|
| 1 | +**数据一致性应该如何维护?** |
| 2 | + |
| 3 | +分布式数据库系统:PBFT、Paxos、Gossip、Raft |
| 4 | + |
| 5 | +区块链系统:工作量证明:PoW,权益证明算法:PoS、DPoS |
| 6 | + |
| 7 | +# PBFT算法 |
| 8 | + |
| 9 | +PBFT(实用BFT算法)算法的提出主要是为了解决拜占庭将军问题。当两军作战时,如果有作恶节点的情况下,忠诚的将军如何保证消息的一致性。这个问题有解的条件是,在信道可靠的情况下,叛徒的数量不能大于等于所有将军数量的1/3。 |
| 10 | + |
| 11 | +Raft算法仅支持容错故障节点,但是对于PBFT算法而言除了容错故障还需要支持作恶节点。极端情况下,有f个问题节点和f个故障节点,问题节点f个被排除,剩下的正常节点需要比故障节点多一个,使得集群达成共识。所以,所有类型的节点数量加起来就是3f+1个。 |
| 12 | + |
| 13 | +## 1. 算法流程 |
| 14 | + |
| 15 | +PBFT算法的基本流程主要有以下四步: |
| 16 | + |
| 17 | +1. 客户端发送请求给主节点 |
| 18 | +2. 主节点广播请求给其它节点,节点执行PBFT算法的三阶段共识流程。 |
| 19 | +3. 节点处理完三阶段流程后,返回消息给客户端。 |
| 20 | +4. 客户端收到来自f+1个节点的相同消息后,代表共识已经正确完成。 |
| 21 | + |
| 22 | +**核心流程:** |
| 23 | + |
| 24 | +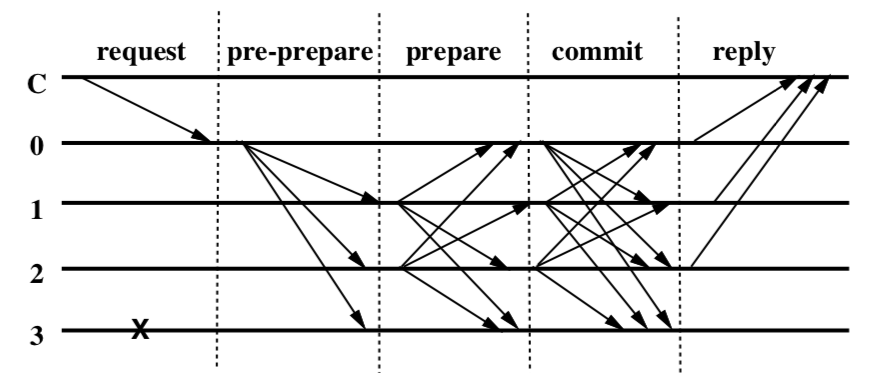 |
| 25 | + |
| 26 | +PBFT算法的核心三个阶段分别是pre-prepare阶段(预准备阶段),prepare阶段(准备阶段),commit阶段(提交阶段)。图中的C代表客户端,0,1,2,3代表节点的编号,打叉的3代表可能是故障节点或者是问题节点,这里表现的行为就是对其它节点的请求无响应。0是主节点。整个过程大致是: |
| 27 | + |
| 28 | +1. 首先,客户端向主节点发起请求,激活主节点的服务操作 |
| 29 | +2. 主节点0收到客户端请求,采用三阶段协议向从节点广播请求。主节点会向其它节点发送pre-prepare消息。 |
| 30 | + - **Pre-prepare阶段**:节点收到pre-prepare消息后,会有两种选择,一种是接受,一种是不接受。 |
| 31 | + - 一种典型的情况就是如果一个节点接到了一条pre-prepare消息,消息里的v和n在之前收到里的消息是曾经出现过的,但是d和m却和之前的消息不一致,或者请求编号不在高低水位之间,这时候就会拒绝请求。拒绝的逻辑就是主节点不会发送两条具有相同的v和n,但d和m却不同的消息。 |
| 32 | + - **Prepare阶段**:节点同意请求后会向其它节点发送prepare消息。这里要注意一点,同一时刻不是只有一个节点在进行这个过程,可能有n个节点也在进行这个过程。因此节点是有可能收到其它节点发送的prepare消息的。在一定时间范围内,如果收到超过2f个不同节点的prepare消息,就代表prepare阶段已经完成。 |
| 33 | + - **Commit阶段**:于是进入commit阶段。向其它节点广播commit消息,同理,这个过程可能是有n个节点也在进行的。因此可能会收到其它节点发过来的commit消息,当收到2f+1个commit消息后(包括自己),代表大多数节点已经进入commit阶段,这一阶段已经达成共识,于是节点就会执行请求,写入数据。 |
| 34 | +3. 处理完毕后,节点会返回消息给客户端。客户端等到f+1的相同的响应结果,则认为此次请求成功完成。 |
| 35 | + |
| 36 | +这就是PBFT算法的全部流程,三阶段分为`pre-prepare,prepare,commit`。 |
| 37 | + |
| 38 | +- `pre-prepare`和`prepare`阶段用于对在同一视图中发送的请求完全排序,即使提出请求排序的*primary*为虚假节点也是如此。 |
| 39 | +- `prepare`和`commit`阶段用于确保在视图之间对提交的请求进行完全排序 |
| 40 | + |
| 41 | +## 2. 和Raft算法的比较分析 |
| 42 | + |
| 43 | +| **对比点** | **Raft** | PBFT | |
| 44 | +| ------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | |
| 45 | +| 适用环境 | 私链 | 联盟链 | |
| 46 | +| 算法通信复杂度 | O(n),follower无需沟通 | O(n^2),节点之间通信 | |
| 47 | +| 最大故障和容错节点 | 故障节点:2f+1<=N | 容错节点:3f+1<=N | |
| 48 | +| 流程对比 | 1.谁先触发超时时间,获得半数以上的选票谁当选 2.从节点之间不交流,leader节点发的消息总是对的,除非宕机 | 1.按照编号依次作主节点 2.从节点之间交流,如果大多数人认为leader有问题会重新选举leader | |
| 49 | + |
| 50 | +## 3. 细节问题 |
| 51 | + |
| 52 | +### pfbt共识为什么至少需要3f+ 1个节点? |
| 53 | + |
| 54 | +最坏的情况,系统拜占庭节点为f个,由于消息到达顺序的问题,有可能f个有问题的节点先比f个正常的节点先返回消息,此时又要保证正确的消息比有问题的消息多,所以至少3f+ 1个节点 |
| 55 | + |
| 56 | +### pbft共识 parpare和commit 阶段为什么收到需要2f+ 1个相同的回复(包括自己的),f + 1个不行吗? |
| 57 | + |
| 58 | +某副本收到了f+ 1相同的消息反馈,如果这个f+ 1个反馈中包含faulty 节点,此时消息是不能作数的,因为faulty可能会发送错误消息给不同的节点,所以需要必须要2f+1个相同的反馈确认才能保证f+1个non-faulty节点正常,这时候即便f个faulty节点给不同人发不同消息也没关系,f+1个non-faulty节点已经形成了统一战线,他们在人数上已经多于那些墙头草了,可以达成一致了。 |
| 59 | + |
| 60 | +### pbft 共识 客户端为什么需要f + 1个节点的相同回复,f个不行吗? |
| 61 | + |
| 62 | +假设只需要从f个不同的节点那里拿到相同的reply,但我们不得不考虑一种情况,即这f个相同的reply全是来自f个faulty节点【系统中至多有f个faulty节点】。如果真是这样的话,很有可能客户端就得到错误的结果。因此为了进一步增强reply的可信度,我们需要来自不同节点的总计(f+1)个相同reply。多出的那一个可以作为对比! |
| 63 | + |
| 64 | +### pbft共识 为什么需要三阶段?去除掉commit阶段可以吗? |
| 65 | + |
| 66 | +假设我们去掉commit,所有节点收到2f+1(包括自己)的prepare之后就执行操作,会发生什么? |
| 67 | + |
| 68 | +其实如果顺利的话,即使有f个作恶节点,依然有f+1个正常节点所有节点都会收到正确的结果,最后所有的节点都能顺利的达成一致的结论。这样看来似乎我们完全不需要commit吗? |
| 69 | + |
| 70 | +但是如果主节点崩溃发生换主,其中只有一个或几个(不是大多数)已经收到了足够的prepare,其他节点因为网络原因没有收到本应该收到的足够多的prepare(异步网络环境没有任何通信保证,只有最终一定会收到的保证),那么那个执行了操作的节点就悲剧了,这个时候新主发起新一轮共识,sequence跟已经执行的操作一致,那个节点到底执行好还是不执行同样sequence的操作? |
| 71 | + |
| 72 | +那么commit是怎么做到的呢?假设节点收到足够多的prepare进入commit阶段,这个时候发生了一样的换主情形,由于节点还没执行,继续按照新一轮的流程走即可,这个时候sequence不变,但是view改变。 |
| 73 | + |
| 74 | +如果已经收到了足够的commit,并且已经执行了操作呢?仿佛陷入了prepare一样的地步…但是实际上因为要产生commit消息,说明2f+1个节点已经prepare了,换主的时候主会去搜集要重放的pre-prepare(2f+1个节点的,必然存在一个诚实节点并且有对应的pre-prepare),因此会把同样的digest对应的消息view改为自己重发一次,并且注意到commit只需要跟当前的view相同就可以接受,那么实际上commit是对view不敏感的。 |
| 75 | + |
| 76 | +简而言之,prepare锁定同一个view下的sequence,commit锁定sequence。 |
| 77 | + |
| 78 | +### 在一个节点数为N的节点中,诚实节点的数量是多少个? |
| 79 | + |
| 80 | +(non-faulty)=(2/3)*N+1 |
| 81 | + |
| 82 | +### CAP定理在pbft中是如何取舍的? |
| 83 | + |
| 84 | +PBFT算法将一致性(C)摆在首位,对可用性(A)作了妥协。一旦faulty节点的数量超过f,该系统就不能继续执行客户端的请求【系统会卡住,不能做写操作】。此外,分区容忍是必须要保证的。 |
| 85 | + |
| 86 | +### 设置waterline的目的是什么? |
| 87 | + |
| 88 | +假设主节点是坏的,它在给请求编号时故意选择了一个很大的编号,以至于超出了序号的范围,所以我们需要设置一个低水位(low water mark)h和高水位(high water mark)H,让主节点分配的编号在h和H之间,不能肆意分配 |
| 89 | + |
| 90 | +### PAREPARE 和commit阶段为什么需要保存消息在本地或者内存?PRE-PREPARE为什么不需要? |
| 91 | + |
| 92 | +保存消息的主要目的是为了方便viewChange的时候能够恢复消息,重新在新的view上达成共识。PRE-PREPARE阶段各节点还没有发送消息给对方,所以不需要保存。 |
| 93 | + |
| 94 | +### pbft通信时间复杂度是多少?如何计算的? |
| 95 | + |
| 96 | +因为需要三阶段共识,每个阶段各个节点之间都需要通信,所以通信量还是很大的。大概是$O(n^2)$ |
| 97 | + |
| 98 | +### 如果在commit阶段view change,会导致达成不了共识吗?会导致之前的view下的请求编号丢失吗? |
| 99 | + |
| 100 | +如果commit阶段viewchange,会保留之前commit阶段的请求,不会达成不了共识,也不会丢失请求编号 |
| 101 | + |
| 102 | +prepare阶段和commit阶段用来确保那些已经达到commit状态的请求即使在发生viewchange后在新的view里依然保持原有的序列不变,比如一开始在view 0中,共有req 0, req 1, req2三个请求依次进入了commit阶段,假设没有坏节点,那么这四个replicas即将要依次执行者三条请求并返回给Client。但这时主节点问题导致view change的发生,view 0 变成 view 1,在新的view里,原本的req 0, req1, req2三条请求的序列被保留,作数。那些处于pre-prepare和prepare阶段的请求在view change发生后,在新的view里都将被遗弃,不作数。 |
| 103 | + |
| 104 | +简单来说就是 如果每个节点都进入了commit阶段(这里要强调的是每个节点都进入这个commit阶段才算是整体进入了commit阶段),这时即使view change,也会保留之前的view里进入commit阶段的请求信息,view change会继续之前的commit阶段请求,不会再重新进入pre-prepare和prepare阶段。 |
| 105 | + |
| 106 | +## 参考文献 |
| 107 | + |
| 108 | +[深入剖析区块链的共识算法 Raft & PBFT](https://blog.51cto.com/u_14977574/2546916) |
| 109 | + |
| 110 | +[pbft共识算法](https://yp945.github.io/2019/07/09/consensus-pbft/) |
0 commit comments