21CVPR#UP-DETR: Unsupervised Pre-training for Object Detection with Transformers #38
Labels
area/image
area/SSL
self-supervised learning
Code
Code available.
Summary/Brief
A breif summary about the paper.
task/detection
trend/Transformer
Every paper uses transformer...
Comments
|
Highlight:
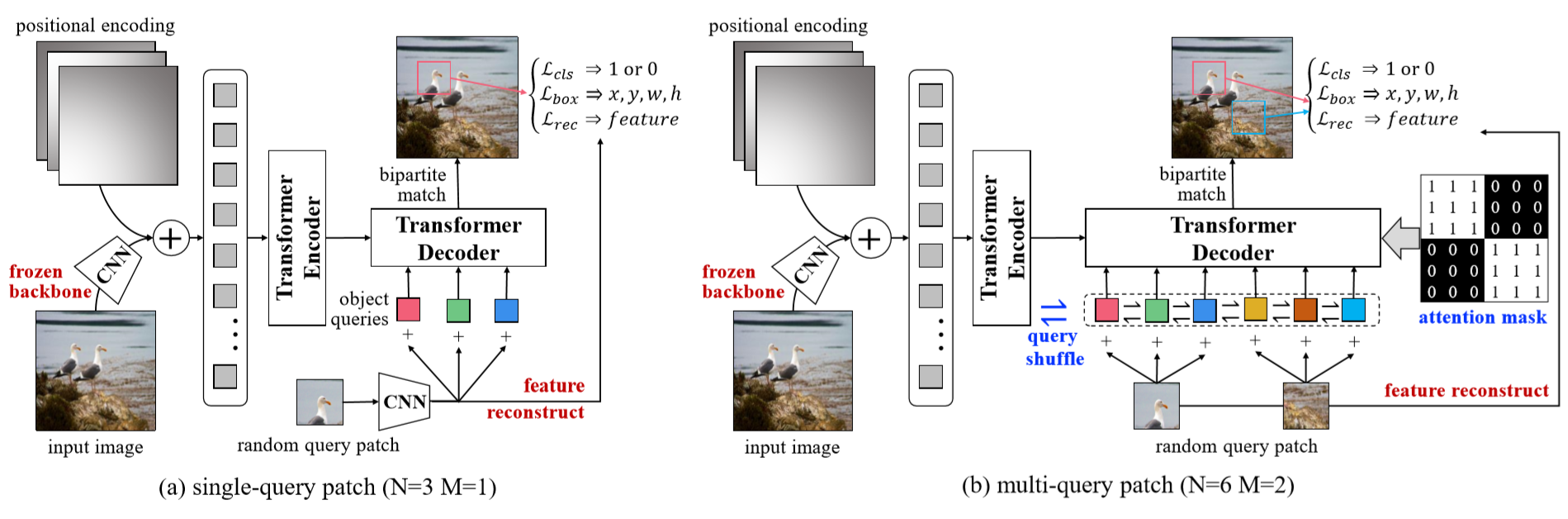
The entire framework:
The loss function is formed by three parts:
|
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Paper
Code-pytorch
Authors:
Zhigang Dai, Bolun Cai, Yugeng Lin, Junying Chen
The Chinese explanation from the author Zhigang Dai in Zhihu.
The framework of the proposed UP-DETR.
The text was updated successfully, but these errors were encountered: