make ordinal regression great again #5066
Replies: 10 comments 8 replies
-
|
I now see that there is now an |
Beta Was this translation helpful? Give feedback.
-
|
Maybe I am missing something, but couldn't you get the second parametrization by just fixing the first cutpoint to zero? Is there something wrong with this?: with pm.Model():
sd = pm.HalfNormal("group_sd")
raw = pm.ZeroSumNormal("group_raw", dims="group")
group_effect = pm.Deterministic("group_effect", sd * raw, dims="group")
age_effect = pm.Normal("age_effect")
# Add intercept if we constrain the sum of cutpoints to 0, or set the first cutpoint to 0.
mu = (
group_effect[group_idx]
+ age_effect * data["age"]
)
# I don't like this prior. We should maybe investigate distributions
# on ordered sets that optionally sum to zero or start at zero?
cutpoints = pm.Normal("cutpoints", mu=[-1,1], sigma=10, shape=2,
transform=pm.distributions.transforms.ordered)
pm.OrderedLogistic("z", eta=mu, cutpoints=cutpoints, observed=data["observation"])You need to make sure though that you only add an intercept to the model if the cutpoints have only n-1 degrees of freedom. So maybe something like this? with pm.Model():
intercept = pm.Normal("intercept", sigma=10)
sd = pm.HalfNormal("group_sd")
raw = pm.ZeroSumNormal("group_raw", dims="group")
group_effect = pm.Deterministic("group_effect", sd * raw, dims="group")
age_effect = pm.Normal("age_effect")
# Add intercept if we constrain the sum of cutpoints to 0, or set the first cutpoint to 0.
mu = (
intercept
+ group_effect[group_idx]
+ age_effect * data["age"]
)
cutpoints_raw = at.concatenate([
np.zeros(1),
pm.Dirichlet("cutpoints_raw_upper", a=np.ones(n_observation_groups - 1))
])
# If I don't misunderstand something larger sigma should indicate that we are very sure about
# our predictions based on mu?
sigma = pm.HalfNormal("sigma")
pm.OrderedLogistic("z", eta=sigma * mu, cutpoints=sigma * cutpoints_raw, observed=data["observation"]) |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @aseyboldt I'm just double checking... multiplying the |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @aseyboldt My only problem so far is constraining the cutpoints: If you have time, I've got a notebook on this here https://github.com/drbenvincent/ordinal-regression/blob/main/ordinal%20logistic%20regression.ipynb. It's Model 3 which involves the constraint on cutpoints which ends up failing. |
Beta Was this translation helpful? Give feedback.
-
|
Should be |
Beta Was this translation helpful? Give feedback.
-
|
Hmm. Looking again, it looks like it's a bad initial value problem. Setting start values works! with model:
trace = pm.sample(return_inferencedata=True, start={"cutpoints_raw_upper": np.array([0.1, 0.2, 0.3])}) |
Beta Was this translation helpful? Give feedback.
-
|
Ok. So we've made progress in that the issue is not about parameterisation of That said, as @aseyboldt mentioned, some consideration to the priors could be given. I've worked up a notebook using the very latest v4 code, with The basic issue seems to be how you deal with too many degrees of freedom. We have The method that Krushcke uses is to constrain the lower and upper outpoints. A PyMC implementation is here but this is old and clunky and doesn't utilise initial = np.arange(K-1-2)+2.5
print(initial)
with pm.Model() as model:
cutpoints = at.concatenate([
np.ones(1)*1.5,
pm.Uniform("cutpoints_unknown", lower=1+0.5, upper=K-0.5, shape=K-1-2), # transform=pm.distributions.transforms.ordered),
np.ones(1)*(K-0.5)
])
mu = pm.Normal('mu', mu=K/2, sigma=K)
sigma = pm.HalfNormal("sigma", 1)
pm.OrderedProbit("y_obs", cutpoints=cutpoints, eta=mu, sigma=sigma, observed=y)
trace = pm.sample(start={"cutpoints_unknown": initial})
az.plot_trace(trace, var_names=["cutpoints_unknown", "mu", "sigma"]);
plt.tight_layout()The posteriors are sensible in terms of their values, but we have major divergence issues I tried the approach outlined by @aseyboldt, which is to fix the first outpoint to zero, and use a Dirichlet distribution for the unknown outpoints. I think this then has a total of K-1 degrees of freedom because the Dirichlet will sum to 1? initial = np.linspace(0.1, 0.9, K-2)
print(initial)
with pm.Model() as model:
cutpoints = at.concatenate([
np.zeros(1),
pm.Dirichlet("cutpoints_unknown", a=np.ones(K - 1 - 1))
])
mu = pm.Normal('mu', mu=K/2, sigma=K)
sigma = pm.HalfNormal("sigma", 1)
pm.OrderedProbit("y_obs", cutpoints=cutpoints, eta=mu, sigma=sigma, observed=y)
trace = pm.sample(start={"cutpoints_unknown": initial})
# pm.model_to_graphviz(model)
az.plot_trace(trace, var_names=["cutpoints_unknown", "mu", "sigma"]);
plt.tight_layout()Again, OK inferences in terms of numerical values, but still crazy divergence issues. I'd be grateful for pointers:
If I've left out any important details, see here for full notebook example. EDIT: Wrapping the Dirichlet variables in with pm.Model() as model:
cutpoints = at.concatenate([
np.zeros(1),
at.extra_ops.cumsum(pm.Dirichlet("cutpoints_unknown", a=np.ones(K - 1 - 1)))
])
mu = pm.Normal('mu', mu=K/2, sigma=K)
sigma = pm.HalfNormal("sigma", 1)
pm.OrderedProbit("y_obs", cutpoints=cutpoints, eta=mu, sigma=sigma, observed=y)
trace = pm.sample(start={"cutpoints_unknown": initial})
az.plot_trace(trace, var_names=["cutpoints_unknown", "mu", "sigma"]);
plt.tight_layout()But the posteriors over unknown outpoints are suspect
|



Beta Was this translation helpful? Give feedback.
-
|
Finally got a handle on this! The last version above actually works fine. By ordering the Dirichlet distributed unknown outpoints we have resolved the issue with divergences, but the problem was that the posteriors looks bad (very high overlap). But this is a non-problem when we remember about the thresholds being correlated with each other... see DBDA by Kruschke for more info. Looking at marginal posterior distributions for the outpoints is misleading. |

Beta Was this translation helpful? Give feedback.
-
|
Created an issue, proposing a new distribution which would be very useful here #5215 |
Beta Was this translation helpful? Give feedback.
-
|
https://journals.sagepub.com/doi/full/10.1177/2515245918823199 |
Beta Was this translation helpful? Give feedback.
-
|
https://mc-stan.org/docs/2_23/stan-users-guide/ordered-logistic-section.html |
Beta Was this translation helpful? Give feedback.
-
|
@drbenvincent I just posted to the Discourse forums about the Kruschke-style ordered probit model here before actually seeing this thread and your latest notebook. The approaches are very similar. |
Beta Was this translation helpful? Give feedback.
-
|
Hi everyone - joining this thread late after struggling hard with ordinal data! I've been working through the examples above as well as @drbenvincent's great notebooks to try and get a handle on things, but I am still very confused. I'm looking to use the same approach Kruschke uses in DBDA2 to estimate the latent mean and scale of an ordinal set of data to do some inferences on that. I've been using I've been using the following parameterisation (forgive hard-coding of values) which results in relatively sensible estimates (but not of the mean), but with severe divergences, and requires starting values to not crash: `
Using the
I'm probably missing something fundamental here about Any pointers are massively appreciated from this struggling Bayesian 🙏🏻 |
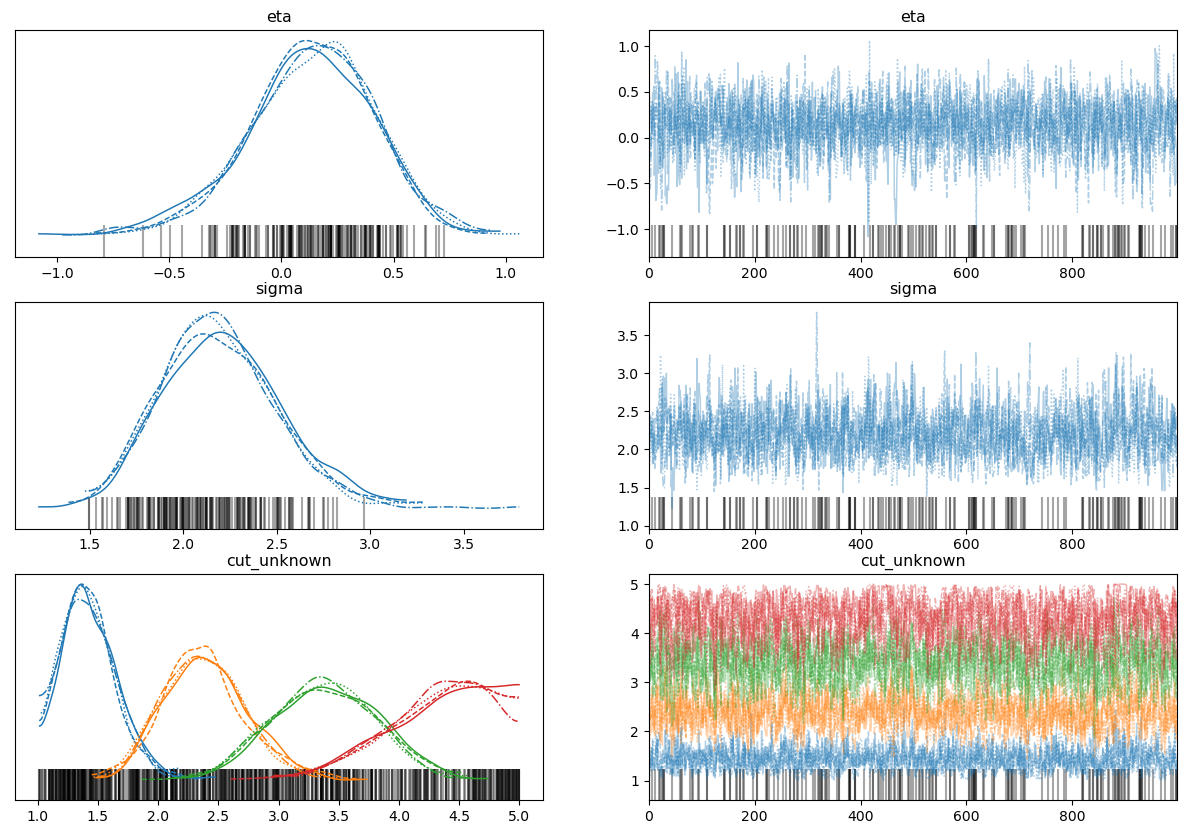
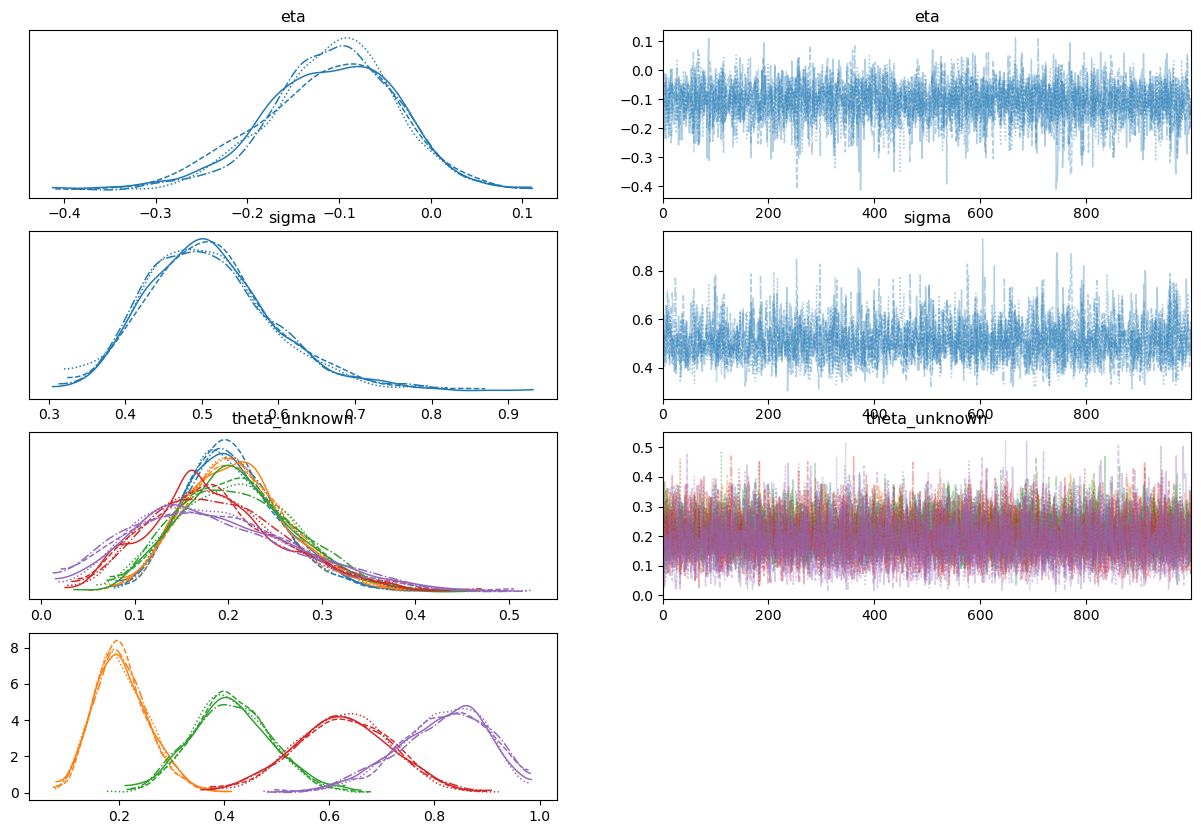
Beta Was this translation helpful? Give feedback.
-
|
Hi @alexjonesphd. Just a quick reply for the moment... The cutoff parameters have to be ordered. The uniform won't give you that, so that's one red flag I can see with a quick inspection. |
Beta Was this translation helpful? Give feedback.
-
|
Will have a play with that, of course! Thank you. |
Beta Was this translation helpful? Give feedback.
-
|
Getting a bit of a handle on this and realised something of a basic mistake on my part. I'm still a bit vague on the use of the I guess for most purposes this doesn't matter too much. If the goal is to compare latent distributions to one another the relative difference is important, but I can imagine there are maybe some situations were it would be important to estimate the latent parameters on the precisely observed units of the data, which |
Beta Was this translation helpful? Give feedback.
-
|
You should be able to transform the constrained uniform to the scale you want. That's what the |
Beta Was this translation helpful? Give feedback.
-
|
Ah - I will try and work with that and see what I get, I hadn't tried to play with those! I responded over on the Discourse too - probably safer for confused people like me to keep discussion there as suggested. Thank you! |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
I have been exploring ordinal regression modelling, and I've found that it's not as simple as it could/should be from a modeller's perspective.
Probit regression
If we want to do probit regression (which assumes a normally distributed latent variable) then we have a PyMC implementation of DBDA by Kruschke here. This turns out to require some jumping through hoops, see...
There are further examples in that notebook about how you can use this approach in a regression context with metric predictors. This is fine, but you are stuck with an API/model which is not very clean. The modeller has to jump through a lot of hoops.
So this might make you think how we could use the
OrderedLogisticdistribution with Logit models instead...Ordered Logit
Current parameterisation
Going Logit (rather than Probit) is promising, because we can define simple models like this (taken from the docstring of
OrderedLogistic...However I was hoping to run ordinal regression in a regression context where I could estimate regression coefficients for predictor variables. However, it seems that parameterisation of

$c_{1.5}, c_{2.5}$ on the scale of the data (x) and sigma.
OrderedLogisticis not set up for this. For example, as far as I can tell, it seems to most closely match the parameterisation of eq15.8 from Regression and Other Stories by Gelman, Hill & Vehtari. That is, for an example with 3 categories (2 cut points), the model specification isSo it is basically estimating cutpoints
A better(?) parameterisation
This might be very useful in some contexts, but it is not very useful in a GLM/regresion context. In this case it would be nicer if there as an alternative parameterisation (see eq 15.9 from Regression and Other Stories)

Note that the first cutpoint is now constrained to be zero and the of the Logistic is constrained to be 1, and we have additional regression coefficients alpha and beta.
Questions
OrderedLogisticdistribution in a GLM context?Beta Was this translation helpful? Give feedback.
All reactions