#
蒙特卡洛搜索(MCTS) MCTS这里的采样,是指一次从根节点到游戏结束的路径访问,只要采样次数足够多,可以近似知道走哪条路径比较好。对于树型结构,解空间太大,不可能完全随机去采样,需要解决深度优化和广度优化问题:分支节点怎么选(广度优化)?评估节点是否一定要走到底得到游戏最优结果(深度优化)?怎么走,随机走?Selection,Expansion,Simulation和Backpropagation。
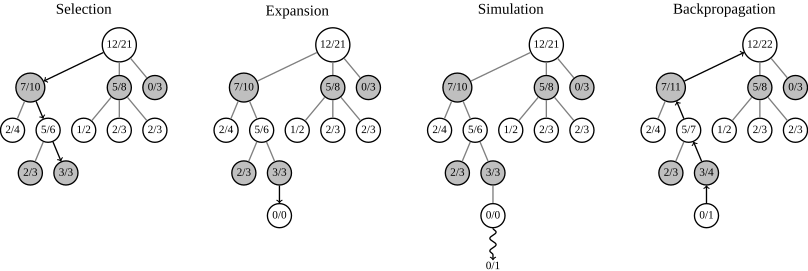
具体的细节,可以参考UCT(Upper Confidence Bound for Trees) algorithm – the most popular algorithm in the MCTS family。从维基百科最下方那篇论文截的图。原文有点长,这里点到为止,足够理解AlphaGO即可。N是搜索次数,控制exploitation vs. exploration。免得一直搜那个最好的分支,错过边上其他次优分支上的好机会。


-
走棋网络(Policy Network),给定当前局面,预测/采样下一步的走棋。
-
快速走子(Fast rollout),目标和1一样,但在适当牺牲走棋质量的条件下,速度要比1快1000倍。
-
估值网络(Value Network),给定当前局面,估计是白胜还是黑胜。
-
蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS),把以上这三个部分连起来,形成一个完整的系统。
Supervised learning(SL)学得objective是高手在当前state选择的action。Pσ=(a|s)
-
- 从棋局中随机抽取棋面(state/position)
-
- 30 million positions from the KGS Go Server (KGS是一个围棋网站)。数据可以说是核心,所以说AI战胜人类还为时尚早,AlphaGo目前还是站在人类expert的肩膀上前进。
-
- 棋盘当作19*19的黑白二值图像,然后用卷积层(13层)。比图像还好处理。rectifier nonlinearities
-
- output all legal moves
-
- raw input的准确率:55.7%。all input features:57.0%。后面methods有提到具体什么特征。需要一点围棋知识,比如liberties是气的意思
linear softmax + small pattern features 。对比前面Policy Network,
- 非线性 -> 线性
- 局部特征 -> 全棋盘
准确率降到24.2%,但是时间3ms-> 2μs。前面MCTS提到评估的时候需要走到底,速度快的优势就体现出来了。
要点
- 前面policy networks的结果作为初始值ρ=μ
- 随机选前面某一轮的policy network来对决,降低过拟合。
- zt=±1是最后的胜负。决出胜负之后,作为前面每一步的梯度优化方向,赢棋就增大预测的P,输棋就减少P。
- 校正最终objective是赢棋,而原始的SL Policy Networks预测的是跟expert走法一致的准确率。所以对决结果80%+胜出SL。
跟Pachi对决,胜率从原来当初SL Policy Networks的11%上升到85%,提升还是非常大的。
判断一个棋面,黑或白赢的概率各是多少。所以参数只有s。当然,你枚举一下a也能得到p(a|s)。不同就是能知道双方胜率的相对值
- using policy p for both players (区别RL Policy Network:前面随机的一个P和最新的P对决)
- vθ(s)≈vPρ(s)≈v∗(s) 。v∗(s) 是理论上最优下法得到的分数。显然不可能得到,只能用我们目前最强的Pρ算法来近似。但这个要走到完才知道,只好再用Value Network vθ(s)来学习一下了。
