Previous common practices of diffusion models (e.g., stable diffusion models) used U-Net backbone, which lacks scalability. DiT is a new class diffusion models based on transformer architecture. The authors designed Diffusion Transformers (DiTs), which adhere to the best practices of Vision Transformers (ViTs) [1]. It accepts the visual inputs as a sequence of visual tokens through "patchify", and then processed the inputs by a sequence of transformer blocks (DiT blocks). The structure of DiT model and DiT blocks is shown below:
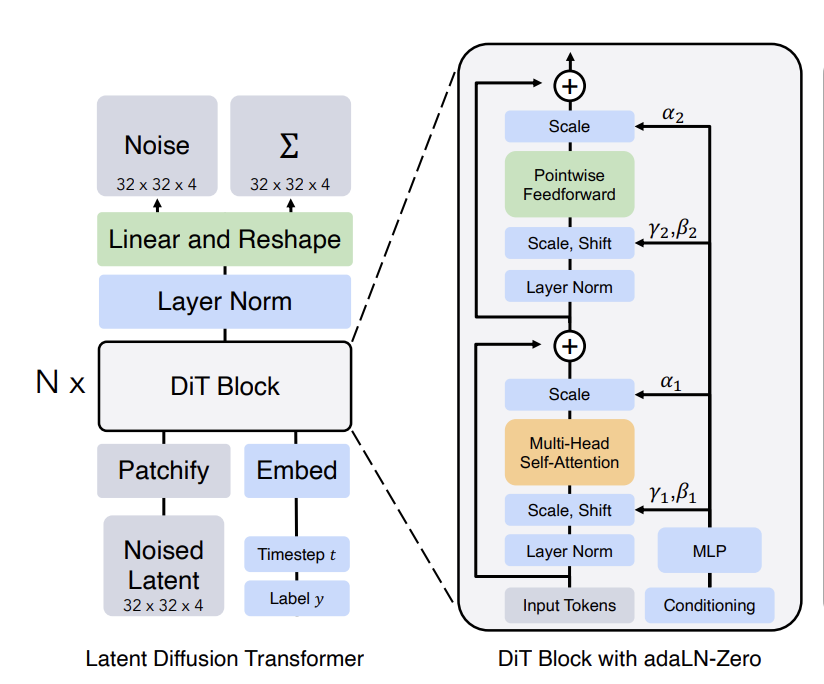
Figure 1. The Structure of DiT and DiT blocks. [2]
DiTs are scalable architectures for diffusion models. The authors found that there is a strong correlation between the network complexity (measured by Gflops) vs. sample quality (measured by FID). In other words, the more complex the DiT model is, the better it performs on image generation.
In this tutorial, we will introduce how to run inference and finetuning experiments using MindONE.
pip install -r requirements.txt
We refer to the official repository of DiT for pretrained checkpoints downloading. Currently, only two checkpoints DiT-XL-2-256x256 and DiT-XL-2-512x512 are available.
After downloading the DiT-XL-2-{}x{}.pt file, please place it under the models/ folder, and then run tools/dit_converter.py. For example, to convert models/DiT-XL-2-256x256.pt, you can run:
python tools/dit_converter.py --source models/DiT-XL-2-256x256.pt --target models/DiT-XL-2-256x256.ckptIn addition, please download the VAE checkpoint from huggingface/stabilityai.co, and convert this VAE checkpoint by running:
python tools/vae_converter.py --source path/to/vae/ckpt --target models/sd-vae-ft-mse.ckptAfter conversion, the checkpoints under models/ should be like:
models/
├── DiT-XL-2-256x256.ckpt
├── DiT-XL-2-512x512.ckpt
└── sd-vae-ft-mse.ckptTo run inference of DiT-XL/2 model with the 256x256 image size on Ascend devices, you can use:
python sample.py -c configs/inference/dit-xl-2-256x256.yamlTo run inference of DiT-XL/2 model with the 512x512 image size on Ascend devices, you can use:
python sample.py -c configs/inference/dit-xl-2-512x512.yamlTo run the same inference on GPU devices, simply set --device_target GPU for the commands above.
By default, we run the DiT inference in mixed precision mode, where amp_level="O2". If you want to run inference in full precision mode, please set use_fp16: False in the inference yaml file.
For diffusion sampling, we use same setting as the official repository of DiT:
- The default sampler is the DDPM sampler, and the default number of sampling steps is 250.
- For classifier-free guidance, the default guidance scale is
$4.0$ .
If you want to use DDIM sampler and sample for 50 steps, you can revise the inference yaml file as follows:
# sampling
sampling_steps: 50
guidance_scale: 4.0
seed: 42
ddim_sampling: TrueSome generated example images are shown below:












Now, we support finetuning DiT model on a toy dataset imagenet_samples/images/. It consists of three sample images randomly selected from ImageNet dataset and their corresponding class labels. This toy dataset is stored at this website. You can also download this toy dataset using:
bash scripts/download_toy_dataset.shAfterwards, the toy dataset is saved in imagenet_samples/ folder.
To finetune DiT model conditioned on class labels on Ascend devices, use:
python train.py --config configs/training/class_cond_finetune.yamlYou can adjust the hyper-parameters in the yaml file:
# training hyper-params
start_learning_rate: 5e-5 # small lr for finetuning exps. Change it to 1e-4 for regular training tasks.
scheduler: "constant"
warmup_steps: 10
train_batch_size: 2
gradient_accumulation_steps: 1
weight_decay: 0.01
epochs: 3000After training, the checkpoints will be saved under output_folder/ckpt/.
To run inference with a certain checkpoint file, please first revise dit_checkpoint path in the yaml files under configs/inference/, for example,
# dit-xl-2-256x256.yaml
dit_checkpoint: "outputs/ckpt/DiT-3000.ckpt"
Then run python sample.py -c config-file-path.
You can start the distributed training with ImageNet dataset format using the following command
export MS_ASCEND_CHECK_OVERFLOW_MODE="INFNAN_MODE"
mpirun -n 4 python train.py \
-c configs/training/class_cond_train.yaml \
--dataset_path PATH_TO_YOUR_DATASET \
--use_parallel Truewhere PATH_TO_YOUR_DATASET is the path of your ImageNet dataset, e.g. ImageNet2012/train.
For machine with Ascend devices, you can also start the distributed training using the rank table. Please run
bash scripts/run_distributed.sh path_of_the_rank_table 0 4 path_to_your_datasetto launch a 4P training. For detail usage of the training script, please run
bash scripts/run_distributed.sh -h[1] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2020. 1, 2, 4, 5
[2] W. Peebles and S. Xie, “Scalable diffusion models with transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4195–4205, 2023