Structed Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine.
- Streaming computation
- batch computation on static data
More information about Structed Streaming: git address.
- how to express basic operation?
- how to guarantee end-to-end exactly-once stream processing?
- how to provide fast,fault-tolerant stream processing performance?
-
DStream -> Structed Streaming
-
DataFrame/RDD -> Dataset API
/**
* Created by alienware on 2017/1/10.
* 车型预测流式处理
*/
public class PredictCarModel {
private static volatile Broadcast<List<String>> broadcast0 = null;
private static volatile Broadcast<StructType> broadcast = null;
private static volatile Broadcast<HiveContext> broadcast2 = null;
private static volatile Broadcast<StructType> broadcast3 = null;
public static void main(String[] args) throws InterruptedException{
System.setProperty("hadoop.home.dir", "D:\\Program Files\\hadoop-2.5.2");
SparkConf sparkConf = new SparkConf()
.setAppName("PredictCarModel")
.setMaster("local[12]")
// .set("spark.streaming.receiver.writeAheadLog.enable","true") //HA
.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.set("spark.default.parallelism","20");
// .set("spark.streaming.blockInterval","50");
JavaStreamingContext javaStreamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(ConfigurationManager.getInteger(Constants.PREDICT_CARMODEL_DURATION)));
final HiveContext hiveContext = new HiveContext(javaStreamingContext.sparkContext());
javaStreamingContext.checkpoint("hdfs://192.168.1.157:9000/streaming-checkpoint");//upadteStateByKey.,window等有状态的操作,自动的进行checkpoint
//构建Kafka的参数Map
Map<String,String> kafkaParams = new HashMap<String, String>();
kafkaParams.put("metadata.broker.list", ConfigurationManager.getProperty(Constants.KAFKA_METADATA_BROKER_LIST));
//构建topic set
String kafkaTopics = ConfigurationManager.getProperty(Constants.KAFKA_PREDICTCARMODEL_TOPICS);
String[] kafkaTopicsSplited = kafkaTopics.split(",");
Set<String> topics = new HashSet<String>();
for(String kafkaTopic : kafkaTopicsSplited){
topics.add(kafkaTopic);
}
//基于kafka direct api模式,构建出针对kafka集群中指定topic的输入DStream<K,V>
JavaPairInputDStream<String,String> realTimeDStream = KafkaUtils.createDirectStream(
javaStreamingContext,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
kafkaParams,
topics
);
//从MySQL中查出所有Brand组成一个RDD
IBrandDAO brandDAO = DAOFactory.getBrand();
List<String> brands = brandDAO.getBrands();
broadcast0 = javaStreamingContext.sparkContext().broadcast(brands);
broadcast2 = javaStreamingContext.sparkContext().broadcast(hiveContext);
List<StructField> fields = getField();
List<StructField> newFields = getNewField();
//构建schema
final StructType schema = DataTypes.createStructType(fields);
final StructType newSchema = DataTypes.createStructType(newFields);
broadcast = javaStreamingContext.sparkContext().broadcast(schema);
broadcast3 = javaStreamingContext.sparkContext().broadcast(newSchema);
//首先需要进行过滤,就是没有进入模型的Brand品牌的车型需要过滤出来,然后将过滤出来的数据写入MySQL数据库
JavaPairDStream<String,String> filteredDStream = filterBrand(realTimeDStream);
//然后进行预测,将预测的结果写入MySQL数据库中,将预测准确无误的结果放到数据仓库中,提供给以后训练模型使用
PredictCarModelRes(filteredDStream);
javaStreamingContext.start();
javaStreamingContext.awaitTermination();
javaStreamingContext.close();
}
/**
* Created by lenovo on 2017/1/6.
*/
public class TCPSocketWordCount {
public static void main(String[] args){
System.setProperty("hadoop.home.dir", "D:\\Program Files\\hadoop-2.5.2");
SparkSession sparkSession = SparkSession
.builder()
.appName("TCPSocketWordCount")
.master("local[12]")
.getOrCreate();
//Create DataFrame representing the stream of input lines from connection to localhost:9999
Dataset<Row> lines = sparkSession
.readStream()
.format("socket")
.option("host","localhost")
.option("port",9999)
.load();
//Split the lines into words
Dataset<String> words = lines
.as(Encoders.STRING())
.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
},Encoders.STRING());
//Generate running word count
Dataset<Row> wordCounts = words.groupBy("value").count();
// Start running the query that prints the running counts to the console
StreamingQuery streamingQuery = wordCounts.writeStream()
.outputMode("complete")
.format("console")
.start();
try {
streamingQuery.awaitTermination();
} catch (StreamingQueryException e) {
e.printStackTrace();
}
}
}
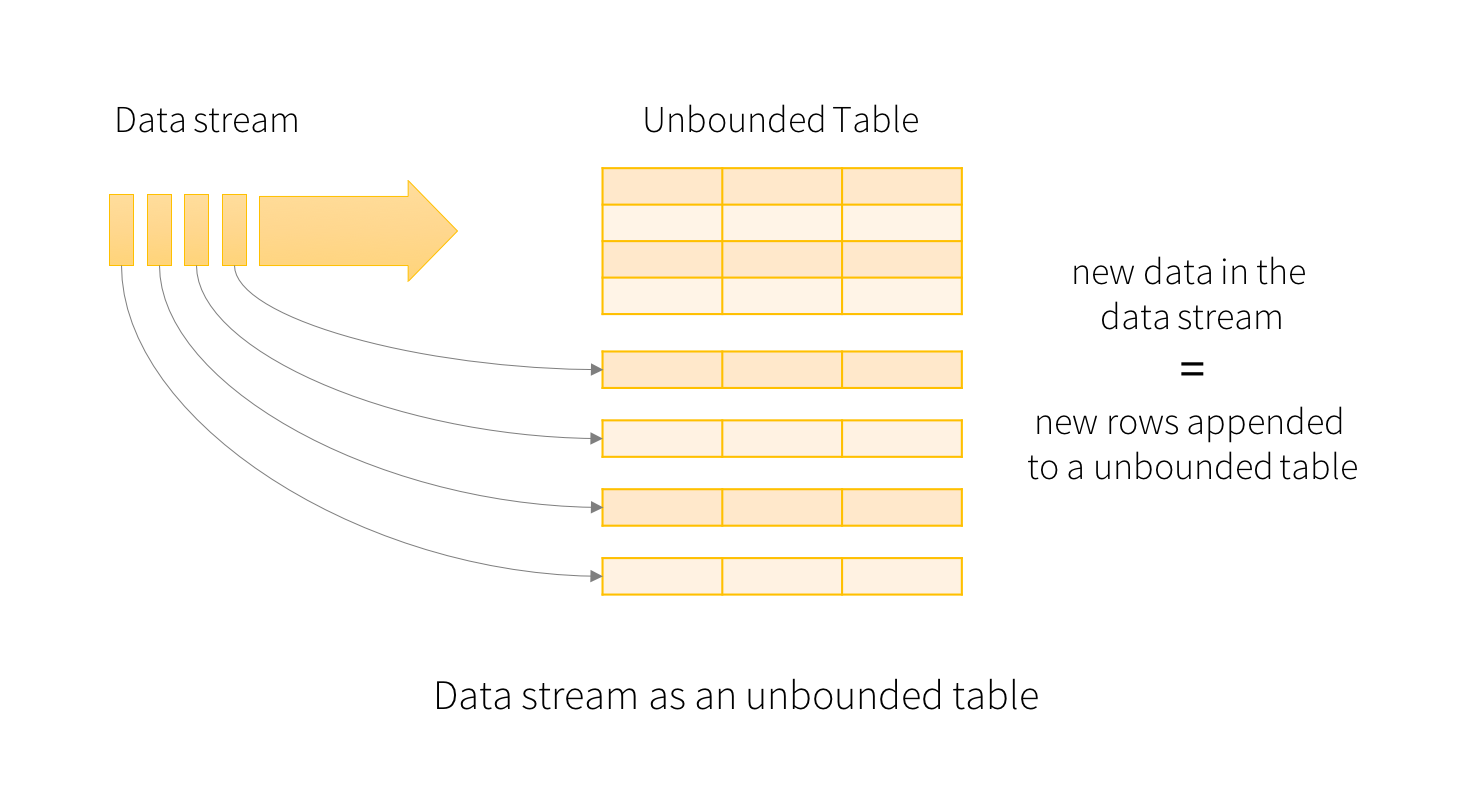
- treat a live data stream as a table that is being continuously appended.
- express your streaming computation as standard batch-like query as on a static table/
support for watermarking
-
designed the Structed Streaming sources,the sinks and the execution engine
-
checkpoint and WAL