diff --git a/Linear_Regression/Documentation.md b/Linear_Regression/Documentation.md
new file mode 100644
index 0000000..c333d0f
--- /dev/null
+++ b/Linear_Regression/Documentation.md
@@ -0,0 +1,77 @@
+# **Linear Regression**
+Linear regression is a *supervised* machine learning model which tries to best fit the linear expression on the training dataset to best predict for the future x input values.
+
+
+
+ +
+
+
+## Hypothesis
+
+
+
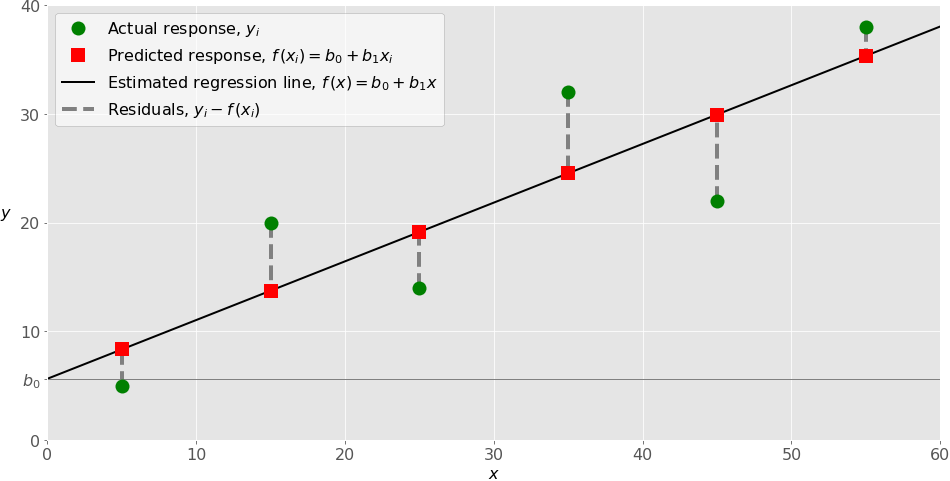
+In the above image the slope is called the *hypothesis*
+and the y-intercept is called the *bias*. Linear regression model tries to optimize the slope by using the cost function.
+
+hypothesis function is given by :-
+
+
+
+
+
+## Hypothesis
+
+
+
+In the above image the slope is called the *hypothesis*
+and the y-intercept is called the *bias*. Linear regression model tries to optimize the slope by using the cost function.
+
+hypothesis function is given by :-
+
+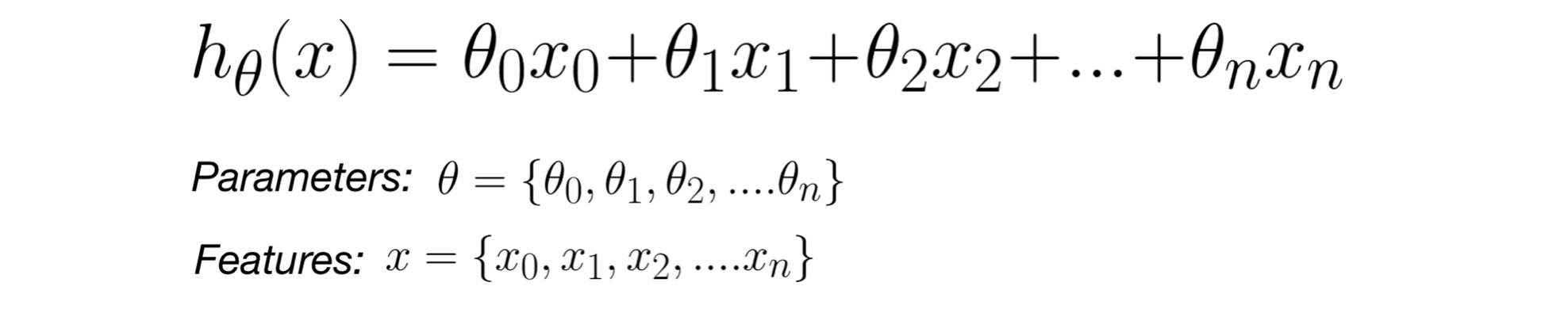 +
+
+
+here, parameters (theta) are the weights of the respective features(x).
+
+
+
+## Cost Function
+This function gives the loss of data against the predicted values. The cost function of regression model is given by :-
+
+
+
+
+
+
+
+here, parameters (theta) are the weights of the respective features(x).
+
+
+
+## Cost Function
+This function gives the loss of data against the predicted values. The cost function of regression model is given by :-
+
+
+
+ +
+
+
+## Gradient Descent
+
+
+
+
+
+
+
+## Gradient Descent
+
+
+
+ +
+
+
+The weights and bias are optimized by using *Gradient descent* which attempts to find a global/local minima of the cost function plotted against the weights.
+
+
+
+
+
+
+
+The weights and bias are optimized by using *Gradient descent* which attempts to find a global/local minima of the cost function plotted against the weights.
+
+
+
+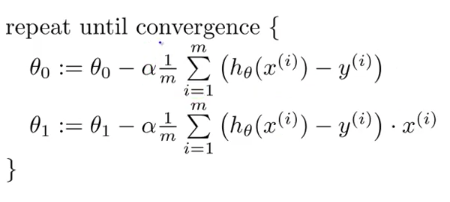 +
+
+
+* Here, alpha is the learning rate which determines the size of steps taken to reach the required minima. If its value is too large, the counter will bounce back and forth and will never reach the minima. Also if its value is too low then the will surely reach the minima but will a lot of time. So, there is a sweet spot in between in which the learning rate must reside to make optimum calculations.
+
+
+
+
+
+
+
+* Here, alpha is the learning rate which determines the size of steps taken to reach the required minima. If its value is too large, the counter will bounce back and forth and will never reach the minima. Also if its value is too low then the will surely reach the minima but will a lot of time. So, there is a sweet spot in between in which the learning rate must reside to make optimum calculations.
+
+
+
+ +
+
+
+* After alpha is the derivative of cost function with respect to feature(x) weights for theta_1 and derivative of cost function with respect to bias for theta_0.
+
+
+
+## Implementation
+___
+
+Linear Regression code consists of three main following functions:
+* Fit
+* Predict
+* Score
+### Fit Function
+Fit function is used to train our regression model and return the weights and bias.Weights ang bias are first initialised as zero and then passes through the *gradient descent* funtion multiple times to optimize the weights and bias.
+
+### Predict & Score Function
+Predict Function - This function returns the predicted y value based on the trained model.
+
+Score Function - This function evaluates the model and return a value between 0-1. Higher the score, more accurate will be the predictions made by the regression model.
diff --git a/Linear_Regression/Linear_Regression.ipynb b/Linear_Regression/Linear_Regression.ipynb
new file mode 100644
index 0000000..bed1dc2
--- /dev/null
+++ b/Linear_Regression/Linear_Regression.ipynb
@@ -0,0 +1,295 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": 62,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#import libraries\n",
+ "import numpy as np\n",
+ "from sklearn.datasets import make_regression\n",
+ "from sklearn.model_selection import train_test_split"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 63,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Generate Dummy data to test linear regression\n",
+ "\n",
+ "x,y=make_regression(n_samples=100,n_features=1,noise=20,random_state=4)\n",
+ "x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 64,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#Cost function\n",
+ "\n",
+ "def cost(x_train,y_train,weights,bias):\n",
+ " n_data,n_features=x_train.shape\n",
+ " cost=0\n",
+ " for i in range(n_data):\n",
+ " y_predict=np.dot(x_train[i].T,weights)+bias\n",
+ " cost+=((y_train[i]-y_predict)**2)/n_data\n",
+ " return cost "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 65,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Gradient Descent Function\n",
+ "\n",
+ "def gradientdescent(x_train,y_train,lr,weights,bias):\n",
+ " n_data,n_features=x_train.shape\n",
+ " weight_update=weights\n",
+ " bias_update=bias\n",
+ " \n",
+ " y_predict=np.dot(x_train,weights)+bias\n",
+ " dw=(-2/n_data)*np.dot(x_train.T,(y_train-y_predict))\n",
+ " db=(-2/n_data)*np.sum(y_train-y_predict)\n",
+ " weights_new=weights-lr*dw\n",
+ " bias_new=bias-lr*db\n",
+ "\n",
+ " return weights_new,bias_new"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 66,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Fit function\n",
+ "\n",
+ "def fit(x_train,y_train,lr,itr):\n",
+ " n_data,n_feature=x_train.shape\n",
+ " weights=np.zeros(n_feature)\n",
+ " bias=0\n",
+ " for i in range(itr):\n",
+ " weights,bias=gradientdescent(x_train,y_train,lr,weights,bias)\n",
+ " print(\"cost=\",cost(x_train,y_train,weights,bias))\n",
+ " return weights,bias"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 67,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def predict(x_test,weights,bias):\n",
+ " return np.dot(x_test,weights)+bias"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 68,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Score function to evalute the model\n",
+ "\n",
+ "def score(y_predict,y_true):\n",
+ " y_mean=np.mean(y_true)\n",
+ " return 1-((np.sum((y_true-y_predict)**2))/(np.sum((y_predict-y_mean)**2)))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 69,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "cost= 3808.943336170967\n",
+ "cost= 2568.684841123737\n",
+ "cost= 1768.8730253255492\n",
+ "cost= 1252.5190147981036\n",
+ "cost= 918.7948464487748\n",
+ "cost= 702.8696417592345\n",
+ "cost= 563.011155383819\n",
+ "cost= 472.32574846503945\n",
+ "cost= 413.4628686393532\n",
+ "cost= 375.21627800024777\n",
+ "cost= 350.3401989636246\n",
+ "cost= 334.14451524575384\n",
+ "cost= 323.5900950595011\n",
+ "cost= 316.7055340355867\n",
+ "cost= 312.2107016558603\n",
+ "cost= 309.27349614462946\n",
+ "cost= 307.35249924893975\n",
+ "cost= 306.0950856262999\n",
+ "cost= 305.2713718332876\n",
+ "cost= 304.73135337494017\n",
+ "cost= 304.37706056987787\n",
+ "cost= 304.14445242650265\n",
+ "cost= 303.991631152567\n",
+ "cost= 303.8911634153005\n",
+ "cost= 303.8250726041834\n",
+ "cost= 303.78157001041296\n",
+ "cost= 303.7529191926282\n",
+ "cost= 303.7340394898385\n",
+ "cost= 303.7215920998955\n",
+ "cost= 303.7133814882096\n",
+ "cost= 303.7079630240789\n",
+ "cost= 303.70438560265086\n",
+ "cost= 303.70202269194226\n",
+ "cost= 303.7004613490979\n",
+ "cost= 303.6994292679998\n",
+ "cost= 303.6987467955278\n",
+ "cost= 303.6982953516441\n",
+ "cost= 303.69799663347084\n",
+ "cost= 303.6977989132761\n",
+ "cost= 303.69766800576815\n",
+ "cost= 303.69758131053914\n",
+ "cost= 303.69752388087574\n",
+ "cost= 303.69748582853174\n",
+ "cost= 303.69746060972153\n",
+ "cost= 303.6974438926552\n",
+ "cost= 303.6974328090151\n",
+ "cost= 303.6974254590294\n",
+ "cost= 303.69742058411015\n",
+ "cost= 303.6974173502548\n",
+ "cost= 303.69741520468995\n",
+ "cost= 303.6974137809637\n",
+ "cost= 303.697412836095\n",
+ "cost= 303.69741220894406\n",
+ "cost= 303.6974117926251\n",
+ "cost= 303.69741151623043\n",
+ "cost= 303.69741133271214\n",
+ "cost= 303.69741121084877\n",
+ "cost= 303.6974111299194\n",
+ "cost= 303.697411076169\n",
+ "cost= 303.6974110404673\n",
+ "cost= 303.69741101675186\n",
+ "cost= 303.69741100099725\n",
+ "cost= 303.69741099053084\n",
+ "cost= 303.6974109835766\n",
+ "cost= 303.69741097895604\n",
+ "cost= 303.6974109758857\n",
+ "cost= 303.69741097384536\n",
+ "cost= 303.6974109724896\n",
+ "cost= 303.69741097158857\n",
+ "cost= 303.69741097098967\n",
+ "cost= 303.6974109705916\n",
+ "cost= 303.6974109703271\n",
+ "cost= 303.69741097015134\n",
+ "cost= 303.69741097003447\n",
+ "cost= 303.69741096995676\n",
+ "cost= 303.69741096990515\n",
+ "cost= 303.69741096987065\n",
+ "cost= 303.6974109698479\n",
+ "cost= 303.6974109698328\n",
+ "cost= 303.69741096982256\n",
+ "cost= 303.69741096981596\n",
+ "cost= 303.6974109698116\n",
+ "cost= 303.6974109698086\n",
+ "cost= 303.69741096980664\n",
+ "cost= 303.69741096980533\n",
+ "cost= 303.6974109698045\n",
+ "cost= 303.69741096980374\n",
+ "cost= 303.6974109698033\n",
+ "cost= 303.69741096980323\n",
+ "cost= 303.6974109698031\n",
+ "cost= 303.69741096980306\n",
+ "cost= 303.69741096980283\n",
+ "cost= 303.69741096980266\n",
+ "cost= 303.69741096980266\n",
+ "cost= 303.6974109698027\n",
+ "cost= 303.6974109698026\n",
+ "cost= 303.69741096980266\n",
+ "cost= 303.6974109698027\n",
+ "cost= 303.6974109698028\n",
+ "cost= 303.6974109698028\n"
+ ]
+ }
+ ],
+ "source": [
+ "weights,bias=fit(x_train,y_train,0.1,100)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 70,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "0.9468259773072768\n"
+ ]
+ }
+ ],
+ "source": [
+ "y_pred=predict(x_test,weights,bias)\n",
+ "print(score(y_pred,y_test))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 71,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "array([ 40.04975768, 61.95168262, 70.75259092, -137.45267539,\n",
+ " 24.39488421, 17.72229083, 114.86372767, 11.55805803,\n",
+ " 67.78412395, 24.39465238, -48.58469823, -20.92097096,\n",
+ " 31.69495894, -6.90322556, 59.38654823, 21.77986183,\n",
+ " -86.5061475 , -177.58814523, 15.23873962, -85.53663248,\n",
+ " -4.41360057, -42.42031553, 2.32555789, 37.62691579,\n",
+ " -108.75369459])"
+ ]
+ },
+ "execution_count": 71,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "y_pred"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3.9.12 ('base')",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.12"
+ },
+ "orig_nbformat": 4,
+ "vscode": {
+ "interpreter": {
+ "hash": "c19b36fe549fe2dce1ac32d0dd317d0a363043eb1c14a547f46436cb05190cdf"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
+
+
+
+* After alpha is the derivative of cost function with respect to feature(x) weights for theta_1 and derivative of cost function with respect to bias for theta_0.
+
+
+
+## Implementation
+___
+
+Linear Regression code consists of three main following functions:
+* Fit
+* Predict
+* Score
+### Fit Function
+Fit function is used to train our regression model and return the weights and bias.Weights ang bias are first initialised as zero and then passes through the *gradient descent* funtion multiple times to optimize the weights and bias.
+
+### Predict & Score Function
+Predict Function - This function returns the predicted y value based on the trained model.
+
+Score Function - This function evaluates the model and return a value between 0-1. Higher the score, more accurate will be the predictions made by the regression model.
diff --git a/Linear_Regression/Linear_Regression.ipynb b/Linear_Regression/Linear_Regression.ipynb
new file mode 100644
index 0000000..bed1dc2
--- /dev/null
+++ b/Linear_Regression/Linear_Regression.ipynb
@@ -0,0 +1,295 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": 62,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#import libraries\n",
+ "import numpy as np\n",
+ "from sklearn.datasets import make_regression\n",
+ "from sklearn.model_selection import train_test_split"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 63,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Generate Dummy data to test linear regression\n",
+ "\n",
+ "x,y=make_regression(n_samples=100,n_features=1,noise=20,random_state=4)\n",
+ "x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 64,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#Cost function\n",
+ "\n",
+ "def cost(x_train,y_train,weights,bias):\n",
+ " n_data,n_features=x_train.shape\n",
+ " cost=0\n",
+ " for i in range(n_data):\n",
+ " y_predict=np.dot(x_train[i].T,weights)+bias\n",
+ " cost+=((y_train[i]-y_predict)**2)/n_data\n",
+ " return cost "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 65,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Gradient Descent Function\n",
+ "\n",
+ "def gradientdescent(x_train,y_train,lr,weights,bias):\n",
+ " n_data,n_features=x_train.shape\n",
+ " weight_update=weights\n",
+ " bias_update=bias\n",
+ " \n",
+ " y_predict=np.dot(x_train,weights)+bias\n",
+ " dw=(-2/n_data)*np.dot(x_train.T,(y_train-y_predict))\n",
+ " db=(-2/n_data)*np.sum(y_train-y_predict)\n",
+ " weights_new=weights-lr*dw\n",
+ " bias_new=bias-lr*db\n",
+ "\n",
+ " return weights_new,bias_new"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 66,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Fit function\n",
+ "\n",
+ "def fit(x_train,y_train,lr,itr):\n",
+ " n_data,n_feature=x_train.shape\n",
+ " weights=np.zeros(n_feature)\n",
+ " bias=0\n",
+ " for i in range(itr):\n",
+ " weights,bias=gradientdescent(x_train,y_train,lr,weights,bias)\n",
+ " print(\"cost=\",cost(x_train,y_train,weights,bias))\n",
+ " return weights,bias"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 67,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def predict(x_test,weights,bias):\n",
+ " return np.dot(x_test,weights)+bias"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 68,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Score function to evalute the model\n",
+ "\n",
+ "def score(y_predict,y_true):\n",
+ " y_mean=np.mean(y_true)\n",
+ " return 1-((np.sum((y_true-y_predict)**2))/(np.sum((y_predict-y_mean)**2)))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 69,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "cost= 3808.943336170967\n",
+ "cost= 2568.684841123737\n",
+ "cost= 1768.8730253255492\n",
+ "cost= 1252.5190147981036\n",
+ "cost= 918.7948464487748\n",
+ "cost= 702.8696417592345\n",
+ "cost= 563.011155383819\n",
+ "cost= 472.32574846503945\n",
+ "cost= 413.4628686393532\n",
+ "cost= 375.21627800024777\n",
+ "cost= 350.3401989636246\n",
+ "cost= 334.14451524575384\n",
+ "cost= 323.5900950595011\n",
+ "cost= 316.7055340355867\n",
+ "cost= 312.2107016558603\n",
+ "cost= 309.27349614462946\n",
+ "cost= 307.35249924893975\n",
+ "cost= 306.0950856262999\n",
+ "cost= 305.2713718332876\n",
+ "cost= 304.73135337494017\n",
+ "cost= 304.37706056987787\n",
+ "cost= 304.14445242650265\n",
+ "cost= 303.991631152567\n",
+ "cost= 303.8911634153005\n",
+ "cost= 303.8250726041834\n",
+ "cost= 303.78157001041296\n",
+ "cost= 303.7529191926282\n",
+ "cost= 303.7340394898385\n",
+ "cost= 303.7215920998955\n",
+ "cost= 303.7133814882096\n",
+ "cost= 303.7079630240789\n",
+ "cost= 303.70438560265086\n",
+ "cost= 303.70202269194226\n",
+ "cost= 303.7004613490979\n",
+ "cost= 303.6994292679998\n",
+ "cost= 303.6987467955278\n",
+ "cost= 303.6982953516441\n",
+ "cost= 303.69799663347084\n",
+ "cost= 303.6977989132761\n",
+ "cost= 303.69766800576815\n",
+ "cost= 303.69758131053914\n",
+ "cost= 303.69752388087574\n",
+ "cost= 303.69748582853174\n",
+ "cost= 303.69746060972153\n",
+ "cost= 303.6974438926552\n",
+ "cost= 303.6974328090151\n",
+ "cost= 303.6974254590294\n",
+ "cost= 303.69742058411015\n",
+ "cost= 303.6974173502548\n",
+ "cost= 303.69741520468995\n",
+ "cost= 303.6974137809637\n",
+ "cost= 303.697412836095\n",
+ "cost= 303.69741220894406\n",
+ "cost= 303.6974117926251\n",
+ "cost= 303.69741151623043\n",
+ "cost= 303.69741133271214\n",
+ "cost= 303.69741121084877\n",
+ "cost= 303.6974111299194\n",
+ "cost= 303.697411076169\n",
+ "cost= 303.6974110404673\n",
+ "cost= 303.69741101675186\n",
+ "cost= 303.69741100099725\n",
+ "cost= 303.69741099053084\n",
+ "cost= 303.6974109835766\n",
+ "cost= 303.69741097895604\n",
+ "cost= 303.6974109758857\n",
+ "cost= 303.69741097384536\n",
+ "cost= 303.6974109724896\n",
+ "cost= 303.69741097158857\n",
+ "cost= 303.69741097098967\n",
+ "cost= 303.6974109705916\n",
+ "cost= 303.6974109703271\n",
+ "cost= 303.69741097015134\n",
+ "cost= 303.69741097003447\n",
+ "cost= 303.69741096995676\n",
+ "cost= 303.69741096990515\n",
+ "cost= 303.69741096987065\n",
+ "cost= 303.6974109698479\n",
+ "cost= 303.6974109698328\n",
+ "cost= 303.69741096982256\n",
+ "cost= 303.69741096981596\n",
+ "cost= 303.6974109698116\n",
+ "cost= 303.6974109698086\n",
+ "cost= 303.69741096980664\n",
+ "cost= 303.69741096980533\n",
+ "cost= 303.6974109698045\n",
+ "cost= 303.69741096980374\n",
+ "cost= 303.6974109698033\n",
+ "cost= 303.69741096980323\n",
+ "cost= 303.6974109698031\n",
+ "cost= 303.69741096980306\n",
+ "cost= 303.69741096980283\n",
+ "cost= 303.69741096980266\n",
+ "cost= 303.69741096980266\n",
+ "cost= 303.6974109698027\n",
+ "cost= 303.6974109698026\n",
+ "cost= 303.69741096980266\n",
+ "cost= 303.6974109698027\n",
+ "cost= 303.6974109698028\n",
+ "cost= 303.6974109698028\n"
+ ]
+ }
+ ],
+ "source": [
+ "weights,bias=fit(x_train,y_train,0.1,100)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 70,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "0.9468259773072768\n"
+ ]
+ }
+ ],
+ "source": [
+ "y_pred=predict(x_test,weights,bias)\n",
+ "print(score(y_pred,y_test))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 71,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "array([ 40.04975768, 61.95168262, 70.75259092, -137.45267539,\n",
+ " 24.39488421, 17.72229083, 114.86372767, 11.55805803,\n",
+ " 67.78412395, 24.39465238, -48.58469823, -20.92097096,\n",
+ " 31.69495894, -6.90322556, 59.38654823, 21.77986183,\n",
+ " -86.5061475 , -177.58814523, 15.23873962, -85.53663248,\n",
+ " -4.41360057, -42.42031553, 2.32555789, 37.62691579,\n",
+ " -108.75369459])"
+ ]
+ },
+ "execution_count": 71,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "y_pred"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3.9.12 ('base')",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.12"
+ },
+ "orig_nbformat": 4,
+ "vscode": {
+ "interpreter": {
+ "hash": "c19b36fe549fe2dce1ac32d0dd317d0a363043eb1c14a547f46436cb05190cdf"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}