Three aspect:
- What is the target?
- The representation?
- Data
- Target function
- Algorithms (i.e. ML Method)
Three Spaces
- Input Space/Feature Space: space used to describe each instance
- Continuous (e.g. Word embedding)
- Discrete (e.g. Feature engineering)
- Binary
- Output Space: space of possible output values; very dependent on problem
- Continuous vs. Discrete
- Binary vs. Multivalued (in Discrete)
- Hypothesis Space: space of functions that can be selected by the machine learning algorithm (it's the set of all functions h that satisfy the goal)
Three Problems
- Accordance Assumption: m examples chosen i.i.d. according to an unknown real world distribution
- Modeling: For a hypotheses, estimate the parameters based on training data and minimize loss
- Generalization: Accuracy on real data (training & test set)
Goal of ML
- Find a function h belonging to hypothesis space H, such that the expected error on new examples is minimal.
- Find a function h:
$Y = H(X)$ , where$D = {(X, y) | x \in X, y \in Y}$
Types of ML Problem
- Y = empty set: unsupervised learning
- Y is a set of integer: classification
- If |Y|=2, h is called a concept: concept learning
- Y is a set of real number: regression
- Y are not given for some Ds: semi-supervised learning
- Y is order set: learning for ranking
- ...
Learning Frame
- Describing data with feature (Input Space): Manually designing input feature
- Learning algorihtm (Hypothesis Space): Optimizing the weights on features
Reasons of ML methods fail
- Wrong Bias: best hypothesis is not in H
- Search Failure: best model is in H but search fails to examine it
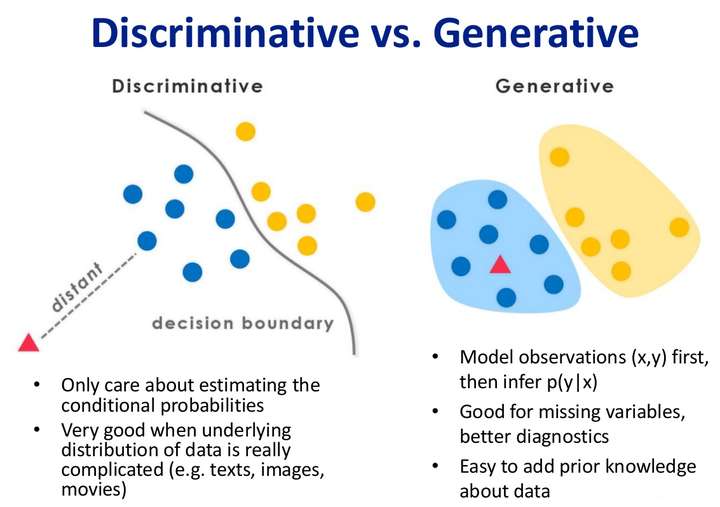
- Discriminative Model
- Discriminative Function 判別式 (決策函數) [非機率模型]: predict class/label
- SVM
- Perceptron (Traditional Neural Network)
- Logistic Regression
- K-Nearest Neighbor
- Probabilistic Discriminative Model 機率條件 [機率模型]: predict probability
- Maximum Entropy Model (MEM)
- Conditional Random Field (CRF)
- Discriminative Function 判別式 (決策函數) [非機率模型]: predict class/label
- Generative Model
- Naive Bayes Model
- Hidden Markov Model (HMM)
- (Bayesian Networks, Markov Random Fields)
Links
- Medium - Generative VS Discriminative Models
- Wiki - Generative model
- Explain to Me: Generative Classifiers VS Discriminative Classifiers
- Discriminative Modeling vs Generative Modeling
- 知乎 - 機器學習「判定模型」和「生成模型」有什麼區別?
- 機器學習之判別式模型和生成式模型
判別式模型舉例:要確定一個羊是山羊還是綿羊,用判別模型的方法是從歷史數據中學習到模型,然後通過提取這只羊的特徵來預測出這只羊是山羊的概率,是綿羊的概率。 生成式模型舉例:利用生成模型是根據山羊的特徵首先學習出一個山羊的模型,然後根據綿羊的特徵學習出一個綿羊的模型,然後從這只羊中提取特徵,放到山羊模型中看概率是多少,在放到綿羊模型中看概率是多少,哪個大就是哪個。 判別式模型是根據一隻羊的特徵可以直接給出這只羊的概率(比如logistic regression,這概率大於0.5時則為正例,否則為反例),而生成式模型是要都試一試,最大的概率的那個就是最後結果Slides
Book
統計學習方法 Ch1.3.1 模型
- Discribe Conditional Distribution
- From Data to Category
- Represent in Discriminative Function 決策函數(判別式)
- Represent in Conditional Probability 條件機率
- Describe Joint Distribution
- From Category to Data
Standard classification problem assumes indifvidual cases are disconnected and independent (i.i.d: independently and identically distributed)
We're going to minimize the empirical classification error
- Decision Trees
- Function space is Boolean formula in Disjunctive Normal Form (DNF)
- Probability Model
- Function space is dependent on the distribution assumptions of the model
- Discriminant Functions
- Partition the D dimensional spae with a (D-1) dimensional function
- Function space is dependent on the function used to discriminate
- Linear Discriminates
- Partition the D dimensional space with a (D-1) dimensional linear function
- Learning Problem
- Optimization Problem
- Is the test set required for the unsupervised learning?
- In a way, no - as there is no ground truth. But often, unsupervised learning is followed by or associated with supervised learning.
- Word2Vec followed by classification/regression - Text Prediction
- PCA on TFIDF vectors followed by classification/regression -Text Prediction
- Clustering on labeled data - if you want to tune the clustering to get the least error
- Topic Modeling - you use LDA or LSA to get topic models and use the “elbow” to find the optimum number of topics - but now you would like to see if this would generalize well - and then you need a test set.
Intra-cluster distances are minimized; Iner-cluster distances are maximized.
- Hard clustering => more in practical
- Partition D into k subsets strictly
- Soft clustering
- Partitional clustering 劃分式的聚類
- Hierarchical clustering 層次式的聚類
- Dendrogram
- Hierarchical clustering
- Aglommerative clustering (bottom-up)
- Divisive clustering (partitional, top-down)
- Graph based clustering
- K-means
Aglommerative Clustering:
- Compute the proximity matrix
- Let each data point be a cluster
- Repeat until only a single cluster remains
- Merge the two closest clusters
- Update the proximity matrix (re-calculate distance) => Different method -> different algorithm
- Calculate cluster similarity
- Single link => result in thin and long
- Max-similarity: Use minimum distance of pairs
- Complete link => result in ball shape
- Max-distance: Use minimum similarity of pairs
- Group average => globular cluster
- Distance between centroids
- Single link => result in thin and long
- Calculate cluster similarity
- Time complexity O(N³) -> can be reduce to O(N²log(N))
- Pruning: Similarity compare to a threshold
- Don't need to give how many clusters K beforehand
Graph Based Clustering:
consider with the similarity
TBD
General Graph Method (Algorithm):
- Construct the Maximum Spanning Tree (MST) of the similarity or the Mimimum Spanning Tree of the distance
TBD
inconsistent edges:
- Use a threshold (delete the light edges)
- Delete an edge if its weitht is significantly lower than that of nearby edges
Cutting Method
- Minimum Cut
- Drawbacks of Miminum Cut
- Ratio Cut (NP hard)
- Normalized Cut (NP hard)
- MaxMin Cut (NP hard)
Spectral Graph Theorty 譜圖理論
Adjacency Matrix: similarity between notes
TBD (important)
Combines labeled and unlabeled data during training to improve performance.
- Semi-supervised classification: Training on labeled data exploits additional unlabeled data, frequently resulting in a more accurate classifier
- => In order to get a classifier
- Semi-supervised clustering: Uses small amount of labeled data to aid and bias the clustering of unbalanced data
- => Guide the clustering process using some labeled data to get better clustering result
Why using unlabeled data:
- Labeling is expensive!
- Unlabeled data are usually plentiful
- Domain adaptation: want a model for different domain (e.g. Knowledge Graph)
The initial points of original K-Means are random chosen
Seeded K-Means:
Seed points are only used for initialization
Constrained K-Means:
Cluster labels of seed data are kept unchanged
The constrain is not about the labeled data. But some pairwise relationships.
Pairwise Constrain: must-link (must be in same cluster) and cannot-link constraints on data points
Create a graph where the nodes (vertices) are all the data points, labeled or unlabeled.
Propagate the labels through the edges. The weight of edge can be considered either similarity or distance.
Typical Example:
- Web page classification
- Document classification
- Protein classification
- Self-training vs. Co-training
- Data split into labeled set and unlabeled set.
- Predict unlabeled set and join some of them to labeled set. Labeled set ↑ ; Unlabeled set ↓
- Self-training use only one classifier; Co-trianing use two (or more) classifiers.
TBD
We can train multiple classifiers based on disjoint (redundant) features.
The clssifiers should agree on the classification for each unlabeled example
TBD
Incorporating unlabeled Data with EM
- Train a classifier with only the labeled documents.
- Use it to probailistically classify the unlabeled documents.
- Use ALL the documents to train a new classifier.
- Iterate steps 2 and 3 to convergence.
直推式學習 vs. Inductive Learning
Learning from labeled data and test data (boostrapping) and cannot handle unseen data.
(The test data is unlabeled data, but we use it as a part of training data.)
遠程監督