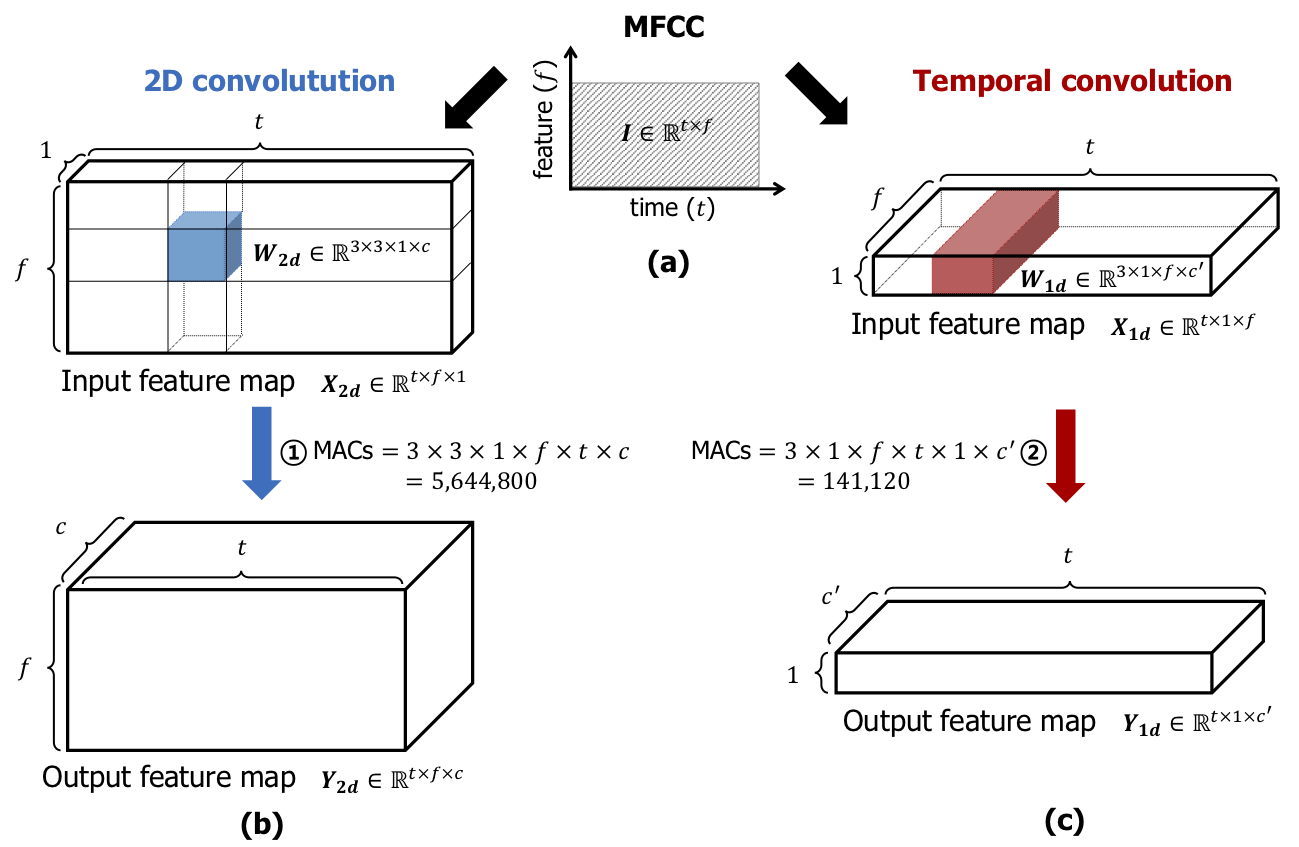
Keyword spotting (KWS) plays a critical role in enabling speech-based user interactions on smart devices. Recent developments in the field of deep learning have led to wide adoption of convolutional neural networks (CNNs) in KWS systems due to their exceptional accuracy and robustness. The main challenge faced by KWS systems is the trade-off between high accuracy and low latency. Unfortunately, there has been little quantitative analysis of the actual latency of KWS models on mobile devices. This is especially concerning since conventional convolution-based KWS approaches are known to require a large number of operations to attain an adequate level of performance.
In this paper, we propose a temporal convolution for real-time KWS on mobile devices. Unlike most of the 2D convolution-based KWS approaches that require a deep architecture to fully capture both low- and high-frequency domains, we exploit temporal convolutions with a compact ResNet architecture. In Google Speech Command Dataset, we achieve more than 385x speedup on Google Pixel 1 and surpass the accuracy compared to the state-of-the-art model. In addition, we release the implementation of the proposed and the baseline models including an end-to-end pipeline for training models and evaluating them on mobile devices.
- Python 3.6+
- Tensorflow 1.13.1
git clone https://github.com/hyperconnect/TC-ResNet.git
pip3 install -r requirements/py36-[gpu|cpu].txtFor evaluating the proposed and the baseline models we use Google Speech Commands Dataset.
Follow instructions in speech_commands_dataset/
Scripts to reproduce the training and evaluation procedures discussed in the paper are located on scripts/commands. After training a model, you can generate .tflite file by following the instruction below.
To train TCResNet8Model-1.0 model, run:
./scripts/commands/TCResNet8Model-1.0_mfcc_40_3010_0.001_mom_l1.sh
To freeze the trained model checkpoint into .pb file, run:
python freeze.py --checkpoint_path work/v1/TCResNet8Model-1.0/mfcc_40_3010_0.001_mom_l1/TCResNet8Model-XXX --output_name output/softmax --output_type softmax --preprocess_method no_preprocessing --height 49 --width 40 --channels 1 --num_classes 12 TCResNet8Model --width_multiplier 1.0
To convert the .pb file into .tflite file, run:
tflite_convert --graph_def_file=work/v1/TCResNet8Model-1.0/mfcc_40_3010_0.001_mom_l1/TCResNet8Model-XXX.pb --input_format=TENSORFLOW_GRAPHDEF --output_format=TFLITE --output_file=work/v1/TCResNet8Model-1.0/mfcc_40_3010_0.001_mom_l1/TCResNet8Model-XXX.tflite --inference_type=FLOAT --inference_input_type=FLOAT --input_arrays=input --output_arrays=output/softmax --allow_custom_ops
As shown in above commands, you need to properly set height, width, model, model specific arguments(e.g. width_multiplier).
For more information, please refer to scripts/commands/
Android Debug Bridge (adb) is required to run the Android benchmark tool (model/tflite_tools/run_benchmark.sh).
adb is part of The Android SDK Platform Tools and you can download it here and follow the installation instructions.
Run following command.
adb devicesYou should see similar output to the one below. The ID of a device will, of course, differ.
List of devices attached
FA77M0304573 device
Go to model/tflite_tools and place the TF Lite model you want to benchmark (e.g. mobilenet_v1_1.0_224.tflite) and execute the following command.
You can pass the optional parameter, cpu_mask, to set the CPU affinity CPU affinity
./run_benchmark.sh TCResNet_14Model-1.5.tflite [cpu_mask]If everything goes well you should see an output similar to the one below.
The important measurement of this benchmark is avg=5701.96 part.
The number represents the average latency of the inference measured in microseconds.
./run_benchmark.sh TCResNet_14Model-1.5_mfcc_40_3010_0.001_mom_l1.tflite 3
benchmark_model_r1.13_official: 1 file pushed. 22.1 MB/s (1265528 bytes in 0.055s)
TCResNet_14Model-1.5_mfcc_40_3010_0.001_mom_l1.tflite: 1 file pushed. 25.0 MB/s (1217136 bytes in 0.046s)
>>> run_benchmark_summary TCResNet_14Model-1.5_mfcc_40_3010_0.001_mom_l1.tflite 3
TCResNet_14Model-1.5_mfcc_40_3010_0.001_mom_l1.tflite > count=50 first=5734 curr=5801 min=4847 max=6516 avg=5701.96 std=210