Replies: 5 comments 22 replies
-
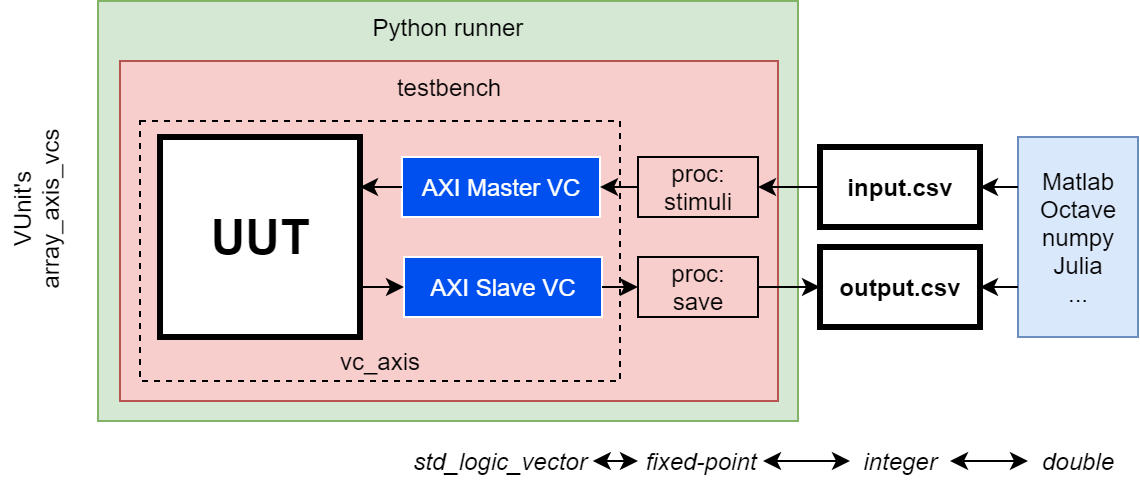
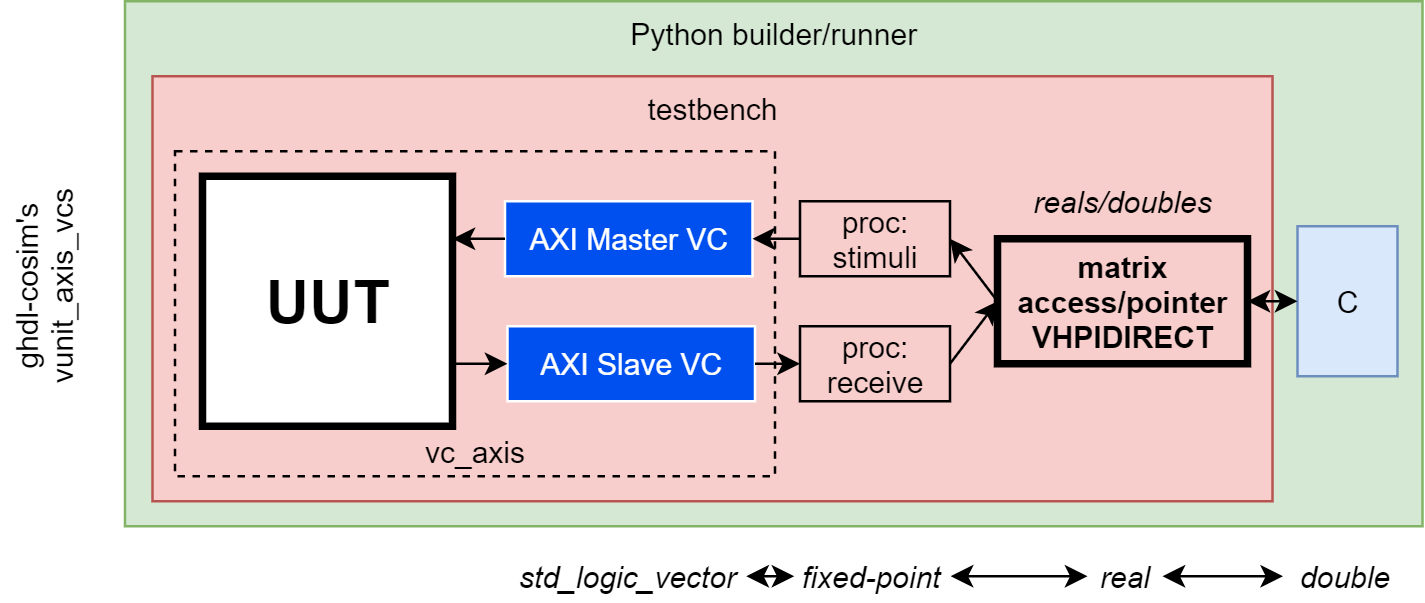
AXI StreamThe AXI Stream loopback example available in VUnit's repository (https://github.com/VUnit/vunit/tree/master/examples/vhdl/array_axis_vcs/src) is an AXI Stream slave connected to an AXI Stream master through a FIFO. That is used as a foundation for any streaming DSP processing, by placing custom logic either before, after or in-between the FIFO. Say, for instance a CORDIC component (either pipelined or iterative, since I/O are async/FIFO). I believe that example is interesting because I've used it for didactic/demo purposes in other open source project documentation sites and in academia/research. For instance, in https://ghdl.github.io/ghdl-cosim/vhpidirect/examples/arrays.html#array-and-axi4-stream-verification-components it is modified for using direct cosimulation as an alternative to CSV files for sharing data with foreign functions/tools. For didactic purposes too, VHDL's fixed_generic_pkg is used. That is further related to dbhi/vboard. The same example was used in DBHI: towards decoupled functional hardware-software co-design on SoCs. 28th ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA 2020). It's the same architecture, but a Dynamic Binary Modification tool is used for replacing a function call in a binary application (without access to the sources). Yet, as you see, that is all related to simulation/cosimulation and to testing the accelerator itself through Verification Components. Synthesis is not covered/documented in any open source repo (yet). When using MicroBlaze, having AXI Stream accelerators is quite nice. They used to have these Fast Simplex Link (FSL) interfaces (https://www.xilinx.com/support/documentation/sw_manuals/mb_ref_guide.pdf) which were then replaced with Stream Link Interfaces (https://www.xilinx.com/support/documentation/sw_manuals/xilinx2018_2/ug984-vivado-microblaze-ref.pdf). Same software framework in both cases: specific ASM instructions for writing/reading to/from some specific registers, which are mapped to the hardware "Links", i.e. AXI Stream ports. On Zynq, that's slightly uglier. There is no built-in AXI Stream between the hard ARM cores and the Programmable Logic (PL). Therefore, a DMA or an AXI-Lite to Stream bridge needs to be used. Not a huge deal, but a whole source of potential bugs and configuration issues when one wants to just test some software and some accelerator together. NEORV has a Wishbone component, which is labeled as en External bus of type Wishbone b4 or AXI4-Lite. I assume it is a single master port to be connected to some interconnect, in case multiple external peripherals are added. Therefore, the integration would need to be similar to the Zynq. However, since RISC-V is suppossed to be easy to extend, open, and because NEORV32 is also open, I wonder if we can do better. @stnolting, what do you think? Can we provide a configurable number of "Links" which 1) can be of type out only, in only or "instantiate" one of each; 2) are mapped in the CPU memory; and 3) are usable through specific instructions? I guess it is a two stage question. The first one is adding a configurable number of links. The second one is whether it's worth having specific instruction for that. I must say I know nothing specific about RISC-V and CPU architecture is not my field. Please, excuse me if I'm making some stupid assumptions. For now, I'm not concerned about performance, but about having a solution which is as simple as technically possible. It is meant for students to understand the whole system, CPU, interface and Core. That's why AXI-Lite to Stream bridges or DMAs are not desirable as the first use case. That should addressed after they are familiar with the most simple Stream/FIFO interface (which is otherwise pretty common in low-level RTL). |
Beta Was this translation helpful? Give feedback.
-
I think this is the most common use case of soft-core CPUs: Orchestrating a custom system instead of doing all the work.
I am familiar with AXI4 stream but I have never really used it. As the name already suggests, it is used for streaming data to feed things converters / encryption units / data interfaces and so on. But how do you configure these devices? For example if you have a programmable CORDIC unit, how do you configure the actual function? Do you really use the "side band" channel for this?
Correct.
1. 2. 3.
Or do we need a specific control and status register for each link (to check if data is available and to check if we can send new data). If we do so, then I do not see a real advantage here. A Wishbone/AXI4-Lite to AXI-stream converter would then be the better choice.
From my point of view, AXI-stream without a dedicated DMA is not more or less performant as the normal AXI4-Lite interface. However, it would provide a different type of interface that might be better suited for some kinds of applications. So I'm open for this idea 👍 But again, using an AXI-lite-to-AXI-stream converter does also seem to be a valid solution 🤔 |
Beta Was this translation helpful? Give feedback.
-
Sorry, I forgot about that. |
Beta Was this translation helpful? Give feedback.
-
It is! However, since I do research, the scope is slightly wider. We target implementation of complex and data-intensive real-time and high-performance applications in the edge. Moving data, or having places where to place data temporarily becomes a really expensive resource. It might not be affordable to have some additional DMA and it might be too expensive to implement certain operators in hardware. In such cases, we need a CPU which is slightly more complex than a simple uC, so that it can perform some pre/post processing without being a bottleneck. On the other hand, when we are using a large device for prototyping but we did not have time for implementing some stage/operator/component in hardware yet, having a simple uC with FIFO/Stream I/O is very valuable for doing behaviour prototyping of the system in hardware. The idea is that each of the blocks in the system can be written either in C or in VHDL, and it can be either simulated or implemented. Therefore, this request is also for using dozens of NEORV32 instances as functional black-boxes, mostly ignoring the whole SoC except the very specific interfaces of that submodule/component. From a visual point of view, imagine that each of the blocks in umarcor.github.io/hwstudio can have an architecture defined in C. Not HLS, but automatic instantiation of some soft CPU which executes the C source you wrote. Same ports and same behaviour as a "real" HDL architecture, but a completely different implementation. For simulation purposes, we ignore the soft CPUs, we do that with cosimulation (as shown in the diagrams below), using Verification Components (that's why we want to use Wishbone/AXI/UART...). For testing in hardware, we use the CPUs. Whenever a "hardware" architecture is ready, the user changes it in the diagram and hits simulation/implementation again. I got a lot of problems when explaining this workflow/methodology. Most people understand I'm talking about HLS or any other kind of automatic source transformation. It has nothing to do with that. I want to write both C and VHDL manually, because SoC design is an art I love. However, I don't want to wait until everything is synthesisable VHDL in order to be able to test the whole system. I want an iterative methodology that allows testing all the mixed software-hardware-nonsynth-synth variants that a developer writes when designing a SoC from scratch. GHDL, VUnit, containers, MSYS2, CI, Octave, Python/numpy, etc. all of that composes the infrastructure for making that vision possible with open source tooling only. As you might guess, that's a lot of people from many different places, each with their own priorities and interests. It takes a lot of time to understand and then being able to help each other. That's why I say I'm a hitchhiker in the open-source electronic design automation (EDA) galaxies 😆.
A FIFO is basically an AXI4 Stream slave connected to an AXI4 Stream master. You use the empty/full signals from the FIFO as the ready/valid signals of the AXI4 Streams: https://github.com/VUnit/vunit/blob/master/examples/vhdl/array_axis_vcs/src/axis_buffer.vhd#L60-L84. That is ignoring the usage of STRB, TLAST, and other signals. However, I guess you get the basic idea about what it's used for.
AXI defines how bytes are transferred, not the meaning of the bytes. So, for example, you can decide to convert an AXI-Lite to an AXI Stream by sending address first and then data. Or using a wide word including both the address and the data. However, the concept is that you don't use Streams if you need addressable content. Yet, you can use specific "commands" in the stream, which the receiver can interpret. I believe there are specific (optional) signals which you can use for that. But it's not different from just widening your word size, thus, having some additional bits for encoding the opcodes. Widening the word size is something you can only do if you design all the cores. When you use, e.g., Vivado you are forced to some widths (say 32 bits), because multiples of bytes are the "reasonable solution. That's why AXI specifies additional optional signals, but it is explained that they are handled together with the data signal (same valid/registering/behaviour). With regard to the CORDIC unit, it's a tradeoff:
Furthermore, CORDIC(s) can be iterative or pipelined. If pipelined, AXI Streams can receive one data element each clock cycle. Otherwise, it needs to wait until the previous computation is done. This completely modifies the criteria for selecting the options above. This is also what makes Verification Components and virtual queues so valuable. You can protoype all those strategies using VHDL but without actually describing the hardware (writing single process architectures with "push" and "pop" procedures/functions). After you evaluate which is the best solution for an specific application/use case, your can keep all the interface structure/architecture and make the VHDL synthesisable. You can use C/C++ threads, golang channels, Python queues or some other "fancier" environment such as Simulink for that high-level modelling. However, it makes all sense if the final target is precisely describing a SoC in VHDL.
This is the same discussion we are having in #9. Let's solve it there 😉
Yes. In the most basic solution, the software writes to the same register again and again, and each write generates a transaction. By the same token, after a value is received, it's read and the interface is ready for receiving a new value. Obviously, this is a very simplistic description, and you already pointed out additional requirements:
I'm not specifically interested in TDEST, TSTRB, TUSER, etc. yet. I'm good with them being unused or fixed for now. However, I guessed you wanted an overall view of what might be needed.
Yes. However, if TDEST is supported, it might be handy to hide that complexity from the user. Say it has 4 bits, users could use a single statement for writing to an specific channel or reading from it. So, Alternatively, it can be done in C, by providing a function with two arguments, and using two instructions instead of one. However, reading and setting specific fields by masking each of them can reduce performance y we add TLAST, TSTRB, TUSER, etc. So, rather than asking about "an specific instruction" the question is what is the recommended software-hardware approach for a reasonable solution. Does it make sense to provide additional addresses for writing/reading specific fields, which do "hardware masking" of the same register? That is, add some area to the module, for reducing the software overhead. Personally, I don't need the custom instructions. To me, it's enough with having a data register and a configuration register for each Stream interface. And it's enough with a single master and a single slave. I prefer having that well implemented (with LAST, STRB, DEST, USER, etc. and with nice to use software), than having lots of interfaces with less features. I'm willing to understand whether something can be achieved which is better than using an intermediate AXI-Lite interconnect and bridge.
The user should check the flag before writing. Otherwise, yes, I guess it's an exception. Strictly, the user might overwrite the value in the register before it's sent, but then it's not possible to know whether the old or the new one was sent. In AXI terminology, the slave is not busy, it's said it is not ready (just inverse logic). Well, at the moment, I'm not sure whether it's the master or the slave the one that is forced not to wait for the other. That's part of the specification. If a FIFO is used, the need of an additional flag depends on how long chunks you want to support. See above.
A system composed of AXI Stream components is, by definition, a systolic array. That is, if a single component cannot receive/send whatever it needs to, the whole system is stalled. Therefore, if the CPU receives an item, the READY flag is unset. No other values can be received. It is up to the user to decide whether the system needs to be blocked or if the flag can be set again (no need to read the data, although doing it might be easier than setting the flag). It is also up to the user to add FIFOs wherever they need, given the topology of their system. I don't think it's intuitive that the AXI component discards the data and sets an overrun flag. That could potentially silently drop hundreds/thousands of items. By concept, if the CPU wants to decide when to handle and when to drop data, then it wants to be the master in the communication. It'd better use an AXI-Lite (probably with 1-2 registers/addresses) which connects to a bridge where the overrun flag is handled. Conversely, if an (stream) slave interface is used, the CPU is expected to respond with an acceptable delay. Attending the interrupt (or pooling) should be prioritary. Overall, I think that supporting a FIFO is interesting for dealing with multiple channels (TDEST) and/or supporting chunk copies. But that should be an optional and relatively very simple to implement enhancement, after the software-stream is implemented.
As commented, if an optional FIFO is used, or if the user adds it, memcpy can be used. That allows copying large chunks of data as fast as the CPU can handle. Hence, the interface, the interconnect and the slave need to support the throughput. Using AXI Stream interconnects and slaves, the CPU is likely to be the limit. However, AXI-Lite is a bidirectional interface. Therefore, area and maximum frequency are to be affected. Sure, if there is a single external AXI-Lite slave, and that is an Stream, most of the signals from the AXI-Lite interface can be ignored and optimised. However, if an interconnect is used and at least another slave is connected which needs read/write, the additional logic for dealing with the "stream" won't always be optimised.
I guess it's a matter of how the traffic is prioritised. Having AXI-Lite and AXI Stream interfaces makes an statement about expecting two subnets, one addressable low-throughput and one non-addressable high-performance. If AXI-Lite is provided only, users can emulate that by customising the interconnect for prioritising the AXI-Lite-to-Stream bridge over other slaves. However, having an open source interconnect with configurable priority might not be straightforward. I guess a sensible approach is to write a "2 x n x 32 bit register to AXI master and from AXI slave" component. Then, evaluate the performance by wrapping it in an "32 bit AXI-Lite to 2 x n register" module. Last, try mapping the register control signals to the CPU. As you might understand due to my explanation above, I have some internal inconsistencies because I'm thinking about both using a single NEORV32 as the main orchestrator, and using lots of instances as black-box modules. Hence, there is some friction with regard to having to instantiate an interconnect and a bridge, or not. When it's used as an orchestrator, interconnects will be required anyway, so having a few levels of hierarchy there is ok. In the other user case, the most compact and easy to use, the best. Please, excuse me if this dicotomy makes some explanations blurry. |
Beta Was this translation helpful? Give feedback.
-
请问如何实现AXI4-Full到AXI4-Stream的转换呢 |
Beta Was this translation helpful? Give feedback.
-
If you are using AMD then I can highly recommend the AXI Streaming FIFO: IP module: https://www.xilinx.com/products/intellectual-property/axi_fifo.html#overview For an open source version, this looks promising - but I haven't tested it myself. Btw, English is the default language here. So please use deepl or any other translator. 😉 |
Beta Was this translation helpful? Give feedback.
-
AXI-LiteAXI-Lite is an obvious candidate for any not complex addressable register/memory. In umarcor/SIEAV, there is some content I use for teaching cosimulation and testing/verification with VHDL and open source tooling (GHDL, VUnit, Octave...). The system we use as a reference is a typical closed-loop control system with a controller, a plant, and drivers/actuators and capture/holds in-between.
The design is complemented with an AXI Slave component, in order to modify the setpoint and/or the constants/parameters of the controller, at runtime. Similarly to the AXI Stream example above, we use a Verification Component and cosimulation for testing the software-hardware interaction:
The motivation is to abstract away the specific implementation of the CPU and/or any other peripheral in the SoC, and focus on the "logic" of our application only, both software and the Core.
The actual implementation (synthesis) of the whole system is out of the scope of the course (for now). Hence, I didn't advance further. For future courses (and for enhancing the learning resources about using VHDL with open source tooling), I would like to add a working example with a minimal synthesisable setup:
However, I was missing some free and open source CPU written in VHDL, with a trivial build procedure (for someone used to hardware design in VHDL) and with a responsive maintainer 😄. As you might guess, NEORV32 is a nice candidate for showcasing how to go ahead with the system integration, synthesis and implementation:
I would like to prototype this on a Fomu, using GHDL, Yosys and nextpnr. As commented in some other issues, @tmeissner did already contribute a setup for UPduino v3.0 and I added the CI plumbing for it. Next step is to conciliate the structure with https://github.com/im-tomu/fomu-workshop/tree/master/hdl and/or https://github.com/dbhi/vboard/tree/main/vga. That is, having some common Moreover, for some reason, I was not watching this repo, and I did not see the PRs that @LarsAsplund opened these last days. Since I'm already using VUnit in umarcor/SIEAV, I think I might add NEORV32 as a submodule, and execute the VUnit tests in CI. I believe there is no explicit public example about that yet: two repos (maintained by different people) submoduling each another repo, both of them using VUnit. @stnolting, where do you suggest me to start reading? What is the closest to "How to add an external AXI4-Lite peripheral to the Wishbone bus in NEORV32"? |





Beta Was this translation helpful? Give feedback.
-
|
@AWenzel83, thanks for explaining!
So, that's the opposite architecture I'd like to use. I.e., instead of having the top level HDL wrapper generated by Vivado, and NEORV32 included as a block in a Vivado block-design (TCL), I would like to manually handle the top level VHDL source.
With open source tools, there are no block-design (TCL) components. HDLs are used only. That's why it would make it easier if we
Whenever you create the example design, would you mind trying this approach? |
Beta Was this translation helpful? Give feedback.
-
|
You should also look into the "bitsy" version of the icebreaker, a cheaper version without the FTDI that relies on USB bootloader and comms (like fomu) : https://github.com/icebreaker-fpga/icebreaker#icebreaker-bitsy It you want to port NeoRV32 and add usb support to it using my no2usb core, I can send you a spare one. (They're not generally for sale yet, first batch is in progress). I can also send you a few spare fomu I have here (hacker version from mithro). I don't have cases for all of them so you'll need to 3d print some. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @smunaut! Is there any estimate for the general availability? Will it be available in Europe? I've been checking the european shop, but didn't see it :( @stnolting, I guess you want to accept that proposal 😉. That is almost the same as the Fomu, but including more I/O. You can adapt it to a feather, and maybe to a baseboard with PMOD. |
Beta Was this translation helpful? Give feedback.
-
|
Just asked @esden on discord, should be 2-3 weeks for the US store. Then probably a couple more weeks to get to the EU stock. |
Beta Was this translation helpful? Give feedback.
-
Don't get me wrong. I just wanted to say that I am really impressed by your work and all the effort and also love you put into it 👍
I feel you.
You gotta dream big! 😎😆
Oh I am sorry! Unfortunately,
Thanks for that, but it's ok. I have a UPduino here and I think it would be possible the solder the USB front-end by myself.
This is a good point. I know there are thousands of open-source projects out there that use some kind of AMBA-related interface. But what about the patent/copyright issues? It is legal? In theory? 😅
I like that. One could provide a "proprietary" stream interface that could be translated into AXI stream (by simple signal re-naming? 😉)
I don't get what your question is pointing at?! There already is a Vivado project for the Arty board. The TCL script only requires some more command to make Vivado do the actual synthesis.
I thought about that as well. I would recommend using a direct Wishbone-to-AXI-Stream approach.
I will have a look! 👍
Thank you so much! That is really nice :) |
Beta Was this translation helpful? Give feedback.
-
|
@umarcor |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @smunaut! |
Beta Was this translation helpful? Give feedback.
-
|
Great, thank you very much @smunaut 👍
Right, but that was just something like a proof-of-concept to test how much of the SoC we can squeeze into that FPGA. A minimal setup with CPU (base ISA (data generated for an older version of the NEORV32. the current version should be even a little bit smaller) |
Beta Was this translation helpful? Give feedback.
-
|
I am currently working on a "Stream Link Interface" that is compatible to the AXI4-Stream base protocol. The interface will support up to 8 independent RX and TX links - each link provides a configurable internal FIFO. This is what the top entity might look like: -- Stream link interface --
SLINK_NUM_TX : natural := 0; -- number of TX links (0..8)
SLINK_NUM_RX : natural := 0; -- number of TX links (0..8)
SLINK_TX_FIFO : natural := 1; -- TX fifo depth, has to be a power of two
SLINK_RX_FIFO : natural := 1; -- RX fifo depth, has to be a power of two
-- TX stream interfaces (available if SLINK_NUM_TX > 0) --
slink_tx_dat_o : out sdata_8x32_t; -- output data
slink_tx_val_o : out std_ulogic_vector(7 downto 0); -- valid output
slink_tx_rdy_i : in std_ulogic_vector(7 downto 0) := (others => '0'); -- ready to send
-- RX stream interfaces (available if SLINK_NUM_RX > 0) --
slink_rx_dat_i : in sdata_8x32_t := (others => (others => '0')); -- input data
slink_rx_val_i : in std_ulogic_vector(7 downto 0) := (others => '0'); -- valid input
slink_rx_rdy_o : out std_ulogic_vector(7 downto 0); -- ready to receiveThe top signals always implement all 8 links even if less links are configured by the generics (the remaining links are terminated internally; so no extra logic). Of course one could constrain the simple I am not sure about additional "tag" signals like I know a stream link is basically a simple FIFO interface that should not be too hard to verify even with a simple testbench. However, I would like to do some "stress tests" someday (like randomized traffic). I am looking through VUnit's streaming verification components (https://vunit.github.io/verification_components/vci.html#stream-master-vci) but I couldn't find any example setups so far. @LarsAsplund @umarcor do you have any hints? 😉 |
Beta Was this translation helpful? Give feedback.
-
|
@stnolting Let me have a look and get back to you how it can be done. I see that you have a loopback from CPU back to the CPU. If we want to stress the CPU we could do a loopback starting in the testbench. Apply random input, wait for the CPU to loop that data back on the output and verify the correctness. |
Beta Was this translation helpful? Give feedback.
-
|
thank you
…--------------原始邮件--------------
发件人:"stnolting ***@***.***>;
发送时间:2024年12月7日(星期六) 中午1:59
收件人:"stnolting/neorv32" ***@***.***>;
抄送:"汪龙河 ***@***.***>;"Comment ***@***.***>;
主题:Re: [stnolting/neorv32] How to add AXI-Lite and AXI Stream peripherals (Discussion #52)
-----------------------------------
请问如何实现AXI4-Full到AXI4-Stream的转换呢
How to realize AXI4-Full to AXI4-Stream conversion?
If you are using AMD then I can highly recommend the AXI Streaming FIFO: IP module: https://www.xilinx.com/products/intellectual-property/axi_fifo.html#overview
For an open source version, this looks promising - but I haven't tested it myself.
Btw, English is the default language here. So please use deepl or any other translator. 😉
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you commented.Message ID: ***@***.***>
|
Beta Was this translation helpful? Give feedback.
-
|
You're welcome. |
Beta Was this translation helpful? Give feedback.
-
After getting familiar with the structure of the project, it's time to look into some practical use case. 🚀
My background is developing ad-hoc accelerators for non-trivial DSP, say machine-learning/image-processing, say algebraic kernels in VHDL. During testing and verification, those need to be complemented with some CPU, in order to move data and results between a workstation/laptop and the accelerator. I used MicroBlaze and Zynq (ARM A9). The interfaces are either AXI-Lite or AXI Stream, despite some cores using Wishbone internally. However, those CPUs are overkill for orchestration purposes only, and the toolchains/frameworks provided by the vendor are not the most comfortable out there.
I'm willing to learn how to use NEORV32 SoC. Although not all my designs are open source, I believe there are a few examples which can be useful enough for didactic purposes.
Beta Was this translation helpful? Give feedback.
All reactions