Kubernetes provides detailed information about applications and cluster resources usage. This information allows to evaluate the application’s performance and where bottlenecks can be removed to improve overall performance of the cluster.
In Kubernetes, applications monitoring does not depend on a single monitoring solution. In this section, we're going to explore some of the monitoring tools currently available.
When creating a pod, we can specify the amount of CPU and memory that a container requests and a limit on what it may consume.
The following pod manifest requests-pod.yaml specifies the CPU and memory requests for its single container.
apiVersion: v1
kind: Pod
metadata:
name: request-pod
namespace:
labels:
spec:
containers:
- image: busybox:latest
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: busybox
resources:
requests:
cpu: 200mBy specifying resource requests, we specify the minimum amount of resources the pod needs. However the pod above can take more than the requested CPU and memory we requested, according to the capacity and the actual load of the working node. Each node has a certain amount of CPU and memory it can allocate to pods. When scheduling a pod, the scheduler will only consider nodes with enough unallocated resources to meet the pod requirements. If the amount of unallocated CPU or memory is less than what the pod requests, the scheduler will not consider the node, because the node can’t provide the minimum amount required by the pod.
Please, note that we're not specifying the maximum amount of resources the pod can consume. If we want to limit the usage of resources, we have to limit the pod as in the following limited-pod.yaml descriptor file
apiVersion: v1
kind: Pod
metadata:
name: limited-pod
namespace:
labels:
spec:
containers:
- image: busybox:latest
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: busybox
resources:
requests:
cpu: 200m
limits:
cpu: 200mCreate the pod
kubectl apply -f limited-pod.yaml
Checking the resource usage
kubectl exec limited-pod top
Mem: 3458876K used, 2408668K free, 309892K shrd, 2072K buff, 2264840K cached
CPU: 7.6% usr 8.5% sys 0.0% nic 83.5% idle 0.0% io 0.0% irq 0.2% sirq
Load average: 1.97 1.14 0.74 6/621 12
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1236 0.0 0 10.5 dd if /dev/zero of /dev/null
5 0 root S 1244 0.0 0 0.0 top
We can see the pod taking 10% of the node CPU. On a 2 core CPU node, this corresponds to 200m of the single CPU.
Both resources requests and limits are specified for each container individually, not for the entire pod. The pod resource requests and limits are the sum of the requests and limits of all the containers contained into the pod.
We can check the usage of the resources at node level by describing the node
kubectl describe node kubew00
...
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
default limited-pod 200m (10%) 200m (5%) 0 (0%) 0 (0%)
default request-pod 200m (10%) 0 (0%) 0 (0%) 0 (0%)
Allocated resources:
Resource Requests Limits
-------- -------- ------
cpu 400m (20%) 200m (10%)
memory 0 (0%) 0 (0%)
The resource usage is provided by the cAdvisor agent running into kubelet binary and exposed externally to the port 4194 on the worker node. This is an unsecure port and it might be closed on some setups. To open this port, pass the --cadvisor-port flag to the kubelet configuration. We can start a simple web UI of the cAdvisor agent by using a web browser. The cAdvisor auto-discovers all containers running on the node and collects CPU, memory, filesystem, and network usage statistics. It also provides the overall machine usage and metrics.
The Metric Server is a kubernetes add-on running as pod in the cluster. It makes centrally accessible all the metrics collected by all the cAdvisor agents running on the worker nodes. Once installed, the metric server makes it possible to obtain resource usages for nodes and individual pods through the kubectl top command.
To see how much CPU and memory is being used on the worker nodes, run the command:
kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
kubew03 366m 18% 2170Mi 38%
kubew04 102m 6% 2170Mi 38%
kubew05 708m 40% 2170Mi 38%
This shows the actual, current CPU and memory usage of all the pods running on all the nodes.
To see how much each individual pod is using, use the command:
kubectl top pods
NAME CPU(cores) MEMORY(bytes)
curl 0m 0Mi
limited-pod 200m 0Mi
request-pod 999m 0Mi
To see resource usages across individual containers instead of pods, use the --containers option
kubectl top pod limited-pod --containers
POD NAME CPU(cores) MEMORY(bytes)
limited-pod busybox 200m 0Mi
Metrics are also exposed as API by the kubernetes API server at http://cluseter.local/apis/metrics.k8s.io/v1beta1 address.
The purpose of the Metric Server is to provide a stable, versioned API that other kubernetes components can rely on. Metric Server is part of the so-called core metrics pipeline and it is installed as kubernetes add-on.
In order to setup the Metrics Server, we first need to configure the aggregation layer on the cluster. The aggregation layer is a feature of the API server, allowing other custom API servers to register themselves to the main kubernetes API server. This is accomplished by configuring the kube-aggregator on the main kubernetes API server. The aggregator is basically a proxy (embedded into the main API server) that forwards requests coming from clients to all the API servers, including the main one.
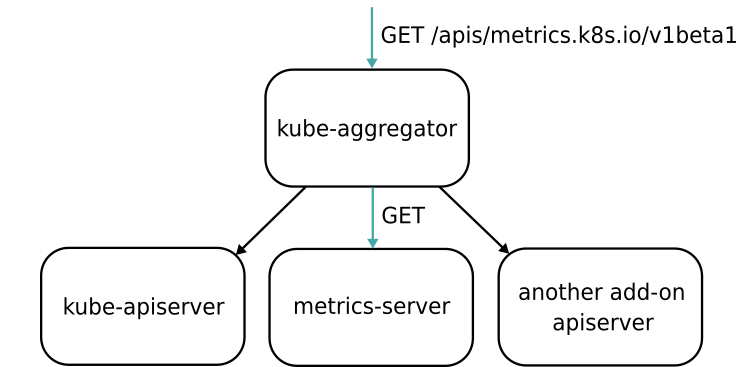
Configuring the aggregation layer involves setting a number of flags on the API Server
--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt
--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key
--requestheader-allowed-names=front-proxy-client
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--enable-aggregator-routing=true
See here for details.
The Metric Server is only one of the custom API server that can be used by means of the aggregator. To install the Metric Server, configure the API server to enable the aggregator and then deploy it in the kube-system namespace from the manifest files:
kubectl apply -f auth-delegator.yaml
kubectl apply -f auth-reader.yaml
kubectl apply -f resource-reader.yaml
kubectl apply -f metrics-apiservice.yaml
kubectl apply -f metrics-server-sa.yaml
kubectl apply -f metrics-server-deployment.yaml
kubectl apply -f metrics-server-service.yaml
The metric server will be deployed as pod and exposed as an internal service.
get deploy metrics-server
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
metrics-server 1 1 1 1 2h
kubectl get svc metrics-server
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
metrics-server ClusterIP 10.32.0.19 <none> 443/TCP 2h
The Metric Server is the foundation for the autoscaling feature.
Applications running in pods can be scaled out manually by increasing the replicas field of the Replica Set, Deploy, or Stateful Set. However, kubernetes can monitor the pods and scale them up automatically as soon as it detects an increase in the CPU usage or some other metric. To achieve this, we need to configure an autoscaler object. We can have multiple autoscalers, each one controlling a separated set of pods.
The pods autoscaling process is implemented as a control loop that can be split into three steps:
- Obtain metrics of all the pods managed by the scaled resource object.
- Calculate the number of pods required to bring the metrics close to a target value.
- Update the replicas field of the scaled resource.
The autoscaler controller doesn’t perform the collection of the pod metrics itself. Instead, it gets the metrics from the Metric Server through REST calls.
Once the autoscaler gathered all the metrics for the pods, it can use those metrics to return the number of replicas to bring the metrics close to the target. When the autoscaler is configured to consider only a single metric, calculating the required replica count is simple: sum the metrics values of all the pods, divide that by the target value and then round it up to the next integer. If multiple metrics are used, then the calculation takes place independently for each metric and then the maximum integer is considered.
The final step of the autoscaler is update the desired replica count field on the resource object, e.g. the deploy, and then letting it take care of spinning up additional pods or deleting excess ones. However, to deal with spike in the metrics, the scale operation is smoothed: if only one replica exists, it will scale up to a maximum of four replicas in a single step; if two or more replicas exist, it will double the number of replicas in a single step.
The period of the autoscaler is controlled by the --horizontal-pod-autoscaler-sync-period flag of controller manager (default 30 seconds). The delay between two scale up operations is controlled by using the --horizontal-pod-autoscaler-upscale-delay flag (default 180 seconds). Similarly, the delay between two scale down operations is adjustible with the --horizontal-pod-autoscaler-downscale-delay flag (default 300 seconds).
The most common used metric for pods autoscaling is the node's CPU consumed by all the pods controlled by the autoscaler. Those values are collected from the Metric Server and evaluated as an average.
The target parameter used by the autoscaler to determine the number of replicas is the requested CPU specified by the pod descriptor.
In this section, we're going to configure the pods autoscaler for a set of nginx pods.
Define a deploy as in the following nginx-deploy.yaml descriptor file
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: nginx
namespace:
spec:
replicas: 3
selector:
matchLabels:
run: nginx
template:
metadata:
labels:
run: nginx
spec:
containers:
- image: nginx:1.12
name: nginx
ports:
- containerPort: 80
protocol: TCP
resources:
requests:
cpu: 50m
limits:
cpu: 100mWe set the requests for 50m CPU. This means that, considering a standard two CPUs node, each pod needs for the 2.5% of node's CPU to be scheduled. Also we set 100m CPU as hard limit for each pod. This means that each pod cannot eat more than 5% of the node's CPU.
Create the deploy
kubectl apply -f nginx-deploy.yaml
and check the pods CPU usage
kubectl top pod
NAME CPU(cores) MEMORY(bytes)
nginx-945d64b6b-995tf 0m 1Mi
nginx-945d64b6b-b4sc6 0m 1Mi
nginx-945d64b6b-ncsnm 0m 1Mi
Please, note that it takes a while for cAdvisor to get the CPU metrics and for Metric Server to collect them. Because we’re running three pods that are currently receiving no requests, we should expect their CPU usage should be close to zero.
Now we define an autoscaler as in the following nginx-hpa.yaml descriptor file
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: nginx
namespace:
labels:
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: nginx
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 20This creates an autoscaler object and sets the nginx deployment as the scaling target object. We’re setting the target CPU utilization to 20% of the requested CPU, i.e. 10m for each pod. We're also specifying the minimum and maximum number of replicas. The autoscaler will constantly adjusting the number of replicas to keep the single pod CPU utilization around 10m, but it will never scale down to less than one or scale up to more than ten replicas.
We can also spcify the metrics in terms of direct values, istead of percentage of the requested value. To achieve this, simply use the targetAverageValue: 10m instead of the targetAverageUtilization: 20.
Create the pods autoscaler
kubectl apply -f nginx-hpa.yaml
and check it
kubectl get hpa nginx
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 0/20% 1 9 1 3s
Because all three pods are consuming an amount of CPU close to zero, we expect the autoscaler scale them to the minimum number of pods. Is soon scales the deploy to a single replica
kubectl get deploy nginx
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 1 1 1 1 10m
Remember, the autoscaler only adjusts the desired replica count on the deployment. Then the deployment takes care of updating the desired replica count on its replica set, which then causes the replica set to delete the two excess pods, leaving only one pod running.
Now, we’ll start sending requests to the remaining pod, thereby increasing its CPU usage, and we should see the autoscaler in action by detecting this and starting up additional pods.
To send requests to the pods, we need to expose them as an internal service, so we can send requests in a load balanced mode. Create a service as for the nginx-svc.yaml manifest file
kubectl apply -f nginx-svc.yaml
Also we define a simple load generator pod as in the following load-generator.yaml file
apiVersion: v1
kind: Pod
metadata:
name: load-generator
namespace:
labels:
spec:
containers:
- image: busybox:latest
name: busybox
command: ["/bin/sh", "-c", "while true; do wget -O - -q http://nginx; done"]Create the load generator
kubectl apply -f load-generator.yaml
As we start to sending requests to the pod, we'll see the metric jumping to 72m, that is more than the target value of 10m.
kubectl top pod
NAME CPU(cores) MEMORY(bytes)
nginx-55cbff4979-spg9p 72m 1Mi
This corresponds to 140% of the requested CPU
kubectl get hpa -o wide
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa/nginx Deployment/nginx 144%/20% 1 10 1 2m
and that's very far from the target of 20%.
Now the autoscaler calculates the required replicas based on the measured CPU utilization: ceil(144/20) = 8 replicas. However, since only one replica exists, the autoscaler will scale up to a maximum of four replicas in a single step:
kubectl get deploy nginx
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 4 4 4 4 15m
Checking the pod's consumed CPU
kubectl top pod
NAME CPU(cores) MEMORY(bytes)
nginx-55cbff4979-6c6zd 20m 1Mi
nginx-55cbff4979-lxmkd 20m 1Mi
nginx-55cbff4979-spg9p 20m 1Mi
nginx-55cbff4979-xnx7t 20m 1Mi
we see each pod consuming 20m, that is more than the target value of 10m.
This corresponds to 40% of the requested CPU
kubectl get hpa -o wide
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa/nginx Deployment/nginx 40%/20% 1 10 4 16m
and that's still far from the target value of 20%.
After the upscale delay timeout (default 180 seconds), the autoscaler starts calculating again the number of replicas: ceil((40+40+40+40)/20) = 8 replicas. Since four replicas exist, the autoscaler scales up the deploy to have 8 replicas
kubectl get deploy nginx
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 8 8 8 8 20m
Checking the pod's consumed CPU
kubectl top pod
NAME CPU(cores) MEMORY(bytes)
nginx-55cbff4979-6c6zd 10m 1Mi
nginx-55cbff4979-fwgd8 10m 1Mi
nginx-55cbff4979-hlrcv 10m 1Mi
nginx-55cbff4979-lmgzm 10m 1Mi
nginx-55cbff4979-lxmkd 10m 1Mi
nginx-55cbff4979-nckqh 10m 1Mi
nginx-55cbff4979-spg9p 10m 1Mi
nginx-55cbff4979-xnx7t 10m 1Mi
we see each pod consuming 10m, that is the target value.
kubectl get hpa -o wide
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa/nginx Deployment/nginx 20%/20% 1 10 8 20m
Stopping the load generator
kubectl delete -f load-generator.yaml
we can see the pod's consumed CPU reaching zero
kubectl top pod
NAME CPU(cores) MEMORY(bytes)
nginx-55cbff4979-6c6zd 0m 1Mi
nginx-55cbff4979-fwgd8 0m 1Mi
nginx-55cbff4979-hlrcv 0m 1Mi
nginx-55cbff4979-lmgzm 0m 1Mi
nginx-55cbff4979-lxmkd 0m 1Mi
nginx-55cbff4979-nckqh 0m 1Mi
nginx-55cbff4979-spg9p 0m 1Mi
nginx-55cbff4979-xnx7t 0m 1Mi
After the down scale delay timeout (default 300 seconds), the autoscaler will scale down the deploy to a single replica only
kubectl get deploy nginx
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 1 1 1 1 30m
Please, note the autoscaler does't work with target resources that do not support scaling operations, e.g. the daemon sets.
Configure the memory based autoscaling is less easy than CPU based autoscaling. The main reason is because the memory management depends much more on the application itself than on the operating system. For example, after scaling up, the previous set of pods need to release memory to make the autoscaler working properly. Unfortunately, this is much related to the application memory management (think Java based applications) and we cannot be sure the memory is released by the application, so in that case, the autoscaler would scale it up again until it reaches the maximum number of pods configured on the autoscaler object.
Often one metric does not fit all use cases. For example, for a message queue application, the number of messages in waiting state might be a more appropriate metric than the CPU or memory usage. As another example, for a business application which handles thousands of transactions per second, the QPS (Query Per Second) might be the right metric to use.
Kubernetes supports the usage of custom metrics for the pods autoscaler. Custom metrics rely on custom adapters that serves the custom metrics API. These adapters need to be registered at /apis/custom.metrics.k8s.io of the main kubernetes API server to tell the aggregation layer where to forward requests for custom metrics.
The most common solution for custom metrics in kubernetes is based on the Prometheus project.
The pods autoscaler creates additional pod instances when the need for them arises. However, it may encounter the problem where none of the nodes can accept the more pods, because the node’s resources aren't enough to run all required pods. In that case, the only option is to add new nodes to the cluster. This could be a manual process involving the cluster infrastructure or it can be automated by means of the nodes autoscaler.
Unlike the pods autoscaler, the nodes autoscaler (a.k.a cluster autoscaler) relies on the cluster infrastructure to work. For example, if the cluster is hosted on a cloud infrastructure, the autoscaler needs to use the APIs provided by the cloud provider to provision new node instances.
The cluster autoscaler takes care of automatically provisioning (scale up) additional nodes when there are unschedulable pods because of a lack of resources on the current set of nodes. It also deprovisions (scale down) nodes when they are underutilized for a given period of time.