- Split the training data into ratio 7:3 (train:test) and Evaluate them with P/R/F1 metrics
- Use entire training data to train the model and Test with the test data and then Submit the prediciton as the same format as the training data
data format is utf-16 little endian
This is a Traditional Chinese corpus.
- Max sentence (sequence) length: 165 (training data max: 164)
- Total unique word (include PAD): 4744
- Training data size
- examples (sentences): 66713 (70% training data)
- examples (sentences): 95304 (100% training data)
- words (max sentence length): 165
- features (one-hot encode, i.e. total unique word): 4744
- tags (cws tags): 4
- Max sentence (sequence) length: 374 (training data max > test data max)
- Total unique word (include PAD): 4379
- Training data size
- examples (sentences): 25434 (70% training data)
- examples (sentences): 36334 (100% training data)
- words (max sentence length): 374
- features (one-hot encode, i.e. total unique word): 4379
- tags (ner tags): 7 (PER x 2 + LOC x 2 + ORG x 2 + N)
| Category | Tag |
|---|---|
| PER | Person |
| LOC | Location |
| ORG | Organization |
The NER starts with B-[Tag], if it is multiple words than will follow by I-[Tag].
If the word is not NER than use the N tag.
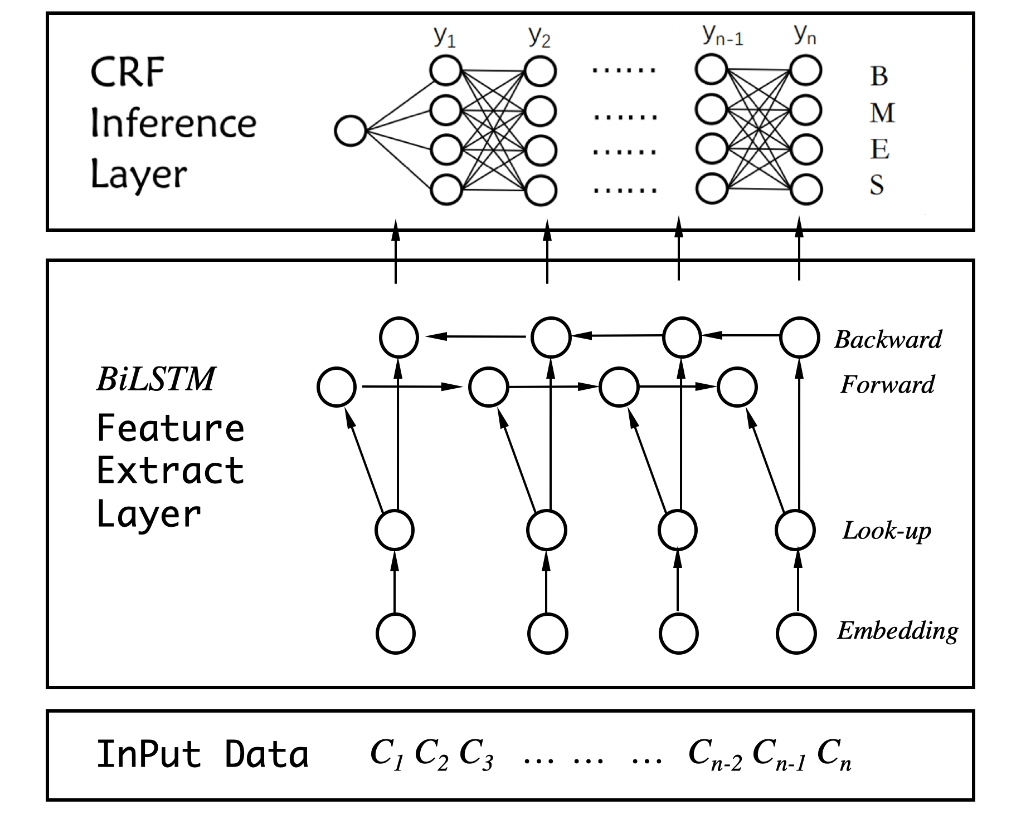
- Method/Approach
- Experiment Settings and Steps
- The 30% test data evaluation result
- Question analysis and discussion
Submission should be named as
Name-ID.segandName-ID.ner
Train and Predict
python3 cws_crf.pypython3 ner_crf.py
- Performance per label type per token
- Performance over full named-entity

- tf.contrib.layers.xavier_initializer
- tf.nn.xw_plus_b: Computes matmul(x, weights) + biases.
- macanv/BERT-BiLSTM-CRF-NER: BERT + BiLSTM + CRF
- scofield7419/sequence-labeling-BiLSTM-CRF: BiLSTM + CRF
Not same task but similar model
- nyu-mll/multiNLI - Baseline Models for MultiNLI Corpus
--
- Python - read text file with weird utf-16 format
- How to split/partition a dataset into training and test datasets for, e.g., cross validation?
Python Logging
- Graphs and Sessions
- Save and Restore
- global_step
- Variables
- Sharing Variable
- What happens when setting reuse=True in tensorflow
- reuse and variable scopes in general are deprecated and will be removed in tf2
- instead recommend you use the tf.keras layers to build your model, which you can reuse by just reusing the objects
- tf.variable_scope
- What happens when setting reuse=True in tensorflow
- Is Training
- Sharing Variable
When I try to use them, it will swallow up more than 50G
- Numpy
- np.eye
np.eye(num_features, dtype=np.uint8)[numpy_dataset]
- np.eye + np.reshape
np.squeeze(np.eye(num_features, dtype=np.uint8)[numpy_dataset.reshape(-1)]).reshape([num_examples, num_words, num_features])
- np.eye
- Scipy.sparse: currently don't support 3-dim matrix (scipy issue - 3D sparse matrices #8868)
- list + scipy.sparse.eye => np.array
sparse.eye(num_features, dtype=np.uint8).tolil()[numpy_dataset.reshape(-1)].toarray().reshape((num_examples, num_words, num_features))(don't work)
- list + scipy.sparse.eye -> tf.sparse.SparseTensor: this need to modify the network structure (X)
- list + scipy.sparse.eye => np.array
- Keras
- keras.utils.to_categorical (tf.keras.utils.to_categorical)
to_categorical(numpy_dataset, num_classes=num_features)
- keras.utils.to_categorical (tf.keras.utils.to_categorical)
- Pandas: don't seem will support 3-dim either
- TensorFlow: this will need to modify network structure which will limit the generalization
- Scikit Learn
- sklearn.preprocessing.OneHotEncoder: this will need to input the "original word: encode" pair, which is not what I want
- sklearn.preprocessing.LabelBinarizer: can't transform 3-dim data
- lazyarray
- Numpy
- np.argmax