Introduction to Mixins Overwriting Methods
Up to this point, the mixin functionality we have covered has been exclusively additive in nature, and does not fundamentally alter the original behaviour of the target class. However there are two situations where we may wish to have our mixins alter or replace content in the target class:
- We wish to change the behaviour of an existing method.
- We wish to define an accessor in the target class which already exists, but whose name may change after it is obfuscated.
Both of these scenarios require us to potentially overwrite some part of the target class.
Overwrites are the least subtle of the mixin capabilities, and in general effort should be undertaken to instead make use of Callback Injectors, Rerouters or other mixin code injection capabilities.
Let's take a moment to remind ourselves of the example from the first part of this tutorial where we add the method setLevel to the target class using a mixin:
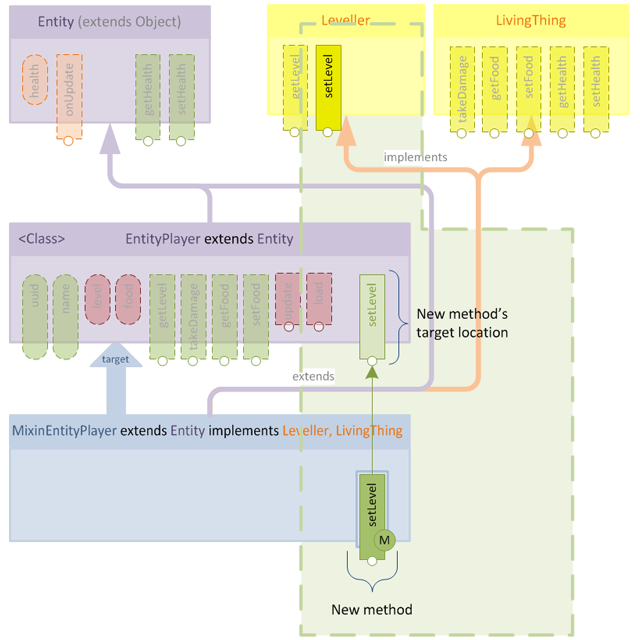
The mixin contains the extra method with no extra decoration and the method is added to the target class. After mixin application, the method exists in the target class as if it had been there all along. I've tagged the mixin method with  in order to make it easier to spot when merged:
in order to make it easier to spot when merged:
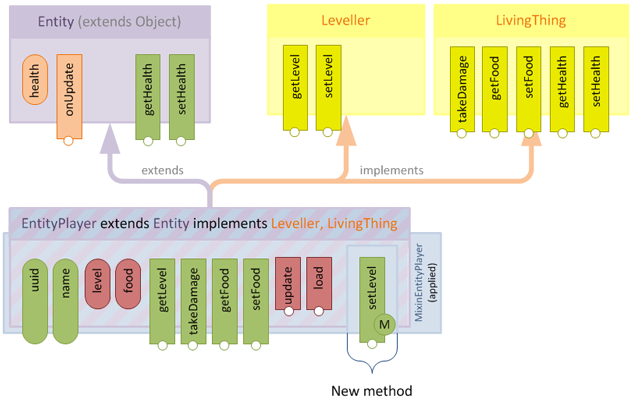
So the next question is: what happens if we declare a method in a mixin which already exists in the target class?
The answer is, the mixin method completely overwrites the original method.
Let's take a look at a simple example. We will assume that the getLevel() method in EntityPlayer doesn't function in the manner required by our interface. Maybe the interface contract stipulates that calling getLevel() should always return a non-negative value, but the internal structure of EntityPlayer does not prevent negative levels and we want to guard against this.
We will define a new body for getLevel() which respects the interface contract:
@Mixin(EntityPlayer.class)
public abstract class MixinEntityPlayer
extends Entity
implements LivingThing, Leveller {
@Shadow
private int level;
/**
* This method overwrites getLevel in the target class and
* ensures that it returns a non-negative value.
*/
public int getLevel() {
return Math.max(this.level, 0);
}
@Override
public void setLevel(int newLevel) {
... etc.Now when the mixin is applied, the getLevel() method defined in the mixin will overwrite its existing counterpart:
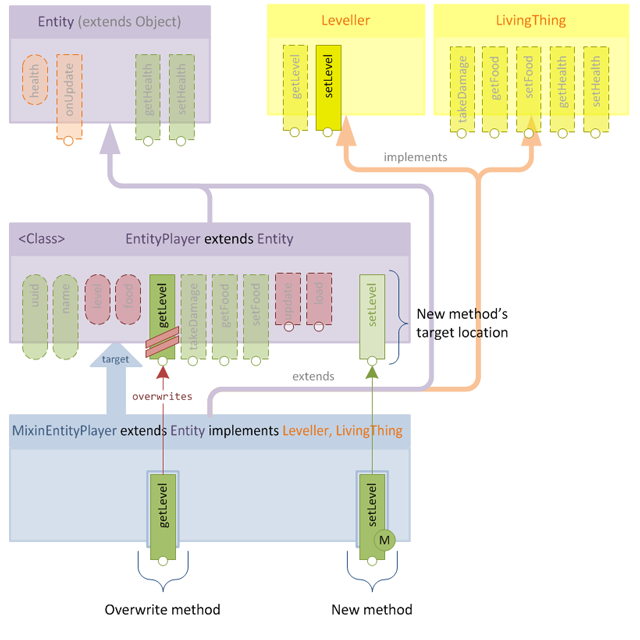
Resulting in a class whose structure is no different from before, but contains our new logic in the getLevel() method.
It should be noted early on that overwrites are not some kind of panacea, they have a number of quite significant drawbacks and care should be taken when choosing to use them. Drawbacks include, but are not limited to:
- Overwrites completely eradicate any previous transformations applied to the method. This means that any other mod using a transformer to change the target method will have their changes eradicated. This could cause the other mod, or even the entire game to become unstable.
- As well as other mods, other mixins which want to overwrite the same method will conflict. The mixin with the highest defined priority will win, and only the overwrite from that mixin will actually be present in the target class. If a later mixin tries to overwrite a method from a mixin with a higher priority, a warning is generated.
- Overwriting more complex methods may lead to the overwrite becoming "out of date". For example if you decide to overwrite a method with a modified version of its original code, it becomes your responsibility to ensure that that code maintains parity with its target in your mixin. You can help yourself do this using constraints (see below).
- Using overwrites may cause premature baldness and a tendency to shout at traffic.
You should thus consider carefully whether to use an overwrite. Some considerations, and places where overwrites are appropriate to use are:
-
Simple methods, such as accessors Using overwrites in these scenarios to decorate an accessor with some additional logic can be a quick and efficient way to add functionality such as argument validation. Since getters and setters don't tend to be very dynamic, modifying them using overwrites is quick and straightforward. However you should still consider whether an Injector would be more suitable.
-
Rapid prototyping Another place where overwrites can be handy is when prototyping changes to a method which you intend to later change to use Callback Injectors. Making a copy of the original method in your mixin can be a fast and easy way to create a simple "patch" during development, especially when trying to determine the best way to alter a method's behaviour to suit your needs.
-
Situations where injectors simply aren't powerful enough Whilst Callback Injectors are incredibly powerful, their scope is nevertheless limited and you will occasionally encounter scenarios where they don't cut the mustard, especially in extremely complex or large methods. As with all overwrites, extreme reluctance should be excercised when taking this kind of approach, but sometimes it's simply necessary.
-
Careful with that rope Overwrites should be considered a great length of rope to hang yourself with. Ensure that overwrites don't come back to bite you by setting up a process for managing any overwrites you have on an ongoing basis. I recommend that you, as a minimum:
-
Decorate all overwriting methods with comments explaining why the overwrite is being used, who added it and when they did so. Review these comments on an ongoing basis to ensure that overwrites remain necessary and relevant.
-
When using a "copy and modify" approach to overwrites, where the original method body is used as a starting point, comment changes you make to the method body. This will make it easier to extract and merge your changes should the target method change.
-
Decorate any overwrites used for prototyping or "to be converted to injectors" as such so that they don't get left in the codebase longer than necessary.
-
Use constraints to add a level of sanity checking to your overwrites, more details on these are provided in the section below.
You may have wondered why the the previous section went into such a painful amount of detail to define this thing we refer to as the obfuscation boundary. You may recall from that section that
Any mixin-specific mechanisms ... will always be decorated with some kind of annotation. This makes them visible to the Mixin Annotation Processor which will handle their obfuscation traversal.
... and indeed this is the case.
If you think about it this is perfectly logical: an overwrite method doesn't "know" it's going to be overwriting a target method until the mixin is applied, at which point it discovers that it's comfy spot by the fire is already occupied by the original method and realises its destiny as an overwrite. This is fine when no obfuscation is involved, but is a real pain when there is because we need some way of "connecting" the overwrite with the desired target method in order to let the AP generate the obfuscation table entries.
To do this, we use a simple annotation called @Overwrite.
/**
* Adding the annotation to our overwrite connects it with
* its will-be-obfuscated target method.
*/
@Overwrite
public int getLevel() {
return Math.max(this.level, 0);
}Decorating a method with @Overwrite will cause the annotation processor to look up the target method at compile time. If no mapping is found the AP will generate an error.
This means that:
-
To define an overwrite in your mixin for a method which is not obfuscated, you should simply declare the method.
-
To define an overwrite for a method which is obfuscated you should declare the method and decorate it with an
@Overwriteannotation.
You should also bear in mind that any mixin containing an overwrite method cannot target more than one class. The reason for this is that even if all of the target classes define the same method with the same name and signature in the mcp environment, this will not be the case for the obfuscated environment where every method has a unique name. It is possible to work around this restriction using aliases but this is not recommended.
There is one final use of the @Overwrite decoration. Defining an overwrite for a public static method in the target class.
By default, including a method declared as public static in a mixin raises an Id10t Error, since there is no way to ever call a method defined in this way! However it should be clear that overwrites provide a use-case for this otherwise pointless operation. Decorating the method with @Overwrite will bypass the restriction and allow the public static method to be defined in the mixin.
Whilst the behaviour of regular overwrites is easy to understand and quite predictable, their lack of flexibility presents some challenges for mixin design which are not easy to overcome. The good news is that Mixin provides built-in functionality to cope with these problems. The not so good news is that this functionality looks quite complicated at first. We shall approach the problem step-by-step in order to understand these methods more clearly.
As we have seen, one of the key undertakings with Mixin is to provide pseudo-duck-typing capabilities in our Java applications by applying our own interfaces to existing objects using mixins. As we have seen, sometimes a method in the existing class will already implement an interface method, we call this type of method an Intrinsic method because it is a part of the existing class: effectively our class already knows - intrinsically - how to quack.
However there's a problem: what happens if the intrinsic method in question is obfuscated? The answer is - the object no longer quacks once it's obfuscated, and the interface contract is broken once the obfuscation boundary is crossed.
Let's look at a simple example. In this example, we will use the same class and interface from the previous article, but we will assume that instead the Identifyable interface doesn't conflict with the target object this time:
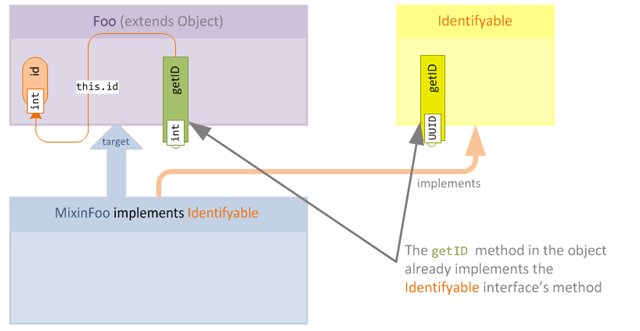
As we can see, no implementation of getID is required in the mixin, since the class Foo already intrinsically implements the interface. However, after obfuscation the class, field and method names have all changed, and we run into a problem:
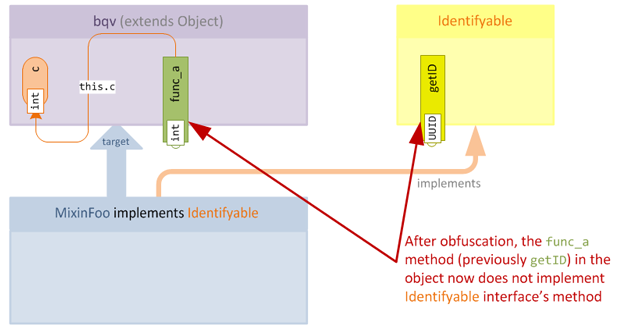
Now that the method is no longer implemented, any consumer will cause an AbstractMethodError to be raised if they try to call the method.
There is a way to fix this using functionality we already know about:
-
Overwrite the method with a copy of the original method
This might seem like the most obvious, and it's certainly the simplest approach. As we know, omitting the
@Overwriteannotation will cause the overwrite to not be obfuscated. This means that in our dev environment (where the method and field names are not obfuscated) the method will simply overwrite the existing method in the target:
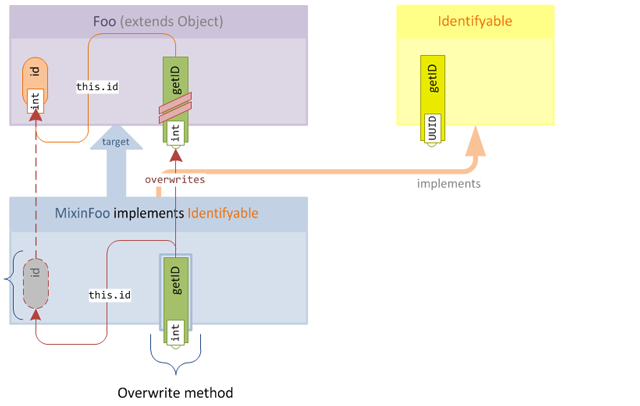
After obfuscation, the overwrite magically transforms into a new accessor, since the semantics of method merging mean that the method will simply be added to the target class:
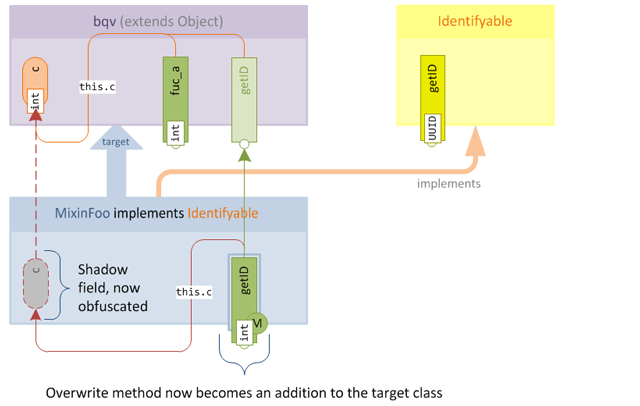
The two major drawbacks with this approach are firstly that it requires duplicating the original method into the mixin, which is acceptable for simple accessors but can be problematic for more complex methods, since it once again puts us in a position of needing to manually retain functional parity with the target method; if the target method changes then we must update our overwrite. Secondly we potentially end up needing to create shadows for fields which we are not really interested in and would rather access via the public contract of the existing class (for example via the original accessors) and for more complex methods this could potentially be a lot of shadow fields. We are not really interested in these fields except for replicating the functionality of the original method, so adding them just creates code noise.
Intrinsic Proxy methods allow us finer-grained control over the overwrite process when this situation arises.
We can improve on the situation somewhat by introducing a new overwrite behaviour, specifically:
"Don't overwrite method if it already exists (is intrinsic)"
In this situation, we create the overwrite as above, but decorate it with an @Intrinsic annotation. This effectively declares that the overwrite is for an intrinsic method, and if the method is found then the overwrite should not take place.
Whilst this is not a huge improvement, it does mean that from the point of view of all foreign code (the code in the target codesbase) the original contract of the method is guaranteed to be preserved which alleviates some of the concern that the underlying method may change and the changes won't be reflected in our overwrite. By allowing the original method to always exist, and only adding our new method (for our own code to consume) in production, we have improved the chances of stability somewhat.
Of course, this still means that our own code invoking method calls against our duck-typed interface could end up interacting with different implementations of the method based on the environment, which could be undesirable depending on the nature of the method. What we would really like to be able to do is call the original method, and maybe wrap some of our own logic around it.
Fortunately we can, by defining our overwrite as an intrinsic proxy.
Intrinsic Proxy Methods work by altering the behaviour of an overwrite so that the original method is moved instead of overwritten. We can then call the original method from the overwrite in all circumstances. However in order to define the new proxy method, we need to @Shadow the original method - which creates a conflict. Fortunately we know exactly how to deal with conflicts: we use soft implementation!
Let's take a small step in the direction of sanity and convert our new accessor to a soft implementation:
@Mixin(Foo.class)
@Implements(@Interface(iface = Indentifyable.class, prefix = "id$"))
public abstract class MixinFoo {
@Shadow
public abstract int getID();
/**
* This method will become our intrinsic proxy method, it
* calls the original (shadowed) version of the accessor.
*/
public int id$getID() {
// Call original accessor
return this.getID();
}
}Of course the prefix will be stripped when applying the mixin, this means we will end up with a conflict after the mixin is merged. As we already know, mixin will treat this conflict as an overwrite and we're back at square one!
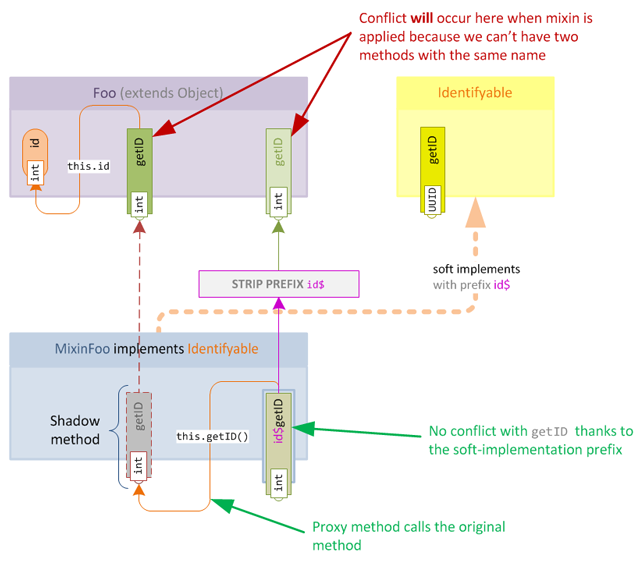
It gets worse however, because the call to this.getID() within the new method now becomes self-referential, this will cause a stack overflow if the method is called because it will recursively call itself until the JVM runs out of stack space!
This is where our new friend @Intrinsic once again comes to the rescue. The @Intrinsic annotation has a secondary behaviour which allows the target intrinsic method to be not replaced but instead displaced, if it already exists.
/**
* This method will become our intrinsic proxy method, it
* calls the original (shadowed) version of the accessor.
* It uses the displace parameter to avoid re-entrance when
* the method would otherwise be overwritten.
*/
@Intrinsic(displace = true)
public int id$getID() {
// Call original accessor
return this.getID();
}Adding the displace parameter causes the intrinsic overwrite to behave in the following way:
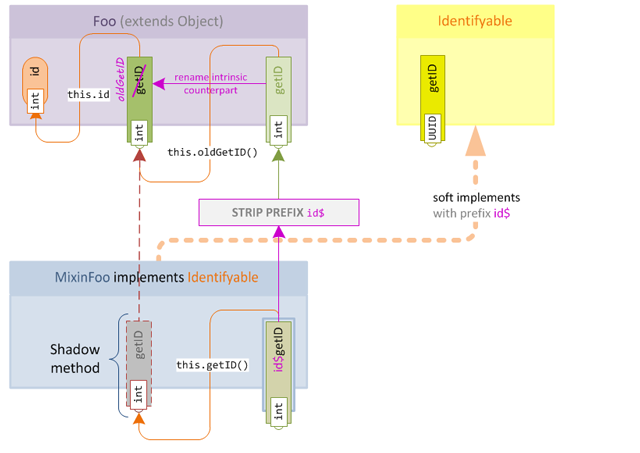
- If the intrinsic counterpart does not exist (for example, if in an obfuscated environment where the method has a different name) then the new proxy method is simply added to the target class as normal.
- If the intrinsic counterpart does exist, then three things happen:
- The intrinsic counterpart is renamed to a new name.
- References to the intrinsic counterpart within the proxy are updated with the new name.
- The proxy method is then added to the target class as before.
This new behaviour allows to have our cake and eat it too, since we ensure that our own code always calls the proxy method but that the contract of the original accessor is always preserved as well. We also do not need to add shadows for any unrelated target class members, and can simply shadow the intrinsic counterpart, making our mixin code much clearer.
Our new mixin behaviour map looks like this:
As mentioned above, overwrite capabilities need to be employed carefully in order to avoid breaking the target application. Whilst applying a strict process to the management of overwrites in your mixin codebase will help a great deal, managing your product "in the wild" can be trickier, especially if users are deploying your product in an unexpected environment, for example with a much later version of the software you are intending to mix into.
Constraints thus provide a level of sanity checking which would otherwise be unavailable, provided that you are able to supply relevant information into the environment upon which constraints may be based.
Constraints take the form of string tokens which are associated with a single integer value. The values of these tokens must be provided into the mixin environment by registering Token Provider instances with the MixinEnvironment.
The tokens are entirely up to you, but in general you will wish to represent some aspect of the target application environment. Let's assume that you are able to fetch the target application's build number from a singleton instance of the application: a simple token provider might look like this:
public class MyTokenProvider implements ITokenProvider {
public Integer getToken(String token) {
if ("BUILD".equals(token)) {
return TargetApplication.getInstance().getBuildNumber();
}
return null;
}
}This token provider returns the application build number for the token BUILD. It returns null for all other tokens which indicates that the provider does not support this token. We must register an instance of our token provider when bootstrapping the Mixin library
Once we have defined tokens in our environment, we can then define constraints on our overwrites:
@Overwrite(constraints = "BUILD(1234)")
public void someHackyOverwrite(int x, int y) {
// do hacky things
}This hacky method is defined with a constraint which indicates that the token BUILD must be defined and also must have the value 1234. If this constraint is not met, the mixin processor will raise an error and crash the application.
We can also define constraints which have some wiggle room built in to them. To define a range of values we could write:
@Overwrite(constraints = "BUILD(1230-1240)")This will allow any value between 1230 and 1240 (inclusive) to succeed, and can also be written as:
@Overwrite(constraints = "BUILD(1230+10)")A full list of constraint specifiers is provided below:
| Constraint String | Meaning |
|---|---|
| () | The token value must be present in the environment, but can have any value |
| (1234) | The token value must be exactly equal to 1234 |
|
(1234+) (1234-) (1234>) |
All of these variants mean the same thing, and can be read as "1234 or greater" |
| (<1234) | Less than 1234 |
| (<=1234) | Less than or equal to 1234 ( equivalent to 1234< ) |
| (>1234) | Greater than 1234 |
| (>=1234) | Greater than or equal to 1234 ( equivalent to 1234> ) |
| (1234-1300) | Value must be between 1234 and 1300 (inclusive) |
| (1234+10) | Value must be between 1234 and 1234+10 (1234-1244 inclusive) |
Any feature of the target environment which can be represented as an integer can be used as the basis for a constraint. For example a boolean state can be represented as 1 or 0.
The exact constraints to use will depend on your target environment, and the expected volatility of the method in question. For example overwriting a simple accessor could be considered much less risky than overwriting a complex one, and could thus recieve a more generous constraint. With extremely volatile methods (volatility in this case being a method's likelihood of being changed) then smaller constraints are probably a good idea.
Of course the exact value of "generous" and "small" will depend on the token, for example using build number on a project with multiple builds per day, "small" might be a value of 100. Whereas with a project which only changes a few times a year, "small" might be a value of 2. Use your judgement when defining tokens into the environment, and document the expected volatility of the token in your application's developer notes.
Overwrites and Intrinsic Proxies provide a great deal of power, however they must be carefully designed taking into account many factors, and should nearly always be avoided when possible.
Using overwrites as another tool in your repertoire can provide a great deal of flexibility and power when designing mixins, using them recklessly and not considering potential pitfalls will almost certainly cause you problems later on in your application lifecycle.