/cdn.vox-cdn.com/uploads/chorus_asset/file/19725578/TheRinger_Top25NBAPlayers_2.png)
This Machine Learning example uses 15 seasons (2005-2020) of NBA player statistics (the features) to predict the position of each player (the target). Machine Learning models include Decision Trees, Random Forests, SVMs and Gradient Boosting. An example PCA transformation of X-data is included as well. Each model is then evaluated and compared to the others to determine which Machine Learning model works best for this particular set of NBA data. Specific players are fed into the best model, and interesting insights are made into which players truly deviate from the norms of their respective position and perhaps which position they may be more suited for.
Note: Stats are per 36 minutes, not per game. This ensures that the players' statistics are a fairer representation of the position's output. For instance, if a player only averages 5 min/game, his per game stats would be representative of that player's individual production, but for the purposes of predicting their position, does not say much. Stats per 36 minutes scales the data and makes it more meaningful.
CSV Datasets obtained from Basketball-Reference.com

Pre-processing mainly consisted of cleaning up the data and filtering the dataset to only show players that matched a certain criteria. Each season was read in as a separate CSV, and then concatenated into one single dataframe that I could work from. Next, I filtered the dataframe to only include players that had a minimum of 820 minutes played/season (10 min/game * 82 games/season). I did this because rows containing less than this acceptable level of Minutes Played would unfairly skew the data. For instance, if a player only plays 1 minute for a team and scores 2 points, his Points Per 36 Minutes would be 72; clearly not a fair representation.
original_df = original_df[original_df.MP >= 820]
I then sliced that dataframe to only include relevant features (dropping columns such as Name, Age and Team; features that aren't actually player statistics and have no bearing on a player's position). Next was to convert mixed positions, like "C-PF" and "PF-SF" into one of the 5 main basketball positions:
df = df.replace("C-PF","C")
This was done for every combination. Last thing to do was to round all columns to 2 decimal places: for simplicity's sake, only 1 conversion is shown here:
df = df.round({'PTS': 2})
This was done for every column. My original dataframe consisted of 7089 rows and 29 columns; after filtering players and dropping irrelevant columns, I was left with a dataframe of 4051 rows and 21 columns. This meant 4051 rows of player statistics for my model to work with, along with 20 features for the model to test (20 features, 1 target column). Here is a sample of the dataframe, showing only 5 rows, but all columns:

To confirm that target classes were evenly distributed and no re-balancing would need to take place, I checked the amount of unique values for each position:
df.loc[:, 'Pos'].value_counts()
SG: 947
PG: 873
PF: 814
SF: 809
C: 608
Positions are evenly distributed. We are now done with data pre-processing and can start getting into the models in-earnest.
summary_df = df.groupby('Pos').mean()
 We can glean useful information from the above chart. We see that in terms of, say, PTS, there is not much difference position-by-position: each averages about 15 points/36 minutes. However we see serious differences in a few categories, which are the ones we would expect; most namely, TRB (Total Rebounds) and AST (Assists). While point guards take the ball up the court and distribute the ball, leading to assists (PGs average 6.2 assists while Cs average 2.1 assists), centers are taller and have a more rebound-heavy responsibility (Cs average 10.1 rebounds while PGs average 3.9 rebounds). This gives a good idea about what to expect in the model, especially in terms of what the model deems to be the most important features that help determine a player's position.
We can glean useful information from the above chart. We see that in terms of, say, PTS, there is not much difference position-by-position: each averages about 15 points/36 minutes. However we see serious differences in a few categories, which are the ones we would expect; most namely, TRB (Total Rebounds) and AST (Assists). While point guards take the ball up the court and distribute the ball, leading to assists (PGs average 6.2 assists while Cs average 2.1 assists), centers are taller and have a more rebound-heavy responsibility (Cs average 10.1 rebounds while PGs average 3.9 rebounds). This gives a good idea about what to expect in the model, especially in terms of what the model deems to be the most important features that help determine a player's position.
bar_chart_df = summary_df[['PTS', 'TRB', 'AST', 'STL', 'BLK']]
bar_chart_df.plot(kind='bar', figsize = (12, 8), title='Bar Chart of Main Stats across all 5 Positions')

This simple bar chart shows the five main basketball statistics - Points, Rebounds, Assists, Steals and Blocks - and how they are distributed among the five positions. As mentioned above, points/36 minutes do not differ that greatly position-by-position; rebounds and assists, however, vary greatly. We can also see in yellow that centers average signficantly more blocks than other positions - blocks in general are hard to come by, so while centers average only 1.6 blocks/36 minutes, point guards average only .26 blocks/36 minutes, meaning in this particular dataset, centers average 144% more blocks/36 minutes than do point guards. This feature could potentially be deemed one of the more important ones by the upcoming models.
sns_df = df[['PTS', 'TRB', 'AST', 'STL', 'BLK', 'Pos']].head(300)
sns_df = sns_df.reset_index()
sns_df = sns_df.drop('index', axis=1)
sns_plot = sns.pairplot(sns_df, hue='Pos', size=2)
sns_plot
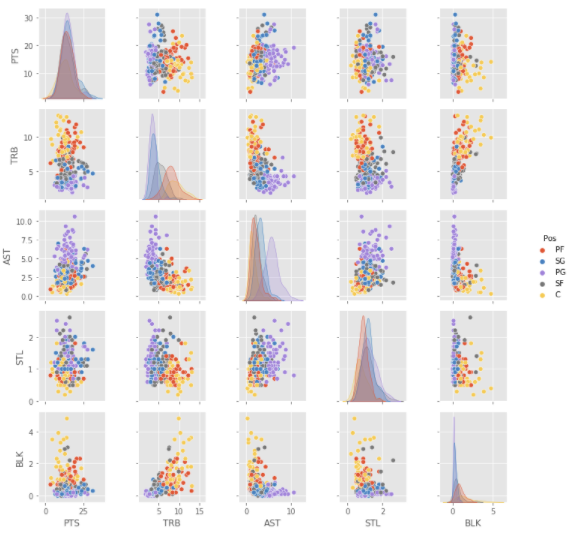
Here we see scatter plots of all possible x/y-axis combinations. The first thing I notice is the general positive correlation in these graphs - meaning, as the x-axis values increase, so do the y-values. This makes sense to me, as it tells me that the better a player is at one particular category, chances are, they are also good at other statistical categories (good players don't just do one thing well). However, with TRB and AST, it appears the opposite is true: generally speaking, the more assists a player has, or the more rebounds, the less of the other stat they will have.
The diagonal gives us insight into the distribution of each variable, broken down by position - it helps visualize the ranges in values by position. Looking at the TRB vs. TRB intersection, for example, we see that centers have a longer tail than other positions, while for the AST metric, point guards have a longer tail than other positions - the longer tail indicates a wider distribution, a wider range of values). While most categories have varied distributions, the PTS distribution remains relatively steady across all five positions.
A few more model-specific steps needed to be taken before running the models. This consisted of:
- Splitting the dataframe into one solely containing the features (the X-variables) and one solely containing the target column (the y-variable, what the model will predict). Conventionally, the X-variable is capitalized, while the y-variable is lower-case.
X = df.drop('Pos', axis=1)
y = df.loc[:, 'Pos']
- Manually encoding y-labels to make them more meaningful for the confusion matrix during evaluation:
position_dictionary = {
"PG": 1,
"SG": 2,
"SF": 3,
"PF": 4,
"C": 5}
y = y.map(position_dictionary).values.reshape(-1,1)
- Splitting X and y into X_train, X_test, y_train, y_test, and checking shape of each:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1, stratify=y)
print('X_train:', X_train.shape)
print('y_train:', y_train.shape)
print('X_test:', X_test.shape)
print('y_test:', y_test.shape)
The purpose of splitting the data into training and testing datasets is to test the accuracy of the model. You "train" the model with your training dataset (typically 80% of the data) and then "test" the model's accuracy with the testing dataset (typically 20% of the data). This allows for an easy way to evaluate the model's performance. The shape of the training and testing dataframes are as follows:
X_train: 3038 rows, 20 columns
y_train: 3038 rows, 1 column
X_test: 1013 rows, 20 columns
y_test: 1013 rows, 1 column
This means that we will "train" the model using 3038 rows of data containing 20 features/x-variables. We will "test" the model using 1013 rows of data containing the same 20 features/x-variables. The y-datasets simply consist of one column (the target column, the player's position), with the y_train containing more data than the y_test.
- Scale data:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaler = scaler.fit(X_train)
X_train_scaled = X_scaler.transform(X_train)
X_test_scaled = X_scaler.transform(X_test)
Scaling the data changes the range of values without changing the shape of the distribution. This was done because in my dataset, all columns are not on the same scale: for instance, many columns are integers/floats (PTS, TRB, AST, etc.) while others are expressed as percentages (FG%, 3P%, FT%, etc.). Scaling data generally makes machine learning algorithms perform better/faster because features are on a relatively smaller scale and are normally distributed. It ultimately makes it easier for the model to run.
- PCA Transform X-data (not necessary, and only done once in models, for example's sake)
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
X_pca = pca.fit(X_train_scaled)
X_train_pca = X_pca.transform(X_train_scaled)
X_test_pca = X_pca.transform(X_test_scaled)
X_train_pca_df = pd.DataFrame(data = X_train_pca, columns = ["PC1", "PC2", "PC3"])
X_test_pca_df = pd.DataFrame(data = X_test_pca, columns = ["PC1", "PC2", "PC3"])
The code above generates the above dataset.
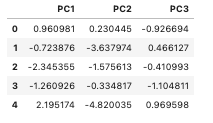
PCA transformation of X-data is generally performed on large datasets in order to reduce the number of dimensions in the dataset and make it easier for the model to run. It transforms the X-dataset, meaning you no longer have your original features as columns; they are now split into "Principal Components," and an explained variance ratio can be computed which tells you how much of the explained variance was captured in the dataset - what percent could it make sense of? For a dataset of this size, PCA transformation of X-data would typically not be used; it was only included for example's sake, and was only performed on one dataset.
Decision Trees, Random Forests, Support Vector Machines (SVMs) and Gradient Boosted Trees (GBTs) were tested. Each model was tested at least twice: once using all 20 the features, and once using only the top 5 most important features, deemed by the model itself. Only Decision Trees were tested three times (to show an example of PCA transformation and how it affected performance of model).
Note that models are "trained" using the X_train_scaled and the accompanying y_train datasets, while the predictions are based off of the X_test_scaled (data that the model has not seen).
# Decision Trees:
from sklearn import tree
dt1_model = tree.DecisionTreeClassifier(random_state=1)
dt1_model = dt1_model.fit(X_train_scaled, y_train)
predictions = dt1_model.predict(X_test_scaled)
# Random Forests:
from sklearn.ensemble import RandomForestClassifier
rf1_model = RandomForestClassifier(n_estimators=500, random_state=1)
rf1_model = rf1_model.fit(X_train_scaled, y_train)
predictions = rf1_model.predict(X_test_scaled)
# Support Vector Machines (SVMs):
from sklearn import svm
from sklearn.svm import SVC
svm1_model = svm.SVC(kernel='linear', random_state=1)
svm1_model = svm1_model.fit(X_train_scaled, y_train)
predictions = svm1_model.predict(X_test_scaled)
# Gradient Boosted Trees (GBTs):
from sklearn.ensemble import GradientBoostingClassifier
gbt1_model = GradientBoostingClassifier(n_estimators=20, learning_rate=0.75, max_depth=3, random_state=1)
gbt1_model = gbt1_model.fit(X_train_scaled, y_train)
predictions = gbt1_model.predict(X_test_scaled)
Each model was run one after the other, in an order that flowed: first I tested the full dataset and determined what the model deemed to be the most important/relevant features. Then I ran the same model, except this time, limiting my features to only those top-5 most important (by simply dropping unneeded columns in dataframe and re-running model). As mentioned, for the Decision Tree models, an example is included where I PCA transform the X-data; that is not done for the other models.
A key parameter in the Gradient Boosted Trees model is the Learning Rate: how fast the model learns. Generally speaking, the lower the learning rate, the slower the model learns, and models that learn slowly perform better. But this comes at a cost - it takes more time to train the model, and more trees are needed to train the model, which creates a risk of overfitting. To determine which learning rate is best, I created a list of learning_rates and ran a for-loop that tests the accuracy scores of both the training and the testing datasets for all learning_rates:
learning_rates = [0.05, 0.1, 0.25, 0.5, 0.75, 1]
for learning_rate in learning_rates:
gbt1_model = GradientBoostingClassifier(n_estimators=20, learning_rate=learning_rate, max_features=5, max_depth=3, random_state=0)
# Fit the model
gbt1_model.fit(X_train_scaled, y_train.ravel())
print("Learning rate: ", learning_rate)
# Score the model
print("Accuracy score (training): {0:.3f}".format(
gbt1_model.score(
X_train_scaled,
y_train.ravel())))
print("Accuracy score (validation): {0:.3f}".format(
gbt1_model.score(
X_test_scaled,
y_test.ravel())))
Running this allowed me to choose the optimal learning_rate for the model. I chose learning_rate = 0.75 because it had the best combination of Training Accuracy Score (84.7%) and Testing Accuracy Score (68.3%).
Generate a "Feature Importance" table/graph to identify what the model deems to be the 5 most important/relevant features, and use only those 5 features in the next model to compare to the previous model (which used all 20 features):
Feature Importance tables for Decision Trees, Random Forests, and Gradient Boosted Trees can be generated by using a simple "model.feature_importances_" function:
model_importances = pd.DataFrame(model.feature_importances_, index = X_train.columns, columns=['Importance']).sort_values('Importance', ascending=False)
The code above generates the following feature importance table, this being the one for Decision Tree 1:
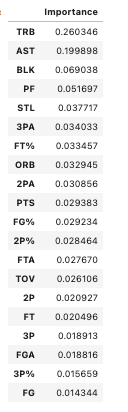
We can see in this example that Decision Tree 1 deemed TRB, AST, BLK, PF and STL to be the most important features that help the model predict positions. It deemed FG, 3P%, FGA, 3P and FT to be the least important features. This makes sense - the categories in which average stats differ greatly position-by-position (like TRB and AST) the model deems to be important, while categories in which average stats do not differ greatly position-by-position (like FG and FGA) the model deems to be unhelpful toward making predictions.
Feature Importance tables for SVMs, however, do not have that same "model.feature_importances_" function. Rather, a plot must be constructed that visualizes the importance:
def f_importances(coef, names, top=-1):
imp = coef
imp, names = zip(*sorted(list(zip(imp, names))))
# Show all features:
if top == -1:
top = len(names)
plt.barh(range(top), imp[::-1][0:top], align='center')
plt.yticks(range(top), names[::-1][0:top])
plt.show()
feature_names = ['PTS', 'TRB', 'ORB', 'AST', 'STL', 'BLK', 'FG', 'FGA', 'FG%', '3P', '3PA', '3P%', '2P', '2PA', '2P%', 'FT', 'FTA', 'FT%', 'PF', 'TOV']
f_importances(abs(svm1_model.coef_[0]), feature_names)
The code above generates the following feature importance chart for SVM 1:

We can see in this example that SVM 1 deemed AST, BLK, TRB, 2P and FTA to be the most important features that help the model predict positions. It deemed PTS, FG%, FT%, 2P% and STL to be the least important features. This makes sense - the categories in which average stats differ greatly position-by-position (like TRB and AST) the model deems to be important, while categories in which average stats do not differ greatly position-by-position (like PTS) the model deems to be unhelpful toward making predictions.
For all of the below metrics, replace the variable name with specific model being run to compare them all. Run after each model, as opposed to all at once at the end, because the "y_test" and "predictions" datasets will change after each time a new model is run.
from sklearn.metrics import accuracy_score
model_accuracy_score = accuracy_score(y_test, predictions)
Make sure your accuracy score is based on y_test, not y_train. A true accuracy score should be based on numbers that the model has not yet seen, which is what the testing dataset is.
- Random Forest 1 Accuracy score (all 20 features): 71.4%
- SVM 1 Accuracy score (all 20 features): 70.6%
- SVM2 Accuracy score (top 5 features): 67.2%
- Random Forest 2 Accuracy score (top 5 features): 66.2%
- Gradient Boosted Tree 1 Accuracy score (all 20 features): 66.2%
- Gradient Boosted Tree 2 Accuracy score (top 5 features): 65.7%
- Decision Tree 1 Accuracy score (all 20 features): 61.7%
- Decision Tree 3 Accuracy score (top 5 features): 59.6%
- Decision Tree 2 Accuracy score (all 20 features, PCA transformation): 50.0%
The highest accuracy score of 71.4% was obtained from the Random Forest model which uses all 20 features; the lowest accuracy score of 50.0% was obtained from the Decision Tree model which uses all 20 features and uses PCA transformation of X-data. In general, Random Forests and SVMs performed the best, while Gradient Boosted Trees and Decision Trees performed the worst.
Confusion Matrices are a good way to visualize the accuracy of a classification, but in a more visual style. They are tabluar summaries of the number of correct and incorrect predictions made by a classifier. I defined a custom function to print a Confusion Matrix Heatmap, and once this function was defined, all future confusion matrices were generated by simply calling the function name.
from sklearn.metrics import confusion_matrix
# Define Custom Confusion Matrix function that plots Heatmap of Actuals vs. Predictions:
def confusion_matrix_heatmap(y_test, predictions):
"""This plots the confusion matrix"""
warnings.filterwarnings('ignore')
cm = confusion_matrix(y_test, predictions)
# Plot Heatmap:
f, ax = plt.subplots(figsize=(9, 7))
heat_map = sns.heatmap(cm, annot=True, fmt="d", linewidths=1, ax=ax, cmap=sns.cubehelix_palette(50), xticklabels=position_dictionary.keys(), yticklabels=position_dictionary.keys())
# Set X and Y Labels:
heat_map.set_xlabel("# Predicted")
heat_map.set_ylabel("# Actual")
# Print confusion matrix:
cm1 = confusion_matrix_heatmap(y_test, predictions)
The code above generates the following confusion matrix, this being the one for Random Forest 1:

The confusion matrix is a helpful way to visualize the model's accuracy. We can see in the above, for instance, that out of the 218 point guards included in the Testing Dataset (181+34+3+0+0), the model correctly predicted "point guard" 181 times. 34 times it thought the point guard was a shooting guard, 3 times it thought the point guard was a small forward, it never thought the point guard was a power forward, and it never thought the point guard was a center. That distribution makes sense - as the differing responsibilities of the positions increased, the model was less likely to predict that the point guard was that position.
Classification Reports show other key metrics for the model that are related to, but are not exactly, accuracy (Precision, Recall, F1 and Support scores). We will see that these scores tend to be very close to, if not exactly the same as, the accuracy score (given the multiclass nature of the target column, position).
from sklearn.metrics import classification_report
model_class_report = classification_report(y_test, predictions, target_names = ['PG', 'SG', 'SF', 'PF', 'C'])
The code above generates the following classification report, this being the one for Random Forest 1:

Precision: Accuracy of positive predictions: The model positively predicted a position (meaning it said it is this position as opposed to it is NOT that position) at a 72% rate.
Recall: Fraction of positives that were correctly identified: The model caught 71% of the positive cases.
F1 Score: The percentage of positive predictions correctly predicted: The model correctly predicted 72% of the positive predictions.
Support: Number of occurrences in the dataset, AKA, the number of rows in the dataset. This dataset contained 1013 rows of data and therefore had a Support score of 1013.
### Best Accuracy Score: Random Forest 1 model: 71.4%
### Best Classification Report Scores: Random Forest 1 model: 72% precision, 71% recall, 72% F1 score
### Best Overall Model: Random Forest 1 model
Let's use the best model (Random Forest 1, 71.4% accuracy) and give it specific predictions, feeding it real stats of real players, to see how it classifies each player.
First, I created two dataframes: one of players who define their position well, and one of players who play a more "positionless" game, one in which their stats are not confined to the traditional responsibilities of their position. Then I dropped and re-ordered the dataframe columns to mimic Random Forest 1's dataset, and scaled the data because the Random Forest model data was scaled.
# Select players who define their position well:
pg_steph_row = original_df.loc[((original_df['Player'] == 'Stephen Curry') & (original_df['Age'] == 26))]
sg_beal_row = original_df.loc[((original_df['Player'] == 'Bradley Beal') & (original_df['Age'] == 24))]
sf_kawhi_row = original_df.loc[((original_df['Player'] == 'Kawhi Leonard') & (original_df['Age'] == 25))]
pf_love_row = original_df.loc[((original_df['Player'] == 'Kevin Love') & (original_df['Age'] == 27))]
c_embiid_row = original_df.loc[((original_df['Player'] == 'Joel Embiid') & (original_df['Age'] == 24))]
# Concatenate above into one dataframe:
position_players_df = pd.concat([pg_steph_row, sg_beal_row, sf_kawhi_row, pf_love_row, c_embiid_row], axis='rows', join='inner')
# Drop/Re-order columns to mimic Random Forest 1's dataset:
position_players_df = position_players_df[['PTS', 'TRB', 'ORB', 'AST', 'STL', 'BLK', 'FG', 'FGA', 'FG%', '3P', '3PA', '3P%', '2P', '2PA', '2P%', 'FT', 'FTA', 'FT%', 'PF', 'TOV']]
# Scale data (model data was scaled, so this data needs to be scaled as well):
position_players_df_scaled = scaler.fit_transform(position_players_df)
# Select players who play a more "positionless" game, in which their stats are not confined to the traditional responsibilities of their position:
pg_simmons_row = original_df.loc[((original_df['Player'] == 'Ben Simmons') & (original_df['Age'] == 22))]
pg_westbrook_row = original_df.loc[((original_df['Player'] == 'Russell Westbrook') & (original_df['Age'] == 24))]
sg_harden_row = original_df.loc[((original_df['Player'] == 'James Harden') & (original_df['Age'] == 26))]
pf_lebron_row = original_df.loc[((original_df['Player'] == 'LeBron James') & (original_df['Age'] == 33))]
pf_draymond_row = original_df.loc[((original_df['Player'] == 'Draymond Green') & (original_df['Age'] == 27))]
pf_giannis_row = original_df.loc[((original_df['Player'] == 'Giannis Antetokounmpo') & (original_df['Age'] == 23))]
c_gasol_row = original_df.loc[((original_df['Player'] == 'Marc Gasol') & (original_df['Age'] == 33))]
# Concatenate above into one dataframe:
positionless_players_df = pd.concat([pg_simmons_row, pg_westbrook_row, sg_harden_row, pf_lebron_row, pf_draymond_row, pf_giannis_row, c_gasol_row], axis='rows', join='inner')
# Drop/Re-order columns to mimic Random Forest 1's dataset:
positionless_players_df = positionless_players_df[['PTS', 'TRB', 'ORB', 'AST', 'STL', 'BLK', 'FG', 'FGA', 'FG%', '3P', '3PA', '3P%', '2P', '2PA', '2P%', 'FT', 'FTA', 'FT%', 'PF', 'TOV']]
# Scale data (model data was scaled, so this data needs to be scaled as well):
positionless_players_df_scaled = scaler.fit_transform(positionless_players_df)
# Predict first dataframe, containing players who define their position well:
# A PG, SG, SF, PF, then C were loaded in. Therefore, this output should be 1, 2, 3, 4, 5.
# Also keep in mind order of players: PG Curry, SG Beal, SF Leonard, PF Love, C Embiid.
position_predictions = rf1_model.predict(position_players_df_scaled)
# Output = array([1, 2, 3, 4, 5])
# Predict second dataframe, containing players who play a more "positionless" game:
# A PG, PG, SG, PF, PF, PF, and C were loaded in. Therefore, this output should be 1, 1, 2, 4, 4, 4, 5.
# Also keep in mind order of players: PG Simmons, PG Westbrook, SG Harden, PF LeBron, PF Draymond, PF Giannis, C Gasol.
positionless_predictions = rf1_model.predict(positionless_players_df_scaled)
# Output = array([4, 2, 2, 3, 4, 4, 4])
The Random Forest 1 model correctly predicted all 5 positions in the "position" dataframe (the dataframe with players who define their position well), as we expected it to. But what about the "positionless" dataframe?
The Random Forest 1 model correctly predicted 3 of the 7 positions in the "positionless" dataframe: it correctly predicted James Harden as a SG, Draymond Green as a PF, and Giannis Antetokounmpo as a PF. However, it thought PG Ben Simmons was a PF, PG Westbrook was a SG, PF LeBron James was a SF and C Marc Gasol was a PF. For a center to be mistaken for a power forward, and vice-versa, or for a point guard to be mistaken for a shooting guard, and vice-versa, is not an egregious error. These positions are similar and share similar responsibilities, and oftentimes, these players do in fact play both positions over the course of a season, or even at different points in the same game. The most interesting finding here is the one relating to PG Ben Simmons: the model thought he was a PF. Ben Simmons is 6'10", which is very tall for a point guard. He is also a notoriously bad shooter for his position, rarely shooting from the outside, and mostly missing when he does. Therefore, his stats are more similar to those of power forwards, grabbing rebounds and shooting poorly from the outside. This is why the model thought he was a power forward.
Let's do the same thing, but this time, we'll use the 2020-2021 season statistics for my favorite NBA team, the New York Knicks.
At this point in time the season is only 15-games through, so take this model's predictions with a grain of salt:
# Load in 2020-2021 Knicks dataframe:
knicks_csv_path = Path('CSVs/knicks.csv')
knicks_df = pd.read_csv(knicks_csv_path)
# This particular dataset did not contain a "Position" column. Let's add one ourselves:
positions = {'Position': ['PF', 'SG', 'C', 'PG', 'SF', 'SF', 'SG', 'C', 'PG', 'SG', 'PF', 'PG', 'PG', 'SG', 'SF', 'PG']}
df_positions = pd.DataFrame(positions)
knicks_df['Pos'] = df_positions
# Filter dataframe to only include rows with at least 100 Minutes Played:
# We are only 15 games through the 2020-2021 season at the time of this writing,
# so a few players who have been injured have very few minutes: remove them
# from the dataset.
knicks_df = knicks_df[knicks_df.MP >= 100]
# Drop/Re-order columns to mimic Random Forest 1's dataset:
knicks_df = knicks_df[['PTS', 'TRB', 'ORB', 'AST', 'STL', 'BLK', 'FG', 'FGA', 'FG%', '3P', '3PA', '3P%', '2P', '2PA', '2P%', 'FT', 'FTA', 'FT%', 'PF', 'TOV']]
# Replace "NaN" values with "0" instead of dropping null rows completely (helps preserve the data):
knicks_df[np.isnan(knicks_df)] = 0.0
# Scale data (model data was scaled, so this data needs to be scaled as well):
knicks_df_scaled = scaler.fit_transform(knicks_df)
This left me with a dataframe exactly like that of Random Forest 1. Now all I had to do was feed this dataframe into Random Forest 1's model, and see what it predicted:
knicks_predictions = rf1_model.predict(knicks_df_scaled)
# Output = array([4, 3, 5, 1, 3, 2, 2, 5, 1])
- The Random Forest 1 model correctly predicted 7 of the 9 positions: it correctly predicted Julius Randle as a PF, Mitchell Robinson as a C, Elfrid Payton as a PG, Reggie Bullock as a SF, Austin Rivers as a SG, Nerlens Noel as a C and Immanuel Quickley as a PG.
- However, it thought SG RJ Barrett was a SF and it thought SF Kevin Knox was a SG.
- What I expected to see is exactly what happened - SG RJ Barrett was not in fact identified as a SG, or even as a PG. This is because RJ Barrett, at least at this point in his young career, is an inconsistent, abysmal shooter who scores most of his points in the paint.
- This information is useful because it can be one of the factors in setting lineups - which players can play multiple positions, or which players could see success trying their hand in a new role. In this particular case with Barrett, it could be a warning signal to the Knicks not to play him at SG, but to instead play him at what the model predicted he was, a SF. Perhaps the Knicks can switch Barrett and Knox's positions - play Barrett at SF and Knox at SG, like the model predicted.
The first, and most obvious, way to improve the model would be to use a larger dataset; my dataset contained 15 seasons and 4051 rows of data (after filtering), which is not small, but a larger dataset with more training/testing data could have benefitted. Another way to improve the models' accuracy would be to filter the dataframe even further: I only included players with at least 820 minutes played in the season (10 min/game * 82 games), which I felt was a good number to use because it filtered out rarely-used players while still keeping a good amount of the data. Using a higher threshold of minutes played would ensure that the players included in the dataset are truly representative of that position's output.
I also think a key feature was missing from the original dataset: the player's height. This is a huge factor in determining one's position, and I believe if that feature was included in the original dataset, it would have been deemed by the models as one of the most important feautures and would have ultimately increased accuracy scores across the board. More robust feature engineering in general would serve this dataset well.
In addition, today's NBA is becoming increasingly more "positionless". Players' skill-sets are much more thorough and comprehensive than they used to be - back in the day, centers typically did not shoot three pointers and point guards did not grab many rebounds. But in today's game, one's "position" on paper does not mean all that much; players have a variety of skills, and like we saw above in Random Forest 1's predictions, it is not so easy to predict positions anymore in the NBA. Using seasons from many years ago, much older than 15 years - when the game was more rigid than it is today and players mainly stuck to the traditional responsibilities of their respective position - would make it easier for the model to make predictions. A next step could be to use another Random Forest model using the same 20 features, but this time, use a different dataset, one containing NBA data from, say, 1980-1995, and see how accurate the model is compared to the model's accuracy using more current NBA data.