diff --git a/CHANGELOG.md b/CHANGELOG.md
index 0792418..0f5b89d 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -1,4 +1,92 @@
# dbt-fabricspark Changelog
- This file provides a full account of all changes to `dbt-fabricspark`.
-## Previous Releases
+## 1.9.1rc2 (2024-12-31)
+
+### exprimental feature
+
+- Enable Python model, fixed [Issue #32](https://github.com/microsoft/dbt-fabricspark/issues/32), [get contact](mailto:willem.liang@icloud.com)
+ Usage
+
+ Create your pyspark model in dbt project, and implementation python function `model(dbt, session) -> DataFrame` in your model's code.
+ - [Release Note](https://www.getdbt.com/blog/introducing-support-for-python)
+ - [Document](https://docs.getdbt.com/docs/build/python-models)
+
+ Example:
+ ```python
+ # A udf to calculate distance between two coordinates
+ from coordTransform_py import coordTransform_utils # see also: https://github.com/wandergis/coordTransform_py
+ from geopy.distance import geodesic
+ from pyspark.sql.functions import udf
+ from pyspark.sql.types import DoubleType
+
+ @udf(DoubleType())
+ def udf_geo_distance(lng1,lat1,lng2,lat2,vendor1,vendor2):
+ wgs84_converters = {
+ 'baidu': coordTransform_utils.bd09_to_wgs84,
+ 'amap': coordTransform_utils.gcj02_to_wgs84,
+ 'tencent': lambda lng, lat: (lng, lat),
+ 'google': lambda lng, lat: (lng, lat)
+ }
+
+ convert1 = wgs84_converters.get(vendor1)
+ convert2 = wgs84_converters.get(vendor2)
+ # convert into WGS84
+ coord1 = tuple(reversed(convert1(lng1, lat1)))
+ coord2 = tuple(reversed(convert2(lng2, lat2)))
+ # calculate distance
+ distance = geodesic(coord1, coord2).meters
+ return distance
+
+ def model(dbt, session) -> DataFrame:
+ records = [
+ {
+ 'coord1_vendor':'amap',
+ 'coord1_addr':'Zhangjiang High-Tech Park',
+ 'coord1_lng':121.587691,
+ 'coord1_lat':31.201839,
+ 'coord2_vendor':'baidu',
+ 'coord2_addr':'JinKe Rd.',
+ 'coord2_lng':121.608551,
+ 'coord2_lat':31.210002
+ }
+ ]
+ souece_df = session.createDataFrame(records)
+
+ # Data processing BY RDD API or UDFs
+ final_df = souece_df.withColumn("distance",
+ udf_geo_distance(
+ souece_df["coord1_lng"],souece_df["coord1_lat"],
+ souece_df["coord2_lng"],souece_df["coord2_lat"],
+ souece_df["coord1_vendor"],souece_df["coord2_vendor"])
+ )
+ return final_df
+ ```
+  -
-
-
-
-
-
-[dbt](https://www.getdbt.com/) enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
-
-dbt is the T in ELT. Organize, cleanse, denormalize, filter, rename, and pre-aggregate the raw data in your warehouse so that it's ready for analysis.
-
-## dbt-fabricspark
-
-The `dbt-fabricspark` package contains all of the code enabling dbt to work with Synapse Spark in Microsoft Fabric. For more information, consult [the docs](https://docs.getdbt.com/docs/profile-fabricspark).
-
-## Getting started
-
-- [Install dbt](https://docs.getdbt.com/docs/installation)
-- Read the [introduction](https://docs.getdbt.com/docs/introduction/) and [viewpoint](https://docs.getdbt.com/docs/about/viewpoint/)
-
-## Running locally
-Use livy endpoint to connect to Synapse Spark in Microsoft Fabric. The binaries required to setup local environment is not possiblw with Synapse Spark in Microsoft Fabric. However, you can configure profile to connect via livy endpoints.
-
-Create a profile like this one:
-
-```yaml
-fabric-spark-test:
- target: fabricspark-dev
- outputs:
- fabricspark-dev:
- authentication: CLI
- method: livy
- connect_retries: 0
- connect_timeout: 10
- endpoint: https://api.fabric.microsoft.com/v1
- workspaceid: bab084ca-748d-438e-94ad-405428bd5694
- lakehouseid: ccb45a7d-60fc-447b-b1d3-713e05f55e9a
- lakehouse: test
- schema: test
- threads: 1
- type: fabricspark
- retry_all: true
-```
-
-### Reporting bugs and contributing code
-
-- Want to report a bug or request a feature? Let us know on [Slack](http://slack.getdbt.com/), or open [an issue](https://github.com/microsoft/dbt-fabricspark/issues/new).
-
-## Code of Conduct
-
-Everyone interacting in the Microsoft project's codebases, issue trackers, and mailing lists is expected to follow the [PyPA Code of Conduct](https://www.pypa.io/en/latest/code-of-conduct/).
-
-## Join the dbt Community
-
-- Be part of the conversation in the [dbt Community Slack](http://community.getdbt.com/)
-- Read more on the [dbt Community Discourse](https://discourse.getdbt.com)
-
-## Reporting bugs and contributing code
-
-- Want to report a bug or request a feature? Let us know on [Slack](http://community.getdbt.com/), or open [an issue](https://github.com/microsoft/dbt-fabricspark/issues/new)
-- Want to help us build dbt? Check out the [Contributing Guide](https://github.com/microsoft/dbt-fabricspark/blob/HEAD/CONTRIBUTING.md)
-
-## Code of Conduct
-
-Everyone interacting in the dbt project's codebases, issue trackers, chat rooms, and mailing lists is expected to follow the [dbt Code of Conduct](https://community.getdbt.com/code-of-conduct).
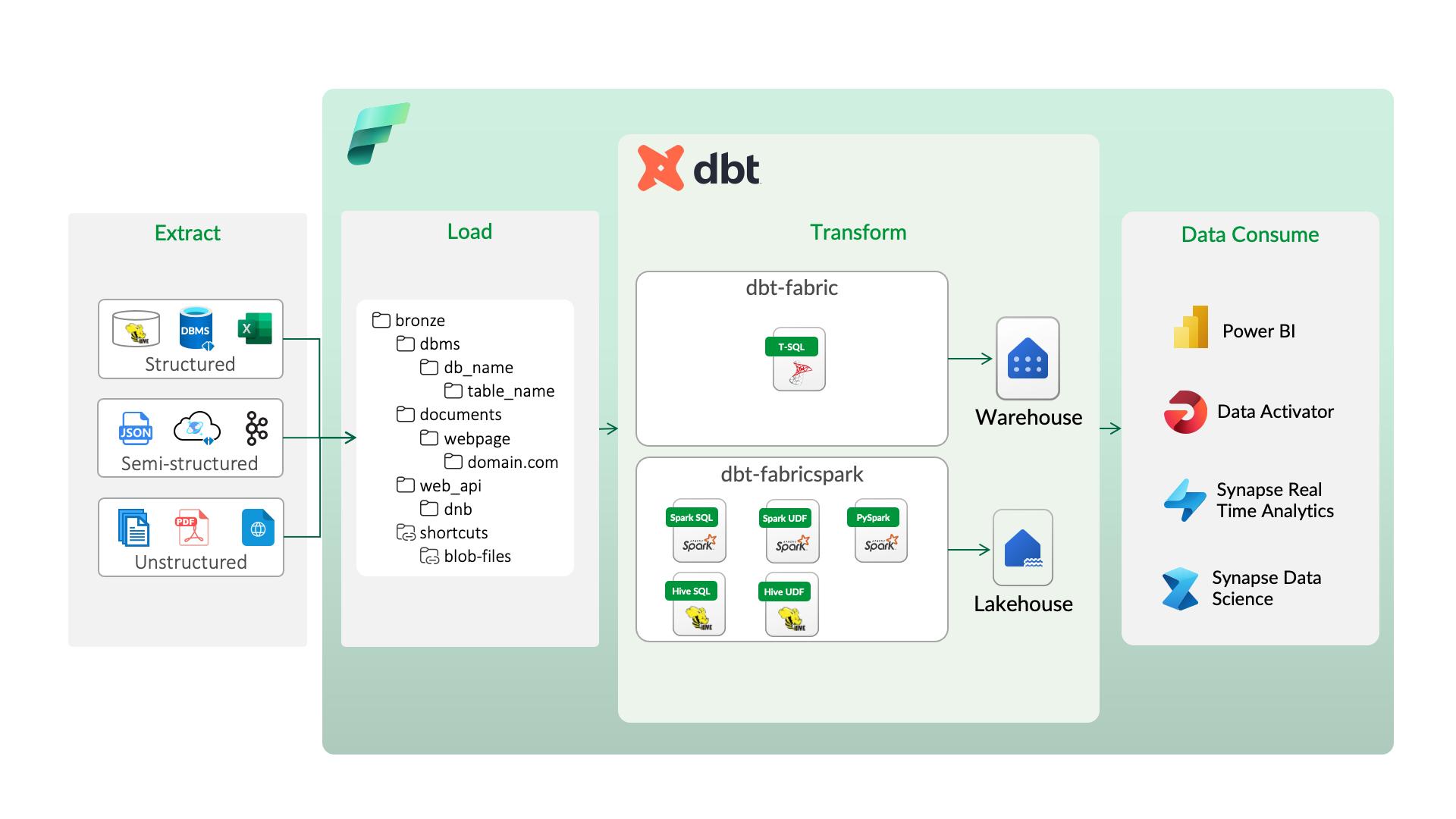
+# dbt-fabricspark
+
+dbt-FabricSpark is an adapter that connects dbt to Microsoft Fabric Lakehouse, featuring support for PySpark to enable efficient data processing and transformation.
+
+## Enhancements
+- **PySpark Support**: Run PySpark code within dbt to perform complex data transformations.
+- **Enhanced Functionality**: Bug fixes and optimizations for better compatibility with Microsoft Fabric Lakehouse.
+- **Seamless Integration**: Fully compatible with dbt’s existing workflow. (i.e. use the same dbt-core package to manage your warehouse and lakehouse.)
+
+[](https://www.bilibili.com/video/BV1jcQnYsEh3)
+*Click to play the video*
+
+## Quick Start
+
+This quick demo shows how to convert parent-child pairs into hierarchical path strings in Microsoft Fabric Lakehouse using a dbt project. In practical scenarios, it displays the hierarchical relationship of financial account structures (also known as COA, Chart of Accounts), such as `EBITDA > NOI > Revenue > Sales Income`. To simplify data representation, administrative data from Shanghai is used.
+
+**Input Data Example**
+
+| code | name |parent|
+|---------|----------|------|
+| 31| 上海市| null|
+| 3101| 市辖区| 31|
+| 310101| 黄浦区| 3101|
+|310101002|南京东路街道|310101|
+|310101013| 外滩街道|310101|
+| 310104| 徐汇区| 3101|
+|310104003| 天平路街道|310104|
+|310104004| 湖南路街道|310104|
+
+
+**Output Data Example**
+
+| code | name |parent| hierarchy_path |
+|---------|----------|------|----------------------------------|
+| 31| 上海市| null|上海市 |
+| 3101| 市辖区| 31|上海市 > 市辖区 |
+| 310101| 黄浦区| 3101|上海市 > 市辖区 > 黄浦区 |
+|310101002|南京东路街道|310101|上海市 > 市辖区 > 黄浦区 > 南京东路街道|
+|310101013| 外滩街道|310101|上海市 > 市辖区 > 黄浦区 > 外滩街道 |
+| 310104| 徐汇区| 3101|上海市 > 市辖区 > 徐汇区 |
+|310104003| 天平路街道|310104|上海市 > 市辖区 > 徐汇区 > 天平路街道 |
+|310104004| 湖南路街道|310104|上海市 > 市辖区 > 徐汇区 > 湖南路街道 |
+
+**Steps**
+
+1. Build & Install.
+
+ ```bash
+ # Build the dbt-fabricspark package.
+ cd script
+ make build
+ latest_built=$(ls -t dist/dbt_fabricspark_custom-*.whl | head -1)
+
+ # Install the dbt-fabricspark package into your Python virtual environment.
+ cd /path/to/your/working/directory
+ workdir=$(pwd)
+ # Create virtual environment
+ python -m venv --prompt dbt-fabricspark .dbt-fabricspark
+ echo "export PS1=\"(dbt-fabricspark) \h:\W \u\$ \"" >> .dbt-fabricspark/bin/activate
+ echo "export DBT_PROFILES_DIR=\"${workdir}/projects\"" >> .dbt-fabricspark/bin/activate
+ source .dbt-fabricspark/bin/activate
+
+ # Upgrade pip & Install dbt-fabricspark
+ python -m pip install --upgrade pip
+ python -m pip install ${latest_built}
+ ```
+
+ Preparing your project structure as below:
+ ```bash
+ .
+ ├── .dbt-fabricspark # Python virtual environment
+ └── projects # dbt project
+ ├── playground # demo project for Fabric Lakehouse
+ │ ├── dbt_project.yml # project config
+ │ ├── models
+ │ └── profile_template.yml
+ ├── jaffle_shop # demo project for Fabric Warehouse. Remove it if you won't to use it.
+ │ ├── LICENSE
+ │ ├── README.md
+ │ ├── dbt_project.yml # project config
+ │ ├── etc
+ │ ├── logs
+ │ ├── models
+ │ ├── seeds
+ │ └── target
+ └── profiles.yml # dbt profiles
+ ```
+
+
+2. Configure: Update your `profiles.yml` with Microsoft Fabric Lakehouse credentials.
+
+ ```yaml
+ flags:
+ partial_parse: true
+ # dbt-fabricspark project, Fabric Lakehouse Spark Endpoint(via Livy)
+ playground:
+ target: fabricspark-dev
+ outputs:
+ fabricspark-dev:
+ authentication: CLI
+ method: livy
+ connect_retries: 0
+ connect_timeout: 1800000
+ endpoint: https://api.fabric.microsoft.com/v1
+ workspaceid: the-workspaceid-within-livy-endpoint # replace with yours
+ lakehouseid: the-lakehouseid-within-livy-endpoint # replace with yours
+ lakehouse: dl_playground
+ schema: dbo
+ threads: 1
+ type: fabricspark
+ retry_all: true
+ ```
+
+3. Create Models: Define PySpark models in .py files within the `project/playground/models/` directory.
+
+ test_pyspark_model.py
+
+ ```python
+ import pandas as pd
+ from pyspark.sql import DataFrame
+ from pyspark.sql.types import ArrayType, StringType
+ from io import StringIO
+
+ def generate_data(sparkSession)->DataFrame:
+ tree = '31:上海市#$01:市辖区#%01:黄浦区#|002:南京东路街道#|013:外滩街道#|015:半淞园路街道#|017:小东门街道#|018:豫园街道#|019:老西门街道#|020:五里桥街道#|021:打浦桥街道#|022:淮海中路街道#|023:瑞金二路街道#%04:徐汇区#|003:天平路街道#|004:湖南路街道#|007:斜土路街道#|008:枫林路街道#|010:长桥街道#|011:田林街道#|012:虹梅路街道 #|013:康健新村街道#|014:徐家汇街道#|015:凌云路街道#|016:龙华街道#|017:漕河泾街道#|103:华泾镇#|501:漕河泾新兴技术开发区#%05:长宁区#|001:华阳路街道#|002:江苏路街道#|004:新华路街道#|005:周家桥街道#|006:天山路街道#|008:仙霞新村街道#|009:虹桥街道#|010:程家桥街道#|011:北新泾街道#|102:新泾镇#%06:静安区#|006:江宁路街道#|011:石门 二路街道#|012:南京西路街道#|013:静安寺街道#|014:曹家渡街道#|015:天目西路街道#|016:北站街道#|017:宝山路街道#|018:共和新路街道#|019:大宁路街道#|020:彭浦新村街道#|021:临汾路街道#|022:芷江西路街道#|101:彭浦镇#%07:普陀区#|005:曹杨新村街道#|014:长风新村街道#|015:长寿路街道#|016:甘泉路街道#|017:石泉路街道#|020:宜川路街道#|021:万 里街道#|022:真如镇街道#|102:长征镇#|103:桃浦镇#%09:虹口区#|009:欧阳路街道#|010:曲阳路街道#|011:广中路街道#|014:嘉兴路街道#|016:凉城新村街道#|017:四川北路街道#|018:北外滩街道#|019:江湾镇街道#%10:杨浦区#|001:定海路街道#|006:平凉路街道#|008:江浦路街道#|009:四平路街道#|012:控江路街道#|013:长白新村街道#|015:延吉新村街道#|016: 殷行街道#|018:大桥街道#|019:五角场街道#|020:新江湾城街道#|021:长海路街道#%12:闵行区#|001:江川路街道#|006:古美街道#|008:新虹街道#|009:浦锦街道#|101:莘庄镇#|102:七宝镇#|103:颛桥镇#|106:华漕镇#|107:虹桥镇#|108:梅陇镇#|110:吴泾镇#|112:马桥镇#|114:浦江镇#|501:莘庄工业区#%13:宝山区#|003:友谊路街道#|007:吴淞街道#|008:张庙街道 #|101:罗店镇#|102:大场镇#|103:杨行镇#|104:月浦镇#|106:罗泾镇#|109:顾村镇#|111:高境镇#|112:庙行镇#|113:淞南镇#|501:宝山工业园区#%14:嘉定区#|001:新成路街道#|002:真新街道#|004:嘉定镇街道#|102:南翔镇#|103:安亭镇#|106:马陆镇#|109:徐行镇#|111:华亭镇#|114:外冈镇#|118:江桥镇#|401:菊园新区#|501:嘉定工业区#%15:浦东新区#|004: 潍坊新村街道#|005:陆家嘴街道#|007:周家渡街道#|008:塘桥街道#|009:上钢新村街道#|010:南码头路街道#|011:沪东新村街道#|012:金杨新村街道#|013:洋泾街道#|014:浦兴路街道#|015:东明路街道#|016:花木街道#|103:川沙新镇#|104:高桥镇#|105:北蔡镇#|110:合庆镇#|114:唐镇#|117:曹路镇#|120:金桥镇#|121:高行镇#|123:高东镇#|125:张江镇#|130:三林 镇#|131:惠南镇#|132:周浦镇#|133:新场镇#|134:大团镇#|136:康桥镇#|137:航头镇#|139:祝桥镇#|140:泥城镇#|141:宣桥镇#|142:书院镇#|143:万祥镇#|144:老港镇#|145:南汇新城镇#|401:芦潮港农场#|402:东海农场#|403:朝阳农场#|501:中国(上海)自由贸易试验区(保税片区)#|502:金桥经济技术开发区#|503:张江高科技园区#%16:金山区#|001:石化街道#|1 01:朱泾镇#|102:枫泾镇#|103:张堰镇#|104:亭林镇#|105:吕巷镇#|107:廊下镇#|109:金山卫镇#|112:漕泾镇#|113:山阳镇#|503:上海湾区高新技术产业开发区#%17:松江区#|001:岳阳街道#|002:永丰街道#|003:方松街道#|004:中山街道#|005:广富林街道#|006:九里亭街道#|102:泗泾镇#|103:佘山镇#|104:车墩镇#|105:新桥镇#|106:洞泾镇#|107:九亭镇#|109:泖 港镇#|116:石湖荡镇#|117:新浜镇#|120:叶榭镇#|121:小昆山镇#|501:松江工业区#|504:佘山度假区#|507:上海松江出口加工区#%18:青浦区#|001:夏阳街道#|002:盈浦街道#|003:香花桥街道#|102:朱家角镇#|103:练塘镇#|104:金泽镇#|105:赵巷镇#|106:徐泾镇#|107:华新镇#|109:重固镇#|110:白鹤镇#%20:奉贤区#|001:西渡街道#|002:奉浦街道#|003:金海街道#| 101:南桥镇#|102:奉城镇#|104:庄行镇#|106:金汇镇#|109:四团镇#|111:青村镇#|118:柘林镇#|123:海湾镇#|503:海湾旅游区#%51:崇明区#|101:城桥镇#|102:堡镇#|103:新河镇#|104:庙镇#|105:竖新镇#|106:向化镇#|107:三星镇#|108:港沿镇#|109:中兴镇#|110:陈家镇#|111:绿华镇#|112:港西镇#|113:建设镇#|114:新海镇#|115:东平镇#|116:长兴镇#|201: 新村乡#|202:横沙乡#|401:前卫农场#|402:东平林场#|501:上实现代农业园区'
+ data=['code,name,parent']
+ p=['']*4
+ for node in tree.split('#'):
+ i = '$%|'.find(node[0])+1
+ [k,v] = node.strip('$%|').split(':')
+ p[i]=k
+ data.append(''.join(p[:i+1])+f",{v},"+''.join(p[:i]))
+
+ csv_content = '\n'.join(data)
+ pandas_df = pd.read_csv(StringIO(csv_content),dtype=str)
+ spark_df = sparkSession.createDataFrame(pandas_df)
+ return spark_df
+
+ def find_hierarchy_path(linked_list:ArrayType, target_node:StringType)->ArrayType(StringType()):
+ result = []
+ visited = set()
+ next_node = target_node
+
+ map_dict = {}
+ for item in linked_list:
+ map_dict.update(item)
+
+ while next_node in map_dict and next_node not in visited:
+ result.append(next_node)
+ visited.add(next_node)
+ next_node = map_dict.get(next_node)
+
+ return result
+
+ def reverse_array(input:ArrayType)->ArrayType(StringType()):
+ return input[::-1]
+
+ def model(dbt, session) -> DataFrame:
+ spark_df = generate_data(session)
+ spark_df.show()
+
+ stg_table="stg_prop_city_dist"
+ lakehouseName="dl_playground"
+ spark_df.createOrReplaceTempView(stg_table)
+
+ session.udf.register("find_hierarchy_path", find_hierarchy_path, ArrayType(StringType()))
+ session.udf.register("reverse_array", reverse_array, ArrayType(StringType()))
+
+ sql_stmt = f"""
+ select
+ code
+ ,name
+ ,parent
+ ,regexp_replace(concat_ws(' > ', reverse_array(find_hierarchy_path(nodes, code_name))),'[0-9]*::', '') as hierarchy_path
+ from (
+ select
+ cur.code
+ ,cur.name
+ ,concat(cur.code, '::', cur.name) as code_name
+ ,cur.parent
+ ,collect_list(
+ map(
+ concat(cur.code, '::', cur.name)
+ ,case when parent.code is null or cur.parent is null or lower(trim(cur.parent)) = 'null'
+ then concat(cur.code, '::', cur.name)
+ else concat(parent.code, '::', parent.name)
+ end)
+ ) OVER () as nodes
+ from {stg_table} as cur
+ left join {stg_table} as parent
+ on cur.parent = parent.code
+ ) tbl
+ """
+ final_df = session.sql(sql_stmt)
+ return final_df
+ ```
+