Automatic document clustering and search tools for ICCV / CVPR papers by using fasttext from Facebook Research
- Build word/phrase dataset by text corpus
- Train word embedding vector by fasttext
- Build dcoument vector and reduce data dimension
- Clusterize and visualize each document
- Search Document by keywords
- Find Document by similar Document
Scrape paper info (title, abstract and PDF) from CVPR open access repository. Then extracts words to build a corpus. Scraping HTML/PDF is a little off-topic for this sample, so I removed those scraping code from this repository.
After extracting text from each PDF, we pre-processes the data like below.
- Remove "-" with "/n" to concatenate words divided by CR.
- Then replace "-" with " ".
- Replace all other non character codes with " "
- Convert all capital to small.
- Remove "one character word" and special words like "http/https/ftp" or urls
- Remove the, an in, on, and, of to, is, for, we, with, as, that, are, by, our, this, from, be, ca, at, us, it, has, have, been, do, does, these, those, and "et al".
- Replace popular plural noun to singular noun.
- Remove people's name.
The input corpus we built is placed under raw_data
Build my Paper2Vec instance. Load multiple corpus files. Replace rare words with UNK token to build a suitable size of dictionary.
p2v = Paper2Vec(data_dir=args.data_dir, word_dim=args.word_dim)
p2v.add_dictionary_from_file('CVPR2016/corpus.txt')
p2v.add_dictionary_from_file('CVPR2017/corpus.txt')
p2v.add_dictionary_from_file('CVPR2018/corpus.txt')
p2v.build_dictionary(args.max_dictionary_words)
Count occurrences of words sequence. Unite frequent sequence words with "_". For ex "deep learning" will be now one word, "deep_learning".
p2v.detect_phrases(args.phrase_threshold)
p2v.create_corpus_with_phrases('corpus.txt')
p2v.convert_text_with_phrases('CVPR2018/abstract.txt', 'abstract.txt')
copyfile(args.data_dir + '/CVPR2018/paper_info.txt', args.data_dir + '/paper_info.txt')
You can train with "skipgram" or "cbow" by fasttext. Default dimension of vector is 75. Also you can find similar word by calling get_most_similar_words().
p2v.train_words_model('corpus.txt', 'fasttext_model', model=args.train_model, min_count=args.min_count)
print('[deep_learning]', p2v.get_most_similar_words('deep_learning', 12))
Calculate mean vector of each words' vector in abstract and title to define the vector as a paper representation vector.
p2v.build_paper_vectors()
Reduce 75-dim of paper vector into 2-dim by using t-SNE.
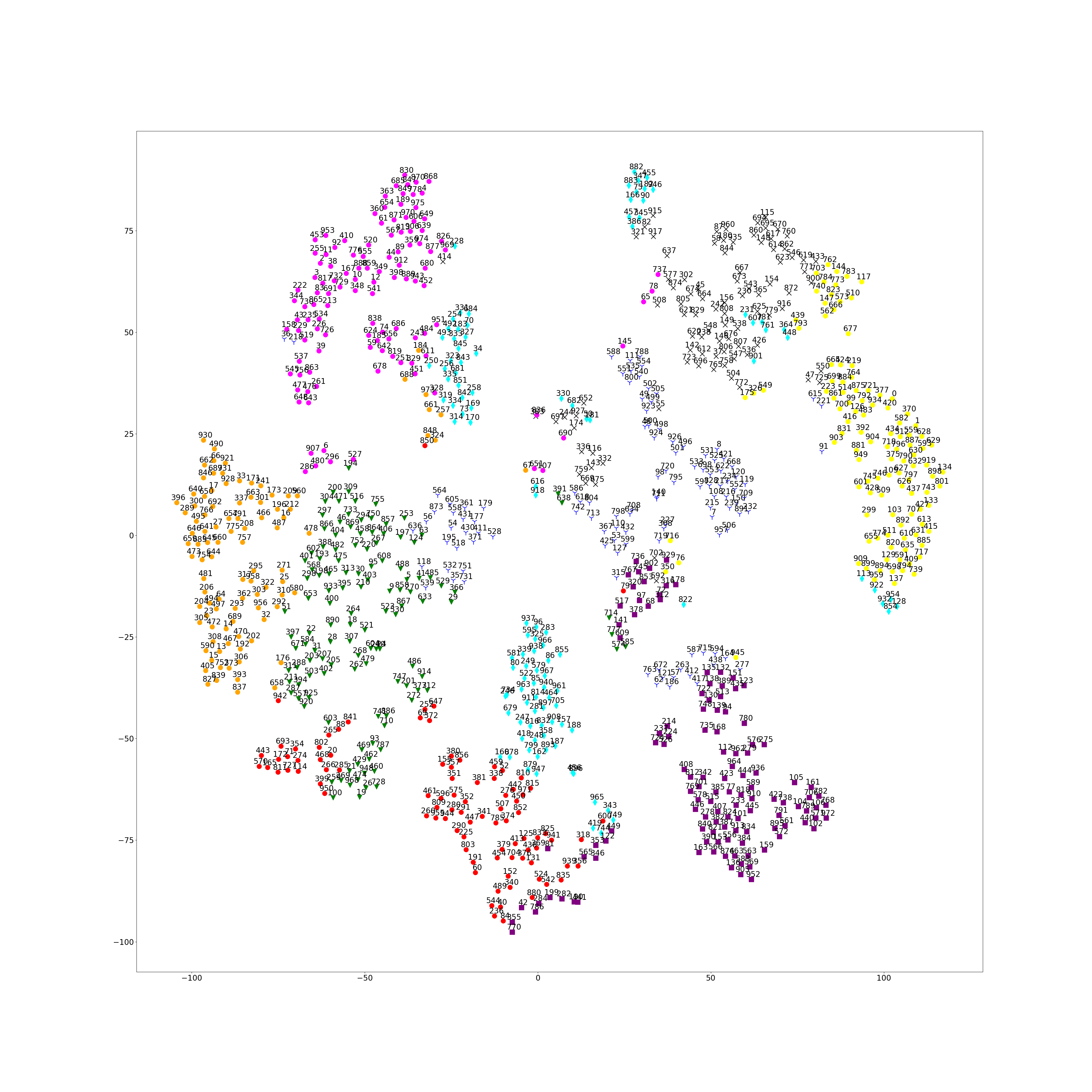
After clustering those papers, pick frequently used words in their title and abstract.
cluster[0] keywords: [question, over, representations, visual, vqa, scene, structure answering]
cluster[1] keywords: [feature, room, physics, optimization, semantic, transfer, layout, estimation]
cluster[2] keywords: [binary, local, lbc, convolutional_layer, cnn, linear, weights, savings, sparse, learnable]
cluster[3] keywords: [facial, wild, three_dimensional, texture, captured, morphable, new, datasets]
cluster[4] keywords: [quality, light, fields, light_field, dense, metrics, compression, reference, distorted]
cluster[5] keywords: [tracking, position, virtual, reality, commodity, vr, experience, infrastructure, infrared]
cluster[6] keywords: [tof, material, distortion, classification, depth, time, frequency, flight]
python find_paper_by_paper.py "Hyperspectral Image Super-Resolution via Non-Local Sparse Tensor Factorization" --c 5
Output:
Loaded 783 papers info.
Target: [ Hyperspectral Image Super-Resolution via Non-Local Sparse Tensor Factorization ]
5 Papers found ---
Score:4.10, [ Hyper-Laplacian Regularized Unidirectional Low-Rank Tensor Recovery for Multispectral Image Denoising ]
Abstract URL:http://openaccess.thecvf.com/content_cvpr_2017/html/Chang_Hyper-Laplacian_Regularized_Unidirectional_CVPR_2017_paper.html
PDF URL:http://openaccess.thecvf.com/content_cvpr_2017/papers/Chang_Hyper-Laplacian_Regularized_Unidirectional_CVPR_2017_paper.pdf
Score:5.33, [ A Non-Local Low-Rank Framework for Ultrasound Speckle Reduction ]
Abstract URL:http://openaccess.thecvf.com/content_cvpr_2017/html/Zhu_A_Non-Local_Low-Rank_CVPR_2017_paper.html
PDF URL:http://openaccess.thecvf.com/content_cvpr_2017/papers/Zhu_A_Non-Local_Low-Rank_CVPR_2017_paper.pdf
Score:6.36, [ Nonnegative Matrix Underapproximation for Robust Multiple Model Fitting ]
Abstract URL:http://openaccess.thecvf.com/content_cvpr_2017/html/Tepper_Nonnegative_Matrix_Underapproximation_CVPR_2017_paper.html
PDF URL:http://openaccess.thecvf.com/content_cvpr_2017/papers/Tepper_Nonnegative_Matrix_Underapproximation_CVPR_2017_paper.pdf
Score:6.76, [ Fractal Dimension Invariant Filtering and Its CNN-Based Implementation ]
Abstract URL:http://openaccess.thecvf.com/content_cvpr_2017/html/Xu_Fractal_Dimension_Invariant_CVPR_2017_paper.html
PDF URL:http://openaccess.thecvf.com/content_cvpr_2017/papers/Xu_Fractal_Dimension_Invariant_CVPR_2017_paper.pdf
Score:7.64, [ On the Global Geometry of Sphere-Constrained Sparse Blind Deconvolution ]
Abstract URL:http://openaccess.thecvf.com/content_cvpr_2017/html/Zhang_On_the_Global_CVPR_2017_paper.html
PDF URL:http://openaccess.thecvf.com/content_cvpr_2017/papers/Zhang_On_the_Global_CVPR_2017_paper.pdf
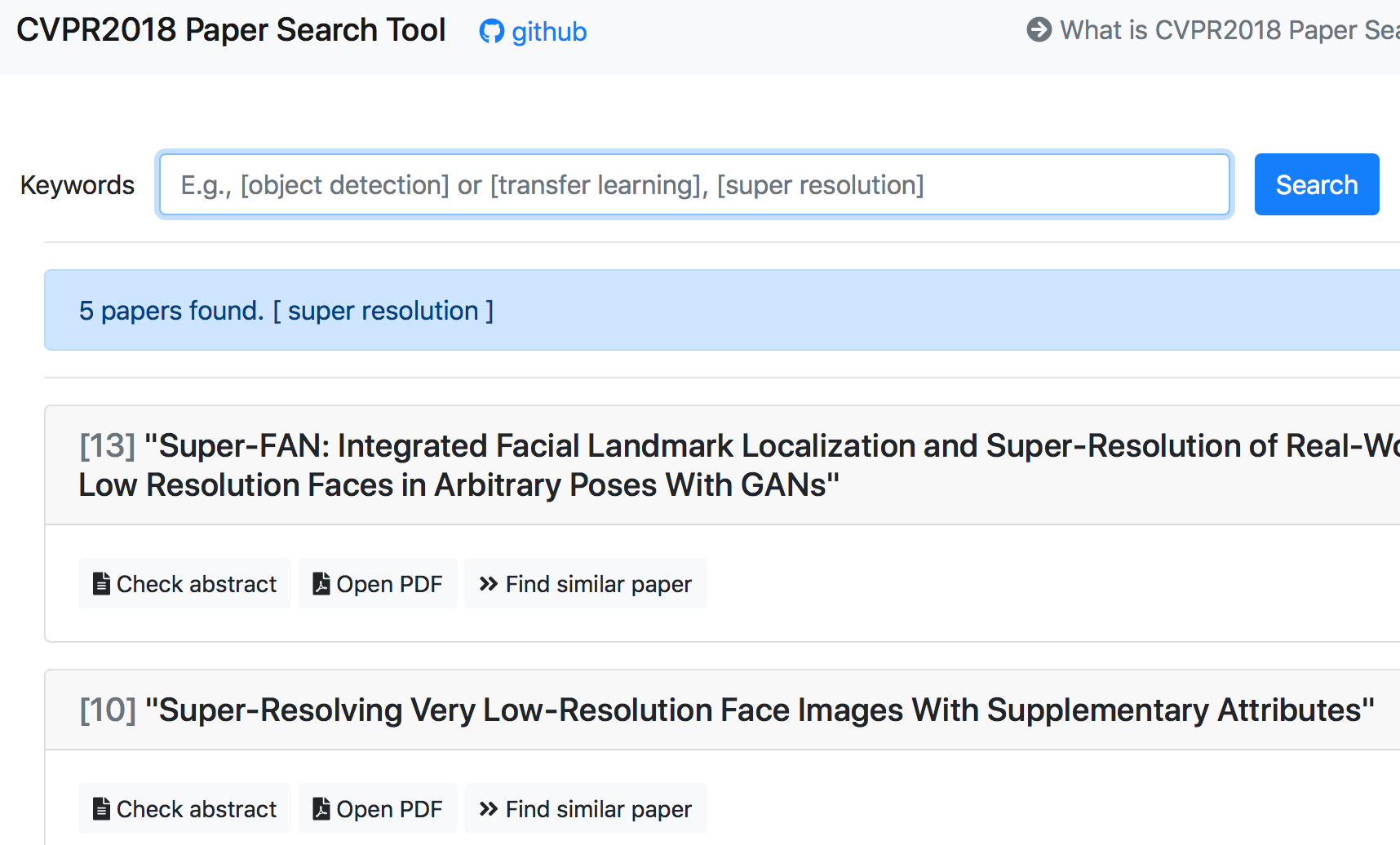
python find_paper_by_words.py super resolution -c 5
Loaded 783 papers info.
Keyword(s): ['super', 'resolution']
5 Papers found ---
Score:14, [ Hyperspectral Image Super-Resolution via Non-Local Sparse Tensor Factorization ]
Abstract URL:http://openaccess.thecvf.com/content_cvpr_2017/html/Dian_Hyperspectral_Image_Super-Resolution_CVPR_2017_paper.html
PDF URL:http://openaccess.thecvf.com/content_cvpr_2017/papers/Dian_Hyperspectral_Image_Super-Resolution_CVPR_2017_paper.pdf
Score:12, [ Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network ]
Abstract URL:http://openaccess.thecvf.com/content_cvpr_2017/html/Ledig_Photo-Realistic_Single_Image_CVPR_2017_paper.html
PDF URL:http://openaccess.thecvf.com/content_cvpr_2017/papers/Ledig_Photo-Realistic_Single_Image_CVPR_2017_paper.pdf
Score:9, [ Real-Time Video Super-Resolution With Spatio-Temporal Networks and Motion Compensation ]
Abstract URL:http://openaccess.thecvf.com/content_cvpr_2017/html/Caballero_Real-Time_Video_Super-Resolution_CVPR_2017_paper.html
PDF URL:http://openaccess.thecvf.com/content_cvpr_2017/papers/Caballero_Real-Time_Video_Super-Resolution_CVPR_2017_paper.pdf
Score:8, [ Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution ]
Abstract URL:http://openaccess.thecvf.com/content_cvpr_2017/html/Lai_Deep_Laplacian_Pyramid_CVPR_2017_paper.html
PDF URL:http://openaccess.thecvf.com/content_cvpr_2017/papers/Lai_Deep_Laplacian_Pyramid_CVPR_2017_paper.pdf
Score:7, [ Simultaneous Super-Resolution and Cross-Modality Synthesis of 3D Medical Images Using Weakly-Supervised Joint Convolutional Sparse Coding ]
Abstract URL:http://openaccess.thecvf.com/content_cvpr_2017/html/Huang_Simultaneous_Super-Resolution_and_CVPR_2017_paper.html
PDF URL:http://openaccess.thecvf.com/content_cvpr_2017/papers/Huang_Simultaneous_Super-Resolution_and_CVPR_2017_paper.pdf