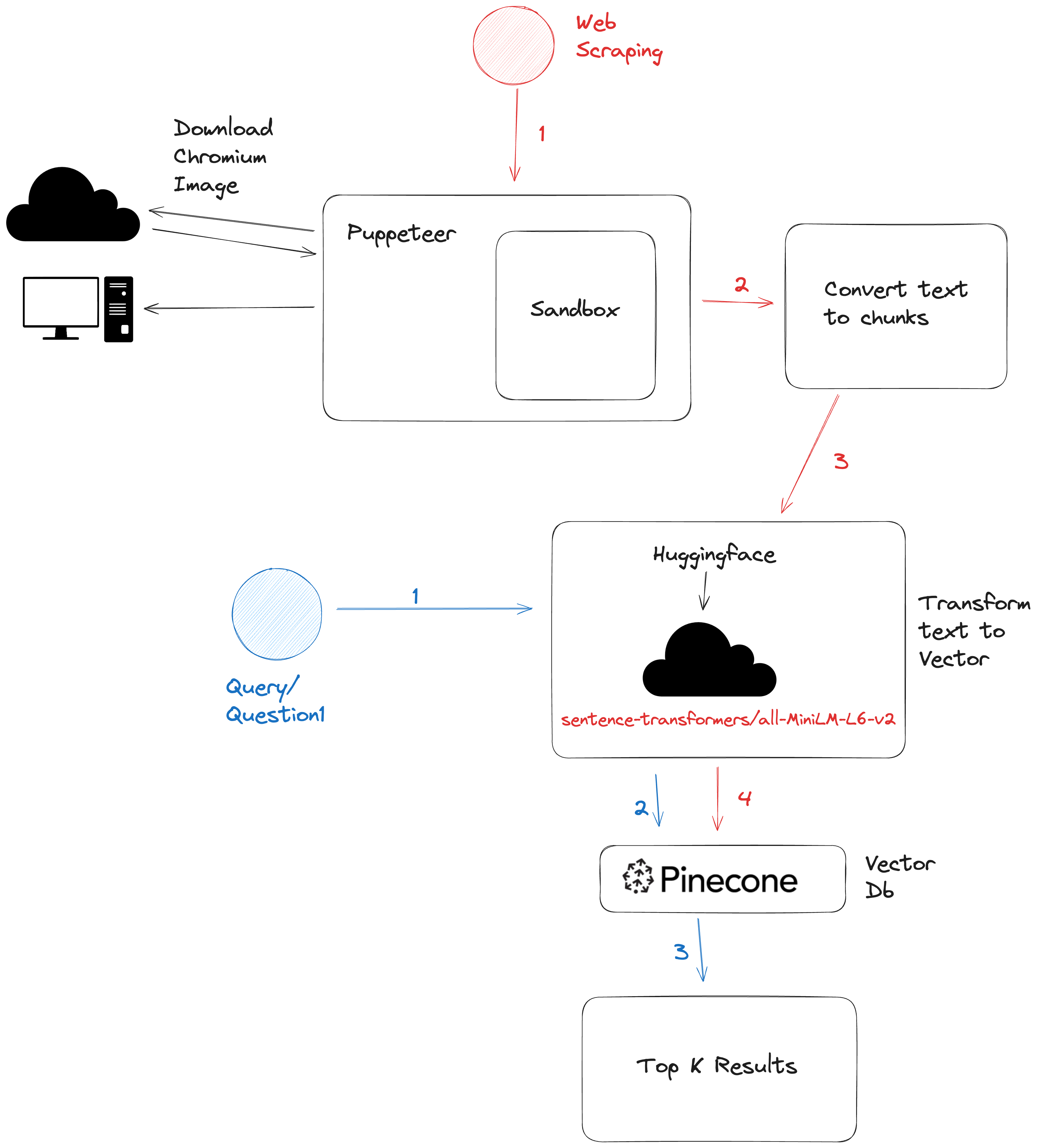
Web scraper powered by Puppeteer and Pinecone DB as Vector DB.

- UI flow is tested for a happy path. There will be some bugs available.
- Refer
.env.examplefile for example env variables - Service is based on Next.js 13 and deployed using Render. Due to limitations of free tier of Render, it suffers from cold start issues. Usually takes 1 minute to start after certain inactivity period.
- Model to convert text to vectors: sentence-transformers/all-MiniLM-L6-v2
- Live link
- We don't have an active high volume storage available in Free Tier accounts. That's why we're downloading chromium build at runtime.
- Easiest deployment solution is Vercel. But due to recent changes in Free Tier, we can't run Puppeteer. There are Network Bandwidth limitations and Vercel has a timeout of 10 seconds.
- Render is another free option. It gives a free machine to run web services, but suffers from cold start or spin down after a while. Also, suffers from random server crash.
https://scrapifyx.onrender.com/
- You will need huggingface and pineconedb api keys, refer
.env.examplefor env keys.
$ npm i
$ npm run dev
$ npm i
$ npm build
$ npm start
- Trigger web scraping
curl --location 'https://scrapifyx.onrender.com/api' \
--header 'content-type: application/json' \
--data '{"url":"https://www.britannica.com/plant/plant"}'
- Ask questions
curl --location 'https://scrapifyx.onrender.com/question' \
--header 'content-type: application/json' \
--data '{"question":"how does protein work?"}'
id|values|metadata
- Keeping the design simple and straightforward.
- id: Identifier of the object. Should be an auto-increment number or uuid. I made a mistake of putting encoded urls under id.
- values: This is where you'll keep your vector data. Working with vector databases and learning more about it, I understood vector dbs are more optimised to query vectors. One key thing they have is indexes over these vectors and a lot more. Refer this article to learn more: https://www.pinecone.io/learn/vector-database/
- metadata: Now, this is where you will store metadata of your vectors like some content or path location.
metadata: {
loc: <value>
pageContent: <value>
textPath: <value>
}
- metadata.loc: stores url of scraping website.
- metadata.pageContent: splitted chunks of text stored in raw string format. Good to have, since we need to show the text after query.
- metadata.txtPath: contains page title of that website.
- Querying strategy: As mentioned in
General Architecture, questions are converted to vectors embeddings. Using those vector embeddings, we query our vector db (Pinecone DB) w/ questions vector embeddings to find similar results (also known as Top K). Behind the scenes we are doing a dot product ofvector(question) . vector(db record)and trying to find the top related results.
- Keep a snapshot in cache of scraped website. Avoid multiple web scraping triggers within a small time period. This is a complete usecase specific thing.
- Better exception handing w/ error classes and show relevant api response from api handlers. Provides better code readability.
- Instead of relying on 3rd party api for vector embedding generation, use a locally cached model to optimise for query performance. This can't be done for existing deployment due to space and hardware limitations.
- Random UI issues w/ changing screen size. Handled for common mobile and desktop size.
- Mention in UI to ask short questions and limit to vector embedding model's token length.
- Ability to scrape pages in depth. Depth 0: url, Depth 1: href or side links, Depth 2 and so one.
- April 9, 2024: Less frequent downtime at page load. Thanks to ping on render from @UptimeRobot