❤️💕💕新时代拥抱云原生,云原生具有环境统一、按需付费、即开即用、稳定性强特点。Myblog:http://nsddd.top
[TOC]
命名空间是 Linux 内核的一项功能,它对内核资源进行分区,以便一组进程看到一组资源,而另一组进程看到另一组资源。该功能通过为一组资源和进程使用相同的命名空间来工作,但这些命名空间引用不同的资源。资源可能存在于多个空间中。此类资源的示例有进程 ID、主机名、用户 ID、文件名、一些与网络访问相关的名称以及进程间通信。
在后面的 docker 、Kubernetes 中,命名空间是 Linux 中容器的一个基本方面。
术语“命名空间”通常用于命名空间的类型(例如进程 ID)以及特定的名称空间。
Linux 系统从每种类型的单个名称空间开始,供所有进程使用。进程可以创建额外的命名空间,也可以加入不同的命名空间。
对于容器技术而言,它实现资源层面上的限制和隔离,依赖于 Linux 内核所提供的 cgroup 和 namespace 技术。
我们先对这两项技术的作用做个概括:
- cgroup 的主要作用:管理资源的分配、限制;
- namespace 的主要作用:封装抽象,限制,隔离,使命名空间内的进程看起来拥有他们自己的全局资源;
从内核5.6版本开始,有8种命名空间。所有类型的命名空间功能都是相同的:每个进程都与一个命名空间相关联,并且只能查看或使用与该命名空间关联的资源,以及适用的后代命名空间。这样每个进程(或其进程组)都可以对资源有独特的看法。隔离哪个资源取决于为给定进程组创建的命名空间类型。
| namespace名称 | 使用的标识 - Flag | 控制内容 |
|---|---|---|
| Cgroup | CLONE_NEWCGROUP | Cgroup root directory cgroup 根目录 |
| IPC | CLONE_NEWIPC | System V IPC, POSIX message queues信号量,消息队列 |
| Network | CLONE_NEWNET | Network devices, stacks, ports, etc.网络设备,协议栈,端口等等 |
| Mount | CLONE_NEWNS | Mount points挂载点 |
| PID | CLONE_NEWPID | Process IDs进程号 |
| Time | CLONE_NEWTIME | 时钟 |
| User | CLONE_NEWUSER | 用户和组 ID |
| UTS | CLONE_NEWUTS | 系统主机名和 NIS(Network Information Service) 主机名(有时称为域名) |
挂载命名空间控制挂载点。创建时,当前挂载命名空间的挂载被复制到新的命名空间,但之后创建的挂载点不会在命名空间之间传播(使用共享子树,可以在命名空间 [4] 之间传播挂载点)。
用于创建此类新名称空间的克隆标志是 CLONE_NEWNS - “NEW NameSpace”的缩写。这个术语不是描述性的(它没有说明要创建哪种命名空间),因为挂载命名空间是第一种命名空间,设计者没有预料到还有其他命名空间。
PID 命名空间为进程提供一组独立于其他命名空间的进程 ID (PID)。 PID 命名空间是嵌套的,这意味着当创建一个新进程时,它将为从当前命名空间到初始 PID 命名空间的每个命名空间都有一个 PID。因此,初始 PID 命名空间能够看到所有进程,尽管 PID 与其他命名空间将看到的进程不同。
就跟你 fork 后,你的父进程和子进程之间的关系。
在 PID 命名空间中创建的第一个进程被分配了进程 ID 号 1,并获得与普通 init 进程相同的大部分特殊待遇,最值得注意的是 命名空间中的孤立进程附加到它。这也意味着终止此 PID 1 进程将立即终止其 PID 命名空间中的所有进程和任何后代。
这样我们便是可以理解了为什么 docker 中容器 单一原则 吧。
网络命名空间虚拟化了网络堆栈。创建时,网络名称空间仅包含一个环回接口。
网络的环回接口(Loopback Interface)是一种特殊的网络接口,用于将网络通信数据包发送回到发送方,而不是通过实际的物理网络接口发送出去。
环回接口通常用于本地主机的自我测试,以确保网络协议栈和应用程序是否正常工作。环回接口的IP地址通常为127.0.0.1,也称为本地回环地址。当应用程序尝试连接本地主机上的服务时,可以使用本地回环地址来测试该服务是否正在运行。
环回接口还可用于模拟远程主机,使应用程序能够以与与远程主机通信相同的方式进行测试,而无需实际连接到远程主机。
需要注意的是,由于环回接口并不涉及实际的网络传输,因此它不适用于测试与网络传输相关的问题,例如延迟和吞吐量。
# 测试 SMTP 服务 telnet 127.0.0.1 25
每个网络接口(物理或虚拟)只存在于 1 个命名空间中,并且可以在命名空间之间移动。
每个网络接口只能存在于一个命名空间中,但可以在命名空间之间移动。这意味着,一个网络接口可以从一个命名空间中移动到另一个命名空间中,从而使不同的命名空间共享同一网络接口。这种方式可以实现网络接口资源的共享和重用,提高系统的资源利用率。
例如,在容器技术中,每个容器都可以拥有自己的网络命名空间,而容器之间共享宿主机的物理网络接口。当一个新容器创建时,可以通过将一个现有的网络接口移动到新的命名空间中,从而在新的命名空间中创建一个新的虚拟网络接口。这使得容器可以拥有独立的IP地址和网络协议栈,而不会与其他容器发生冲突。同时,它们也可以与宿主机和其他容器进行通信,实现网络互连。
每个名称空间都有一组私有 IP 地址、自己的路由表、套接字列表、连接跟踪表、防火墙和其他与网络相关的资源。
销毁网络名称空间会销毁其中的任何虚拟接口,并将其中的任何物理接口移回初始网络名称空间。
IPC 命名空间将进程与 SysV 风格的进程间通信隔离开来。这可以防止不同 IPC 命名空间中的进程使用 SHM 函数族等在两个进程之间建立共享内存范围。相反,每个进程将能够为共享内存区域使用相同的标识符,并生成两个这样的不同区域。
UTS(UNIX 分时)命名空间允许单个系统对不同的进程显示为具有不同的主机名和域名。 “当一个进程创建一个新的 UTS 命名空间时......新 UTS 命名空间的主机名和域是从调用者的 UTS 命名空间中的相应值复制的。”
用户命名空间是一项功能,可在自内核 3.8 起可用的多组进程之间提供权限隔离和用户身份隔离。 在管理协助下,可以构建一个看似具有管理权限的容器,而无需实际为用户进程提供更高的权限。与 PID 命名空间一样,用户命名空间是嵌套的,每个新的用户命名空间都被视为创建它的用户命名空间的子级。
用户命名空间包含一个映射表,将用户 ID 从容器的角度转换为系统的角度。例如,这允许 root 用户在容器中拥有用户 ID 0,但实际上被系统视为用户 ID 1,400,000 以进行所有权检查。一个类似的表用于组 ID 映射和所有权检查。
为了促进管理操作的特权隔离,每个命名空间类型在创建时都被认为属于基于活动用户命名空间的用户命名空间。在适当的用户命名空间中具有管理权限的用户将被允许在该其他命名空间类型中执行管理操作。例如,如果一个进程具有更改网络接口 IP 地址的管理权限,只要它自己的用户命名空间与拥有网络命名空间的用户命名空间相同(或祖先),它就可以这样做。因此,初始用户命名空间对系统中的所有命名空间类型具有管理控制权。
cgroup 命名空间类型隐藏了进程所属的控制组的身份。这样一个名称空间中的进程,检查任何进程属于哪个控制组,会看到一条实际上相对于创建时设置的控制组的路径,隐藏其真正的控制组位置和身份。这种命名空间类型自 2016 年 3 月起就存在于 Linux 4.6 中。 、
CGroup 在 容器中影响是很大的Z~
Cgroup namespace 是进程的 cgroups 的虚拟化视图,通过 /proc/[pid]/cgroup 和 /proc/[pid]/mountinfo 展示。
使用 cgroup namespace 需要内核开启 CONFIG_CGROUPS 选项。可通过以下方式验证:
[root@VM-4-3-opencloudos ~]# grep CONFIG_CGROUPS /boot/config-$(uname -r)
CONFIG_CGROUPS=ycgroup namespace 提供的了一系列的隔离支持:
- 防止信息泄漏(容器不应该看到容器外的任何信息)。
- 简化了容器迁移。
- 限制容器进程资源,因为它会把 cgroup 文件系统进行挂载,使得容器进程无法获取上层的访问权限。
每个 cgroup namespace 都有自己的一组 cgroup 根目录。这些 cgroup 的根目录是在 /proc/[pid]/cgroup 文件中对应记录的相对位置的基点。当一个进程用 CLONE_NEWCGROUP(clone(2) 或者 unshare(2)) 创建一个新的 cgroup namespace时,它当前的 cgroups 的目录就变成了新 namespace 的 cgroup 根目录。
[root@VM-4-3-opencloudos ~] cat /proc/self/cgroup
0::/user.slice/user-1000.slice/session-2.scope当一个目标进程从 /proc/[pid]/cgroup 中读取 cgroup 关系时,每个记录的路径名会在第三字段中展示,会关联到正在读取的进程的相关 cgroup 分层结构的根目录。如果目标进程的 cgroup 目录位于正在读取的进程的 cgroup namespace 根目录之外时,那么,路径名称将会对每个 cgroup 层次中的上层节点显示 ../ 。
我们来看看下面的示例(这里以 cgroup v1 为例,如果你想看 v2 版本的示例,请在留言中告诉我):
- 在初始的 cgroup namespace 中,我们使用 root (或者有 root 权限的用户),在 freezer 层下创建一个子 cgroup 名为
moelove-sub,同时,将进程放入该 cgroup 进行限制。
[root@VM-4-3-opencloudos ~] mkdir -p /sys/fs/cgroup/freezer/moelove-sub
[root@VM-4-3-opencloudos ~] sleep 6666666 &
[1] 1489125
[root@VM-4-3-opencloudos ~] echo 1489125 > /sys/fs/cgroup/freezer/moelove-sub/cgroup.procs
- 我们在 freezer 层下创建另外一个子 cgroup,名为
moelove-sub2, 并且再放入执行进程号。可以看到当前的进程已经纳入到moelove-sub2的 cgroup 下管理了。
[root@VM-4-3-opencloudos ~] mkdir -p /sys/fs/cgroup/freezer/moelove-sub2
[root@VM-4-3-opencloudos ~] echo $$
1488899
[root@VM-4-3-opencloudos ~] echo 1488899 > /sys/fs/cgroup/freezer/moelove-sub2/cgroup.procs
[root@VM-4-3-opencloudos ~] cat /proc/self/cgroup |grep freezer
7:freezer:/moelove-sub2
- 我们使用
unshare(1)创建一个进程,这里使用了-C参数表示是新的 cgroup namespace, 使用了-m参数表示是新的 mount namespace。
[root@VM-4-3-opencloudos ~] unshare -Cm bash
root@moelove:~#
- 从用 unshare(1) 启动的新 shell 中,我们可以在
/proc/[pid]/cgroup文件中看到,新 shell 和以上示例中的进程:
root@moelove:~# cat /proc/self/cgroup | grep freezer
7:freezer:/
root@moelove:~# cat /proc/1/cgroup | grep freezer
7:freezer:/..
# 第一个示例进程
root@moelove:~# cat /proc/1489125/cgroup | grep freezer
7:freezer:/../moelove-sub- 从上面的示例中,我们可以看到新 shell 的 freezer cgroup 关系中,当新的 cgroup namespace 创建时,freezer cgroup 的根目录与它的关系也就建立了。
root@moelove:~# cat /proc/self/mountinfo | grep freezer
1238 1230 0:37 /.. /sys/fs/cgroup/freezer rw,nosuid,nodev,noexec,relatime - cgroup cgroup rw,freezer
- 第四个字段 (
/..) 显示了在 cgroup 文件系统中的挂载目录。从 cgroup namespaces 的定义中,我们可以知道,进程当前的 freezer cgroup 目录变成了它的根目录,所以这个字段显示/..。我们可以重新挂载来处理它。
root@moelove:~# mount --make-rslave /
root@moelove:~# umount /sys/fs/cgroup/freezer
root@moelove:~# mount -t cgroup -o freezer freezer /sys/fs/cgroup/freezer
root@moelove:~# cat /proc/self/mountinfo | grep freezer
1238 1230 0:37 / /sys/fs/cgroup/freezer rw,relatime - cgroup freezer rw,freezer
root@moelove:~# mount |grep freezer
freezer on /sys/fs/cgroup/freezer type cgroup (rw,relatime,freezer)
时间命名空间允许进程以类似于 UTS 命名空间的方式查看不同的系统时间。 2018年提出,登陆Linux 5.6,2020年3月发布。
不过我们不做那么深究的讨论,简化问题,Linux 系统实际上没有实现相关的虚拟路由器设备,自然也没有工具可以操作路由器,因为 Linux 本身就是一台路由器。
Linux 提供一个开关来操作路由功能,就是 /proc/sys/net/ipv4/ip_forward,默认这个开关是关的,打开只需:
echo 1 > /proc/sys/net/ipv4/ip_forward但这种打开方式只是临时的,如果要一劳永逸,可以修改配置文件 /etc/sysctl.conf,添加或修改项 net.ipv4.ip_forward 为:
net.ipv4.ip_forward = 1为了降低大家实践的难度,我们就不创建虚拟机了,直接使用 namespace,一条 ip 命令就可以搞定所有的操作。
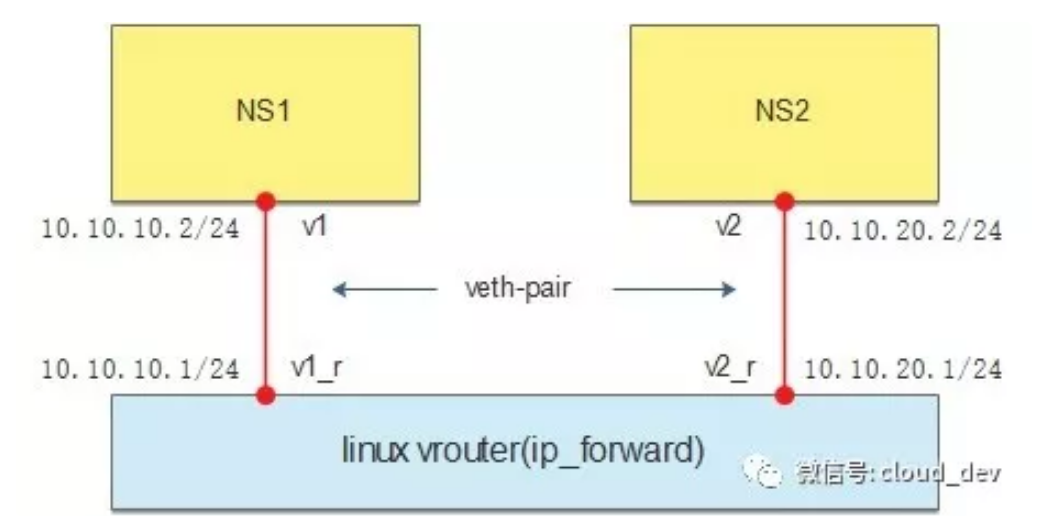
创建两个 namespace:
ip netns add ns1
ip netns add ns2创建两对 veth-pair,一端分别挂在两个 namespace 中:
ip link add v1 type veth peer name v1_r
ip link add v2 type veth peer name v2_r
ip link set v1 netns ns1
ip link set v2 netns ns2veth-pair 是一种 Linux 内核中的虚拟网络设备,它是由一对虚拟网络接口组成的,一个是 veth0,另一个是 veth1。这两个接口之间通过虚拟线缆连接在一起,形成了一条虚拟网络链路。
veth-pair 通常被用于创建一个虚拟的网络命名空间,并将 veth-pair 的一个端口连接到该命名空间中。这样就可以在该命名空间内创建自己独立的网络环境,包括 IP 地址、路由表、防火墙规则等等。另一个端口则可以连接到宿主机的网络中,或者连接到其他网络设备上,实现数据传输和网络通信。
veth-pair 有很多用途:
- 可以用于容器化技术中,将容器与宿主机隔离,创建容器的网络环境;
- 也可以用于 VPN 网络中,通过创建多个 veth-pair 连接到不同的虚拟网络命名空间,实现网络隔离和安全通信。
- veth-pair 还可以用于测试和模拟网络环境,方便开发人员进行网络调试和性能测试。
分别给两对 veth-pair 端点配上 IP 并启用:
ip a a 10.10.10.1/24 dev v1_r
ip l s v1_r up
ip a a 10.10.20.1/24 dev v2_r
ip l s v2_r up
ip netns exec ns1 ip a a 10.10.10.2/24 dev v1
ip netns exec ns1 ip l s v1 up
ip netns exec ns2 ip a a 10.10.20.2/24 dev v2
ip netns exec ns2 ip l s v2 up在一个命名空间中,使用 ping 命令测试另一个命名空间中的 IP 地址:
验证一下: v1 ping v2,结果不通。
[root@VM-4-3-opencloudos ~]# ip netns exec ns1 ping 10.10.20.2
PING 10.10.20.2 (10.10.20.2) 56(84) bytes of data.看下 ip_forward 的值:
[root@VM-4-3-opencloudos ~]# cat /proc/sys/net/ipv4/ip_forward
0**设置为 :1 ** 还是不通。
看下 ns1 的路由表:
[root@VM-4-3-opencloudos ~]# ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 v1只有一条直连路由,没有去往 10.10.20.0/24 网段的路由,怎么通?那就给它配一条:
[root@VM-4-3-opencloudos ~]# ip netns exec ns1 route add -net 10.10.20.0 netmask 255.255.255.0 gw 10.10.10.1
[root@VM-4-3-opencloudos ~]# ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 v1
10.10.20.0 10.10.10.1 255.255.255.0 UG 0 0 0 v1同理也给 ns2 配上去往 10.10.10.0/24 网段的路由。
[root@VM-4-3-opencloudos ~]# ip netns exec ns2 route add -net 10.10.10.0 netmask 255.255.255.0 gw 10.10.20.1最后再 ping,成功了!
[root@VM-4-3-opencloudos ~]# ip netns exec ns1 ping 10.10.20.2
PING 10.10.20.2 (10.10.20.2) 56(84) bytes of data.
64 bytes from 10.10.20.2: icmp_seq=1 ttl=63 time=0.036 ms
64 bytes from 10.10.20.2: icmp_seq=2 ttl=63 time=0.040 ms
64 bytes from 10.10.20.2: icmp_seq=3 ttl=63 time=0.043 ms
64 bytes from 10.10.20.2: icmp_seq=4 ttl=63 time=0.052 ms
64 bytes from 10.10.20.2: icmp_seq=5 ttl=63 time=0.042 ms
^C
--- 10.10.20.2 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4129ms
rtt min/avg/max/mdev = 0.036/0.042/0.052/0.008 ms虚拟机地址192.168.232.133,网关为 192.168.232.10;主机地址为10.100.59.167,网关为 10.100.0.1;设置路由,实现通信
虚拟机:
需要将默认网关设置为192.168.232.10。这将允许虚拟机访问在该网关下的网络。然后,您需要在192.168.232.10网关上设置一条路由,以指向10.100.59.167的网络。
具体来说,在192.168.232.10网关上设置以下路由:
目标网络:10.100.59.0/24 下一跳:192.168.232.133
这将告诉192.168.232.10网关将目标网络10.100.59.0/24的所有数据包发送到虚拟机的地址192.168.232.133。这样,当您在虚拟机上发送到10.100.59.0/24网络的数据包时,它们将通过默认网关192.168.232.10发送到10.100.59.0/24网络。
sudo ip route add 10.100.0.0/16 via 192.168.232.10主机:
在主机上,需要将默认网关设置为10.100.0.1。然后,您需要在10.100.0.1网关上设置以下路由:
目标网络:192.168.232.0/24 下一跳:10.100.59.167
这将告诉10.100.0.1网关将目标网络192.168.232.0/24的所有数据包发送到主机的地址10.100.59.167。这样,当您在主机上发送到192.168.232.0/24网络的数据包时,它们将通过默认网关10.100.0.1发送到192.168.232.0/24网络。
route add 192.168.232.0 mask 255.255.255.0 10.100.59.167-
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©