diff --git a/docs/autoregressive/autoregressive.md b/docs/autoregressive/autoregressive.md
index 2696200..b4c41fb 100644
--- a/docs/autoregressive/autoregressive.md
+++ b/docs/autoregressive/autoregressive.md
@@ -1,6 +1,109 @@
-# Modelos Autorregressivos e Aplicação em World Foundation Models (WFMs)
+# Autoregressive models and application on World Foundation Models (WFMs)
-## O que é um Modelo Autorregressivo?
+**_Authors / Autores: [@gibi177](http://github.com/gibi177), [@DaniloCTM](http://github.com/DaniloCTM)_**
+
+## English
+
+### What is an Autoregressive Model?
+
+An autoregressive (AR) model is a type of statistical model that predicts future values in a sequence based on its own past values. The term “autoregressive” reflects the idea that the model “regresses on itself", that is, predictions are made from previous observations. In it, we have the relationship:
+
+- **Input**: Past observations (e.g., previous words in a sentence, frames in a video).
+- **Output**: Prediction of the next value in the sequence (e.g., next word, next frame).
+
+The formula that describes autoregressive models is expressed as
+
+$$X_t = \sum_{i=1}^{p} \phi_i X_{t-i} + \varepsilon_t$$
+
+Where:
+
+- $X_t$ is the value of the time series at time $t$,
+- $\phi_i$ are the autoregressive coefficients,
+- $p$ is the order of the autoregressive model,
+- $X_{t-i}$ are the past values of the time series
+- $\varepsilon_t$ is the error or noise, considered a random variable with zero mean and constant variance
+
+
+
+_Comparison between 2 autoregressive models with different parameters. The image shows the flexibility of the models in handling different time series patterns._
+
+#### Usage examples
+
+Autoregressive models are widely used in areas such as natural language processing (NLP) and time series due to their ability to capture sequential and temporal dependencies. Some examples of autoregressive models are:
+
+- **Time series**: used to predict sequential data, such as stock prices, weather forecasting, or data traffic.
+
+- **NLP**: models like GPT operate with an autoregressive approach, generating the next word based on the previous words, sequentially. Dependence among previous words is important for generating context and coherent sentences.
+
+- **Audio and Signal**s: The AR model is a classical foundation in audio signal analysis, such as in audio coding, speech recognition, and music signal processing. Autocorrelation among audio data at different times can be modeled to predict sounds or identify temporal patterns.
+
+
+
+_Example of an autoregressive application for next-word prediction in a context. The sequential nature of predictions is evident, where only one word is predicted at a time. Furthermore, each word depends on previously generated words, demonstrating the autoregressive nature of language models._
+
+### WFM based on an autoregressive model
+
+WFMs that use autoregressive approaches apply the same principles of language models to the generation of simulated environments. In this architecture, world simulation is generated by predicting the next token, where each video frame is converted into a sequence of tokens that are processed sequentially by the model. The autoregressive nature comes precisely from predicting the next tokens based on the sequence of frames already seen.
+
+These tokens can represent pixels, visual patches (as in the Vision Transformer), text embeddings, commands, or actions. The model is trained to predict the next token from an accumulated context, respecting the causal order of the data: each prediction is conditioned only on present and past input values, but never on future values.
+
+
+
+_The combination of images and text is often used to generate the actions that the physical AI will perform. The combination of image frames with textual inputs, enabled by the model’s transformer architecture, allows finer control over the actions performed by the agent in the real world._
+
+This multimodal integration (combination of multiple data modalities) allows the model to function as a general agent that observes the environment (via video or images), understands commands (via text), and generates sequences of actions based on these inputs. The model learns to simulate and anticipate world states, acting as an autoregressive planner that operates based on continuous observations of the environment.
+
+#### System Architecture
+
+
+
+The architecture of autoregressive WFMs follows three main components:
+
+1. **Video Tokenization**:
+
+ - Videos are initially passed through a visual tokenizer, which transforms each frame into a sequence of discrete tokens. These tokens are compact representations of the frames. In this architecture it produces a tensor of (8x16x16).
+
+2. **Autoregressive Core**:
+
+ - The core of the model is a Transformer decoder, trained to predict the next token based on the previous sequence (this is where the autoregressive nature lies). To handle the three-dimensional structure of videos (time, height, and width), spatial and temporal positional embeddings are used. It can also receive additional information, such as natural language instructions, through cross-attention mechanisms.
+
+ - **Positional Embedding:** Attention-based models (Transformers) do not understand order or position by default. For the model to process videos (or any sequential data), it is essential to specify where and when each token occurs. This is where positional embeddings come in, and in this case, we have two combined types:
+
+ - **Absolute Positional Embedding:** For each position in the video, the model assigns a fixed vector. This vector is then added directly to the vocabulary token embedding:
+
+ - $\text{vocabulary\_embedding} + \text{positional\_embedding} = \text{final\_embedding}$
+
+ - **3D RoPE:** RoPE (Rotary Positional Embedding) is a type of embedding that incorporates position into the vector via trigonometric rotation, rather than adding a fixed vector. By applying trigonometric rotation to the 3D vector, it is able to infer relative dimensions among tokens, directions of movement, rhythms, and spatial and temporal patterns.
+
+ - **T5 text encoder:** The T5 Text Encoder is the encoder component of the T5 (Text-to-Text Transfer Transformer) model, designed to transform any natural language task into a text-to-text task. In this encoder, the input text (such as a descriptive prompt) is tokenized and processed by a stack of Transformer layers, generating a sequence of dense contextual vectors that capture the semantic meaning of each word in the context of the sentence. These embeddings are then used in cross-attention with the video tokens, allowing the model to condition video reconstruction or generation based on textual content. The use of the T5 encoder enables the system to understand natural language commands with semantic depth, guiding multimodal processing in a flexible and expressive way.
+ - **Cross Attention:** Cross-attention allows video tokens to be guided by text tokens, combining the two modalities intelligently to interpret or generate video based on natural language. The equation used in both self-attention and cross-attention is:
+ - $\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V$
+ - Where:
+ - $Q$ = query matrix
+ - $K$ = key matrix
+ - $V$ = value matrix
+ - $d_k$ = dimension of the key vectors (scaling normalizer)
+ - $QK^T$ = dot product between queries and keys
+ - $\text{softmax}$ = transforms weights into probabilities
+
+3. **Decoding**:
+
+ - Generation happens sequentially, token by token, until a new frame is reconstructed. There is the possibility that the generated tokens are passed through a diffusion decoder to improve visual quality
+
+#### Advantages of the Approach
+
+Among the main strengths of this architecture is its **scalability**: by inheriting the structure of large language models (LLMs), it adapts well to the use of large volumes of data.
+Another important aspect is **flexibility**: the model can handle different types of input (text, video, image), generate sequences of varying lengths, and be controlled precisely by prompts
+
+#### Limitations
+
+Despite the advantages, there are inherent challenges to the approach. The **sequential generation** makes the process naturally slower and more computationally expensive, especially in long videos.
+In addition, since each step depends on the previous one, **small errors tend to propagate** and amplify along the sequence, which can compromise the coherence of the generated video.
+Finally, the aggressive tokenization process, necessary to reduce computational cost, can introduce **unexpected objects** that affect the fidelity of the simulation, which is why it is often necessary to apply post-processing with diffusion models.
+
+## Português
+
+### O que é um Modelo Autorregressivo?
Um modelo autorregressivo (AR) é um tipo de modelo estatístico que prevê valores futuros em uma sequência com base em seus próprios valores passados. O termo "autorregressivo" reflete a ideia de que o modelo "faz regressão sobre si mesmo", ou seja, as previsões são feitas a partir das observações anteriores. Nele, temos a relação:
@@ -8,75 +111,73 @@ Um modelo autorregressivo (AR) é um tipo de modelo estatístico que prevê valo
- **Saída**: Previsão do próximo valor na sequência (ex: próxima palavra, próximo quadro).
-A fórmula que descreve os modelos autoregressivos é expressa como
+A fórmula que descreve os modelos autorregressivos é expressa como
$$X_t = \sum_{i=1}^{p} \phi_i X_{t-i} + \varepsilon_t$$
Onde:
- $X_t$ é o valor da série temporal no tempo $t$,
-- $\phi_i$ são os coeficientes autoregressivos,
-- $p$ é a ordem do modelo autoregressivo,
+- $\phi_i$ são os coeficientes autorregressivos,
+- $p$ é a ordem do modelo autorregressivo,
- $X_{t-i}$ são os valores passados da série temporal
- $\varepsilon_t$ é o erro ou ruído, considerado como uma variável aleatória com média zero e variância constante
-
+
-> Comparação entre 2 modelos autoregressivos com parâmetros diferentes. A imagem mostra a flexibilidade dos modelos em tratar diferentes padrões de séries temporais.
+_Comparação entre 2 modelos autorregressivos com parâmetros diferentes. A imagem mostra a flexibilidade dos modelos em tratar diferentes padrões de séries temporais._
-### Exemplos de uso
+#### Exemplos de uso
-Modelos autoregressivos são muito usados em áreas como processamento de linguagem natural (PLN) e séries temporais, devido à sua capacidade de capturar dependências sequenciais e temporais. Alguns exemplos de modelos autoregressivos são:
+Modelos autorregressivos são muito usados em áreas como processamento de linguagem natural (PLN) e séries temporais, devido à sua capacidade de capturar dependências sequenciais e temporais. Alguns exemplos de modelos autorregressivos são:
-- **Séries temporais**: usados para prever dados sequenciais, como preços de ações, previsão do tempo ou tráfego de dados
+- **Séries temporais**: usados para prever dados sequenciais, como preços de ações, previsão do tempo ou tráfego de dados.
-- **PLN**: modelos como o GPT funcionam com abordagem autoregressiva, gerando a próxima palavra com base nas palavras anteriores, sequencialmente. A dependência entre palavras anteriores é importante para a geração de contexto e de frases coerentes.
+- **PLN**: modelos como o GPT funcionam com abordagem autorregressiva, gerando a próxima palavra com base nas palavras anteriores, sequencialmente. A dependência entre palavras anteriores é importante para a geração de contexto e de frases coerentes.
- **Áudio e Sinais**: O modelo AR é uma base clássica na análise de sinais de áudio, como na codificação de áudio, reconhecimento de fala e processamento de sinais de música. A autocorrelação entre os dados de áudio em diferentes tempos pode ser modelada para prever sons ou identificar padrões temporais.
-
+
-> Exemplo de aplicação autoregressiva para previsão da próxima palavra em um contexto. Percebe-se a sequencialidade das previsões, em que apenas uma palavra é predita de cada vez. Além disso, cada palavra depende das palavras previamente geradas, demonstrando o caráter autoregressivo dos modelos de linguagem.
+_Exemplo de aplicação autoregressiva para previsão da próxima palavra em um contexto. Percebe-se a sequencialidade das previsões, em que apenas uma palavra é predita de cada vez. Além disso, cada palavra depende das palavras previamente geradas, demonstrando o caráter autorregressivo dos modelos de linguagem._
-## WFM baseado em modelo autoregressivo
+### WFM baseado em modelo autorregressivo
-WFMs que utilizam abordagens autoregressivas aplicam os mesmos princípios dos modelos de linguagem à geração de ambientes simulados.
-Nesta arquitetura, a simulação de mundo é gerada por meio da previsão do próximo token, onde cada frame de vídeo é convertido em uma sequência de tokens que são processados sequencialmente pelo modelo. O caráter autoregressivo vem justamente da previsão dos próximos tokens com base na sequência de frames já vista.
+WFMs que utilizam abordagens autorregressivas aplicam os mesmos princípios dos modelos de linguagem à geração de ambientes simulados. Nesta arquitetura, a simulação de mundo é gerada por meio da previsão do próximo token, onde cada frame de vídeo é convertido em uma sequência de tokens que são processados sequencialmente pelo modelo. O caráter autorregressivo vem justamente da previsão dos próximos tokens com base na sequência de frames já vista.
Esses tokens podem representar pixels, patches visuais (como no Vision Transformer), embeddings de texto, comandos ou ações. O modelo é treinado para prever o próximo token a partir de um contexto acumulado, respeitando a ordem causal dos dados: cada predição é condicionada apenas pelos valores presentes e passados de entrada, mas nunca de valores futuros.
-
+
-> Frequentemente usa-se a combinação de imagens e texto para gerar as ações que a IA física realizará. A combinação de frames de imagens com inputs textuais, proporcionados pela arquitetura transformer do modelo, permite um controle mais fino das ações realizadas pelo agente no mundo real.
+_Frequentemente usa-se a combinação de imagens e texto para gerar as ações que a IA física realizará. A combinação de frames de imagens com inputs textuais, proporcionados pela arquitetura transformer do modelo, permite um controle mais fino das ações realizadas pelo agente no mundo real._
-Essa integração multimodal (combinação de várias modalidades de dados), permite que o modelo funcione como um agente geral que observa o ambiente (por vídeo ou imagens), entende comandos (por texto) e gera sequências de ações com base nessas entradas. O modelo aprende a simular e antecipar estados do mundo, funcionando como um planejador autoregressivo que age com base em observações contínuas do ambiente.
+Essa integração multimodal (combinação de várias modalidades de dados), permite que o modelo funcione como um agente geral que observa o ambiente (por vídeo ou imagens), entende comandos (por texto) e gera sequências de ações com base nessas entradas. O modelo aprende a simular e antecipar estados do mundo, funcionando como um planejador autorregressivo que age com base em observações contínuas do ambiente.
-### Arquitetura do Sistema
+#### Arquitetura do Sistema
-
+
-A arquitetura das WFMs autoregressivas segue três componentes principais:
+A arquitetura das WFMs autorregressivas segue três componentes principais:
1. **Tokenização de Vídeo**:
+
- Os vídeos são inicialmente passados por um tokenizador visual, que transforma cada frame em uma sequência de tokens discretos. Esses tokens são representações compactas dos frames. Nessa arquitetura ele gera um tensor de (8x16x16).
-2. **Núcleo Autoregressivo**:
- - O núcleo do modelo é um Transformer decoder, treinado para prever o próximo token com base na sequência anterior (aqui está o caráter autoregressivo). Para lidar com a estrutura tridimensional dos vídeos (tempo, altura e largura), são utilizados embeddings posicionais espaciais e temporais. Ele também pode receber informações adicionais, como instruções em linguagem natural, por meio de mecanismos de atenção cruzada.
+2. **Núcleo Autorregressivo**:
+
+ - O núcleo do modelo é um Transformer decoder, treinado para prever o próximo token com base na sequência anterior (aqui está o caráter autorregressivo). Para lidar com a estrutura tridimensional dos vídeos (tempo, altura e largura), são utilizados embeddings posicionais espaciais e temporais. Ele também pode receber informações adicionais, como instruções em linguagem natural, por meio de mecanismos de atenção cruzada.
- **Positional Embedding:** Modelos baseados em atenção (Transformers) não entendem ordem ou posição por padrão. Para que o modelo processe vídeos (ou qualquer dado sequencial), é essencial dizer onde e quando cada token ocorre. É aqui que entram os positional embeddings, e neste caso, temos dois tipos combinados:
- - **Absolute Positional Embedding:** Para cada posição no vídeo, o modelo atribui um vetor fixo. Em seguida esse vetor é somado diretamente ao embedding do token de vocabulário:
+ - **Absolute Positional Embedding:** Para cada posição no vídeo, o modelo atribui um vetor fixo. Em seguida esse vetor é somado diretamente ao embedding do token de vocabulário:
- - $$embedding\_vocabulário + embedding\_posicional = embedding\_final$$
+ - $$embedding\_vocabulário + embedding\_posicional = embedding\_final$$
- - **3D Rope:** RoPE (Rotary Positional Embedding) é um tipo de embedding que incorpora posição no vetor via rotação trigonométrica, ao invés de somar um vetor fixo. Ao aplicar a rotação trigonométrica no vetor 3D ele é consegue inferir, dimensões relativas entre tokens, direções de movimento, ritmos e padrões espacias e temporais.
+ - **3D Rope:** RoPE (Rotary Positional Embedding) é um tipo de embedding que incorpora posição no vetor via rotação trigonométrica, ao invés de somar um vetor fixo. Ao aplicar a rotação trigonométrica no vetor 3D ele é consegue inferir, dimensões relativas entre tokens, direções de movimento, ritmos e padrões espacias e temporais.
- - **T5 text encoder:** O T5 Text Encoder é a parte codificadora do modelo T5 (Text-to-Text Transfer Transformer), projetado para transformar qualquer tarefa de linguagem natural em uma tarefa de texto para texto.
- Nesse encoder, o texto de entrada (como um prompt descritivo) é tokenizado e processado por uma pilha de camadas Transformer, gerando uma sequência de vetores contextuais densos que capturam o significado semântico de cada palavra no contexto da frase.
- Esses embeddings são então usados na cross-attention com os tokens do vídeo, permitindo que o modelo condicione a reconstrução ou geração de vídeo com base no conteúdo textual. O uso do T5 encoder permite que o sistema compreenda comandos em linguagem natural com profundidade semântica, guiando o processamento multimodal de forma flexível e expressiva.
+ - **T5 text encoder:** O T5 Text Encoder é a parte codificadora do modelo T5 (Text-to-Text Transfer Transformer), projetado para transformar qualquer tarefa de linguagem natural em uma tarefa de texto para texto. Nesse encoder, o texto de entrada (como um prompt descritivo) é tokenizado e processado por uma pilha de camadas Transformer, gerando uma sequência de vetores contextuais densos que capturam o significado semântico de cada palavra no contexto da frase. Esses embeddings são então usados na cross-attention com os tokens do vídeo, permitindo que o modelo condicione a reconstrução ou geração de vídeo com base no conteúdo textual. O uso do T5 encoder permite que o sistema compreenda comandos em linguagem natural com profundidade semântica, guiando o processamento multimodal de forma flexível e expressiva.
- - **Cross Attention:** A cross-attention permite que os tokens do vídeo sejam guiados pelos tokens do texto, combinando as duas modalidades de forma inteligente para interpretar ou gerar vídeo com base em linguagem natural.
- A equação usada tanto no **self-attention** quanto no **cross-attention** é:
+ - **Cross Attention:** A cross-attention permite que os tokens do vídeo sejam guiados pelos tokens do texto, combinando as duas modalidades de forma inteligente para interpretar ou gerar vídeo com base em linguagem natural. A equação usada tanto no **self-attention** quanto no **cross-attention** é:
- $$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V$$
@@ -89,20 +190,20 @@ A arquitetura das WFMs autoregressivas segue três componentes principais:
- $\text{softmax}$ = transforma os pesos em probabilidades
3. **Decodificação**:
+
- A geração acontece de forma sequencial, token por token, até que um novo frame seja reconstruído. Há a possibilidade dos tokens gerados serem passados por um decoder de difusão para melhorar a qualidade visual
-### Vantagens da Abordagem
+#### Vantagens da Abordagem
-Entre os principais pontos positivos dessa arquitetura está sua **escalabilidade**: por herdar a estrutura dos grandes modelos de linguagem (LLMs), ela se adapta bem ao uso de grandes volumes de dados.
+Entre os principais pontos positivos dessa arquitetura está sua **escalabilidade**: por herdar a estrutura dos grandes modelos de linguagem (LLMs), ela se adapta bem ao uso de grandes volumes de dados.
Outro aspecto importante é a **flexibilidade**: o modelo pode lidar com diferentes tipos de entrada (texto, vídeo, imagem), gerar sequências de comprimentos variados e ser controlado de maneira precisa por prompts
-### Limitações
+#### Limitações
-Apesar das vantagens, há desafios inerentes à abordagem. A **geração sequencial** faz com que o processo seja naturalmente mais lento e custoso do ponto de vista computacional, principalmente em vídeos longos. Além disso, como cada passo depende do anterior, **pequenos erros tendem a se propagar** e se amplificar ao longo da sequência, o que pode comprometer a coerência do vídeo gerado. Por fim, o processo de tokenização agressiva, necessário para reduzir o custo computacional, pode introduzir **objetos inesperados** que afetam a fidelidade da simulação, motivo pelo qual, muitas vezes, é necessário aplicar um pós-processamento com modelos de difusão.
+Apesar das vantagens, há desafios inerentes à abordagem. A **geração sequencial** faz com que o processo seja naturalmente mais lento e custoso do ponto de vista computacional, principalmente em vídeos longos.Além disso, como cada passo depende do anterior, **pequenos erros tendem a se propagar** e se amplificar ao longo da sequência, o que pode comprometer a coerência do vídeo gerado.Por fim, o processo de tokenização agressiva, necessário para reduzir o custo computacional, pode introduzir **objetos inesperados** que afetam a fidelidade da simulação, motivo pelo qual, muitas vezes, é necessário aplicar um pós-processamento com modelos de difusão.
### Referências
[Autoregressive model](https://en.wikipedia.org/wiki/Autoregressive_model)
[Cosmos World Foundation Model Platform for Physical AI](https://arxiv.org/html/2501.03575v1)
-
diff --git a/docs/autoregressive/src/AR_comparison.png b/docs/autoregressive/images/AR_comparison.png
similarity index 100%
rename from docs/autoregressive/src/AR_comparison.png
rename to docs/autoregressive/images/AR_comparison.png
diff --git a/docs/autoregressive/src/architecture.png b/docs/autoregressive/images/architecture.png
similarity index 100%
rename from docs/autoregressive/src/architecture.png
rename to docs/autoregressive/images/architecture.png
diff --git a/docs/autoregressive/src/exemplo_autoregressao_linguagem.png b/docs/autoregressive/images/nlp_autoregression_example.png
similarity index 100%
rename from docs/autoregressive/src/exemplo_autoregressao_linguagem.png
rename to docs/autoregressive/images/nlp_autoregression_example.png
diff --git a/docs/autoregressive/src/WFM_input_imagens_texto.png b/docs/autoregressive/images/wfm_input_images_text.png
similarity index 100%
rename from docs/autoregressive/src/WFM_input_imagens_texto.png
rename to docs/autoregressive/images/wfm_input_images_text.png
diff --git a/docs/cosmos_applications/cosmos_applications.md b/docs/cosmos_applications/cosmos_applications.md
index 5a6bbcf..b9fc677 100644
--- a/docs/cosmos_applications/cosmos_applications.md
+++ b/docs/cosmos_applications/cosmos_applications.md
@@ -1,12 +1,183 @@
# Aplicações da plataforma Cosmos
+**_Authors / Autores: [@gibi177](http://github.com/gibi177), [@figredos](http://github.com/figredos)_**
+
+## English
+
+### Introduction
+
+[The Cosmos paper](https://arxiv.org/html/2501.03575v1) suggests a series of possible applications of the World Foundation Models platform. Here, some of these possible applications are discussed, along with the different models available for such applications.
+
+### Different Cosmos WFM Models
+
+NVIDIA, through the NVIDIA Developer site [NVIDIA Developer](https://developer.nvidia.com/cosmos?hitsPerPage=6), provides a set of pre-trained models for download. They vary in function for world generation and the acceleration of Physical AI. Below are the different models and their functions.
+
+#### Cosmos Predict-2
+
+Our best world foundation model so far—higher fidelity, flexible frame rates and resolutions, fewer hallucinations, and better control over text, objects, and motion in the video.
+
+Generate previews from text in under 4 seconds and up to 30 seconds of future-world video from a reference image or preview. Below is an example of using the model in `Python`:
+
+```python
+import torch
+from imaginaire.utils.io import save_image_or_video
+from cosmos_predict2.configs.base.config_video2world import PREDICT2_VIDEO2WORLD_PIPELINE_2B
+from cosmos_predict2.pipelines.video2world import Video2WorldPipeline
+
+# Create the video generation pipeline.
+
+pipe = Video2WorldPipeline.from_config(
+config=PREDICT2_VIDEO2WORLD_PIPELINE_2B,
+dit_path="checkpoints/nvidia/Cosmos-Predict2-2B-Video2World/model-720p-16fps.pt",
+text_encoder_path="checkpoints/google-t5/t5-11b",
+)
+
+# Specify the input image path and text prompt.
+
+image_path = "assets/video2world/example_input.jpg"
+prompt = """
+A high-definition video captures the precision of robotic welding in an industrial setting.
+The first frame showcases a robotic arm, equipped with a welding torch, positioned over a large metal structure.
+The welding process is in full swing, with bright sparks and intense light illuminating the scene, creating a vivid display of blue and white hues.
+A significant amount of smoke billows around the welding area, partially obscuring the view but emphasizing the heat and activity.
+The background reveals parts of the workshop environment, including a ventilation system and various pieces of machinery,
+indicating a busy and functional industrial workspace.
+As the video progresses, the robotic arm maintains its steady position, continuing the welding process and moving to its left.
+The welding torch consistently emits sparks and light, and the smoke continues to rise, diffusing slightly as it moves upward.
+The metal surface beneath the torch shows ongoing signs of heating and melting. The scene retains its industrial ambiance,
+with the welding sparks and smoke dominating the visual field, underscoring the ongoing nature of the welding operation.
+"""
+
+# Run the video generation pipeline.
+
+video = pipe(input_path=image_path, prompt=prompt)
+
+# Save the resulting output video.
+
+save_image_or_video(video, "output/test.mp4", fps=16)
+```
+
+For more information on using the model, see the [Cosmos Predict GitHub](https://github.com/nvidia-cosmos/cosmos-predict2?tab=readme-ov-file).
+
+This [article](https://developer.nvidia.com/blog/develop-custom-physical-ai-foundation-models-with-nvidia-cosmos-predict-2/) explains a possible usage pipeline for the model.
+
+#### Cosmos Transfer
+
+A family of highly performant, pre-trained world foundation models designed to generate videos aligned with input control conditions.
+
+The Cosmos Transfer1 models are a collection of diffusion-based world foundation models capable of generating dynamic, high-quality videos from text and control video inputs. They can serve as a foundation for various applications or research related to world generation. The models are ready for commercial use.
+
+For more information on using the model, see the [Cosmos Transfer1 GitHub](https://github.com/nvidia-cosmos/cosmos-transfer1).
+
+#### Cosmos Reason
+
+Physical AI models understand physical common sense and generate appropriate embodied decisions in natural language through long chain-of-thought reasoning processes.
+
+The Cosmos-Reason1 models are tuned with physical common sense and embodied reasoning data, using supervised fine-tuning and reinforcement learning. These are Physical AI models capable of understanding space, time, and fundamental principles of physics, and can serve as planning models to reason about an embodied agent’s next steps.
+
+For more information on using the model, see the [Cosmos Reason1 GitHub](https://github.com/nvidia-cosmos/cosmos-reason1).
+
+#### Cosmos Tokenizers
+
+Cosmos Tokenizer is a set of visual tokenizers for images and videos that offers different compression rates while maintaining high reconstruction quality. It serves as an efficient building block for image and video generation models based on diffusion and autoregressive approaches.
+
+There are two types of tokenizers:
+
+- **Continuous (C)**: Encodes visual data into continuous latent embeddings, as in latent diffusion models (e.g., Stable Diffusion). Ideal for models that generate data by sampling from continuous distributions.
+- **Discrete (D)**: Encodes visual data into discrete latent codes, mapping to quantized indices, as in autoregressive transformers (e.g., VideoPoet). Essential for models that optimize cross-entropy loss, such as GPT-like models.
+
+Each type has a variant for images (I) and videos (V):
+
+- **Cosmos-Tokenizer-CI**: Continuous for images
+- **Cosmos-Tokenizer-DI**: Discrete for images
+- **Cosmos-Tokenizer-CV**: Continuous for videos
+- **Cosmos-Tokenizer-DV**: Discrete for videos
+
+Given an image or video, Cosmos Tokenizer produces continuous latent or discrete tokens. It achieves spatial compression rates of 8x8 or 16x16 and temporal factors of 4x or 8x, totalling up to a 2048x compression factor (8x16x16). This is 8x more compression than state-of-the-art methods, while maintaining superior image quality and up to 12x speed over the best tokenizers currently available.
+
+In short, Cosmos Tokenizer combines efficiency, high compression, and quality, making it an advanced solution for generative AI applications involving images and videos.
+
+For more information on using the model, see the [Cosmos Tokenizer GitHub](https://github.com/NVIDIA/Cosmos-Tokenizer).
+
+#### Cosmos WFM Post-Training Samples
+
+Cosmos Sample Models for Autonomous Driving are a family of high-performance Cosmos foundation models, post-trained specifically for autonomous driving scenarios.
+
+These models are fine-tuned versions of the Cosmos World foundation models, capable of generating high-quality, multi-view consistent driving videos from text, image, or video inputs. They serve as versatile building blocks for various applications and research related to autonomous driving. Ready for commercial use, the models are available under the NVIDIA Open Model License Agreement.
+
+For more information on using the model, see the [Cosmos Predict GitHub](https://github.com/nvidia-cosmos/cosmos-predict2?tab=readme-ov-file).
+
+#### Cosmos Guardrails
+
+A family of highly performant, pre-trained world foundation models designed to generate videos and world states with physical awareness for the development of Physical AI. Cosmos Guardrail is a content safety model composed of three components that ensure content safety:
+
+1. Blocklist: An expert-curated keyword list used to filter edge cases and sensitive terms.
+
+2. Video Content Safety Filter: A multi-class classifier trained to distinguish between safe and unsafe frames in generated videos, using SigLIP embeddings for high-accuracy detection of inappropriate content.
+
+3. Face Blur Filter: A pixelation filter based on RetinaFace that identifies facial regions with high confidence and applies pixelation to any detections larger than 20x20 pixels, promoting anonymization and privacy in generated scenes.
+
+These components work together to ensure that both text prompts and generated video content meet the content safety standards required for commercial Physical AI applications.
+
+#### Cosmos Upsampler
+
+Cosmos-1.0-Prompt-Upsampler-Text2World is a large language model (LLM) designed to transform original prompts into more detailed and enriched versions. It enhances prompts by adding information and maintaining a consistent descriptive structure before they are used in a text-to-world model, which typically results in higher-quality outputs. This model is ready for commercial use.
+
+### Uses of Cosmos WFM
+
+Below are some of the different applications of the platform.
+
+#### Training autonomous cars
+
+A number of companies in the transportation sector have adopted the Cosmos WFM platform for **_Autonomous Vehicles (AV)_** solutions.
+
+- **_Waabi_**, a pioneer in generative AI for the physical world, starting with autonomous vehicles, is evaluating Cosmos in the context of data curation for AV software development and simulation.
+
+- **_Wayve_**, a company developing AI foundation models for autonomous driving, is evaluating Cosmos as a tool to research corner-case driving scenarios used for safety and validation.
+
+- **_Uber_**, the global ride-sharing giant, is partnering with NVIDIA to accelerate autonomous mobility. Uber’s joint driving data assets, combined with capabilities from the Cosmos platform and NVIDIA DGX Cloud, can help AV partners build stronger AI models even more efficiently.
+
+This [article](https://developer.nvidia.com/blog/simplify-end-to-end-autonomous-vehicle-development-with-new-nvidia-cosmos-world-foundation-models/) shows a way to simplify end-to-end autonomous vehicle development with the _Cosmos WFM_ platform.
+
+#### Synthetic dataset generation
+
+In recent years, with advances in computer vision and deep learning models, there has been a strong demand for large volumes of data to train these networks. In this context, one of the most promising applications of Cosmos is precisely the generation of synthetic data, especially where collecting real data is costly or unfeasible. Thus, Cosmos acts as an artificial extender of existing datasets, meeting the demand for trainable data mentioned above.
+
+
+
+_As an example, based on a short video or image showing a pedestrian crossing at a crosswalk, it is possible to simulate different weather conditions, lighting, times of day, different angles, etc. This diversity is very useful for training autonomous vehicles, for instance, as it greatly reduces the size of the real video training dataset._
+
+In this sense, **Cosmos Predict** proves to be the most suitable model, as its purpose is data generation itself.
+
+Additionally, an important discussion to be had is the **feasibility** of the application. For video generation, one of the simplest models is _Cosmos-Predict2-2B-Video2World_, with 2 billion parameters. Although this model is the simplest released by NVIDIA, it does not run locally on notebooks. Perhaps with a more powerful GPU it is possible to run it with limitations, but in general the computational cost is higher than a typical notebook can support. Thus, the alternative of using cloud computing arises, which also comes with associated financial costs.
+
+| Input image | Output video |
+| ---------------------------------------- | ---------------------------------- |
+|  |  |
+
+_Example of how Cosmos-Predict2-2B-Video2World can be used. With an image and text as input, a short video is generated. This strategy can be replicated for different situations and applications, such as the crosswalk example mentioned earlier._
+
+Another relevant point is the quality of **synthetic data**. Although visually realistic, this data may still contain biases or inconsistencies that affect model training. Therefore, it is necessary to use practices for validating generated outputs and comparing them with real reference data. This verification can be done with **Cosmos-Reason**, highlighted earlier for its capability to interpret videos, or even manually, depending on the size of the synthetic dataset.
+
+#### Other Applications
+
+Using the same approach as the previous application—where _Cosmos-Predict2-2B-Video2World_ is used to generate videos from input images or videos combined with a text prompt—opens the door to several other similar applications. Among them, the following stand out:
+
+- **Scene pre-visualization in films and games**: In the creative industry, the production of films, animations, and digital games goes through various stages of visual prototyping. Traditionally, this requires using 3D modeling tools, physical simulation, and rendering—processes that can be expensive and time-consuming. With Cosmos, however, it is possible to create previsualizations of entire scenes using only simple sketches and textual descriptions. For example, an artist can submit a photo of a landscape and add something like “strong wind swaying the trees at dusk.” The model then generates a short clip that shows this scene with movement, lighting, and weather, without needing to go through the modeling stage.
+
+- **Reconstruction of historical scenes for museums**: Cultural centers can also benefit greatly from using Cosmos. With it, it becomes possible to reconstruct scenes from the past from paintings or old photographs, allowing visitors greater engagement with the content on display and expanding their understanding of the historical context.
+
+## Portuguese
+
+### Introdução
+
O artigo da [Cosmos](https://arxiv.org/html/2501.03575v1), sugere uma série de possíveis aplicações da plataforma de World Foundation Models, aqui são discutidas algumas dessas possíveis aplicações, além dos diferentes modelos disponibilizados para tais aplicações.
-## Diferentes Modelos do Cosmos WFM
+### Diferentes Modelos do Cosmos WFM
A NVIDIA, através do site [nvidia Developer](https://developer.nvidia.com/cosmos?hitsPerPage=6), disponibiliza uma série de modelos pré-treinados para download. Eles variam em função, para geração de mundo, e aceleração de IA física. Abaixo estão listados os diferentes modelos e suas funções.
-### Cosmos Predict-2
+#### Cosmos Predict-2
Nosso melhor modelo fundamental de mundo até agora—maior fidelidade, taxas de quadros e resoluções flexíveis, menos alucinações e melhor controle de texto, objetos e movimento no vídeo.
@@ -55,7 +226,7 @@ Para mais informações sobre a utilização do modelo, utilizar [github do cosm
Esse [artigo](https://developer.nvidia.com/blog/develop-custom-physical-ai-foundation-models-with-nvidia-cosmos-predict-2/) explica uma possível pipeline de utilização do modelo.
-### Cosmos Transfer
+#### Cosmos Transfer
Uma família de modelos fundamentais de mundo pré-treinados altamente performáticos, projetados para gerar vídeos alinhados com as condições de controle de entrada.
@@ -63,7 +234,7 @@ Os modelos Cosmos Transfer1 são uma coleção de modelos fundamentais de mundo
Para mais informações sobre a utilização do modelo, utilizar [github do cosmos tranfer1](https://github.com/nvidia-cosmos/cosmos-transfer1).
-### Cosmos Reason
+#### Cosmos Reason
Modelos de IA Física compreendem o senso comum físico e geram decisões corporificadas apropriadas em linguagem natural por meio de longos processos de raciocínio em cadeia.
@@ -71,7 +242,7 @@ Os modelos **_Cosmos-Reason1_** são ajustados com dados de senso comum físico
Para mais informações sobre a utilização do modelo, utilizar [github do cosmos reason1](https://github.com/nvidia-cosmos/cosmos-reason1).
-### Cosmos Tokenizers
+#### Cosmos Tokenizers
O Cosmos Tokenizer é um conjunto de tokenizadores visuais para imagens e vídeos que oferece diferentes taxas de compressão, mantendo alta qualidade de reconstrução. Ele serve como um bloco eficiente para modelos de geração de imagens e vídeos baseados em difusão e em abordagens autoregressivas.
@@ -93,7 +264,7 @@ Em resumo, Cosmos Tokenizer combina eficiência, alta compressão e qualidade, s
Para mais informações sobre a utilização do modelo, utilizar [github do cosmos tokenizer](https://github.com/NVIDIA/Cosmos-Tokenizer).
-### Cosmos WFM Post-Training Samples
+#### Cosmos WFM Post-Training Samples
Modelos Cosmos Sample para Condução Autônoma são uma família de modelos fundamentais Cosmos de alto desempenho, pós-treinados especialmente para cenários de condução autônoma.
@@ -101,26 +272,28 @@ Esses modelos são versões ajustadas dos modelos fundamentais Cosmos World, cap
Para mais informações sobre a utilização do modelo, utilizar [github do cosmos predict](https://github.com/nvidia-cosmos/cosmos-predict2?tab=readme-ov-file).
-### Cosmos Guardrails
+#### Cosmos Guardrails
Uma família de modelos fundamentais de mundo pré-treinados e altamente performáticos, projetados para gerar vídeos e estados de mundo com consciência física para o desenvolvimento de IA física.
O Cosmos Guardrail é um modelo de segurança de conteúdo composto por três componentes que garantem a segurança do conteúdo:
1. Blocklist: Uma lista de palavras-chave selecionadas por especialistas utilizada para filtrar casos extremos e termos sensíveis.
+
2. Video Content Safety Filter: Um classificador de múltiplas classes treinado para distinguir entre quadros seguros e inseguros em vídeos gerados, utilizando embeddings SigLIP para alta precisão na detecção de conteúdo inadequado.
+
3. Face Blur Filter: Um filtro de pixelização baseado no RetinaFace, que identifica com alta confiança regiões faciais e aplica pixelização em quaisquer detecções maiores que 20x20 pixels, promovendo anonimização e privacidade nas cenas geradas.
Esses componentes atuam de forma integrada para garantir que tanto os prompts de texto quanto o conteúdo de vídeo gerado atendam aos padrões de segurança de conteúdo necessários para aplicações comerciais em IA física
-### Cosmos Upsampler
+#### Cosmos Upsampler
O Cosmos-1.0-Prompt-Upsampler-Text2World é um modelo de linguagem de grande porte (LLM) projetado para transformar prompts originais em versões mais detalhadas e enriquecidas. Ele aprimora os prompts adicionando informações e mantendo uma estrutura descritiva consistente antes que sejam utilizados em um modelo text-to-world, o que normalmente resulta em saídas de maior qualidade. Este modelo está pronto para uso comercial.
-## Usos do Cosmos WFM
+### Usos do Cosmos WFM
Abaixo são citadas algumas das diferentes aplicações da plataforma.
-### Treinamento de Carros autônomos
+#### Treinamento de Carros autônomos
Uma série de empresas do setor de transportes adotaram a plataforma _Cosmos WFM_ para soluções de **_AV (Autonomous Vehicles)_**
@@ -132,11 +305,11 @@ Uma série de empresas do setor de transportes adotaram a plataforma _Cosmos WFM
Esse [artigo](https://developer.nvidia.com/blog/simplify-end-to-end-autonomous-vehicle-development-with-new-nvidia-cosmos-world-foundation-models/) mostra uma forma de simplificar desenvolvimento end-to-end de veículos autônomos com a plataforma _Cosmos WFM_.
-### Geração de datasets sintéticos
+#### Geração de datasets sintéticos
Nos últimos anos, com o avanço dos modelos de visão computacional e deep learning, surgiu uma forte demanda por grandes volumes de dados para o treinamento dessas redes. Nesse cenário, uma das aplicações mais promissoras do Cosmos é justamente a geração de dados sintéticos, especialmente em contextos onde a coleta de dados reais é custosa, ou inviável. Assim, o Cosmos entra como um extensor artificial de datasets já existentes, suprindo a demanda por dados treináveis mencionada.
-
+
> Como exemplo, com base em um vídeo curto ou imagem mostrando um pedestre atravessando na faixa, é possível simular diferentes condições climáticas, de iluminação, de horários, com ângulos diferentes, etc. Essa diversidade vem a ser muito útil para o treinamento de veículos autônomos, por exemplo, já que reduz muito o tamanho do dataset de vídeos reais de treinamento.
@@ -144,15 +317,15 @@ Nesse sentido, o **Cosmos Predict** se mostra como o modelo mais adequado, já q
Ademais, uma discussão importante a ser feita é sobre a **viabilidade** da aplicação. Para a geração de vídeos, um dos modelos mais simples é o _Cosmos-Predict2-2B-Video2World_, com 2 Bilhões de parâmetros. Esse modelo, embora seja o mais simples disponibilizado pela Nvidia, não roda localmente em notebooks. Talvez com uma GPU mais potente seja possível rodar com limitações, mas de forma geral o custo computacional é mais alto do que um notebook normal suporta. Assim, abre-se a alternativa de usar cloud computing, que também vem com custos financeiros associados.
-| Input image | Output video |
-| ------------------------------------- | ------------------------------- |
-|  |  |
+| Input image | Output video |
+| ---------------------------------------- | ---------------------------------- |
+|  |  |
> Exemplo de como o _Cosmos-Predict2-2B-Video2World_ pode ser usado. Com uma imagem e texto de input, gera-se um vídeo curto. Essa estratégia pode ser simulada para diferentes situações e aplicações, como por exemplo a da faixa de pedestres mencionada anteriormente.
Outro ponto relevante é a **qualidade dos dados sintéticos**. Embora visualmente realistas, esses dados ainda podem conter vieses ou inconsistências que afetam o treinamento dos modelos. Dessa forma, faz-se necessário o uso de práticas de validação dos outputs gerados e comparação com dados reais de referência. Essa verificação pode ser feita com o **Cosmos-Reason**, destacado anteriormente pela sua capacidade interpretativa de vídeos, ou mesmo manualmente, a depender do tamanho do dataset sintético.
-### Outras Aplicações
+#### Outras Aplicações
Usar a mesma abordagem da aplicação anterior, em que usamos o _Cosmos-Predict2-2B-Video2World_ para gerar vídeos a partir de imagens ou vídeos de entrada somados a um input de texto, abre portas para várias outras aplicações de cunho semelhante. Dentre elas, podemos destacar:
@@ -160,7 +333,7 @@ Usar a mesma abordagem da aplicação anterior, em que usamos o _Cosmos-Predict2
- **Reconstrução de cenas históricas para museus:** Centros culturais também podem se beneficiar muito do uso do Cosmos. Com ele, torna-se possível reconstruir cenas do passado a partir de pinturas ou fotografias antigas, o que permite ao visitante um engajamento maior com o conteúdo exposto e amplia a sua compreensão do contexto histórico.
-## Referências
+### Referências
- [NVIDIA Cosmos for Developers](https://developer.nvidia.com/cosmos?hitsPerPage=6)
- [World Foundation Models: 10 Use Cases & Examples [2025]](https://research.aimultiple.com/world-foundation-model/)
diff --git a/docs/cosmos_applications/src/example_input.jpg b/docs/cosmos_applications/images/example_input.jpg
similarity index 100%
rename from docs/cosmos_applications/src/example_input.jpg
rename to docs/cosmos_applications/images/example_input.jpg
diff --git a/docs/cosmos_applications/src/output.mp4 b/docs/cosmos_applications/images/output.mp4
similarity index 100%
rename from docs/cosmos_applications/src/output.mp4
rename to docs/cosmos_applications/images/output.mp4
diff --git a/docs/cosmos_applications/src/pedestrian_crosswalk.webp b/docs/cosmos_applications/images/pedestrian_crosswalk.webp
similarity index 100%
rename from docs/cosmos_applications/src/pedestrian_crosswalk.webp
rename to docs/cosmos_applications/images/pedestrian_crosswalk.webp
diff --git a/docs/diffusion.md b/docs/diffusion.md
deleted file mode 100644
index b889daf..0000000
--- a/docs/diffusion.md
+++ /dev/null
@@ -1,137 +0,0 @@
-## Modelos de Difusão em World Foundation Models (WFMs)
-
-No contexto dos World Foundation Models (WFMs), **ele transforma ruído em uma simulação de vídeo do mundo.**
-
-Analogia: "Pense em um modelo de difusão como um artista que começa com uma tela cheia de ruído aleatório (como uma "chuva" de TV antiga) e, gradualmente, passo a passo, aprende a remover esse ruído, revelando uma imagem ou vídeo coerente e significativo."
-
-
-
-### Tokenização de Vídeo: Transformando Vídeos em "Latentes Contínuos"
-
-Assim como os modelos autoregressivos, os modelos de difusão precisam processar vídeos em um formato mais gerenciável para sua operação.
-
-- Tokens Contínuos: Para modelos de difusão, os vídeos são transformados em embeddings latentes contínuos (vetores de números decimais). Pense neles como uma representação compacta e fluida do vídeo, em oposição aos "tokens discretos" (números inteiros) usados pelos modelos autoregressivos.
-
-- Cosmos Continuous Tokenizer (Cosmos-1.0-Tokenizer-CV8x8x8): Este é o componente responsável por essa transformação. Ele comprime o vídeo de entrada em uma representação latente de menor dimensão, preservando a maior parte da informação visual. Este tokenizer possui uma arquitetura de codificador-decodificador que opera no espaço wavelet para maior compressão e preservação de informações semânticas, além de um design causal temporal (a codificação de quadros atuais não depende de quadros futuros, crucial para aplicações de IA Física).
-
-### Formulação: O Processo de Denoising (Remoção de Ruído)
-
-O cerne do modelo de difusão é o processo iterativo de "denoising" (remoção de ruído).
-
-#### Detalhes da Formulação
-
-| **Aspecto** | **Descrição** |
-| :------------------------: | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
-| Adição e Remoção de Ruído | Durante o treinamento, **ruído gaussiano (aleatório)** é progressivamente adicionado a um vídeo real. O modelo é, então, treinado para inverter esse processo, aprendendo a remover o ruído em cada etapa para reconstruir o vídeo original a partir de uma versão ruidosa.
|
-| Função Denoising (D_theta) | O modelo de difusão utiliza uma rede neural **D_theta** (chamada "denoiser") treinada para estimar o ruído presente em uma amostra corrompida (vídeo com ruído) e, consequentemente, removê-lo para chegar à versão limpa do vídeo. |
-| Função de Perda | O treinamento emprega uma função de perda de **"denoising score matching"** que penaliza a diferença entre o ruído previsto pelo modelo e o ruído real adicionado. Uma técnica de **ponderação baseada em incerteza (mu(sigma))** é utilizada para gerenciar o aprendizado em diferentes níveis de ruído, tratando-o como um problema de aprendizado multi-tarefa. |
-
-
-
-### Arquitetura do Modelo: Como o Denoising é Construído
-
-A rede D_theta do modelo de difusão é uma adaptação de uma arquitetura Transformer, otimizada para dados visuais e controle.
-
-#### Componentes Arquitetônicos Chave
-
-| **Componente** | **Descrição** |
-| :-------------------------------------------: | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| Patchificação 3D | As representações latentes de entrada são convertidas em **"patches" (pedaços cúbicos) tridimensionais**, que são então "achatados" em uma sequência unidimensional. Isso prepara os dados para serem processados eficientemente pelo Transformer.
|
-| Embeddings Posicionais Híbridos | Essenciais para a compreensão espacial e temporal: • **Rotary Position Embedding (RoPE) Fatorado em 3D**: Ajuda o modelo a entender as posições relativas dos tokens nas dimensões temporal, de altura e de largura, permitindo a geração de vídeos de tamanhos e durações arbitrárias, compatível com diferentes taxas de quadros (FPS). • **Embedding Posicional Absoluto (Aprendível)**: Um embedding adicional usado em cada bloco Transformer que, combinado com RoPE, melhora o desempenho, reduz a perda de treinamento e minimiza artefatos de "morphing". |
-| Cross-Attention para Condicionamento de Texto | Camadas integradas que permitem ao modelo gerar vídeos com base em descrições de texto, incorporando informações de **embeddings de texto** (gerados pelo **T5-XXL**) no processo de denoising. |
-| QK-Normalização (QKNorm) | Normaliza os vetores de "query" (Q) e "key" (K) antes da operação de atenção, o que aumenta a **estabilidade do treinamento**, especialmente nas fases iniciais, prevenindo a saturação da atenção. |
-| AdaLN-LoRA | Uma otimização arquitetônica que **reduz significativamente a contagem de parâmetros** (ex: 36% para o modelo de 7B parâmetros) sem comprometer o desempenho, tornando o modelo mais eficiente em termos de memória e computação. |
-
-### Estratégia de Treinamento: Como o Modelo Aprende a "Pintar"
-
-Os modelos de difusão são treinados em várias etapas para otimizar seu desempenho e generalização.
-
-| **Aspecto** | **Descrição** |
-| :---------------------------------------------: | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| Treinamento Conjunto Imagem e Vídeo | Para alavancar a vasta quantidade de dados de imagens, uma estratégia de **otimização alternada** intercala lotes de dados de imagem e vídeo. É usada uma **normalização específica de domínio** para alinhar as distribuições latentes e encorajar uma representação isotrópica gaussiana. A perda de denoising para vídeos é escalonada para lidar com a convergência mais lenta.
|
-| Treinamento Progressivo | O modelo é treinado progressivamente, iniciando com **resoluções e durações de vídeo menores** (ex: 512p com 57 quadros) e avançando para **resoluções e durações maiores** (ex: 720p com 121 quadros). Uma fase de **"resfriamento" (cooling-down)** com dados de alta qualidade e uma taxa de aprendizado decrescente refina ainda mais o modelo.
|
-| Treinamento Multi-Aspecto | Os dados são organizados em "buckets" com base em suas **proporções de aspecto** (ex: 1:1, 16:9) para acomodar a diversidade de conteúdo. **Preenchimento (padding) com reflexão** é usado para pixels ausentes durante o processamento em lote. |
-| Treinamento com Precisão Mista | Para eficiência, os pesos do modelo são mantidos em **BF16 e FP32**. O BF16 é usado para os passes de _forward_ e _backward_, e o FP32 para as atualizações de parâmetros, garantindo **estabilidade numérica**. |
-| Condicionamento de Texto | Utiliza o **T5-XXL** como codificador de texto. Modelos **Text2World** são capazes de gerar vídeo a partir de uma entrada textual. |
-| Condicionamento de Imagem e Vídeo (Video2World) | Modelos **Video2World** estendem os modelos Text2World para aceitar quadros anteriores (imagem ou vídeo) como condição para gerar quadros futuros. Ruído adicional é introduzido nos quadros condicionais durante o treinamento para aumentar a robustez. |
-
-### Otimização de Inferência: Tornando a Geração Rápida
-
-Embora os modelos de difusão sejam inerentemente mais lentos devido ao seu processo iterativo de denoising, otimizações significativas são aplicadas para acelerar a geração.
-
-#### Técnicas de Otimização de Inferência
-
-| **Técnica** | **Descrição** |
-| :-----------------------------------: | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
-| FSDP (Fully Sharded Data Parallelism) | Distribui os parâmetros do modelo, gradientes e estados do otimizador por múltiplos dispositivos (GPUs), resultando em significativa **economia de memória** e permitindo o uso de modelos maiores.
|
-| Context Parallelism (CP) | Divide a computação e as ativações ao longo da dimensão da sequência, distribuindo-as entre GPUs. Esta técnica é crucial para lidar com **contextos longos de vídeo**, onde a quantidade de dados a ser processada é muito grande.
|
-
-### Prompt Upsampler: Para Entradas de Texto do Usuário
-
-- Para preencher a lacuna entre as prompts de texto curtas e variadas fornecidas pelos usuários e as descrições de vídeo detalhadas usadas no treinamento dos WFMs, um "Prompt Upsampler" é desenvolvido.
-
-- Ele transforma as prompts originais em versões mais detalhadas e ricas que se alinham com a distribuição das prompts de treinamento, melhorando a qualidade do vídeo gerado. Para modelos Text2World, o Mistral-NeMo-12B-Instruct é usado para isso; para Video2World, o Pixtral-12B é utilizado.
-
-### Decodificador de Difusão: Melhorando a Qualidade Visual do Autoregressivo
-
-Embora este seja uma parte do modelo de difusão, ele tem um papel especial de pós-otimização para outros modelos:
-
-- Para os modelos autoregressivos (que podem gerar vídeos borrados devido à tokenização agressiva), um decodificador de difusão mais poderoso é usado como uma "pós-otimização".
-
-- Este decodificador pega os tokens discretos (saída do modelo autoregressivo) e os "traduz" de volta para tokens contínuos de maior qualidade, que são então convertidos em vídeos RGB de alta qualidade. É como refinar um rascunho em uma obra de arte acabada.
-
-### Equações
-
-**Perda do Denoising:** `ℒ(𝐷𝜃, 𝜎) = Ex0,n [︁⃦⃦ 𝐷𝜃(x0 + n;𝜎)− x0 ⃦⃦2 2 ]︁`
-
-- `x0 (lê-se "x zero")`: Representa o vídeo original, limpo (a "tela perfeita")
-- `n`: Representa o ruído gaussiano aleatório que foi adicionado ao vídeo x0
-- `𝜎 (sigma)`: Indica o nível de ruído naquele momento. Vídeos com mais ruído terão um 𝜎 maior.
-- `x0 + n`: É o vídeo com ruído (a "tela suja") que é dado como entrada para o nosso modelo
-- `𝐷𝜃`: É a nossa rede neural "denoiser". O 𝜃 (theta) representa todos os parâmetros (pesos) que a rede precisa aprender durante o treinamento
-- `𝐷𝜃(x0 + n;𝜎)`: É o que o modelo 𝐷𝜃 prevê que seja o vídeo original limpo (x0), dado o vídeo ruidoso (x0 + n) e o nível de ruído (𝜎)
-- `𝐷𝜃(x0 + n;𝜎)− x0`: Esta é a diferença entre o que o modelo previu e o vídeo real e limpo (x0)
-- ` ... ⃦⃦2 2 ]︁`: Isso significa o quadrado da norma L2, que é uma forma de medir a "distância" ou o "erro" entre a previsão do modelo e a realidade. Basicamente, estamos pegando a diferença, elevando ao quadrado (para que valores negativos e positivos contem igualmente) e somando tudo. Queremos que esse erro seja o menor possível
-- `E_x0,n [ ... ]`: Significa a esperança (ou média) sobre diferentes vídeos limpos (x0) e diferentes tipos de ruído (n)
-
-**Perda total de Treinamento:** `ℒ(𝐷𝜃) = E𝜎 [ 𝜆(𝜎) ℒ(𝐷𝜃, 𝜎) + 𝑢(𝜎) ]`
-
-- `E𝜎 [ ... ]`: Significa a esperança (média) sobre diferentes níveis de ruído (𝜎). O modelo é treinado para lidar com todos os níveis de ruído, do quase limpo ao totalmente ruidoso.
-- `𝜆(𝜎) (lambda de sigma)`: É uma função de ponderação. Ela ajusta a importância de cada nível de ruído (𝜎) na perda total, para que o modelo preste atenção a todos eles. Inicialmente, ela garante que todos os níveis de ruído contribuam igualmente para o aprendizado.
-- `𝑢(𝜎) (u de sigma)`: É uma função de incerteza contínua. O modelo também aprende essa função. Se o modelo está "incerto" sobre como remover o ruído em um certo nível 𝜎, ele se penaliza, incentivando-o a reduzir essa incerteza. Isso ajuda a otimização em diferentes níveis de ruído, tratando-os como um problema de aprendizado multi-tarefa
-
-**Função de Ponderação:** `𝜆(𝜎) = (︀ 𝜎2 + 𝜎2data )︀ / (𝜎 · 𝜎data)`
-
-- `𝜎data`: É o desvio padrão dos dados de treinamento. Essa equação define como o 𝜆(𝜎) calcula o peso de cada nível de ruído, inicialmente visando uma contribuição igualitária
-
-**Distribuição do Nível de Ruído:** `ln(𝜎) ∼ 𝒩 (︀ 𝑃mean, 𝑃 2std )︀`
-
-- Isso descreve como os níveis de ruído (𝜎) são escolhidos durante o treinamento. O logaritmo natural (ln) de 𝜎 segue uma distribuição normal (𝒩), com uma média (𝑃mean) e um desvio padrão (𝑃std) definidos. Isso garante que o modelo veja uma boa variedade de níveis de ruído
-
-### Resultados e Aplicações
-
-Os modelos de difusão Cosmos-1.0 (7B e 14B) são capazes de gerar vídeos com alta qualidade visual, dinâmicas de movimento e alinhamento preciso com o texto. O modelo de 14B demonstra uma capacidade aprimorada de capturar detalhes visuais mais finos e padrões de movimento mais intrincados.
-
-Eles são utilizados em diversas aplicações de IA Física, como:
-
-- Controle de Câmera: Permitem gerar mundos virtuais navegáveis com base em uma imagem de referência e trajetórias de câmera, mantendo a coerência 3D e temporal.
-
-- Manipulação Robótica: Podem ser ajustados para prever vídeos de robôs seguindo instruções de texto ou sequências de ações.
-
-- Condução Autônoma: São adaptados para criar modelos de mundo multi-visão para cenários de condução, gerando vídeos de seis câmeras simultaneamente e até seguindo trajetórias de veículos.
-
-- Modelos de difusão baseados em Transformer são frequentemente capazes de incorporar diversos sinais de controle.
-
-- As avaliações mostram que os WFMs baseados em difusão entregam melhor qualidade de geração e maior consistência 3D em comparação com as linhas de base e os modelos autoregressivos em certas condições.
-
-### Limitações
-
-Apesar dos avanços, os modelos de difusão para simulação do mundo ainda enfrentam desafios comuns aos WFMs:
-
-- Falta de Permanência de Objetos: Objetos podem desaparecer ou aparecer inesperadamente.
-
-- Imprecisões em Dinâmicas com Contato: Interações físicas complexas, como colisões, ainda são difíceis de modelar com precisão.
-
-- Inconsistência no Seguimento de Instruções: O modelo nem sempre segue as instruções de texto de forma totalmente precisa.
-
-- Aderência às Leis da Física: A gravidade, interações de luz e dinâmicas de fluidos ainda não são perfeitamente simuladas.
diff --git a/docs/diffusion/diffusion.md b/docs/diffusion/diffusion.md
new file mode 100644
index 0000000..7574ce9
--- /dev/null
+++ b/docs/diffusion/diffusion.md
@@ -0,0 +1,333 @@
+# Diffusion models in World Foundation Models (WFMs)
+
+**_Authors / Autores: [@Nanashii76](http://github.com/Nanashii76)_**
+
+## Português
+
+No contexto dos World Foundation Models (WFMs), **ele transforma ruído em uma simulação de vídeo do mundo.**
+
+Analogia: "Pense em um modelo de difusão como um artista que começa com uma tela cheia de ruído aleatório (como uma "chuva" de TV antiga) e, gradualmente, passo a passo, aprende a remover esse ruído, revelando uma imagem ou vídeo coerente e significativo."
+
+
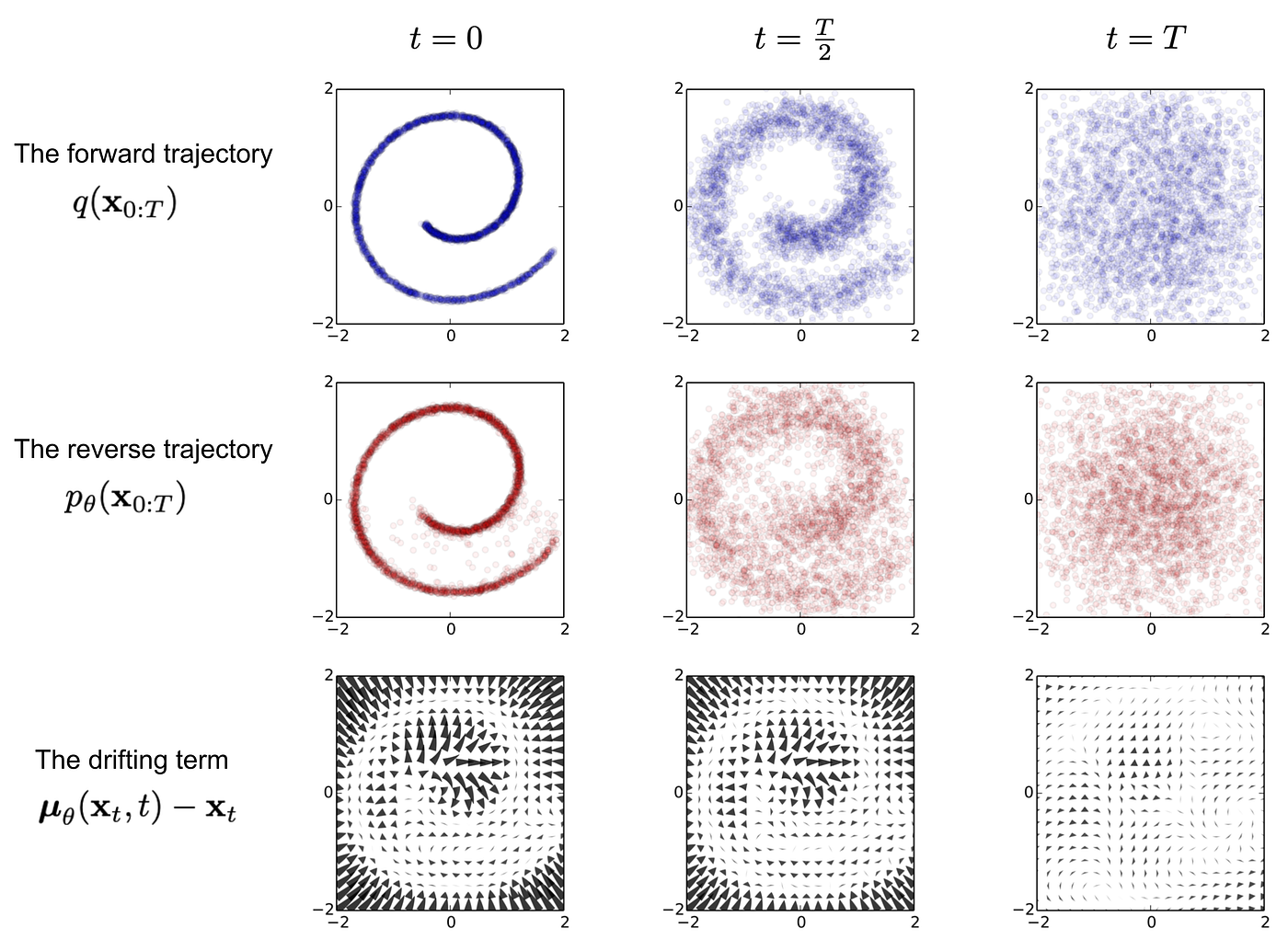
+_"Figura S1.1-F1-ptbr — Modelo de ruído"_
+
+### Tokenização de Vídeo: Transformando Vídeos em "Latentes Contínuos"
+
+Assim como os modelos autoregressivos, os modelos de difusão precisam processar vídeos em um formato mais gerenciável para sua operação.
+
+- Tokens Contínuos: Para modelos de difusão, os vídeos são transformados em embeddings latentes contínuos (vetores de números decimais). Pense neles como uma representação compacta e fluida do vídeo, em oposição aos "tokens discretos" (números inteiros) usados pelos modelos autoregressivos.
+
+- Cosmos Continuous Tokenizer (Cosmos-1.0-Tokenizer-CV8x8x8): Este é o componente responsável por essa transformação. Ele comprime o vídeo de entrada em uma representação latente de menor dimensão, preservando a maior parte da informação visual. Este tokenizer possui uma arquitetura de codificador-decodificador que opera no espaço wavelet para maior compressão e preservação de informações semânticas, além de um design causal temporal (a codificação de quadros atuais não depende de quadros futuros, crucial para aplicações de IA Física).
+
+### Formulação: O Processo de Denoising (Remoção de Ruído)
+
+O cerne do modelo de difusão é o processo iterativo de "denoising" (remoção de ruído).
+
+#### Detalhes da Formulação
+
+| **Aspecto** | **Descrição** |
+| :-------------------------------------: | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Adição e Remoção de Ruído | Durante o treinamento, **ruído gaussiano (aleatório)** é progressivamente adicionado a um vídeo real. O modelo é, então, treinado para inverter esse processo, aprendendo a remover o ruído em cada etapa para reconstruir o vídeo original a partir de uma versão ruidosa. |
+| Função Denoising ($\mathcal{D}_\theta$) | O modelo de difusão utiliza uma rede neural $\mathcal{D}_\theta$ (chamada "denoiser") treinada para estimar o ruído presente em uma amostra corrompida (vídeo com ruído) e, consequentemente, removê-lo para chegar à versão limpa do vídeo. |
+| Função de Perda | O treinamento emprega uma função de perda de **"denoising score matching"** que penaliza a diferença entre o ruído previsto pelo modelo e o ruído real adicionado. Uma técnica de **ponderação baseada em incerteza ($\mu(\sigma)$)** é utilizada para gerenciar o aprendizado em diferentes níveis de ruído, tratando-o como um problema de aprendizado multi-tarefa. |
+
+
+_"Figura S1.1-F2-ptbr — Remoção de ruidos em difusão"_
+
+### Arquitetura do Modelo: Como o Denoising é Construído
+
+A rede $\mathcal{D}_\theta$ do modelo de difusão é uma adaptação de uma arquitetura Transformer, otimizada para dados visuais e controle.
+
+#### Componentes Arquitetônicos Chave
+
+| **Componente** | **Descrição** |
+| :-------------------------------------------: | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Patchificação 3D | As representações latentes de entrada são convertidas em **"patches" (pedaços cúbicos) tridimensionais**, que são então "achatados" em uma sequência unidimensional. Isso prepara os dados para serem processados eficientemente pelo Transformer.
|
+| Embeddings Posicionais Híbridos | Essenciais para a compreensão espacial e temporal: • **Rotary Position Embedding (RoPE) Fatorado em 3D**: Ajuda o modelo a entender as posições relativas dos tokens nas dimensões temporal, de altura e de largura, permitindo a geração de vídeos de tamanhos e durações arbitrárias, compatível com diferentes taxas de quadros (FPS). • **Embedding Posicional Absoluto (Aprendível)**: Um embedding adicional usado em cada bloco Transformer que, combinado com RoPE, melhora o desempenho, reduz a perda de treinamento e minimiza artefatos de "morphing". |
+| Cross-Attention para Condicionamento de Texto | Camadas integradas que permitem ao modelo gerar vídeos com base em descrições de texto, incorporando informações de **embeddings de texto** (gerados pelo **T5-XXL**) no processo de denoising. |
+| QK-Normalização (QKNorm) | Normaliza os vetores de "query" (Q) e "key" (K) antes da operação de atenção, o que aumenta a **estabilidade do treinamento**, especialmente nas fases iniciais, prevenindo a saturação da atenção. |
+| AdaLN-LoRA | Uma otimização arquitetônica que **reduz significativamente a contagem de parâmetros** (ex: 36% para o modelo de 7B parâmetros) sem comprometer o desempenho, tornando o modelo mais eficiente em termos de memória e computação. |
+
+### Estratégia de Treinamento: Como o Modelo Aprende a "Pintar"
+
+Os modelos de difusão são treinados em várias etapas para otimizar seu desempenho e generalização.
+
+| **Aspecto** | **Descrição** |
+| :---------------------------------------------: | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Treinamento Conjunto Imagem e Vídeo | Para alavancar a vasta quantidade de dados de imagens, uma estratégia de **otimização alternada** intercala lotes de dados de imagem e vídeo. É usada uma **normalização específica de domínio** para alinhar as distribuições latentes e encorajar uma representação isotrópica gaussiana. A perda de denoising para vídeos é escalonada para lidar com a convergência mais lenta.
|
+| Treinamento Progressivo | O modelo é treinado progressivamente, iniciando com **resoluções e durações de vídeo menores** (ex: 512p com 57 quadros) e avançando para **resoluções e durações maiores** (ex: 720p com 121 quadros). Uma fase de **"resfriamento" (cooling-down)** com dados de alta qualidade e uma taxa de aprendizado decrescente refina ainda mais o modelo.
|
+| Treinamento Multi-Aspecto | Os dados são organizados em "buckets" com base em suas **proporções de aspecto** (ex: 1:1, 16:9) para acomodar a diversidade de conteúdo. **Preenchimento (padding) com reflexão** é usado para pixels ausentes durante o processamento em lote. |
+| Treinamento com Precisão Mista | Para eficiência, os pesos do modelo são mantidos em **BF16 e FP32**. O BF16 é usado para os passes de _forward_ e _backward_, e o FP32 para as atualizações de parâmetros, garantindo **estabilidade numérica**. |
+| Condicionamento de Texto | Utiliza o **T5-XXL** como codificador de texto. Modelos **Text2World** são capazes de gerar vídeo a partir de uma entrada textual. |
+| Condicionamento de Imagem e Vídeo (Video2World) | Modelos **Video2World** estendem os modelos Text2World para aceitar quadros anteriores (imagem ou vídeo) como condição para gerar quadros futuros. Ruído adicional é introduzido nos quadros condicionais durante o treinamento para aumentar a robustez. |
+
+### Otimização de Inferência: Tornando a Geração Rápida
+
+Embora os modelos de difusão sejam inerentemente mais lentos devido ao seu processo iterativo de denoising, otimizações significativas são aplicadas para acelerar a geração.
+
+#### Técnicas de Otimização de Inferência
+
+| **Técnica** | **Descrição** |
+| :-----------------------------------: | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
+| FSDP (Fully Sharded Data Parallelism) | Distribui os parâmetros do modelo, gradientes e estados do otimizador por múltiplos dispositivos (GPUs), resultando em significativa **economia de memória** e permitindo o uso de modelos maiores.
|
+| Context Parallelism (CP) | Divide a computação e as ativações ao longo da dimensão da sequência, distribuindo-as entre GPUs. Esta técnica é crucial para lidar com **contextos longos de vídeo**, onde a quantidade de dados a ser processada é muito grande.
|
+
+### Prompt Upsampler: Para Entradas de Texto do Usuário
+
+- Para preencher a lacuna entre as prompts de texto curtas e variadas fornecidas pelos usuários e as descrições de vídeo detalhadas usadas no treinamento dos WFMs, um "Prompt Upsampler" é desenvolvido.
+
+- Ele transforma as prompts originais em versões mais detalhadas e ricas que se alinham com a distribuição das prompts de treinamento, melhorando a qualidade do vídeo gerado. Para modelos Text2World, o Mistral-NeMo-12B-Instruct é usado para isso; para Video2World, o Pixtral-12B é utilizado.
+
+### Decodificador de Difusão: Melhorando a Qualidade Visual do Autoregressivo
+
+Embora este seja uma parte do modelo de difusão, ele tem um papel especial de pós-otimização para outros modelos:
+
+- Para os modelos autoregressivos (que podem gerar vídeos borrados devido à tokenização agressiva), um decodificador de difusão mais poderoso é usado como uma "pós-otimização".
+
+- Este decodificador pega os tokens discretos (saída do modelo autoregressivo) e os "traduz" de volta para tokens contínuos de maior qualidade, que são então convertidos em vídeos RGB de alta qualidade. É como refinar um rascunho em uma obra de arte acabada.
+
+### Equações
+
+#### Perda do Denoising:
+
+$$\mathcal{L}(\mathcal{D}_\theta, \sigma) = \mathbb{E}_{x_0, n} ||\mathcal{D}_\theta(x_0 + n; \sigma) - x_0||_2^2$$
+
+Onde:
+
+- $x_0$ (lê-se "x zero"): Representa o vídeo original, limpo (a "tela perfeita")
+
+- $n$: Representa o ruído gaussiano aleatório que foi adicionado ao vídeo x_0
+
+- $\sigma$ (sigma): Indica o nível de ruído naquele momento. Vídeos com mais ruído terão um \sigma maior.
+
+- $x_0 + n$: É o vídeo com ruído (a "tela suja") que é dado como entrada para o nosso modelo
+
+- $\mathcal{D}_\theta$: É a nossa rede neural "denoiser". O \theta (theta) representa todos os parâmetros (pesos) que a rede precisa aprender durante o treinamento
+
+- $\mathcal{D}_\theta(x_0 + n;\sigma)$: É o que o modelo $\mathcal{D}_\theta$ prevê que seja o vídeo original limpo ($x_0$), dado o vídeo ruidoso ($x_0 + n$) e o nível de ruído ($\sigma$)
+
+- $\mathcal{D}_\theta(x_0 + n;\sigma)− x_0$: Esta é a diferença entre o que o modelo previu e o vídeo real e limpo ($x_0$)
+
+- $||...||_2^2$: Isso significa o quadrado da norma L2, que é uma forma de medir a "distância" ou o "erro" entre a previsão do modelo e a realidade. Basicamente, estamos pegando a diferença, elevando ao quadrado (para que valores negativos e positivos contem igualmente) e somando tudo. Queremos que esse erro seja o menor possível
+
+- $\mathbb{E}_{x_0, n}|| ... ||$: Significa a esperança (ou média) sobre diferentes vídeos limpos ($x_0$) e diferentes tipos de ruído (n)
+
+#### Perda total de Treinamento:
+
+$$\mathcal{L}(\mathcal{D}_\theta) = \mathbb{E}_\sigma [\lambda(\sigma) \cdot \mathcal{L}(\mathcal{D}_0, \sigma) + u(\sigma)]$$
+
+Onde:
+
+- $\mathbb{E}_\sigma[ ... ]$: Significa a esperança (média) sobre diferentes níveis de ruído ($\sigma$). O modelo é treinado para lidar com todos os níveis de ruído, do quase limpo ao totalmente ruidoso.
+
+- $\lambda(\sigma)$ (lambda de sigma): É uma função de ponderação. Ela ajusta a importância de cada nível de ruído ($\sigma$) na perda total, para que o modelo preste atenção a todos eles. Inicialmente, ela garante que todos os níveis de ruído contribuam igualmente para o aprendizado.
+
+- $u(\sigma)$ (u de sigma): É uma função de incerteza contínua. O modelo também aprende essa função. Se o modelo está "incerto" sobre como remover o ruído em um certo nível $\sigma$, ele se penaliza, incentivando-o a reduzir essa incerteza. Isso ajuda a otimização em diferentes níveis de ruído, tratando-os como um problema de aprendizado multi-tarefa
+
+#### Função de Ponderação:
+
+$$\lambda(\sigma) = \frac{(\sigma^2 + \sigma_{data}^2)}{\sigma \cdot \sigma_{data}}$$
+
+Onde:
+
+- $\sigma_{data}$: É o desvio padrão dos dados de treinamento. Essa equação define como o $\lambda(\sigma)$ calcula o peso de cada nível de ruído, inicialmente visando uma contribuição igualitária
+
+#### Distribuição do Nível de Ruído:
+
+$$ln(\sigma) ~ N (P_{mean}, P_{std}^2)$$
+
+Onde:
+
+- Isso descreve como os níveis de ruído ($\sigma$) são escolhidos durante o treinamento. O logaritmo natural ($ln$) de $\sigma$ segue uma distribuição normal ($N$), com uma média ($P_{mean}$) e um desvio padrão ($P_{std}$) definidos. Isso garante que o modelo veja uma boa variedade de níveis de ruído
+
+### Resultados e Aplicações
+
+Os modelos de difusão Cosmos-1.0 (7B e 14B) são capazes de gerar vídeos com alta qualidade visual, dinâmicas de movimento e alinhamento preciso com o texto. O modelo de 14B demonstra uma capacidade aprimorada de capturar detalhes visuais mais finos e padrões de movimento mais intrincados.
+
+Eles são utilizados em diversas aplicações de IA Física, como:
+
+- Controle de Câmera: Permitem gerar mundos virtuais navegáveis com base em uma imagem de referência e trajetórias de câmera, mantendo a coerência 3D e temporal.
+
+- Manipulação Robótica: Podem ser ajustados para prever vídeos de robôs seguindo instruções de texto ou sequências de ações.
+
+- Condução Autônoma: São adaptados para criar modelos de mundo multi-visão para cenários de condução, gerando vídeos de seis câmeras simultaneamente e até seguindo trajetórias de veículos.
+
+- Modelos de difusão baseados em Transformer são frequentemente capazes de incorporar diversos sinais de controle.
+
+- As avaliações mostram que os WFMs baseados em difusão entregam melhor qualidade de geração e maior consistência 3D em comparação com as linhas de base e os modelos autoregressivos em certas condições.
+
+### Limitações
+
+Apesar dos avanços, os modelos de difusão para simulação do mundo ainda enfrentam desafios comuns aos WFMs:
+
+- Falta de Permanência de Objetos: Objetos podem desaparecer ou aparecer inesperadamente.
+
+- Imprecisões em Dinâmicas com Contato: Interações físicas complexas, como colisões, ainda são difíceis de modelar com precisão.
+
+- Inconsistência no Seguimento de Instruções: O modelo nem sempre segue as instruções de texto de forma totalmente precisa.
+
+- Aderência às Leis da Física: A gravidade, interações de luz e dinâmicas de fluidos ainda não são perfeitamente simuladas.
+
+## English
+
+In the context of World Foundation Models (WFMs), it transforms noise into a video simulation of the world.
+
+Analogy: “Think of a diffusion model as an artist who starts with a canvas full of random noise (like old TV ‘static’) and, gradually, step by step, learns to remove that noise, revealing a coherent and meaningful image or video.”
+
+
+_"Figura S1.1-F2-ENG — Removal of noises"_
+
+### Video Tokenization: Transforming Videos into “Continuous Latents”
+
+Just like autoregressive models, diffusion models need to process videos in a more manageable format for their operation.
+
+- Continuous Tokens: For diffusion models, videos are transformed into continuous latent embeddings (vectors of decimal numbers). Think of them as a compact and fluid representation of the video, as opposed to the “discrete tokens” (integers) used by autoregressive models.
+- Cosmos Continuous Tokenizer (Cosmos-1.0-Tokenizer-CV8x8x8): This is the component responsible for this transformation. It compresses the input video into a lower-dimensional latent representation, preserving most of the visual information. This tokenizer has an encoder-decoder architecture that operates in the wavelet space for greater compression and preservation of semantic information, along with a causal temporal design (the encoding of current frames does not depend on future frames, which is crucial for Physical AI applications).
+
+### Formulation: The Denoising Process
+
+The core of the diffusion model is the iterative “denoising” process.
+
+#### Formulation Details
+
+| **Aspect** | **Description** |
+| :---------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Noise Addition and Removal | During training, **Gaussian (random) noise** is progressively added to a real video. The model is then trained to invert this process, learning to remove the noise at each step to reconstruct the original video from a noisy version. |
+| Denoising Function ($\mathcal{D}_\theta$) | The diffusion model uses a neural network $\mathcal{D}_\theta$ (called the “denoiser”) trained to estimate the noise present in a corrupted sample (noisy video) and, consequently, remove it to arrive at the clean version of the video. |
+| Loss Function | Training employs a **“denoising score matching”** loss function that penalizes the difference between the noise predicted by the model and the actual added noise. An u**ncertainty-based weighting technique ($\mu(\sigma)$)** is used to manage learning at different noise levels, treating it as a multi-task learning problem. |
+
+### Model Architecture: How Denoising Is Built
+
+The diffusion model’s $\mathcal{D}_\theta$ network is an adaptation of a Transformer architecture, optimized for visual data and control.
+
+#### Key Architectural Components
+
+| **Component** | **Description** |
+| :-----------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| 3D Patchification | The input latent representations are converted into **three-dimensional “patches” (cubic chunks)**, which are then “flattened” into a one-dimensional sequence. This prepares the data to be processed efficiently by the Transformer. |
+| Hybrid Positional Embeddings | Essential for spatial and temporal understanding: - 3**D-Factored Rotary Position Embedding (RoPE)**: Helps the model understand the relative positions of tokens along temporal, height, and width dimensions, enabling the generation of videos of arbitrary sizes and durations, compatible with different frame rates (FPS). - **Absolute (Learnable) Positional Embedding**: An additional embedding used in each Transformer block that, combined with RoPE, improves performance, reduces training loss, and minimizes “morphing” artifacts. |
+| Cross-Attention for Text Conditioning | Integrated layers that allow the model to generate videos based on text descriptions by incorporating **text embeddings** (generated by **T5-XXL**) into the denoising process. |
+| QK-Normalization (QKNorm) | Normalizes the query (Q) and key (K) vectors before the attention operation, which increases **training stability**, especially in the early phases, preventing attention saturation. |
+| AdaLN-LoRA | An architectural optimization that **significantly reduces parameter count** (e.g., 36% for the 7B-parameter model) without compromising performance, making the model more memory- and compute-efficient. |
+
+### Training Strategy: How the Model Learns to “Paint”
+
+Diffusion models are trained in multiple stages to optimize performance and generalization.
+
+| **Aspect** | **Description** |
+| :----------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Joint Image and Video Training | To leverage the vast amount of image data, an **alternating optimization** strategy interleaves batches of image and video data. A **domain-specific normalization** is used to align latent distributions and encourage a Gaussian isotropic representation. The denoising loss for videos is scaled to handle slower convergence. |
+| Progressive Training | The model is trained progressively, starting with **lower video resolutions and durations** (e.g., 512p with 57 frames) and advancing to **higher resolutions and durations** (e.g., 720p with 121 frames). A **“cooling-down” phase** with high-quality data and a decaying learning rate further refines the model. |
+| Multi-Aspect Training | Data are organized into buckets based on their **aspect ratios** (e.g., 1:1, 16:9) to accommodate content diversity. **Reflection padding** is used for missing pixels during batch processing. |
+| Mixed-Precision Training | For efficiency, model weights are kept in **BF16 and **FP32. BF16 is used for _forward_ and _backward_ passes, and FP32 for parameter updates, **ensuring numerical stability**. |
+| Text Conditioning | Uses **T5-XXL** as the text encoder. **Text2World** models are capable of generating video from a text input. |
+| Image and Video Conditioning (Video2World) | **Video2World** models extend Text2World models to accept previous frames (image or video) as a condition to generate future frames. Additional noise is introduced into the conditional frames during training to increase robustness. |
+
+### Inference Optimization: Making Generation Fast
+
+Although diffusion models are inherently slower due to their iterative denoising process, significant optimizations are applied to speed up generation.
+
+#### Inference Optimization Techniques
+
+| **Technique** | **Description** |
+| :-----------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| FSDP (Fully Sharded Data Parallelism) | Distributes model parameters, gradients, and optimizer states across multiple devices (GPUs), resulting in **significant memory savings** and enabling the use of larger models. |
+| Context Parallelism (CP) | Splits computation and activations along the sequence dimension, distributing them across GPUs. This technique is crucial for handling **long video contexts**, where the amount of data to be processed is very large. |
+
+### Prompt Upsampler: For User Text Inputs
+
+- To bridge the gap between short and varied user text prompts and the detailed video descriptions used in WFM training, a “Prompt Upsampler” is developed.
+- It transforms original prompts into more detailed and richer versions that align with the distribution of training prompts, improving the quality of the generated video. For Text2World models, Mistral-NeMo-12B-Instruct is used; for Video2World, Pixtral-12B is used.
+
+### Diffusion Decoder: Improving Autoregressive Visual Quality
+
+Although this is part of the diffusion model, it has a special post-optimization role for other models:
+
+- For autoregressive models (which can generate blurry videos due to aggressive tokenization), a more powerful diffusion decoder is used as a “post-optimization.”
+- This decoder takes the discrete tokens (output of the autoregressive model) and “translates” them back into higher-quality continuous tokens, which are then converted into high-quality RGB videos. It’s like refining a draft into a finished work of art.
+
+### Equations
+
+#### Denoising Loss:
+
+$\mathcal{L}(\mathcal{D}_\theta, \sigma) = \mathbb{E}_{x_0, n} ||\mathcal{D}_\theta(x_0 + n; \sigma) - x_0||_2^2$
+
+Where:
+
+- $x_0$ (read “x zero”): Represents the original, clean video (the “perfect canvas”)
+
+- $n$: Represents the random Gaussian noise that was added to video $x_0$
+
+- $\sigma$ (sigma): Indicates the noise level at that moment. Videos with more noise will have a larger $\sigma$.
+
+- $x_0 + n$: This is the noisy video (the “dirty canvas”) that is given as input to the model
+
+- $\mathcal{D}_\theta$: This is the neural network “denoiser.” The $\theta$ (theta) represents all the parameters (weights) the network needs to learn during training
+
+- $\mathcal{D}_\theta(x_0 + n;\sigma)$: This is what the model $\mathcal{D}_\theta$ predicts the original clean video ($x_0$) to be, given the noisy video ($x_0 + n$) and the noise level ($\sigma$)
+
+- $\mathcal{D}_\theta(x_0 + n;\sigma)− x_0$: This is the difference between what the model predicted and the real, clean video ($x_0$)
+
+- $||...||_2^2$: This means the squared L2 norm, which is a way to measure the “distance” or “error” between the model’s prediction and reality. Basically, we take the difference, square it (so negative and positive values count equally), and sum everything. We want this error to be as small as possible
+
+- $\mathbb{E}_{x_0, n}|| ... ||$: Means the expectation (or average) over different clean videos ($x_0$) and different types of noise ($n$)
+
+#### Total Training Loss:
+
+$\mathcal{L}(\mathcal{D}_\theta) = \mathbb{E}_\sigma [\lambda(\sigma) \cdot \mathcal{L}(\mathcal{D}_0, \sigma) + u(\sigma)]$
+
+Where:
+
+- $\mathbb{E}_\sigma[ ... ]$: Means the expectation (average) over different noise levels ($\sigma$). The model is trained to handle all noise levels, from almost clean to fully noisy.
+
+- $\lambda(\sigma)$ (lambda of sigma): A weighting function. It adjusts the importance of each noise level ($\sigma$) in the total loss so the model pays attention to all of them. Initially, it ensures that all noise levels contribute equally to learning.
+
+- $u(\sigma)$ (u of sigma): A continuous uncertainty function. The model also learns this function. If the model is “uncertain” about how to remove noise at a certain level $\sigma$, it penalizes itself, encouraging it to reduce this uncertainty. This helps optimization across different noise levels, treating them as a multi-task learning problem
+
+#### Weighting Function:
+
+$\lambda(\sigma) = \frac{(\sigma^2 + \sigma_{data}^2)}{\sigma \cdot \sigma_{data}}$
+
+Where:
+
+- $\sigma_{data}$: The standard deviation of the training data. This equation defines how $\lambda(\sigma)$ computes the weight of each noise level, initially aiming for an equal contribution
+
+#### Noise Level Distribution:
+
+$\ln(\sigma) \sim \mathcal{N}(P_{mean}, P_{std}^2)$
+
+Where:
+
+- This describes how the noise levels ($\sigma$) are chosen during training. The natural logarithm ($\ln$) of $\sigma$ follows a normal distribution ($\mathcal{N}$), with a mean ($P_{mean}$) and a standard deviation ($P_{std}$) defined. This ensures the model sees a good variety of noise levels
+
+### Results and Applications
+
+Cosmos-1.0 diffusion models (7B and 14B) are capable of generating videos with high visual quality, motion dynamics, and precise alignment with text. The 14B model demonstrates an enhanced ability to capture finer visual details and more intricate motion patterns.
+
+They are used in various Physical AI applications, such as:
+
+- Camera Control: They enable the generation of navigable virtual worlds based on a reference image and camera trajectories, maintaining 3D and temporal coherence.
+
+- Robotic Manipulation: They can be tuned to predict robot videos following text instructions or action sequences.
+
+- Autonomous Driving: They are adapted to create multi-view world models for driving scenarios, generating videos from six cameras simultaneously and even following vehicle trajectories.
+
+- Transformer-based diffusion models are often capable of incorporating multiple control signals.
+
+- Evaluations show that diffusion-based WFMs deliver better generation quality and greater 3D consistency compared to baselines and autoregressive models under certain conditions.
+
+### Limitations
+
+Despite the advances, diffusion models for world simulation still face challenges common to WFMs:
+
+- Lack of Object Permanence: Objects may disappear or appear unexpectedly.
+
+- Inaccuracies in Contact Dynamics: Complex physical interactions, such as collisions, are still difficult to model accurately.
+
+- Inconsistency in Following Instructions: The model does not always follow text instructions completely accurately.
+
+- Adherence to the Laws of Physics: Gravity, light interactions, and fluid dynamics are not yet perfectly simulated.
+
+## Referências | References
+
+- [Cosmos World Foundation Model Platform for Physical AI arXiv:2501.03575](https://arxiv.org/abs/2501.03575)
diff --git a/docs/diffusion/images/diffusion_denoising.png b/docs/diffusion/images/diffusion_denoising.png
new file mode 100644
index 0000000..60eb1d7
Binary files /dev/null and b/docs/diffusion/images/diffusion_denoising.png differ
diff --git a/docs/diffusion/images/noise.png b/docs/diffusion/images/noise.png
new file mode 100644
index 0000000..a4f1ee1
Binary files /dev/null and b/docs/diffusion/images/noise.png differ
diff --git a/docs/index.md b/docs/index.md
index 9206dbf..02abaa3 100644
--- a/docs/index.md
+++ b/docs/index.md
@@ -1,6 +1,21 @@
-## O que são World Foundation Models (WFMs)?
+# World Foundation Models (WFMs)
+
+## English
+
+### What are World Foundation Models (WFMs)?
+
+World Foundation Models (WFMs) are AI models that simulate or generate dynamic environments that replicate the real world in some aspect. These models are fundamental for systems that have a physical impact on the real world, such as robots or autonomous vehicles.
+
+For these AIs to operate in the physical world, they first need safe training environments, in order to learn how real-world conditions act in their specific domain before they can actually act in the real world. In this way, WFMs provide these training environments, acting as an important intermediary for training AI models that operate in the physical world.
+
+In building WFMs, a two-step approach is used—pre-training and post-training—that balances generalization capability with specialization. In the first phase, the model is exposed to a wide variety of video data, absorbing large-scale real-world patterns. This creates a foundation capable of understanding diverse contexts. Then, this general knowledge is refined with domain-specific data, such as robotics or autonomous driving. Thus, the model adapts to the nuances of the real operating environment without losing its versatility.
+
+## Português
+
+### O que são World Foundation Models (WFMs)?
World Foundation Models (WFMs) são modelos de IA que simulam ou geram ambientes dinâmicos que simulam o mundo real em algum aspecto. Esses modelos são fundamentais para sistemas que possuem um impacto físico no mundo real, como robôs ou veículos autônomos.
+
Para que essas IAs possam operar no mundo físico, elas primeiro precisam de ambientes de treinamento seguros, de forma a aprender como as condições do mundo real atuam na sua área de atuação específica antes de poderem agir de fato no mundo real. Dessa forma, WFMs proporcionam esses ambientes de treinamento, agindo como intermediário importante para o treinamento de modelos de IA com atuação no mundo físico.
Na construção de WFMs, usamos uma abordagem em duas etapas, de pré-treinamento e pós-treinamento, que equilibra a capacidade de generalização com a especialização. Na primeira fase, o modelo é exposto a uma grande variedade de dados de vídeo, absorvendo padrões do mundo real em larga escala.
diff --git a/docs/projeto/escopo.md b/docs/projeto/escopo.md
new file mode 100644
index 0000000..1123fdd
--- /dev/null
+++ b/docs/projeto/escopo.md
@@ -0,0 +1,208 @@
+# Escopo - Projeto World Foundation Model ()
+
+## Visão Geral do projeto
+
+Desenvolver, via simulações físicas 2D, um World Foundation Model capaz de aprender dinâmicas e cinemática de objetos a partir de observações visuais (vídeo/imagens) e prever/planejar evoluções futuras do sistema. O usuário descreve a cena e a tarefa por prompt; o sistema instancia a simulação, executa/prevê rollouts e retorna vídeo, métricas e ações planejadas.
+
+## Problema
+
+- Membros não possuem experiência prática com arquitetura de _world models_, de tal maneira que o projeto se faz necessário para permitir que os membros se capacitem e compreendam a profundidade tanto dos fundamentos quanto da implementação de modelos generativos aplicado à simulação física de comportamento de objetos diante de diferentes cenários dados por meio de prompts do usuário.
+ Falta um modelo unificado, orientado por dados, que:
+ **Generalize** para novas combinações de objetos/propriedades (massa, atrito, elasticidade) em 2D.
+ **Preveja** estados futuros com consistência física por dezenas de passos.
+ **Planeje ações** para atingir metas (p.ex., “fazer o bloco vermelho tocar o alvo”) sem ajustar hiperparâmetros por tarefa.
+
+## Objetivos
+
+- Criar um WorldModel que funcional que permita a interpretação de descrições textuais (prompts) e transformá-las em simulações físicas 2D consistentes e realistas para a devida simulação.
+- Elaborar um artigo para a consolidação do conhecimento adquirido ao longo do projeto, contribuindo assim para a disseminação acadêmica e análise científica do tema exposto.
+- Permitir a compreensão dos membros sobre novas arquiteturas emergentes em inteligência artificial, de tal maneira a ampliar a cpaacidade de inovação do grupo e permitir a criação de oportunidades dos conhecimentos adquiridos nas áreas de educação, pesquisa e desenvolvimento de tecnologias.
+
+## Limites do Projeto
+
+Treinar e avaliar um World Model capaz de compreender e reproduzir a cinemática e dinâmica de objetos em simulações 2D. O projeto não contempla simulações 3D ou aplicações diretas em ambientes físicos, mantendo assim o foco em ambientes digitais controlados.
+
+## Fora do Escopo
+
+- Aplicação em ambiente 3D.
+
+- Aprendizado por reforço end-to-end em hardware físico.
+
+- Contato deformável/fluídos complexos; multiagente competitivo.
+
+## Usuarios/Stakeholders
+
+- Membros da equipe de desenvolvimento e pesquisa diretamente envolvidos no projeto.
+
+- Comunidade acadêmica e técnica interessada em _World Models_, através do artigo de revisão que será publicado.
+
+## Requisitos Funcionais
+
+### Ambiente de simulação deve ser capaz de:
+
+- Gerar vídeos 2D, em formato (.MP4 ou .GIF ou .MKV), representando assim a dinâmica dos objetos a part ir do modelo treinado.
+
+-Receber prompts em **linguagem natural** especificando os elementos, suas propriedades (massa,cor,formato, peso, etc.), condições iniciais (posição, velocidade, energia potencial, etc.) e interações da simulação.
+
+- Permitir que múltiplos cenários com diferentes configurações de objetos sejam executados.
+
+- Registrar automaticamente os experimentos realizados, salvando também os resultados e metadados.
+
+### Modelo treinado deve ser capaz de:
+
+- Ser capaz de inferir a cinemática (posição,velocidade e aceleração) e a dinâmica (forças,colisões, interações) dos objetos simulados.
+
+-Generalizar para diferentes cenários, não apenas aqueles contidos durante o treinamento, e que sigam as mesmas leis físicas.
+
+- Disponibilizar métricas de desempenho (erro médio de previsão de trajetória)
+
+- Ser capaz de interpretar e simular interações entre 2 a N objetos simultâneos, onde N <= 3.
+
+## Métricas de Sucesso
+
+- Métrica de previsão de trajetória (chance de seguir a rota calculada);
+
+## Tópicos que ainda precisam ser abordados na documentação:
+
+- Descrição da arquitetura, técnicas utilizadas, justificativa das escolhas.
+
+- Inserção tutoriais de uso para reprodutibilidade (execução do ambiente, uso de modelo e exemplos de prompts).
+
+## Requisitos não funcionais
+
+Requisitos não funcionais fazem referência aos requisitos que não são intrísecos às funcionalidades do software em si, mas são mais focadas
+
+### Infraestrutura
+
+- O modelo deve ser treinável e executável na infraestrutura computacional que é fornecida no laboratório (CPU/GPU local).
+
+- Deve possuir uma versão reduzida/light que permita a execução em máquinas com recursos mais limitados para testes.
+
+### Qualidade
+
+- Ambiente de simulação deve apresentar consistência visual e física, sem apresentar falhas críticas que impossibilitem a análise.
+
+- Código deve seguir as boas práticas de engenharia de software (modularidade, versionamento, testes unitários básicos).
+
+### Usabilidade
+
+- Interface de usuário deve ser simples e interativa, sem exigir conhecimentos avançados em programação para um usuário comum utilizar dos cenários mais básicos.
+
+- Os prompts devem ser escritos em linguagem natural clara, sem necessidade de sintaxe complexa.
+
+### Reprodutibilidade
+
+- O repositório do gitHub deve conter as instruções completas de instalação, configuração e execução.
+
+- Os experimentos devem poder ser reproduzidos por terceiros com acesso ao dataset e código.
+
+## Entregáveis
+
+- FrontEnd que permita a interação do usuário com o sistema para captar o seu prompt.
+- Vídeo que representa o resultado final da simulação praticado pelo usuário.
+
+## Riscos & Suposições
+
+Poder computacional falho, dificuldades de manejar cargas de atividades da equipe.
+
+### English
+
+# Project Scope - World Foundation Model
+
+## Project Overview
+
+Develop, through 2D physical simulations, a World Foundation Model capable of learning the dynamics and kinematics of objects from visual observations (video/images) and predicting/planning the system’s future evolutions.
+The user describes the scene and the task through a prompt; the system instantiates the simulation, executes/predicts rollouts, and returns video outputs, metrics, and planned actions.
+
+## Problem
+
+- Team members currently lack practical experience with **world model architectures**, making this project necessary to enable them to gain expertise and understand both the theoretical foundations and the practical implementation of generative models applied to physical simulation of object behavior in different user-defined scenarios.
+- There is still no unified, data-driven model that can:
+ - **Generalize** to new combinations of objects/properties (mass, friction, elasticity) in 2D.
+ - **Predict** future states with physical consistency across dozens of steps.
+ - **Plan actions** to achieve specific goals (e.g., _“make the red block touch the target”_) without requiring task-specific hyperparameter tuning.
+
+## Objectives
+
+- Develop a functional **World Model** capable of interpreting textual descriptions (prompts) and transforming them into consistent and realistic 2D physical simulations.
+- Produce an **academic paper** to consolidate the knowledge acquired throughout the project, contributing to scientific dissemination and analysis of the subject.
+- Provide team members with a deeper understanding of emerging **artificial intelligence architectures**, expanding the group’s capacity for innovation and enabling the creation of educational, research, and technological development opportunities.
+
+## Project Boundaries
+
+- Train and evaluate a World Model capable of understanding and reproducing the kinematics and dynamics of objects in 2D simulations.
+- The project **does not cover** 3D simulations or direct applications in physical environments, maintaining its focus on controlled digital environments.
+
+## Out of Scope
+
+- Application in **3D environments**.
+- **End-to-end reinforcement learning** directly in hardware.
+- **Deformable contact/complex fluids**; **competitive multi-agent** settings.
+
+## Users / Stakeholders
+
+- Members of the development and research team directly involved in the project.
+- The academic and technical community interested in **World Models**, through the review article to be published.
+
+## Functional Requirements
+
+### The simulation environment must be able to:
+
+- Generate 2D videos in formats such as `.MP4`, `.GIF`, or `.MKV`, representing object dynamics based on the trained model.
+- Receive **natural language prompts** specifying elements, their properties (mass, color, shape, weight, etc.), initial conditions (position, velocity, potential energy, etc.), and interactions within the simulation.
+- Allow multiple scenarios with different object configurations to be executed.
+- Automatically log conducted experiments, saving results and metadata.
+
+### The trained model must be able to:
+
+- Infer **kinematics** (position, velocity, acceleration) and **dynamics** (forces, collisions, interactions) of simulated objects.
+- **Generalize** to different scenarios, not limited to those present in training, provided they follow the same physical laws.
+- Provide **performance metrics**, such as average trajectory prediction error.
+- Interpret and simulate interactions between **2 to N simultaneous objects**, where `N <= 3`.
+
+## Success Metrics
+
+- Trajectory prediction metric (probability of following the calculated path).
+
+## Documentation Topics Still to be Addressed
+
+- Description of the architecture, techniques used, and rationale for design choices.
+- Tutorials for reproducibility (environment setup, model usage, and example prompts).
+
+## Non-Functional Requirements
+
+Non-functional requirements refer to aspects not directly tied to the software’s functional behavior, but rather to quality attributes and constraints.
+
+### Infrastructure
+
+- The model must be trainable and executable on the computational infrastructure available in the lab (local CPU/GPU).
+- A **lightweight version** should be available for execution on resource-constrained machines for testing purposes.
+
+### Quality
+
+- The simulation environment must present visual and physical consistency, without critical failures that would prevent analysis.
+- The code must follow **software engineering best practices** (modularity, version control, basic unit testing).
+
+### Usability
+
+- The user interface must be simple and interactive, not requiring advanced programming knowledge for basic scenarios.
+- Prompts should be written in clear natural language, without complex syntax requirements.
+
+### Reproducibility
+
+- The GitHub repository must contain complete instructions for installation, configuration, and execution.
+- Experiments should be reproducible by third parties with access to the dataset and code.
+
+## Deliverables
+
+- **Frontend** that allows users to interact with the system and provide prompts.
+- **Video outputs** representing the final result of the simulation generated from the user’s input.
+
+## Risks & Assumptions
+
+- Limited computational resources.
+- Potential difficulties managing team workload.
+
+## Referências | References
+
+[Especificação do projeto](https://docs.google.com/document/d/1GqxDtGbsp0xNqUrYcW_h2VUKyDDuHM6sbOMI6WNnzyQ/edit?tab=t.0)
diff --git a/docs/tokens/cosmos_tokenizer/cosmos_tokenizer.md b/docs/tokens/cosmos_tokenizer/cosmos_tokenizer.md
index ae5be57..25de265 100644
--- a/docs/tokens/cosmos_tokenizer/cosmos_tokenizer.md
+++ b/docs/tokens/cosmos_tokenizer/cosmos_tokenizer.md
@@ -1,5 +1,7 @@
# Cosmos Tokenizer
+**_Authors / Autores: [@figredos](http://github.com/figredos)_**
+
## Português
A seguir apresentamos trechos do capítulo $5$ do artigo **_Cosmos World Foundation Model Platform for Physical AI_**, interpoladas com comentários clarificando e/ou contextualizando conteúdos de seus parágrafos.
@@ -55,6 +57,7 @@ Por outro, uma compressão excessiva pode levar à perda de detalhes visuais ess
A imagem a seguir ilustra os dois tipos de tokens:

+_"Figura S2.1-F1-ptbr — Visualização de Tokenizers contínuos e discretos"_
Tokens ao longo das dimensões espaciais ($\frac{H}{S_{HW}} \times \frac{W}{S_{HW}}$) e temporais ($1 + \frac{T}{S_T}$), com um fator de compressão espacial $S_{HW}$ e um fator de compressão temporal $S_T$. O primeiro token temporal representa o primeiro quadro da entrada, possibilitando a tokenização conjunta de imagens ($T=0$) e vídeos ($T>0$) em um espaço latente compartilhado.
@@ -70,6 +73,7 @@ Tokens ao longo das dimensões espaciais ($\frac{H}{S_{HW}} \times \frac{W}{S_{H
A tabela a seguir ilustra diferentes tokenizers visuais e suas capacidades:

+_"Figura S2.2-F2-ptbr — Diferentes Tokenizers e suas capacidades"_
O _Tokenizador Cosmos_ utiliza uma arquitetura leve e computacionalmente eficiente com um mecanismo temporal causal. Especificamente, ele emprega camadas de convolução temporal causal e camadas de atenção temporal causal para preservar a ordem temporal natural dos quadros de vídeo.
@@ -82,8 +86,7 @@ Os tokenizers são treinados diretamente em imagens de alta resolução e vídeo
Os gráficos abaixo mostram a comparação de desempenho entre o _Cosmos Tokenizer_ e outros tokenizers, evidenciando a sua qualidade superior mesmo em taxas de compressão mais altas:

-
-Claro! Segue abaixo o texto traduzido para o português, com a estrutura Markdown totalmente preservada, e mantendo em inglês apenas os termos técnicos que fazem mais sentido no original:
+_"Figura S2.2-F3-ptbr — Comparações entre Tokenizers"_
### Arquitetura
@@ -219,8 +222,10 @@ Essa abordagem garante flexibilidade no tratamento de diferentes resoluções es
### Resultados

+_"Figura S2.2-F4-ptbr — Avaliação 1 de Tokenizers"_

+_"Figura S2.2-F5-ptbr — Avaliação 2 de Tokenizers"_
Nós avaliamos nossa suíte Cosmos Tokenizer em vários datasets benchmark de imagens e vídeos. Para a avaliação dos image tokenizers, seguimos trabalhos anteriores para avaliar o **MS-COCO 2017** e o **ImageNet-1K**. Utilizamos o subconjunto de validação do **MS-COCO 2017** com $5.000$ imagens, e o subconjunto de validação do **ImageNet-1K** com $50.000$ imagens como benchmark para avaliação de imagens.
@@ -306,6 +311,7 @@ Tokenizers are fundamental building blocks of modern large-scale models. They tr
The image bellow illustrates the tokenization training pipeline, where the goal is to train the encoder and decoder, so that the bottleneck token representation maximally preserves visual information in the input.

+_"Figura S2.1-F6-ENG — Tokenization Pipelines"_
In the pipeline, an input video is encoded into tokens, which are usually much more compact than the input video. The decoder then reconstructs the input video from the tokens. _Tokenizer training is about learning the encoder and decoder to maximally preserve the visual information in the tokens_.
@@ -326,7 +332,7 @@ The success of tokenizers largely relies on their ability to deliver high compre
The following image illustrates the two types of tokens:

-
+_"Figura S2.2-F7-ENG — Visualization of discrete Tokenizers"_
Tokens along spatial ($\frac{H}{S_{HW}} \times \frac{W}{S_{HW}}$) and temporal ($1 + \frac{T}{S_T}$) dimensions, with a spatial compression factor of $S_{HW}$ and a temporal compression factor of $S_T$. The first temporal token represents the first input frame, enabling joint image ($T=0$) and video ($T>0$) tokenization in a shared latent space.
> $S_{HW}$ is the **_spatial compression factor_** used to compress the spatial dimensions of an image. This is a key step in the spatial tokenization process, where the input frame is divided into smaller patches or blocks with each one of these being represented by one or more tokens.
@@ -341,7 +347,7 @@ Tokens along spatial ($\frac{H}{S_{HW}} \times \frac{W}{S_{HW}}$) and temporal (
The following table illustrates different visual Tokenizers and their capabilities:

-
+_"Figura S2.2-F8-ptbr — Different Tokenizers and its capabilites"_
The _Cosmos Tokenizer_ uses a lightweight and computationally efficient architecture with a temporally causal mechanism. Specifically, it employs causal temporal convolution layers and causal temporal attention layers to preserve the natural temporal order of video frames.
> The term "causal" implies that any predictions on a particular frame or time step are based only on that frame and all previous frames, not on any future ones. Therefore "_Causal Temporal Convolution_" means that the feature generation for a given frame only uses data from frame $t$ and earlier.
@@ -353,6 +359,7 @@ The tokenizers are trained directly on high-resolution images and long-duration
The plots bellow show the comparison in performance between the Cosmos Tokenizer and other ones, and denotes the superior quality even at higher compression rates:

+_"Figura S2.2-F8-ptbr — Comparisons between Tokenizers"_
### Architecture
@@ -408,6 +415,7 @@ The decoder mirrors the encoder replacing the downsampling blocks with an upsamp
> 

+_"Figura S2.2-F8-ptbr — Tokenizers architectures"_
The image depicts the **Overall Cosmos Tokenizer architecture illustrating the integration of temporal causality and an encoder-decoder structure.** Temporal causality (left) processes sequential inputs, while the encoder-decoder (right) leverages wavelet transforms and causal operations to capture spatial and temporal dependencies in the data.
@@ -542,7 +550,7 @@ As shown in table $9$, for both image and video tokenizers, Cosmos Tokenizer is
## Referências | References
-- [Cosmos World Foundation Model Platform for Physical AI](https://arxiv.org/abs/2501.03575)
+- [Cosmos World Foundation Model Platform for Physical AI arXiv:2501.03575](https://arxiv.org/abs/2501.03575)
- [What is Wavelet Transform?Fourier vs Wavelet Transform|CWT-DWT|Wavelet Transform in Image Processing](https://www.youtube.com/watch?v=pUty-98Km_0)
diff --git a/docs/tokens/dsc_tokenization.md b/docs/tokens/dsc_tokenization.md
index 8042410..4dc2eb7 100644
--- a/docs/tokens/dsc_tokenization.md
+++ b/docs/tokens/dsc_tokenization.md
@@ -1,132 +1,96 @@
# Data Science Collective - Tokenization
-## Português
-
-### Visão Geral
-
-A IA generativa transformou profundamente nosso cotidiano nos últimos anos, possibilitando desde resumos e traduções automáticos até geração de código e até mesmo apoio ao aprendizado personalizado.
+**_Authors / Autores: [@yuri-sl](http://github.com/yuri-sl)_, [@figredos](http://github.com/figredos)**
-A “moeda” essencial por trás dessa tecnologia avançada é o token. A maioria dos modelos cobra com base no número de tokens de entrada que você fornece e nos tokens de saída que eles geram.
-
-Mas o que é um token, pelo qual pagamos tanto para ser processado? Compreender claramente o conceito de token é fundamental para construir aplicações mais eficientes.
-
-Entender os tokens permite um uso mais eficiente e oportuno da IA generativa, como os grandes modelos de linguagem.
+## Português
-E, honestamente, quem não gostaria de economizar tempo e dinheiro?
+### Visão geral
-Então, vamos ao que interessa: o que são tokens, como são gerados a partir do texto e quais são suas principais características?
+A IA generativa transformou profundamente nosso cotidiano nos últimos anos, possibilitando desde resumos e traduções automatizadas até geração de código e até suporte a aprendizado personalizado. A “moeda” essencial por trás dessa tecnologia avançada é o token. A maioria dos modelos cobra com base no número de tokens de entrada fornecidos e nos tokens de saída que geram.
-Compreender esses fundamentos é o primeiro passo para tirar o máximo proveito da IA generativa.
+Mas o que é um token, pelo processamento do qual pagamos tanto? Entender o que são tokens, como são gerados a partir de texto e quais são suas principais características são os primeiros passos para construir aplicações mais eficientes e aproveitar ao máximo a IA generativa.
### O que é Tokenização?
-Tokenização é a etapa de pré-processamento de texto em tarefas de PLN que divide o texto de entrada em subpalavras, palavras ou caracteres individuais.
-
-Um token é a menor unidade de medida processada por um modelo de IA generativa.
-
-Durante o treinamento de um modelo de IA generativa, esses tokens são fornecidos ao modelo.
-
-O tamanho de um token (uma unidade de entrada) varia entre modelos. Não existe uma estratégia de tokenização unificada. Os desenvolvedores escolhem a estratégia de tokenização a ser aplicada.
-
-Você pode ter uma noção de várias estratégias de tokenização ao experimentar este projeto de tokenização da Hugging Face, que visualiza essas estratégias para modelos populares.
-
- varia entre os modelos. Não há uma estratégia unificada de tokenização; elas são escolhidas pelos desenvolvedores de acordo com a tarefa em questão.
-Isso significa que cada modelo só pode ser usado para inferência em conjunto com o tokenizador com o qual foi treinado.
+É possível ter uma noção de várias estratégias de tokenização experimentando este projeto de tokenização do Hugging Face, que visualiza essas estratégias para modelos populares.
-Após o treinamento, tokens únicos são armazenados em um conjunto especial.
+
-Esse conjunto é chamado de vocabulário para grandes modelos de linguagem e de Cookbook para modelos de geração de imagem e áudio.
+_O Tokenizer Playground visualiza como um grande modelo de linguagem divide o texto em tokens individuais. Aqui, a frase “The quick brown fox jumps over the lazy dog.” é dividida em 10 tokens, demonstrando a primeira etapa no pipeline de processamento de texto de um LLM._
-### Métodos Simples de Tokenização
+> Isso significa que cada modelo só pode ser usado para inferência em combinação com o tokenizador no qual foi treinado.
-As abordagens mais simples de tokenização são a tokenização em nível de palavra e em nível de caractere.
+Após o treinamento, tokens únicos são armazenados em um conjunto especial chamado vocabulário para Grandes Modelos de Linguagem, e no Cookbook para modelos de geração de imagem e áudio.
-A tokenização em nível de palavra divide o texto de entrada por espaços em branco e caracteres especiais, como vírgulas, pontos de interrogação ou pontos de exclamação.
+### Métodos simples de tokenização
-Após dividir o texto em palavras, é criado um vocabulário com os tokens únicos.
+As abordagens mais simples de tokenização são a tokenização em nível de palavra e a tokenização em nível de caractere.
-Nesse vocabulário, cada token é mapeado para um valor inteiro.
+- **Tokenização em nível de palavra** : divide o texto de entrada por espaços em branco e caracteres especiais, como vírgulas, pontos de interrogação ou pontos de exclamação. Depois de dividir o texto em palavras, cria-se um vocabulário a partir dos tokens únicos, onde cada token é mapeado para um inteiro. O vocabulário pode ser usado para transformar cada sentença em uma representação vetorial numérica.
+ - 
-O vocabulário pode ser usado para transformar cada frase em uma representação vetorial numérica.
+No entanto, assim que se deseja codificar texto que não é do corpus de entrada e contém palavras não incluídas no vocabulário, nem todas as palavras podem ser tokenizadas. Essas palavras são chamadas de fora do vocabulário e são representadas por um token especial, como `<|unk|>`. Portanto, “Fora do vocabulário” é a forma educada da IA de dizer: “Não faço ideia do que você acabou de dizer, mas aqui vai uma resposta genérica.”
-
-Essas palavras são referidas como tokens fora do vocabulário e representadas por um token especial, como .
+Uma forma de lidar com esse problema é a tokenização em nível de caractere.
-Portanto, “Fora do vocabulário” é a forma educada da IA de dizer: “Não faço ideia do que você disse, mas aqui está uma resposta genérica.”
+- **Tokenização em nível de caractere**: processa o texto no nível de caracteres, resultando em um tamanho de vocabulário muito menor. Assim, em vez de um token por palavra, uma palavra é representada por uma combinação de muitos tokens.
-
-Assim, em vez de um token por palavra, uma palavra é representada por uma combinação de vários tokens.
+_Tokenização em nível de caractere: Cada caractere em “The quick brown fox” recebe um ID de token único, resultando em sequências de tokens mais longas, mas eliminando problemas de fora do vocabulário._
-Infelizmente, essa estratégia também tem suas falhas.
+Isso evidencia que ambas as estratégias de tokenização têm seus problemas. Por essa razão, modelos como o ChatGPT usam um método que encontra um equilíbrio entre ambas — Byte Pair Encoding (BPE), que será abordado no próximo post desta série.
-Como a tokenização é feita a nível de caractere, os tokens perdem o significado contextual, o que dificulta o aprendizado de gramática pelo modelo.
+### Tokenização no processo de geração de texto de LLMs
-Além disso, essa estratégia resulta em sequências mais longas.
+A relevância da tokenização fica clara quando se vê onde ela se situa no processo de geração de texto dos LLMs.
-A imagem pode ser ampliada
+Ao enviar uma consulta de entrada a um LLM, o texto é dividido em tokens e ingerido pelo modelo. Esses tokens são as unidades essenciais pelas quais se paga, e são subsequentemente transformados em números para que a máquina possa “entendê-los”.
-, que será abordado no próximo post desta série.
+
-Por enquanto, vamos aprofundar esse conhecimento construindo um tokenizador de palavras simples para entender melhor como ele funciona.
+### 4 maneiras de economizar tokens de entrada e saída
-### Tokenização no Processo de Geração de Texto de LLMs
+Economizar tokens é o equivalente, na IA, a apagar as luzes ao sair do cômodo.
-A relevância da tokenização fica clara quando vemos onde ela se situa no processo de geração de texto dos LLMs.
+
-Ao passar uma entrada para um LLM, seu texto é dividido em tokens e ingerido pelo modelo. Esses tokens são as unidades essenciais pelo qual você paga, transformadas em números para que a máquina possa “compreendê-los”.
+Então, para economizar energia, apague sua luz e não deixe seu fluxo de trabalho de IA rodar em um loop infinito processando tokens sem fim, por mais baratos que sejam. Aqui estão três dicas de como atingir esse objetivo.
-Após gerar uma resposta, o LLM retorna uma lista de tokens numéricos, que então são destokenizados para que possamos compreender — pois, infelizmente, não somos tão rápidos quanto as máquinas para processar números.
+1.Remove Unnecessary Context
+Remova instruções repetitivas, saudações, despedidas ou detalhes irrelevantes. Inclua apenas o que o modelo precisa saber para gerar uma resposta de alta qualidade
-Para esses tokens de entrada e saída, os fornecedores de LLM nos cobram. Portanto, faz sentido manter ambos os lados o mais curtos possível, o que reduz o tempo de processamento e economiza dinheiro.
+2.Optimize Prompt Engineering
+Use instruções concisas e claras. Evite explicações verbosas ou exemplos desnecessários. Prompts bem elaborados podem reduzir o tamanho da entrada e guiar o modelo com mais eficiência.
-. Ajuste essa configuração para garantir que a resposta do modelo não seja mais longa do que o necessário.
+4.Chunk Large Tasks
+Se houver um documento ou tarefa grande, divida-o em partes menores e processe-as sequencialmente. Isso reduz o uso de tokens por requisição e permite reutilizar contexto, economizando tokens de entrada e de saída.
-Nas últimas seções, aprendemos o que são tokens e que pagamos por tokens de entrada e saída ao usar modelos. Portanto, os prompts de entrada e saída devem ser o mais precisos possível.
+### Implementação de tokenização word-level
-Economizar tokens é o equivalente na IA a apagar as luzes ao sair do ambiente.
+Nos blocos de código Python a seguir, implementaremos a tokenização word-level , detalhando cada etapa para uma compreensão mais profunda. Os dois textos usados neste exemplo são contos de fadas gerados pelo ChatGPT usando o prompt: “Generate a fairy tale about AI”, e os resultados, no meu caso, foram “Arti the Useful Intelligence” e “Pixel the Dream.” Ambos os textos serão tokenizados por palavras nas linhas de código subsequentes.
-
-Aqui estão três dicas de como alcançar esse objetivo.
+_Contos de fadas de IA na tokenização: “Pixel the Dreamer” e “Artie the Helpful Intelligence” são dois textos de exemplo usados para demonstrar a tokenização word-level neste tutorial._
-**1. Remova Contexto Desnecessário**
-Elimine instruções repetitivas, cumprimentos, despedidas ou detalhes irrelevantes. Inclua apenas o que o modelo precisa saber para gerar uma resposta de qualidade.
+É possível encontrar todo o notebook Jupyter no repositório [GitHub de Python](https://github.com/FLX-20/AI-Explained) para esta série de posts.
-**2. Otimize o Prompt Engineering**
-Use instruções concisas e claras. Evite explicações detalhadas ou exemplos desnecessários. Prompts bem elaborados reduzem o tamanho da entrada e orientam o modelo de forma mais eficiente.
+#### Carregando os arquivos de texto
-**3. Defina Comprimentos Máximos de Saída**
-A maioria das APIs de LLM permite definir um limite máximo de tokens para a saída (por exemplo, _max_tokens_). Ajuste essa configuração para garantir que a resposta do modelo não seja mais longa do que o necessário.
-
-**4. Divida Grandes Tarefas em Partes**
-Se você tiver um documento ou tarefa grande, divida-o em partes menores e processe-as sequencialmente. Isso reduz o uso de tokens por requisição e permite reutilizar contexto, economizando tokens de entrada e saída.
-
-### Implementação de Tokenização a Nível de Palavra
-
-Nos blocos de código Python a seguir, vamos implementar a tokenização por palavras, detalhando cada etapa para um entendimento mais profundo.
-
-Os dois textos usados neste exemplo são contos de fadas gerados pelo ChatGPT com o prompt: “Crie um conto de fadas sobre IA.”
-
-Os resultados, no meu caso, foram “Arti a Inteligência Útil” e “Pixel o Sonhador”.
-
-Ambos os textos serão tokenizados por palavra nas linhas de código a seguir.
-
- desta série de posts.
-
-#### Carregando os Arquivos de Texto
-
-Primeiro, carregamos o texto do arquivo para o ambiente Python.
+Primeiro, carregamos o texto do arquivo de texto no nosso ambiente Python.
```python
import re
@@ -137,7 +101,7 @@ def open_txt_file(file_path):
return content
```
-O texto carregado pode ser verificado imprimindo os primeiros 100 caracteres de cada história.
+O texto carregado pode ser verificado imprimindo os primeiros 100 caracteres de ambas as histórias.
```python
text_1 = open_txt_file('pixel-the-dreamer.txt')
@@ -149,31 +113,21 @@ text_2 = open_txt_file('artie-the-helpful-intelligence.txt')
print(text_2[:100] + "...")
```
-#### Gerando Vocabulário e Vocabulário Reverso
-
-Agora, construímos nosso vocabulário, incluindo todas as palavras únicas do texto de entrada.
+#### Gerar vocabulário e vocabulário reverso
-O vocabulário define como cada palavra é mapeada para um valor inteiro.
+Agora, construímos nosso vocabulário incluindo todas as palavras únicas do texto de entrada. O vocabulário define como cada palavra é mapeada para um valor inteiro, e isso é feito primeiro dividindo o texto por espaços em branco e caracteres especiais usando expressões regulares. Dependendo da expressão regular escolhida, espaços em branco podem ser considerados um tipo de token ou podem ser completamente ignorados.
-Isso é feito primeiramente dividindo o texto usando espaços em branco e caracteres especiais com expressões regulares.
+A escolha de remover espaços em branco depende da aplicação. Embora a remoção desse tipo de caractere diminua a demanda por recursos computacionais, manter espaços em branco é benéfico para o processamento de linguagens de programação; em algumas linguagens de programação, esses espaços são essenciais devido à sensibilidade à indentação e ao espaçamento e não podem ser ignorados.
-Dependendo da expressão regular escolhida, espaços em branco podem ser considerados um tipo de token ou ignorados completamente.
+No exemplo acima, os espaços em branco são ignorados porque estamos lidando com texto bruto, que não é sensível à indentação.
-A escolha de remover espaços em branco depende da aplicação. Embora a remoção reduza o uso de recursos computacionais, mantê-los é benéfico para processar linguagens de programação.
-
-Em algumas linguagens, esses espaços são essenciais devido à sensibilidade à indentação e espaçamento e não podem ser ignorados.
-
-No exemplo acima, espaços em branco são ignorados porque lidamos com texto bruto, sem sensibilidade à indentação.
-
-Você pode incluir espaços em branco usando esta expressão regular:
+É possível incluir espaços em branco usando esta expressão regular:
```python
r'([\w+|\s+|^\w\s])'
```
-Após isso, espaços em branco restantes são removidos dos tokens, restando apenas a palavra ou caractere especial.
-
-Além disso, é gerado o vocabulário reverso, necessário para reconverter os tokens em texto.
+Em seguida, espaços em branco remanescentes são removidos dos tokens para que apenas a palavra ou o caractere especial permaneça. Além disso, é gerado um vocabulário reverso, necessário para converter os tokens de volta em texto.
```python
def generate_vocab(text):
@@ -189,94 +143,74 @@ def generate_vocab(text):
encode_vocab, decode_vocab = generate_vocab(text_1)
```
-Vamos ver como fica a criação do nosso vocabulário.
+Vamos dar uma olhada na criação do nosso vocabulário.
```python
-print("Vocabulário (token -> índice):")
+print("Vocabulary (token -> index):")
for idx, token in enumerate(encode_vocab):
print(f"{idx} -> '{token}'")
```
-No total, nosso vocabulário consiste em 204 palavras únicas.
+No total, nosso vocabulário consiste de 204 palavras únicas.
```python
-print("Número de tokens únicos:", len(encode_vocab))
+print("Number of unique tokens:", len(encode_vocab))
```
-#### Tokenizando um Texto
+#### Tokenizando um texto
-Agora estamos prontos para tokenizar textos de entrada baseado no vocabulário criado.
+Agora estamos prontos para tokenizar textos de entrada com base no vocabulário criado. O processo de tokenização começa de forma semelhante ao processo de criação do vocabulário, em que o texto é dividido em palavras e caracteres especiais, usando a mesma expressão regular de antes.
-O processo de tokenização começa semelhante ao de criação do vocabulário.
+Em seguida, o vocabulário é usado para substituir cada palavra no texto por seu número correspondente no vocabulário ou pelo token <|unk|> se a palavra não existir no vocabulário.
-O texto é dividido em palavras e caracteres especiais usando a mesma expressão regular anterior.
-
-Depois, o vocabulário é usado para substituir cada palavra do texto pelo número correspondente do vocabulário ou pelo token caso a palavra não exista no vocabulário.
-
-Ao final, a representação do texto tokenizado é retornada.
+Ao final, é retornada a representação final do texto tokenizado.
```python
def encode_text(text, encode_vocab):
tokens = re.split(r'(\w+|[^\w\s])', text)
tokens = [t for t in tokens if t.strip()]
- tokens = [encode_vocab.get(token, "") for token in tokens]
+ tokens = [encode_vocab.get(token, "<|unk|>") for token in tokens]
return tokens
```
-Vamos testar a função de tokenização no texto inicial, usado para criar o vocabulário.
+Vamos testar a função de tokenização anterior no texto inicial, que também foi usado para criar o vocabulário.
```python
encoded_text = encode_text(text_1, encode_vocab)
-print("Texto codificado:", encoded_text)
+print("Encoded text:", encoded_text)
```
-Agora, vamos testar também na função do segundo texto, não utilizado para gerar o vocabulário.
+Agora, vamos também testar a função no segundo texto, que não foi usado para a geração do vocabulário.
```python
encoded_text = encode_text(text_2, encode_vocab)
-print("Texto codificado:", encoded_text)
+print("Encoded text:", encoded_text)
```
-Como previsto, nem todas as palavras do segundo texto estão presentes no vocabulário criado com o primeiro texto.
+É possível ver que aconteceu exatamente como previsto anteriormente. Nem todas as palavras do segundo texto estão presentes no primeiro texto, que foi usado para gerar o vocabulário, resultando em muitos tokens desconhecidos fora do vocabulário.
-Isso resulta em muitos tokens desconhecidos (out-of-vocabulary).
+Neste momento, há duas possibilidades para resolver esse problema: Pode-se usar tokenização em nível de caractere ou adicionar as palavras fora do vocabulário ao nosso vocabulário. No próximo bloco de código, seguiremos adicionando as palavras desconhecidas ao vocabulário.
-Temos agora duas alternativas para resolver esse problema: usar tokenização a nível de caractere ou adicionar as palavras desconhecidas ao nosso vocabulário.
-
-Sua vez: use o conhecimento adquirido neste post para implementar a tokenização em nível de caractere e resolver o erro.
-
-No próximo código, vamos adicionar as palavras desconhecidas ao vocabulário.
-
-Fazemos isso somando os dois textos, separados pelo token , que indica ao modelo que o próximo texto é independente do anterior.
-
-Depois, as mesmas funções são reutilizadas para gerar a representação tokenizada do texto de entrada.
+Isso é feito adicionando ambos os textos, separados pelo token `<|endoftext|>`, que indica ao modelo que o próximo texto não está relacionado ao anterior. Em seguida, as mesmas funções são reutilizadas para gerar a representação em tokens do texto de entrada.
```python
-text_corpus = text_1 + " " + text_2
+text_corpus = text_1 + " <|endoftext|> " + text_2
encode_vocab, decode_vocab = generate_vocab(text_corpus)
encoded_text = encode_text(text_2, encode_vocab)
-print("Texto codificado:", encoded_text)
+print("Encoded text:", encoded_text)
```
-#### Detokenização
+#### Destokenização
-Ao final, queremos retornar ao texto original a partir da representação em tokens, para que possamos compreender e interpretar.
+Ao final, queremos voltar ao texto original a partir da representação em tokens, para que possamos entendê-lo e interpretá-lo, o que é exatamente a etapa que ocorre após um Grande Modelo de Linguagem gerar sua saída. As representações numéricas produzidas pelo LLM são convertidas de volta pelo destokenizador em informação textual.
-Esse é exatamente o passo realizado após o LLM gerar sua saída. As representações numéricas produzidas pelo modelo são então convertidas de volta pelo detokenizador em texto.
-
-Aqui, precisamos do vocabulário reverso, que mapeia os tokens de volta para as palavras.
-
-O processo de detokenização é semelhante ao da tokenização.
-
-Basta pegar os números na lista de tokens e substituí-los pelas palavras do vocabulário, separados por espaço.
-
-Esses espaços são removidos antes de caracteres especiais porque, nesses casos, tais caracteres estão sempre ligados a uma palavra.
+Aqui, é necessário o vocabulário reverso, que mapeia tokens de volta para palavras. O processo de destokenização é semelhante ao de tokenização: pegam-se os números da lista de tokens e eles são substituídos pelas palavras correspondentes do vocabulário, separadas por espaço em branco. Esses espaços são removidos antes de caracteres especiais porque eles estão sempre anexados a uma palavra.
A lista final é retornada e impressa.
```python
def decode_text(tokens, decode_vocab):
- text = ' '.join(decode_vocab.get(idx,'') for idx in tokens)
+ text = ' '.join(decode_vocab.get(idx,'<|unk|>') for idx in tokens)
text = re.sub(r'\s([?.!,"](?:\s|$))', r'\1', text)
return text
```
@@ -288,101 +222,56 @@ print(decode_text)
#### Conclusão
-Nesta exploração da tokenização, descobrimos os blocos fundamentais que movem os sistemas modernos de IA generativa.
+Nesta exploração da tokenização, revelamos os blocos de construção fundamentais que alimentam os sistemas modernos de IA generativa. O post destacou que existem diferentes estratégias de tokenização, que variam entre os modelos.
-O post destacou que existem diferentes estratégias de tokenização, que variam entre modelos.
+As duas estratégias mais simples — tokenização word-level e tokenização em nível de caractere — foram introduzidas e implementadas, com seus prós e contras discutidos. O problema de fora do vocabulário encontrado na tokenização por palavras, assim como o grande comprimento da lista de tokens na codificação em nível de caractere, evidenciaram que é necessária uma solução intermediária.
-As duas mais simples — por palavra e por caractere — foram apresentadas e implementadas, discutindo suas vantagens e desvantagens.
-
-O problema de fora do vocabulário na tokenização por palavra e a extensão das listas de tokens na codificação por caractere mostraram que uma solução intermediária é necessária.
-
-Essa solução é o Byte Pair Encoding (BPE), utilizada em quase todos os modelos modernos.
+Essa solução é o Byte Pair Encoding (BPE), usado por quase todos os modelos modernos.
## English
### Overview
-Generative AI has profoundly transformed our daily lives in recent years, enabling everything from automated summaries and translations to code generation and even personalized learning support.
-
-The essential “currency” behind this advanced technology is the token. Most models charge based on the number of input tokens you provide and the output tokens they generate.
-
-But what is a token, for the processing of which we pay so much? Gaining a clear understanding of tokens is crucial for building more efficient applications.
-
-Understanding tokens allows for more efficient and timely use of generative AI, such as large language models.
-
-And honestly, who wouldn’t want to save time and money?
+Generative AI has profoundly transformed our daily lives in recent years, enabling everything from automated summaries and translations to code generation and even personalized learning support. The essential “currency” behind this advanced technology is the token. Most models charge based on the number of input tokens you provide and the output tokens they generate.
-So, let’s dive in: What are tokens, how are they generated from text, and what are their key characteristics?
-
-Understanding these basics is the first step toward making the most of generative AI.
+But what is a token, for the processing of which we pay so much? Understanding what are tokens, how are they generated from text, and what are their key characteristics, are the first steps toward building more efficient applications, and -making the most of generative AI.
### What is Tokenization?
-Tokenization is the text preprocessing step in NLP tasks that splits the input text into individual sub-words, words, or characters.
-
-A token is the smallest unit of measurement processed by a generative AI model.
-
-During the training process of a generative AI model, these tokens are provided to the model.
-
-The size of a token (one input unit) varies between models. There is no unified tokenization strategy. The developers choose the tokenization strategy that will be applied.
+Tokenization is the text preprocessing step in NLP tasks that splits the input text into individual sub-words, words, or characters. A token is the smallest unit of measurement processed by a generative AI model. During its training, these tokens are provided to the model for processing. The size of a token (one input unit) varies between models. There is no unified tokenization strategy, they are chosen by developers according to the task at hand.
You can get an impression of various tokenization strategies by experimenting with this Hugging Face tokenization project, which visualizes these strategies for popular models.
-
-
-> The _Tokenizer Playground_ visualizes how a large language model splits text into individual tokens. Here, the sentence “The quick brown fox jumps over the lazy dog.” is divided into 10 tokens, demonstrating the first step in the LLM text processing pipeline.
+
-This means that each model can only be used for inference in combination with the tokenizer it was trained on.
+_The **Tokenizer Playground** visualizes how a large language model splits text into individual tokens. Here, the sentence “The quick brown fox jumps over the lazy dog.” is divided into 10 tokens, demonstrating the first step in the LLM text processing pipeline._
-After training, unique tokens are stored in a special set.
+> This means that each model can only be used for inference in combination with the tokenizer it was trained on.
-This set is called the vocabulary for Large Language Models, and the Cookbook for image and audio generation models.
+After training, unique tokens are stored in a special set called the vocabulary for Large Language Models, and the Cookbook for image and audio generation models.
### Simple tokenization methods
The simplest tokenization approaches are word-level tokenization and character-level tokenization.
-Word-level tokenization splits the input text by whitespaces and special characters, such as commas, question marks, or exclamation points.
+- **Word-level tokenization**: splits the input text by whitespaces and special characters, such as commas, question marks, or exclamation points. After splitting the text into words, a vocabulary is created from the unique tokens, where each token is mapped to an integer. The vocabulary can be used to transform each sentence into a numerical vector representation.
+ - 
-After splitting the text into words, a vocabulary is created from the unique tokens.
+However, as soon as we want to encode text that is not from the input corpus and contains words not included in the vocabulary, not all words can be tokenized. These words are referred to as out-of-vocabulary tokens and are represented by a special token, such as `<|unk|>`. So “Out-of-vocabulary” is AI’s polite way of saying, “No idea what you just said, but here’s a generic response.”
-In this vocabulary, each token is mapped to an integer.
-
-The vocabulary can be used to transform each sentence into a numerical vector representation.
-
-
-
-However, as soon as we want to encode text that is not from the input corpus and contains words not included in the vocabulary, not all words can be tokenized.
-
-These words are referred to as out-of-vocabulary tokens and are represented by a special token, such as <|unk|>.
-
-So “Out-of-vocabulary” is AI’s polite way of saying, “No idea what you just said, but here’s a generic response.”
-
-
+
One way to address this problem is character-level tokenization.
-This tokenization strategy processes text at the character level, resulting in a much smaller vocabulary size.
-
-Thus, instead of one token per word, a word is represented by a combination of many tokens.
-
-Unfortunately, this strategy also has its flaws.
-
-Because tokenization is performed at the character level, the tokens lose contextual meaning, which makes it more difficult for the model to learn grammar.
-
-Moreover, this tokenization strategy results in longer sequences.
-
-Zoom image will be displayed
+- **Character-level tokenization**: processes text at the character level, resulting in a much smaller vocabulary size. Thus, instead of one token per word, a word is represented by a combination of many tokens.
-
+Unfortunately, this strategy also has its flaws. Because tokenization is performed at the character level, the tokens lose contextual meaning, which makes it more difficult for the model to learn grammar. Moreover, this tokenization strategy results in longer sequences.
-> Character-level tokenization: Every character in “The quick brown fox” is assigned a unique token ID, resulting in longer token sequences but eliminating out-of-vocabulary issues.
+
-This highlights that both tokenization strategies have their problems.
+_Character-level tokenization: Every character in “The quick brown fox” is assigned a unique token ID, resulting in longer token sequences but eliminating out-of-vocabulary issues._
-For this reason, models such as ChatGPT use a method that strikes a balance between both — Byte Pair Encoding (BPE), which will be covered in the next post of this series.
-
-For now, let’s deepen this knowledge by building a simple word tokenizer ourselves to better understand how it works.
+This highlights that both tokenization strategies have their problems. For this reason, models such as ChatGPT use a method that strikes a balance between both — Byte Pair Encoding (BPE), which will be covered in the next post of this series.
### Tokenization in the LLM text generation process
@@ -394,19 +283,15 @@ After an answer has been generated by the LLM, it returns a list of numerical to
For these input and output tokens, the LLM providers make us pay. So it makes sense to keep both ends as short as possible, which decreases processing time and saves money.
-
+
### 4 Ways to Save Input and Output Tokens
-In the last sections, we learned what tokens are and that we pay for input and output tokens when using models. Hence, the input and output prompts should be as precise as possible.
-
Saving tokens is the AI equivalent of turning off the lights when you leave the room.
-
-
-So, to save energy, switch off your light and don’t let your AI workflow run in an infinite loop processing endless tokens, no matter how cheap they are.
+
-Here are three tips on how this goal can be achieved.
+So, to save energy, switch off your light and don’t let your AI workflow run in an infinite loop processing endless tokens, no matter how cheap they are. Here are three tips on how this goal can be achieved.
**1.Remove Unnecessary Context**
Strip out repetitive instructions, greetings, sign-offs, or irrelevant details. Only include what the model needs to know to generate a high-quality response
@@ -421,17 +306,11 @@ If you have a large document or task, break it into smaller parts and process th
### Implementation of word level tokenizing
-In the following Python code blocks, we will implement word-level tokenization, breaking down every step for a deeper understanding.
-
-The two texts used for this example are fairy tales generated by ChatGPT using the prompt: “Generate a fairy tale about AI.”
-
-The results in my case were “Arti the Useful Intelligence” and “Pixel the Dream.”
-
-Both texts will be tokenized by words in the subsequent lines of code.
+In the following Python code blocks, we will implement word-level tokenization, breaking down every step for a deeper understanding. The two texts used for this example are fairy tales generated by ChatGPT using the prompt: “Generate a fairy tale about AI”, and the results in my case were “Arti the Useful Intelligence” and “Pixel the Dream.” Both texts will be tokenized by words in the subsequent lines of code.
-
+
-> AI fairy tales in tokenization: “Pixel the Dreamer” and “Artie the Helpful Intelligence” are two example texts used for demonstrating word-level tokenization in this tutorial.
+_AI fairy tales in tokenization: “Pixel the Dreamer” and “Artie the Helpful Intelligence” are two example texts used for demonstrating word-level tokenization in this tutorial._
You can find the entire Jupyter notebook in the Python [GitHub repo](https://github.com/FLX-20/AI-Explained) for this post series.
@@ -462,17 +341,9 @@ print(text_2[:100] + "...")
#### Generate vocabulary and reverse vocabulary
-Now, we build our vocabulary including all unique words of the input text.
+Now, we build our vocabulary including all unique words of the input text. The vocabulary defines how each word is mapped to an integer value, and is achieved by first splitting the text by white spaces and special characters using regular expressions. Depending on the chosen regular expression, white spaces can be considered as a token type or can be completely ignored.
-The vocabulary defines how each word is mapped to an integer value.
-
-This is achieved by first splitting the text by white spaces and special characters using regular expressions.
-
-Depending on the chosen regular expression, white spaces can be considered as a token type or can be completely ignored.
-
-The choice of removing white spaces depends on the application. While the removal of this character type decreases compute resource demands, keeping white spaces is beneficial for processing programming languages.
-
-In some programming languages, these white spaces are essential due to indentation and spacing sensitivity and cannot be ignored.
+The choice of removing white spaces depends on the application. While the removal of this character type decreases compute resource demands, keeping white spaces is beneficial for processing programming languages, in some programming languages, these white spaces are essential due to indentation and spacing sensitivity and cannot be ignored.
In the example above, the white spaces are ignored because we are dealing with raw text, which is not indentation sensitive.
@@ -482,9 +353,7 @@ You can include white spaces by using this regular expression:
r'([\w+|\s+|^\w\s])'
```
-Afterwards, remaining white spaces are stripped away from the tokens so that only the word or special character is left.
-
-Moreover, a reverse vocabulary is generated, which is necessary for converting the tokens back into text.
+Afterwards, remaining white spaces are stripped away from the tokens so that only the word or special character is left. Moreover, a reverse vocabulary is generated, which is necessary for converting the tokens back into text.
```python
def generate_vocab(text):
@@ -516,11 +385,7 @@ print("Number of unique tokens:", len(encode_vocab))
#### Tokenizing a text
-Now we are ready to tokenize input texts based on the created vocabulary.
-
-The tokenization process starts similarly to the vocabulary creation process.
-
-The text is split into words and special characters, using the same regular expression as before.
+Now we are ready to tokenize input texts based on the created vocabulary. The tokenization process starts similarly to the vocabulary creation process, where the text is split into words and special characters, using the same regular expression as before.
Afterwards, the vocabulary is used to replace each word in the text either with its corresponding number from the vocabulary or the <|unk|> token if the word does not exist in the vocabulary.
@@ -548,17 +413,11 @@ encoded_text = encode_text(text_2, encode_vocab)
print("Encoded text:", encoded_text)
```
-You can see it happened exactly as we previously predicted. Not all words from the second text are present in the first text, which was used to generate the vocabulary.
-
-This results in many unknown out-of-vocabulary tokens.
+You can see it happened exactly as we previously predicted. Not all words from the second text are present in the first text, which was used to generate the vocabulary, resulting in many unknown out-of-vocabulary tokens.
-Right now, we have two possibilities to solve this problem: We can either use character-level tokenization, or we can add the out-of-vocabulary words to our vocabulary.
+Right now, we have two possibilities to solve this problem: We can either use character-level tokenization, or we can add the out-of-vocabulary words to our vocabulary. In the next code block, we will follow up by adding the unknown words to the vocabulary.
-In the next code block, we will follow up by adding the unknown words to the vocabulary.
-
-This is achieved by adding both texts together, separated by the <|endoftext|> token, which indicates to the model that the next text is unrelated to the previous one.
-
-Afterwards, the same functions are reused for generating the token representation of the input text.
+This is achieved by adding both texts together, separated by the `<|endoftext|>` token, which indicates to the model that the next text is unrelated to the previous one. Afterwards, the same functions are reused for generating the token representation of the input text.
```python
text_corpus = text_1 + " <|endoftext|> " + text_2
@@ -569,17 +428,9 @@ print("Encoded text:", encoded_text)
#### Detokenization
-In the end, we would like to go back to the original text from the token representation, so that we humans can understand and interpret it.
-
-This is exactly the step that happens after a Large Language Model generates its output. The numerical representations produced by the LLM are converted back by the detokenizer into textual information.
+In the end, we would like to go back to the original text from the token representation, so that we humans can understand and interpret it, which is exactly the step that happens after a Large Language Model generates its output. The numerical representations produced by the LLM are converted back by the detokenizer into textual information.
-Here, we need the reverse vocabulary, which maps tokens back to words.
-
-The detokenization process is similar to the tokenization process.
-
-You take the numbers from the token list and replace them with the corresponding words from the vocabulary, separated by white space.
-
-These white spaces are removed in front of special characters because they are always attached to a word.
+Here, we need the reverse vocabulary, which maps tokens back to words. The detokenization process is similar to the tokenization process, you take the numbers from the token list and replace them with the corresponding words from the vocabulary, separated by white space. These white spaces are removed in front of special characters because they are always attached to a word.
The final list is returned and printed out.
@@ -597,13 +448,9 @@ print(decode_text)
#### Conclusion
-In this exploration of tokenization, we uncovered the fundamental building blocks that power modern generative AI systems.
-
-The post highlighted that there are different tokenization strategies, which vary between models.
-
-The two simplest tokenization strategies — word-level and character-level tokenization — were introduced and implemented, with their pros and cons discussed.
+In this exploration of tokenization, we uncovered the fundamental building blocks that power modern generative AI systems. The post highlighted that there are different tokenization strategies, which vary between models.
-The encountered out-of-vocabulary problem of word tokenization, as well as the large token list length of character-level encoding, highlighted that an intermediate solution is needed.
+The two simplest tokenization strategies — word-level and character-level tokenization — were introduced and implemented, with their pros and cons discussed. The encountered out-of-vocabulary problem of word tokenization, as well as the large token list length of character-level encoding, highlighted that an intermediate solution is needed.
This solution is Byte Pair Encoding (BPE), which is used by almost all modern models.
diff --git a/docs/tokens/images/dscImages/AIFairyTales.webp b/docs/tokens/images/dsc_images/ai_fairy_tales.webp
similarity index 100%
rename from docs/tokens/images/dscImages/AIFairyTales.webp
rename to docs/tokens/images/dsc_images/ai_fairy_tales.webp
diff --git a/docs/tokens/images/dscImages/characterLevelTokenization.webp b/docs/tokens/images/dsc_images/character_level_tokenization.webp
similarity index 100%
rename from docs/tokens/images/dscImages/characterLevelTokenization.webp
rename to docs/tokens/images/dsc_images/character_level_tokenization.webp
diff --git a/docs/tokens/images/dscImages/handlingUnknownWordsTokenization.webp b/docs/tokens/images/dsc_images/handling_unk_words.webp
similarity index 100%
rename from docs/tokens/images/dscImages/handlingUnknownWordsTokenization.webp
rename to docs/tokens/images/dsc_images/handling_unk_words.webp
diff --git a/docs/tokens/images/dscImages/textGenerationPipeline.webp b/docs/tokens/images/dsc_images/text_gen_pipeline.webp
similarity index 100%
rename from docs/tokens/images/dscImages/textGenerationPipeline.webp
rename to docs/tokens/images/dsc_images/text_gen_pipeline.webp
diff --git a/docs/tokens/images/dscImages/tokenizerPlayground.webp b/docs/tokens/images/dsc_images/tokenizer_playground.webp
similarity index 100%
rename from docs/tokens/images/dscImages/tokenizerPlayground.webp
rename to docs/tokens/images/dsc_images/tokenizer_playground.webp
diff --git a/docs/tokens/images/dscImages/TokensPowerAI.webp b/docs/tokens/images/dsc_images/tokens_power_ai.webp
similarity index 100%
rename from docs/tokens/images/dscImages/TokensPowerAI.webp
rename to docs/tokens/images/dsc_images/tokens_power_ai.webp
diff --git a/docs/tokens/images/dscImages/wordLevelTokenization.webp b/docs/tokens/images/dsc_images/word_level_tokenization.webp
similarity index 100%
rename from docs/tokens/images/dscImages/wordLevelTokenization.webp
rename to docs/tokens/images/dsc_images/word_level_tokenization.webp
diff --git a/mkdocs.yml b/mkdocs.yml
index c4d0ac1..cc46aa4 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -1,17 +1,21 @@
theme:
- name: material
+ name: readthedocs
+ color_mode: auto
+ user_color_mode_toggle: true
site_name: World Foundation Models
nav:
- Home: index.md
- - Diffusion models: diffusion.md
- - Autoregressive models: autoregressive/autoregressive.md
- - Tokens:
- - Cosmos Tokenizer:
- - tokens/cosmos_tokenizer/cosmos_tokenizer.md
- - tokens/cosmos_tokenizer/wavelet_compression.ipynb
- - DSC Tokenization: tokens/dsc_tokenization.md
- - Cosmos Applications: cosmos_applications/cosmos_applications.md
+ - Projeto: projeto/escopo.md
+ - Referências:
+ - Diffusion models: diffusion/diffusion.md
+ - Autoregressive models: autoregressive/autoregressive.md
+ - Tokens:
+ - Cosmos Tokenizer:
+ - tokens/cosmos_tokenizer/cosmos_tokenizer.md
+ - tokens/cosmos_tokenizer/wavelet_compression.ipynb
+ - DSC Tokenization: tokens/dsc_tokenization.md
+ - Cosmos Applications: cosmos_applications/cosmos_applications.md
markdown_extensions:
- pymdownx.arithmatex:
generic: true
@@ -22,7 +26,7 @@ extra_javascript:
- https://cdn.jsdelivr.net/npm/mathjax@3/es5/tex-mml-chtml.js
plugins:
- - mkdocs-jupyter:
+ - mkdocs-jupyter:
execute: true
include_source: true
include: ["*.ipynb"]
diff --git a/site/404.html b/site/404.html
index 0d5151c..5edc8cb 100644
--- a/site/404.html
+++ b/site/404.html
@@ -1,467 +1,130 @@
+
+
+
+
+
+
+
+ World Foundation Models
+
+
+
+
+
+
+
+
+
+
+
+