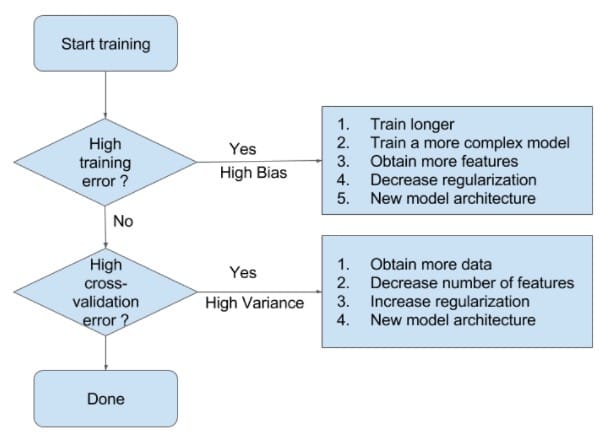
當模型處於欠擬合狀態時,根本的辦法是增加模型的複雜度。一般有以下一些辦法:
- 增加模型迭代次數;
- 訓練一個複雜度更高的模型:比如在神經網絡中增加神經網絡層數、在SVM中用非線性SVM(核技術)代替線性SVM
- 獲取更多的特徵以供訓練使用:特徵少,對模型信息的刻畫就不足夠了
- 降低正則化權重:正則化正是為了限制模型的靈活度(複雜度)而設定的,降低其權值可以在模型訓練中增加模型複雜度。
當模型處於過擬合狀態時,根本的辦法是降低模型的複雜度。一般有以下一些辦法:
- 獲取更多的數據:訓練數據集和驗證數據集是隨機選取的,它們有不同的特徵,以致在驗證數據集上誤差很高。更多的數據可以減小這種隨機性的影響。
- 減少特徵數量
- 增加正則化權重:方差很高時,模型對訓練集的擬合很好。實際上,模型很有可能擬合了訓練數據集的噪聲,拿到驗證集上擬合效果就不好了。我們可以增加正則化權重,減小模型的複雜度。
[Reference]
[机器学习算法系列(18):方差偏差权衡(Bias-Variance Tradeoff)]([https://plushunter.github.io/2017/04/19/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AE%97%E6%B3%95%E7%B3%BB%E5%88%97%EF%BC%8818%EF%BC%89%EF%BC%9A%E6%96%B9%E5%B7%AE%E5%81%8F%E5%B7%AE%E6%9D%83%E8%A1%A1%EF%BC%88Bias-Variance%20Tradeoff%EF%BC%89/](https://plushunter.github.io/2017/04/19/机器学习算法系列(18):方差偏差权衡(Bias-Variance Tradeoff)/))