目标受众: Kubernetes 操作员、机器学习工程师、GPU 迷 原文 :https://www.jimangel.io/posts/nvidia-rtx-gpu-kubernetes-setup/
探索云中 GPU 的强大功能激发了我将本地 NVIDIA GPU 与我的 Kubernetes 家庭实验室集群集成的兴趣。
向 Kubernetes 添加 GPU 使我能够运行 Jupyter Notebooks 和 AI/ML 工作负载。这种方法的最大好处是可移植性;本地运行的相同笔记本和模型可以轻松在云中复制。
这个主题让我感到困惑,我不得不依赖来自各个供应商的信息、GitHub 问题和堆栈溢出帖子。
我的目标是揭开这一过程的神秘面纱,提供一条清晰的途径,让您可以直接从自己的设置中利用 GPU 加速来处理 AI/ML 工作负载。
如果您正在关注:
- 您有一个运行 Ubuntu 22.04 LTS 的节点
- 您有一个连接到该节点的 NVIDIA GPU
- Kubernetes 安装并运行
除非另有说明,所有命令都应在上述节点上运行。
让我们将 GPU 连接路径的每个步骤分解为更大的组件( pod/工作负载→ kubernetes →容器运行时→软件→硬件→ GPU )。
我将从上到下介绍每个组件,然后使用“NEEDS”的相反顺序来设置和验证我的 GPU 加速的 Kubernetes homelab。
下图直观地展示了 Kubernetes 设置中的 GPU 连接路径:
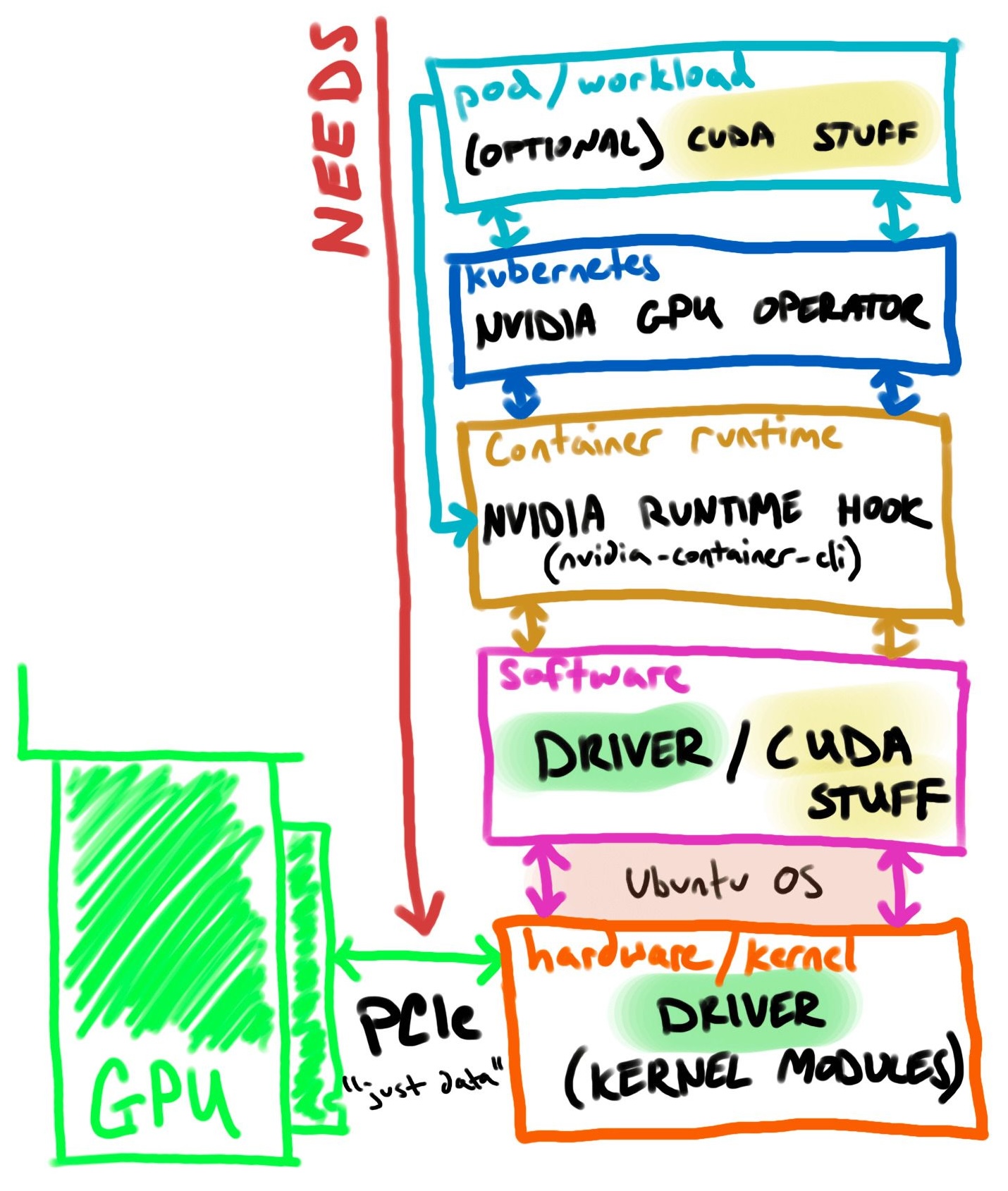
从pod/workload开始,容器应包含软件(如CUDA )以利用 GPU 硬件。我们可以假设容器自动获取带有驱动程序的 GPU,但您仍然需要“在顶部”提供 SDK/API。 NVIDIA容器运行时挂钩提供容器 GPU 设备配置。
对于我的Kubernetes设置,我通过spec.runtimeClassName (运行时类文档)、 spec.containers.resources (资源配额文档)和spec.nodeSelector ( nodeSelector 文档)的组合在 pod/工作负载中声明 GPU。例如:
spec: runtimeClassName: nvidia #<--- USE THE NVIDIA CONTAINER RUNTIME containers: resources: limits: nvidia.com/gpu: 1 #<-- ASSIGN 1 GPU, IF MULTIPLE nodeSelector: #<--- RUN ON GPU ${NODE_NAME} kubernetes.io/hostname: ${NODE_NAME}GPU 节点上出现NoSchedule污点也很常见。这是为了防止不明确需要 GPU 的工作负载运行(污点和容忍文档)。容忍NoSchedule污染:
spec: tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule上面的 YAML 示例指示 Kubernetes 在何处/如何运行工作负载,但是,GPU 被视为“扩展资源”或“非 Kubernetes 内置资源”(文档)。_必须_有某种东西告诉 Kubernetes 有 X 个节点和 X 个 GPU 可用。
许多 NVIDIA GPU 功能均由NVIDIA GPU Operator自动管理,包括向 Kubernetes 通报设备容量的device-plugin-daemonset部署。 ( NVIDIA k8s-device-plugin 文档)
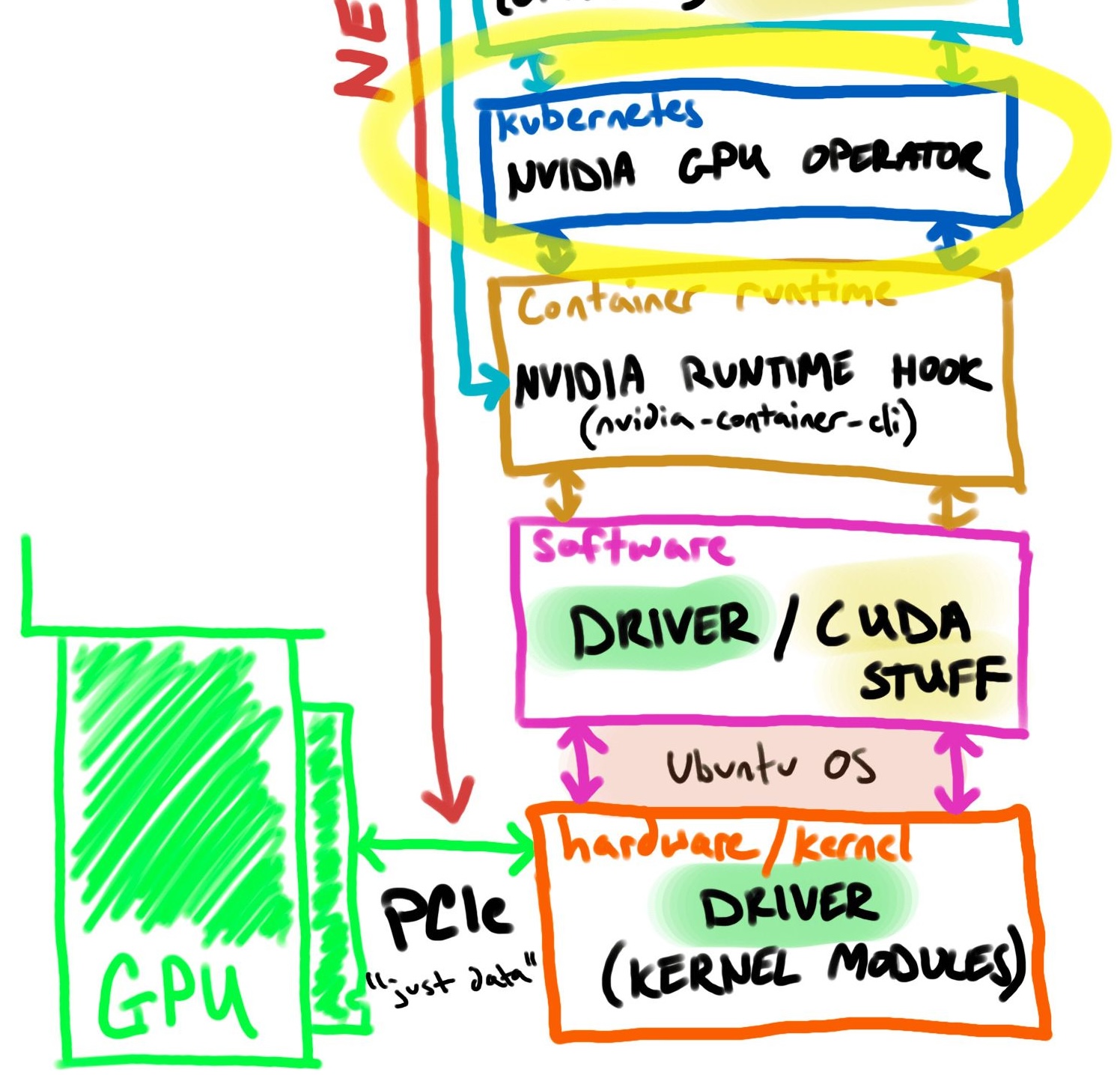
- 在主机上安装 NVIDIA 驱动程序的(可选)能力
- 适用于 GPU 的 Kubernetes 设备插件
- 在主机上配置 NVIDIA Container Runtime 的(可选)能力
- 自动节点标记
- 基于 DCGM(数据中心 GPU 管理器)的监控等
重要的部分是操作员自动为选择器标记节点并评估配额容量。
NVIDIA 设备插件是一个守护进程集,它允许您自动:
- 公开集群每个节点上的 GPU 数量
- 跟踪 GPU 的运行状况
- 在 Kubernetes 集群中运行支持 GPU 的容器
到目前为止,我们的 Kubernetes 集群已将工作负载调度到 GPU 就绪节点,并向容器运行时提供请求 GPU 加速的nvidia RuntimeClass 的指令。
名为 NVIDIA Container Toolkit ( docs ) 的包提供了大部分配置和二进制文件。
在 GPU 节点上,容器运行时(containerd) 配置有一个名为nvidia-container-runtime ( docs ) 的runc包装器。
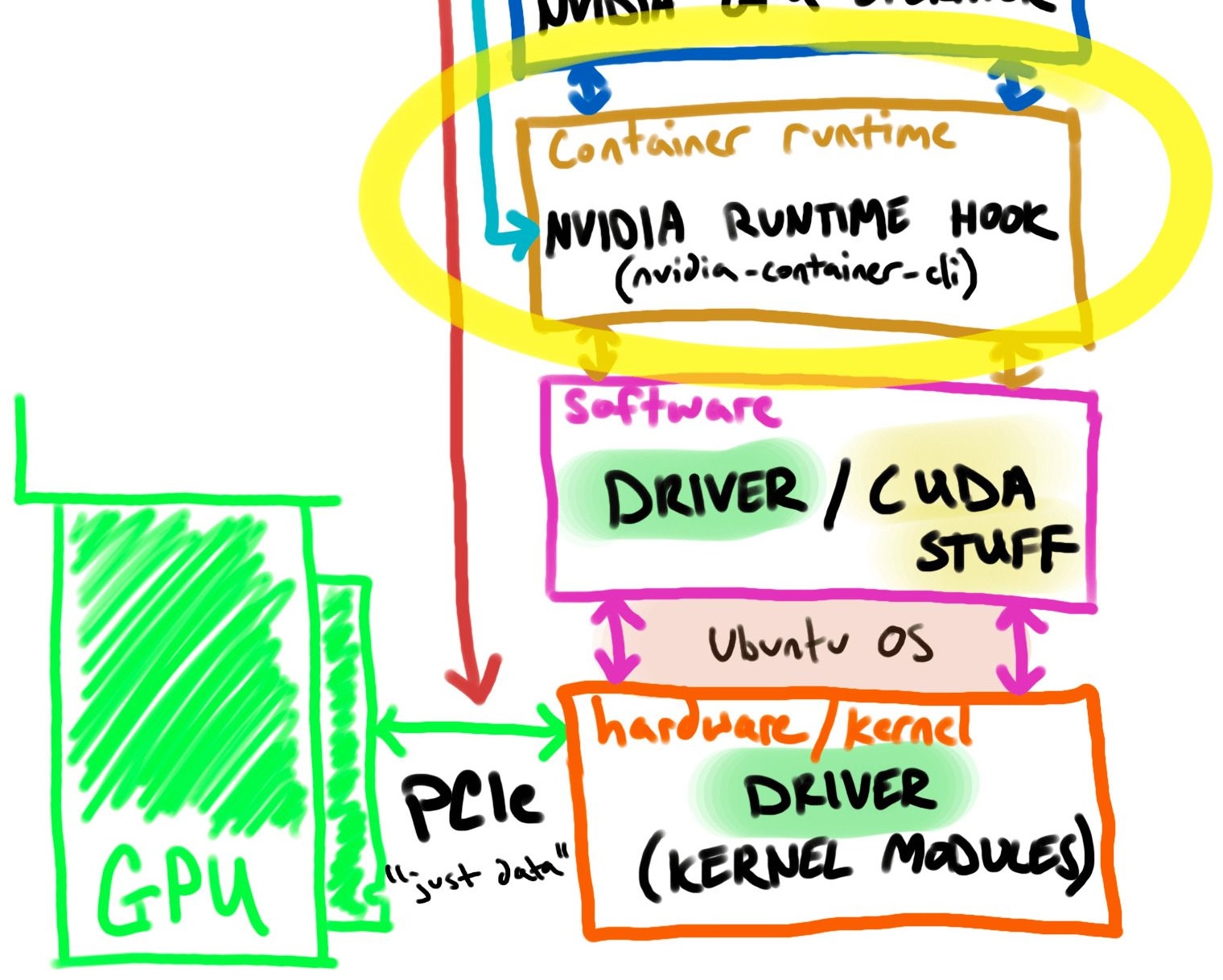
包装器 ( nvidia-container-runtime ) 使用containerd中的预启动挂钩,通过挂载、环境变量等添加主机 GPU。
可以将其想象为将 GPU 硬件配置注入到容器中,但您仍然需要携带软件(例如 CUDA)
以下是containerd使用 NVIDIA 运行时类的示例配置:
# /etc/containerd/config.toml [plugins."io.containerd.grpc.v1.cri".containerd.runtimes] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia] privileged_without_host_devices = false runtime_engine = "" runtime_root = "" runtime_type = "io.containerd.runc.v2" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options] BinaryName = "/usr/bin/nvidia-container-runtime"只要容器使用nvidia运行时类,就会使用上述配置。
配置/etc/containerd/config.toml是通过nvidia-ctk ( nvidia-container-toolkit的一个命名不佳的子集实用程序)自动进行的,稍后介绍。
nvidia-container-toolkit和实用程序负责配置容器运行时,但该过程假设我们已经在主机上配置了 GPU。
简短的答案是司机。驱动程序是操作系统与 NVIDIA 显卡通信所需的基本软件。
NVIDIA 驱动程序使用包管理器安装在 Ubuntu 上。
NVIDIA 驱动程序有 2 个部分,硬件如何知道如何与 GPU 对话(硬件/内核模块)以及软件如何知道如何与 GPU 对话。
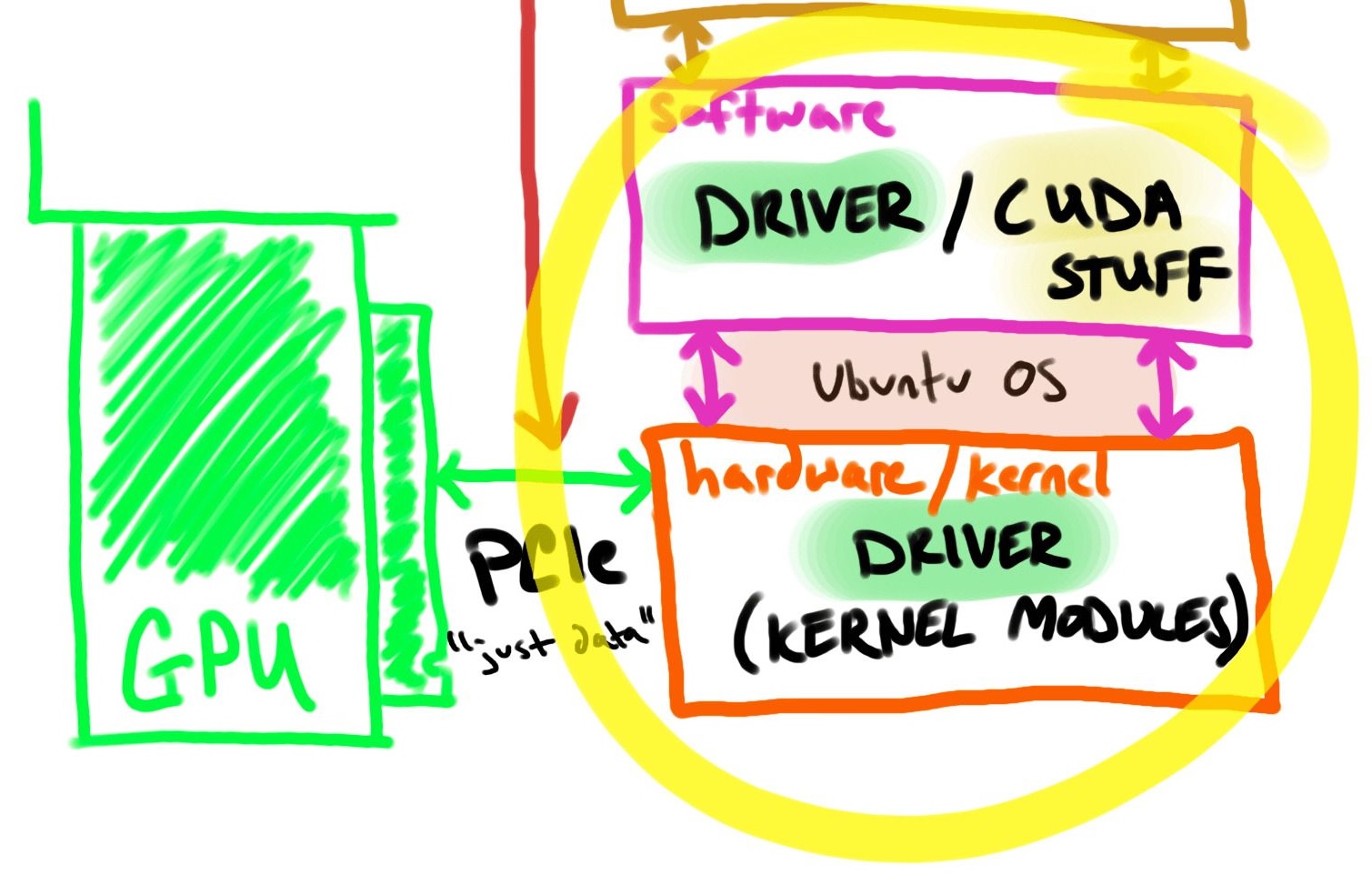
我在图片中包含了“CUDA stuff”,因为它可以安装在主机上,但这取决于具体的用例。本演练不需要它,稍后将对此进行讨论。
这是一个有点棘手的问题。大多数(如果不是全部)消费类 GPU 都是通过 PCIe 连接的。
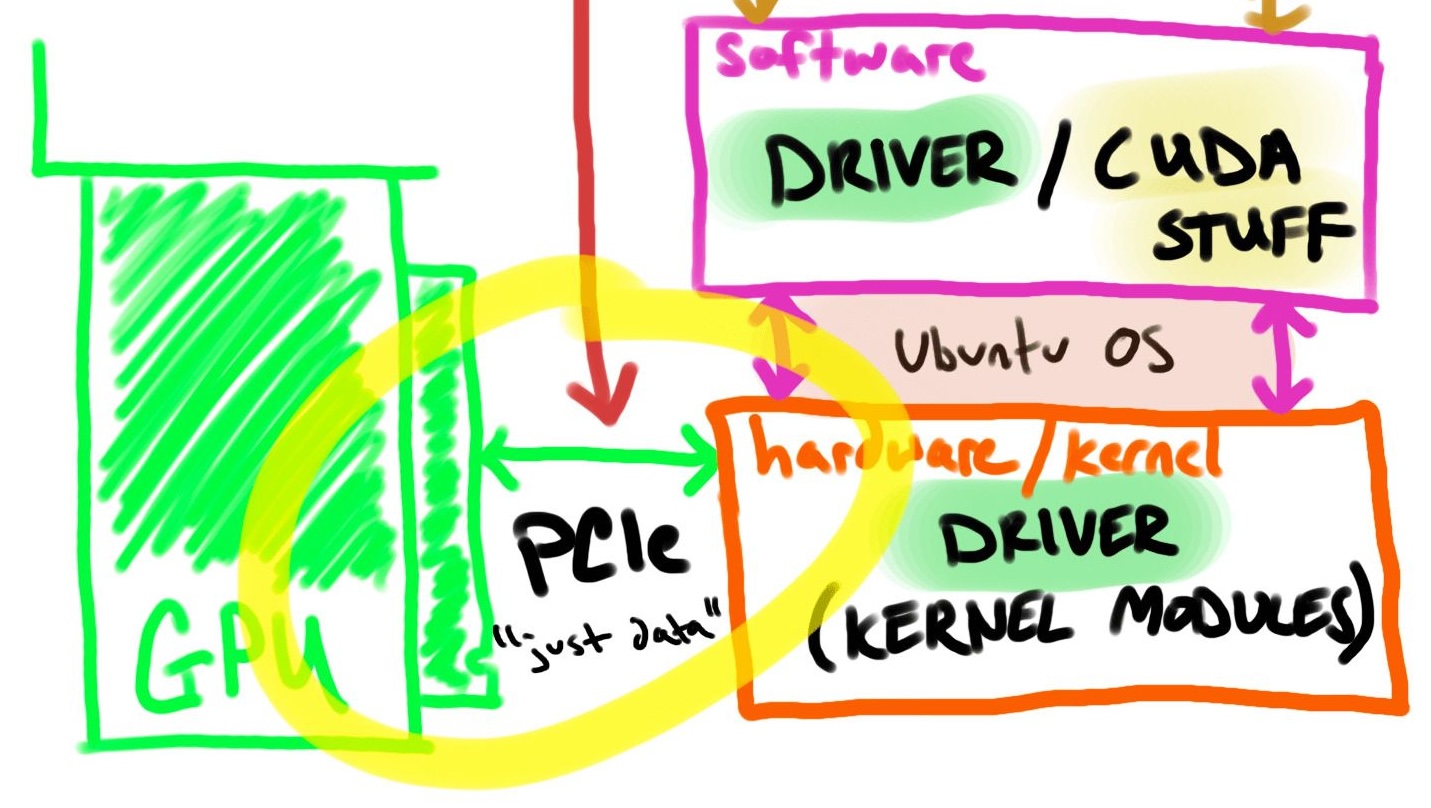
当我进一步思考时,PCIe 支持 GPU、NVMe、NIC 和许多其他外设。这只是传输数据的一种方式。
主板不需要知道它是 GPU,但它确实需要知道_有什么东西_通过 PCIe 插入了它。
笔记
如果使用 Thunderbolt 外部 GPU (eGPU),它仍然被视为 PCI。 “Thunderbolt 将 PCIe 和 DisplayPort 组合成两个串行信号,并通过单根电缆另外提供直流电源。” (来源)
现在我们位于组件的底部,我们可以按照相反的顺序在本地 Kubernetes 集群上安装和验证 GPU。
从我们上次停下的地方开始,让我们检查物理硬件连接。
使用lspci实用程序,用于显示有关系统中的 PCI 总线和连接到它们的设备的信息,以查找已知的 NVIDIA 设备。
# list all PCI devices with the text NVIDIA sudo lspci | grep NVIDIA一切都好! ✅ 输出:
2f:00.0 VGA compatible controller: NVIDIA Corporation GA106 [GeForce RTX 3060 Lite Hash Rate] (rev a1)不仅有许多相互竞争的方法来安装相同的 GPU 驱动程序,而且您如何知道要使用哪个版本?
查找正确的驱动程序版本
使用 NVIDIA 上的搜索菜单驱动程序下载网站查找要安装的最新推荐版本。
例如,搜索 RTX 3060 将返回:
| 场地 | 价值 |
|---|---|
| 版本 | 535.154.05 |
| 发布日期 | 2024.1.16 |
| 操作系统 | Linux 64 位 |
| 语言 | 英语(美国) |
| 文件大小 | 325.86 MB |
这意味着我正在寻找535+ nvidia 驱动程序版本。
CUDA 是帮助应用程序在 NVIDIA GPU 上运行的附加软件。将其视为主机 GPU 的 API。
虽然_此_设置不需要 CUDA 包,但容器中使用的 CUDA 和驱动程序版本之间存在半微妙的关系。如果 CUDA 和您的驱动程序之间不匹配,事情可能无法按预期工作!
提示
安装驱动程序后,可以运行nvidia-smi来检查推荐的CUDA版本,例如nvidia-driver-535输出CUDA 12.2即使我没有安装CUDA。
一旦我与容器中的CUDA 版本以及匹配的主机驱动程序保持一致,我的大部分问题就消失了。 ( CUDA下载)
另外,公平警告,CUDA 为您的容器映像添加了大量资源。
如果你决心缩小镜像的大小,可以选择性地 rm -rf Toolkit 中不需要的部分,但要小心不要删除容器中应用程序可能使用的库和工具!
在 Ubuntu 22.04 LTS 上安装 NVIDIA GPU 驱动程序有几种流行的方法:
- Ubuntu 通过
ubuntu-drivers install管理 NVIDIA 驱动程序(文档) - NVIDIA 通过
.run file管理 NVIDIA 官方驱动程序(下载) - 非官方 PPA 管理的 NVIDIA 驱动程序通过
ppa:graphics-drivers/ppa(文档)
在本演练中,我使用最后一个选项 (ppa),但请随意替换为您喜欢的方法。我选择 PPA 是因为它看起来最简单。
添加 PPA 存储库并安装上面找到的驱动程序。
# add ppa:graphics-driver repo to apt sudo add-apt-repository ppa:graphics-drivers/ppa --yes # update apt content list sudo apt update # install driver sudo apt install nvidia-driver-535警告
我遇到了一个问题,Ubuntu 的unattended-upgrades会自动更新一些 GPU 驱动程序依赖项并破坏我的 GPU 配置。
固定为 sudo apt remove unattended-upgrades 但还有其他不太有力的解决方案。
现在我们已经安装了驱动程序,让我们验证它们是否正常工作。一个快速测试是运行nvidia-smi ,这是一个为 NVIDIA GPU 提供监控和管理功能的实用程序。
# get the driver version nvidia-smi --query-gpu=driver_version --format=csv,noheader通过列出名称中包含“nvidia”或“535”安装的所有软件包 ( dpkg -l ) 来验证安装。
dpkg -l | grep nvidia # or dpkg -l | grep 535 # expected output: non-empty list of packages一切都好! ✅
提示
为了防止意外的软件包更改, hold它们以防止自动升级。
# any package with nvidia in the name should be held dpkg-query -W --showformat='${Package} ${Status}\n' | \ grep -v deinstall | \ awk '{ print $1 }' | \ grep -E 'nvidia.*-[0-9]+$' | \ xargs -r -L 1 sudo apt-mark hold输出:
#... libnvidia-fbc1-535 set on hold. libnvidia-gl-535 set on hold. nvidia-compute-utils-535 set on hold. nvidia-dkms-535 set on hold.这也意味着 sudo apt-mark unhold [package_name] 必须在升级之前运行。
是否安装了内核模块?司机在工作吗?
模块指示内核如何与连接到它的设备进行交互。如果没有任何 NVIDIA 模块,操作系统就不知道如何与硬件通信。
使用lsmod ,该程序列出/proc/modules的内容,显示当前加载的内核模块。
# Show the status of driver modules in the Linux Kernel lsmod | grep nvidia如果您安装了模块,它可能看起来像这样:
nvidia_uvm 1511424 12 nvidia_drm 77824 0 nvidia_modeset 1306624 1 nvidia_drm nvidia 56692736 200 nvidia_uvm,nvidia_modeset drm_kms_helper 311296 1 nvidia_drm drm 622592 4 drm_kms_helper,nvidia,nvidia_drm笔记
我正在使用 eGPU 测试上述输出,但模块没有显示。我以为我的理解错了,结果发现我没有插线。
连接 eGPU 解决了我的问题并且模块出现了。
检查内核驱动版本文件:
cat /proc/driver/nvidia/version一切都好! ✅ 输出:
NVRM version: NVIDIA UNIX x86_64 Kernel Module 535.154.05 Thu Dec 28 15:37:48 UTC 2023 GCC version: gcc version 11.4.0 (Ubuntu 11.4.0-1ubuntu1~22.04)检查设备文件中找到的 nvidia 设备:
# any device files (I/O sys calls) ls /dev/ | grep 'nvidia[0-9]\+'一切都好! ✅ 输出:
看来我们有一个具有可用 GPU 设置的主机,接下来让我们配置containerd以支持 GPU 运行时。
我的家庭实验室正在使用containerd运行 Kubernetes v1.28.4。如前所述,我们需要 NVIDIA Container Toolkit(一组实用程序)来配置containerd以利用 NVIDIA GPU。
据我所知,这会在您的主机上安装工具,但默认情况下不会配置或更改任何内容。
来自“安装 NVIDIA 容器工具包”指南。
# add nvidia-container-toolkit repo to apt sources curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list # update apt content sudo apt update # install container toolkit sudo apt install -y nvidia-container-toolkit现在工具已安装,我们需要更新containerd配置运行时类。幸运的是, nvidia-ctk是工具之一,可以自动化该过程。
来自“安装 NVIDIA 容器工具包”指南。
# options: --dry-run sudo nvidia-ctk runtime configure --runtime=containerd # restart containerd sudo systemctl restart containerd验证containerd是否正在运行 sudo systemctl status containerd
笔记
您可以通过指定运行时名称 ( --nvidia-runtime-name )、NVIDIA 运行时可执行文件的路径 ( --nvidia-runtime-path ) 来自定义 NVIDIA 运行时配置--nvidia-runtime-hook-path )。
还有一个选项可以使用--nvidia-set-as-default将 NVIDIA 运行时设置为默认运行时。 (来源)
如果您想深入了解nvidia-container-runtime在主机上如何公开 GPU,我强烈建议您阅读文档中的低级示例。
如果您还没有厌倦这个主题,那么 NVIDIA 的题为“在容器运行时生态系统中启用 GPU ”的博客非常棒。
检查配置中是否存在 nvidia 运行时。
sudo cat /etc/containerd/config.toml | grep "containerd.runtimes.nvidia."一切都好! ✅ 输出:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]让我们尝试直接在主机上运行容器(跳过 Kubernetes)。首先,我们需要安装nerdctl ,它是docker的直接替代品,它允许我们使用--gpus all参数。
安装 nerdctl 使用预编译版本。
请注意我选择的 CUDA 版本,请查看存储库网站以获取最新的标签选项: docker.com/r/nvidia/cuda/tags
# `nvidia-smi` command ran with cuda 12.3 sudo nerdctl run -it --rm --gpus all nvidia/cuda:12.3.1-base-ubuntu20.04 nvidia-smi # `nvcc -V` command ran with cuda 12.3 (the "12.3.1-base" image doesn't include nvcc) sudo nerdctl run -it --rm --gpus all nvidia/cuda:12.3.1-devel-ubuntu20.04 nvcc -V一切都好! ✅
笔记
如果您使用的是具有多个 GPU 的计算机,则可以将--gpus all替换为--gpus '"device=0,1"'之类的内容来测试共享各个 GPU。
# only use device 0 and 1 out of a possible [0,1,2,3] setup sudo nerdctl run -it --rm --gpus '"device=0,1"' nvidia/cuda:12.2.2-base-ubuntu22.04 nvidia-smi此时,我们有一个可以在容器运行时运行的 GPU 节点。
最后一个难题是,我们需要让 Kubernetes 知道我们有带有 GPU 的节点。
NVIIDA GPU Operator在 Kubernetes 上创建/配置/管理 GPU,并通过 Helm Chart 进行安装。
按照官方说明安装 helm。如果您有兴趣查看 helm 图表和值,请参阅此处的 Github 存储库。
添加舵存储库:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \ && helm repo update在 Kubernetes 集群上安装该版本。
默认情况下,Operator 将 NVIDIA Container Toolkit 和 NVIDIA 驱动程序部署为系统上的容器。由于我们已经安装了这两个组件,因此我们将这些值设置为false 。
helm install --wait gpu-operator \ -n gpu-operator --create-namespace \ nvidia/gpu-operator \ --set driver.enabled=false \ --set toolkit.enabled=false确保所有 pod 都正常运行:
# ensure nothing on kubernetes is wonky kubectl get pods -n gpu-operator | grep -i nvidia一切都好! ✅ 输出:
nvidia-cuda-validator-4hh2v 0/1 Completed 0 3d20h nvidia-dcgm-exporter-86wcv 1/1 Running 5 (7d10h ago) 7d20h nvidia-device-plugin-daemonset-cxfnc 1/1 Running 0 26h nvidia-operator-validator-jhz6j 1/1 Running 0 3d20hkubectl -n gpu-operator logs deployment/gpu-operator | grep GPU这不是一个万无一失的测试,但你应该看到 Number of nodes with GPU label","NodeCount": NUMBER_OF_EXPECTED_GPU_NODES 具有实际值。如果显示 0,则可能存在需要调试的问题。
有用的调试命令: kubectl get events -n gpu-operator --sort-by='.lastTimestamp'
提示
当有疑问时(或者当 GPU 操作员 pod 在单个节点上陷入 init/终止状态但底层设置完好时):重新启动节点。
最后,让我们运行 Kubernetes 工作负载来测试我们的集成是否可以端到端运行。
# EXPORT NODE NAME! export NODE_NAME=node3 cat <<EOF | kubectl create -f - apiVersion: batch/v1 kind: Job metadata: name: test-job-gpu spec: template: spec: runtimeClassName: nvidia containers: - name: nvidia-test image: nvidia/cuda:12.0.0-base-ubuntu22.04 command: ["nvidia-smi"] resources: limits: nvidia.com/gpu: 1 nodeSelector: kubernetes.io/hostname: ${NODE_NAME} restartPolicy: Never EOF通过logs检查输出:
kubectl logs job/test-job-gpu预期输出类似于:
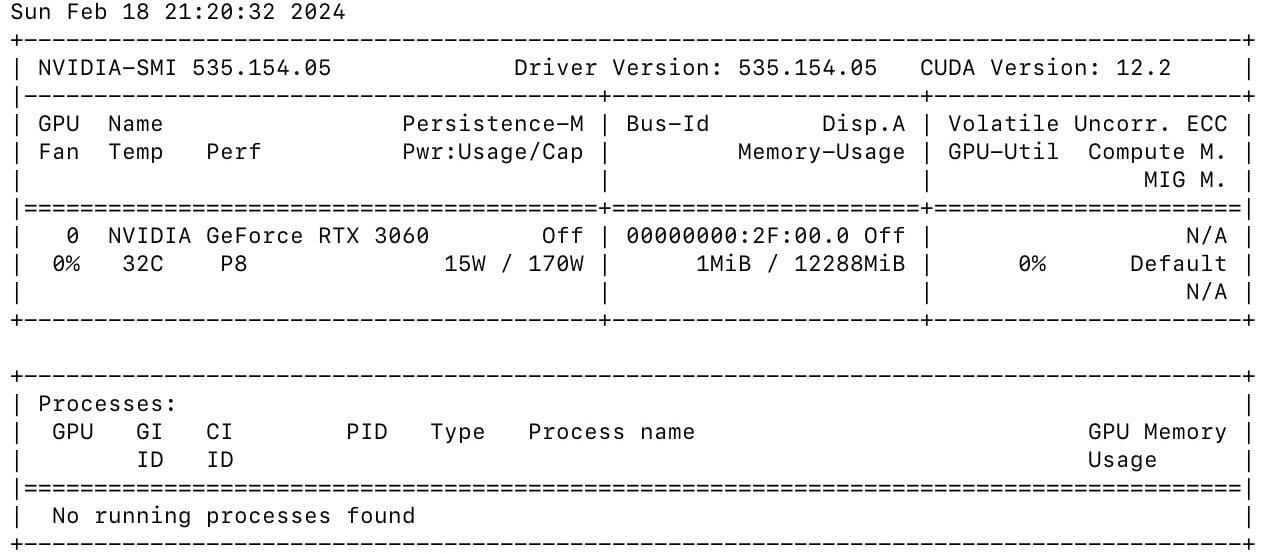
恭喜! 🎉🎉🎉 我们正式拥有本地 GPU 加速的 Kubernetes 集群!
由于涉及的技术层,将 GPU 集成到 Kubernetes 中可能看起来令人畏惧。我希望本指南能够为您揭开 NVIDIA GPU 与 Kubernetes 集成过程的神秘面纱。
总而言之,在 k8s 上暴露 GPU 包括:
- 安装 NVIDIA GPU 驱动程序 (
apt install nvidia-driver-535) - 配置容器运行时(
apt install -y nvidia-container-toolkit&nvidia-ctk runtime configure) - 配置 kubernetes (
helm install nvidia/gpu-operator) - 更新部署 YAML 以包含 GPU 请求
将来,我会考虑使用ubuntu-driver安装程序和/或让 Kubernetes GPU Operator 管理驱动程序和容器工具包。
如果您有任何问题、见解或反馈,请随时分享!
想重新开始吗?安装不同的驱动程序?删除所有内容:
# drain node / remove from cluster # remove gpu-operator deployment helm -n gpu-operator list helm -n gpu-operator delete HELM_RELEASE_NAME # delete driver packages sudo apt remove --purge '^nvidia-.*' sudo apt remove --purge '^libnvidia-.*' # clean up the uninstall sudo apt autoremove # restart containerd我很好奇我目前对本地 NVIDIA GPU 的理解与云中的 GPU 加速相比如何,因此我在 GKE 上启动了一个 A100 节点。
我必须部署该节点两次,因为我在第一次部署时犯了一个错误。我省略了gpu-driver-version=default ;所以没有找到驱动程序和工具(按预期),但我可以看到连接的 PCI 设备。
这里有关于在 COS 上手动安装驱动程序的说明,但我认为它超出了范围。
这是我用来(重新)创建节点池的命令:
# create command gcloud container node-pools create gpu-pool-2 \ --cluster cluster-2 \ --region us-central1 \ --machine-type a2-highgpu-1g \ --num-nodes 1 \ --accelerator type=nvidia-tesla-a100,count=1,gpu-driver-version=default让我们看看我们能找到什么!
# gcloud compute ssh NODE_NAME # PCI connection? sudo lspci | grep NVIDIA 00:04.0 3D controller: NVIDIA Corporation GA100 [A100 SXM4 40GB] (rev a1) # Driver installed? cat /proc/driver/nvidia/version #NVRM version: NVIDIA UNIX x86_64 Kernel Module 470.223.02 Sat Oct 7 15:39:11 UTC 2023 #GCC version: Selected multilib: .;@m64 # tab complete `nvidia-c*` nvidia-container-runtime nvidia-container-runtime.cdi nvidia-container-runtime-hook nvidia-ctk # Where is nvidia-smi? sudo find / -type f -name "nvidia-smi" 2>/dev/null # /home/kubernetes/bin/nvidia/bin/nvidia-smi # Runtime? sudo cat /etc/containerd/config.toml | grep "containerd.runtimes.nvidia." # NO! # But, a quick look around: # bin k8s container runtime is in the default + device plugin # it looks like some things mounted via default runc runtime here, but idk sudo cat /etc/containerd/config.toml | grep bin # OUTPUT # bin_dir = "/home/kubernetes/bin" # ls /home/kubernetes/bin/nvidia/bin/ #nvidia-bug-report.sh nvidia-debugdump nvidia-ngx-updater nvidia-sleep.sh nvidia-xconfig #nvidia-cuda-mps-control nvidia-installer nvidia-persistenced nvidia-smi #nvidia-cuda-mps-server nvidia-modprobe nvidia-settings nvidia-uninstall # check nvidia containers running crictl ps | grep nvidia-gpu # OUTPUT 25eec6551f9e5 2f78042af231d 7 hours ago Running nvidia-gpu-device-plugin 0 ca9dd0d8e2822 nvidia-gpu-device-plugin-small-cos-674fk凉爽的!有些事情是我假设的,有些事情我还需要进一步挖掘!