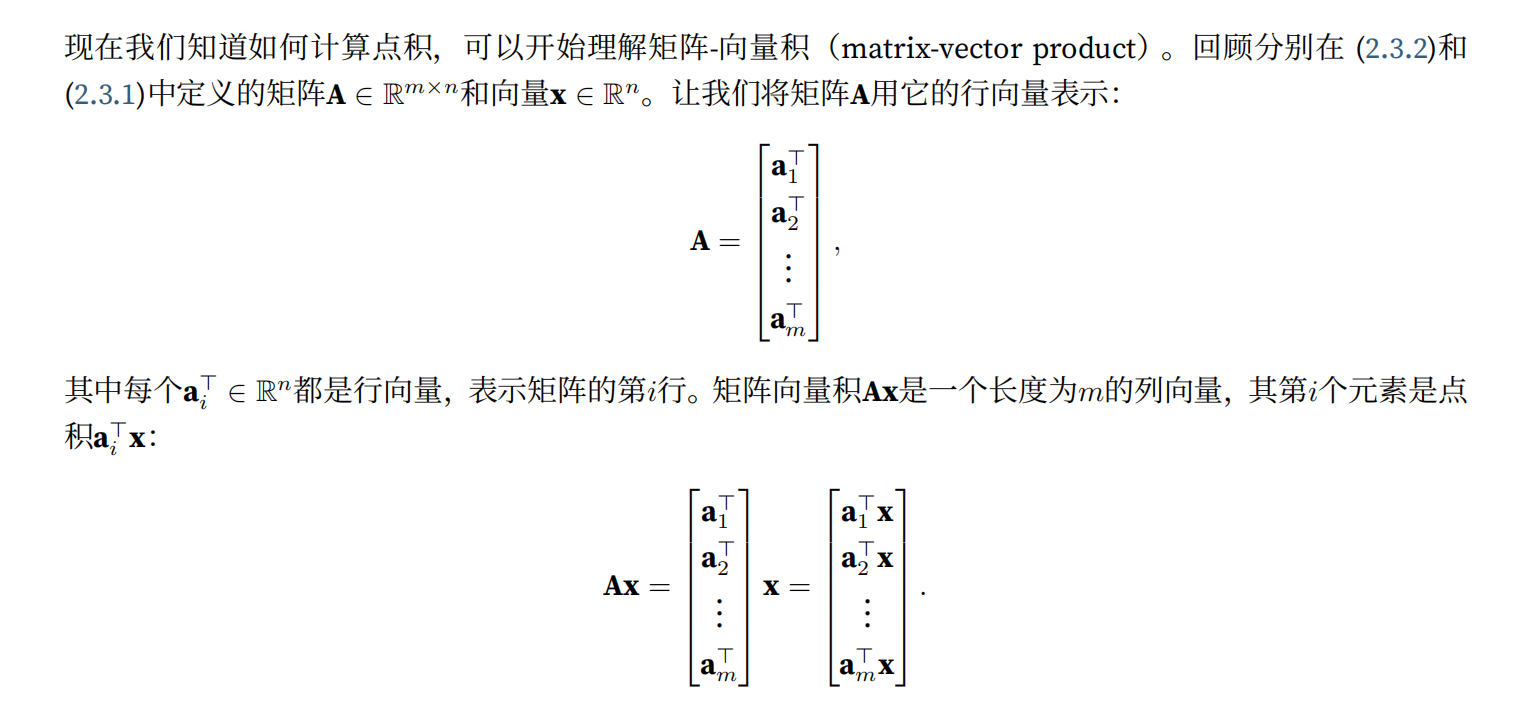
现在我们知道如何计算点积,可以开始理解矩阵-向量积 (matrix-vector product)。回顾分别在 (2.3.2)和 (2.3.1)中定义的矩阵
其中每个
这个公式说明,一个矩阵和一个向量相乘,其结果向量的每一个元素,都是由矩阵的对应行向量与那个向量做点积得到的。
我们来看一个具体的例子。
假设我们有矩阵
这里,矩阵
根据公式,我们可以把矩阵
- 第一个行向量是
$\mathbf{a}_1^\top = [1, 2, 3]$ - 第二个行向量是
$\mathbf{a}_2^\top = [4, 5, 6]$
现在,我们来计算矩阵-向量积
我们分别计算这两个点积:
- 第一个元素:$\mathbf{a}_1^\top \mathbf{x} = (1 \times 7) + (2 \times 8) + (3 \times 9) = 7 + 16 + 27 = 50$
- 第二个元素:$\mathbf{a}_2^\top \mathbf{x} = (4 \times 7) + (5 \times 8) + (6 \times 9) = 28 + 40 + 54 = 122$
所以,最终的结果是:
在掌握点积和矩阵-向量积的知识后,那么矩阵-矩阵乘法 (matrix-matrix multiplication) 应该很简单。
假设有两个矩阵
这个公式的核心思想是:结果矩阵
我们来看一个具体的例子。
假设我们有两个矩阵
要计算
首先,我们把
-
$\mathbf{A}$ 的第1行:$\mathbf{a}_1^\top = [1, 2, 3]$ -
$\mathbf{A}$ 的第2行:$\mathbf{a}_2^\top = [4, 5, 6]$
然后,把
-
$\mathbf{B}$ 的第1列: $\mathbf{b}_1 = \begin{bmatrix} 7 \ 9 \ 11 \end{bmatrix}$ -
$\mathbf{B}$ 的第2列: $\mathbf{b}_2 = \begin{bmatrix} 8 \ 10 \ 12 \end{bmatrix}$
现在,我们根据公式
-
$c_{11}$ (C的第一行第一列) =$\mathbf{A}$ 的第1行$\cdot$ $\mathbf{B}$ 的第1列 = $\mathbf{a}_1^\top \mathbf{b}1$ $c{11} = (1 \times 7) + (2 \times 9) + (3 \times 11) = 7 + 18 + 33 = 58$ -
$c_{12}$ (C的第一行第二列) =$\mathbf{A}$ 的第1行$\cdot$ $\mathbf{B}$ 的第2列 = $\mathbf{a}_1^\top \mathbf{b}2$ $c{12} = (1 \times 8) + (2 \times 10) + (3 \times 12) = 8 + 20 + 36 = 64$ -
$c_{21}$ (C的第二行第一列) =$\mathbf{A}$ 的第2行$\cdot$ $\mathbf{B}$ 的第1列 = $\mathbf{a}_2^\top \mathbf{b}1$ $c{21} = (4 \times 7) + (5 \times 9) + (6 \times 11) = 28 + 45 + 66 = 139$ -
$c_{22}$ (C的第二行第二列) =$\mathbf{A}$ 的第2行$\cdot$ $\mathbf{B}$ 的第2列 = $\mathbf{a}_2^\top \mathbf{b}2$ $c{22} = (4 \times 8) + (5 \times 10) + (6 \times 12) = 32 + 50 + 72 = 154$
最后,把这些结果组合成矩阵