paper
TeraFLOPs TeraParams 설명은 건너뛴다.
TRT-ViT
4개의 rule 을 실험적으로 찾아내며, 아키텍처를 고름
- transformer block 은 마지막 stage 에 위치하는 게 가성비가 좋다 (널리 알려진 사실)
- 앞쪽 stage 는 얕아도 된다.

- transformer block 보다는, transformer + bottleneck 을 혼합시킨게 더 가성비가 좋다
- global 을 먼저 보고 local 을 보는게 더 효과적이더라

이게 끝이다 ㅋㅋ
아래 표에서 볼 수 있듯이 (C) block이 효과적이었다.

detail 한 아키텍처는 다음과 같다

Results
ImageNet
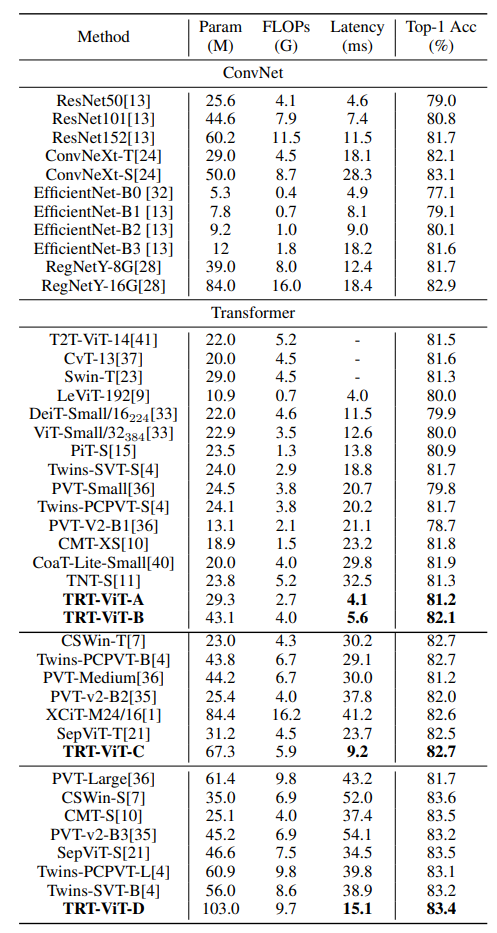
Setttings
Ablations

ADE 20K

COCO

paper
TeraFLOPs TeraParams 설명은 건너뛴다.
TRT-ViT
4개의 rule 을 실험적으로 찾아내며, 아키텍처를 고름
이게 끝이다 ㅋㅋ
아래 표에서 볼 수 있듯이 (C) block이 효과적이었다.

detail 한 아키텍처는 다음과 같다

Results
ImageNet
Setttings
rand-m9-mstd0.5-inc1Ablations
ADE 20K
COCO