November 2020
tl;dr: Best practice to scale single-stage object detector. EfficientNet for Yolov4.
The paper is not as well written as the original Yolov4 paper. This paper follows the methodology of EfficientNet.
From this review on Zhihu it looks like Scaled-YOLOv4 is heavily based on YOLOv5.
- When input image size is increased, we must increase depth or stages of the network. Best practice is to follows the steps:
- scale up the "size of image + #stages"
- scale up depth and width according to required inference time
- Once-for-all network
- Train one Yolov4-Large network, and drop the later stages for efficiency during inference.
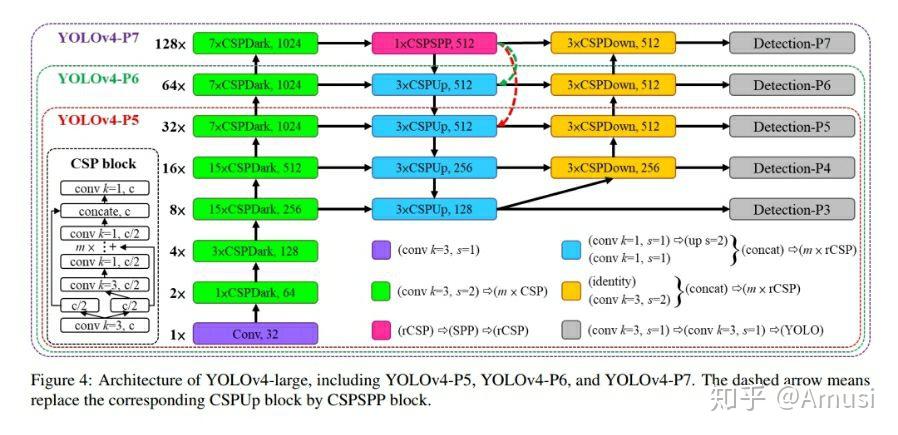
- It uses OSA (one shot aggregation) idea from VoVNet. Basically instead of aggregating/recycling features at every stage, OSA proposes to aggregate the features only once at the end. source

- Code on github