

Update: Pre-trained Universal Sentence Encoders and BERT Sentence Transformer now available for embedding. Read more.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors. Once you train the Top2Vec model you can:
- Get number of detected topics.
- Get topics.
- Get topic sizes.
- Get hierarchichal topics.
- Search topics by keywords.
- Search documents by topic.
- Search documents by keywords.
- Find similar words.
- Find similar documents.
- Expose model with RESTful-Top2Vec
See the paper for more details on how it works.
- Automatically finds number of topics.
- No stop word lists required.
- No need for stemming/lemmatization.
- Works on short text.
- Creates jointly embedded topic, document, and word vectors.
- Has search functions built in.
The assumption the algorithm makes is that many semantically similar documents are indicative of an underlying topic. The first step is to create a joint embedding of document and word vectors. Once documents and words are embedded in a vector space the goal of the algorithm is to find dense clusters of documents, then identify which words attracted those documents together. Each dense area is a topic and the words that attracted the documents to the dense area are the topic words.
1. Create jointly embedded document and word vectors using Doc2Vec or Universal Sentence Encoder or BERT Sentence Transformer.
Documents will be placed close to other similar documents and close to the most distinguishing words.

2. Create lower dimensional embedding of document vectors using UMAP.
Document vectors in high dimensional space are very sparse, dimension reduction helps for finding dense areas. Each point is a document vector.

3. Find dense areas of documents using HDBSCAN.
The colored areas are the dense areas of documents. Red points are outliers that do not belong to a specific cluster.

4. For each dense area calculate the centroid of document vectors in original dimension, this is the topic vector.
The red points are outlier documents and do not get used for calculating the topic vector. The purple points are the document vectors that belong to a dense area, from which the topic vector is calculated.

The closest word vectors in order of proximity become the topic words.

The easy way to install Top2Vec is:
pip install top2vec
To install pre-trained universal sentence encoder options:
pip install top2vec[sentence_encoders]
To install pre-trained BERT sentence transformer options:
pip install top2vec[sentence_transformers]
To install indexing options:
pip install top2vec[indexing]
from top2vec import Top2Vec
model = Top2Vec(documents)Important parameters:
-
documents: Input corpus, should be a list of strings. -
speed: This parameter will determine how fast the model takes to train. The 'fast-learn' option is the fastest and will generate the lowest quality vectors. The 'learn' option will learn better quality vectors but take a longer time to train. The 'deep-learn' option will learn the best quality vectors but will take significant time to train. -
workers: The amount of worker threads to be used in training the model. Larger amount will lead to faster training.
Trained models can be saved and loaded.
model.save("filename")
model = Top2Vec.load("filename")For more information view the API guide.
Doc2Vec will be used by default to generate the joint word and document embeddings. However there are also pretrained embedding_model options for generating joint word and document embeddings:
universal-sentence-encoderuniversal-sentence-encoder-multilingualdistiluse-base-multilingual-cased
from top2vec import Top2Vec
model = Top2Vec(documents, embedding_model='universal-sentence-encoder')For large data sets and data sets with very unique vocabulary doc2vec could produce better results. This will train a doc2vec model from scratch. This method is language agnostic. However multiple languages will not be aligned.
Using the universal sentence encoder options will be much faster since those are pre-trained and efficient models. The universal sentence encoder options are suggested for smaller data sets. They are also good options for large data sets that are in English or in languages covered by the multilingual model. It is also suggested for data sets that are multilingual.
The distiluse-base-multilingual-cased pre-trained sentence transformer is suggested for multilingual datasets and languages that are not covered by the multilingual universal sentence encoder. The transformer is significantly slower than the universal sentence encoder options.
More information on universal-sentence-encoder, universal-sentence-encoder-multilingual, and distiluse-base-multilingual-cased.
If you would like to cite Top2Vec in your work this is the current reference:
@article{angelov2020top2vec,
title={Top2Vec: Distributed Representations of Topics},
author={Dimo Angelov},
year={2020},
eprint={2008.09470},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Train a Top2Vec model on the 20newsgroups dataset.
from top2vec import Top2Vec
from sklearn.datasets import fetch_20newsgroups
newsgroups = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))
model = Top2Vec(documents=newsgroups.data, speed="learn", workers=8)This will return the number of topics that Top2Vec has found in the data.
>>> model.get_num_topics()
77This will return the number of documents most similar to each topic. Topics are in decreasing order of size.
topic_sizes, topic_nums = model.get_topic_sizes()Returns:
-
topic_sizes: The number of documents most similar to each topic. -
topic_nums: The unique index of every topic will be returned.
This will return the topics in decreasing size.
topic_words, word_scores, topic_nums = model.get_topics(77)Returns:
-
topic_words: For each topic the top 50 words are returned, in order of semantic similarity to topic. -
word_scores: For each topic the cosine similarity scores of the top 50 words to the topic are returned. -
topic_nums: The unique index of every topic will be returned.
We are going to search for topics most similar to medicine.
topic_words, word_scores, topic_scores, topic_nums = model.search_topics(keywords=["medicine"], num_topics=5)Returns:
-
topic_words: For each topic the top 50 words are returned, in order of semantic similarity to topic. -
word_scores: For each topic the cosine similarity scores of the top 50 words to the topic are returned. -
topic_scores: For each topic the cosine similarity to the search keywords will be returned. -
topic_nums: The unique index of every topic will be returned.
>>> topic_nums
[21, 29, 9, 61, 48]
>>> topic_scores
[0.4468, 0.381, 0.2779, 0.2566, 0.2515]Topic 21 was the most similar topic to "medicine" with a cosine similarity of 0.4468. (Values can be from least similar 0, to most similar 1)
Using a topic number you can generate a word cloud. We are going to generate word clouds for the top 5 most similar topics to our medicine topic search from above.
topic_words, word_scores, topic_scores, topic_nums = model.search_topics(keywords=["medicine"], num_topics=5)
for topic in topic_nums:
model.generate_topic_wordcloud(topic)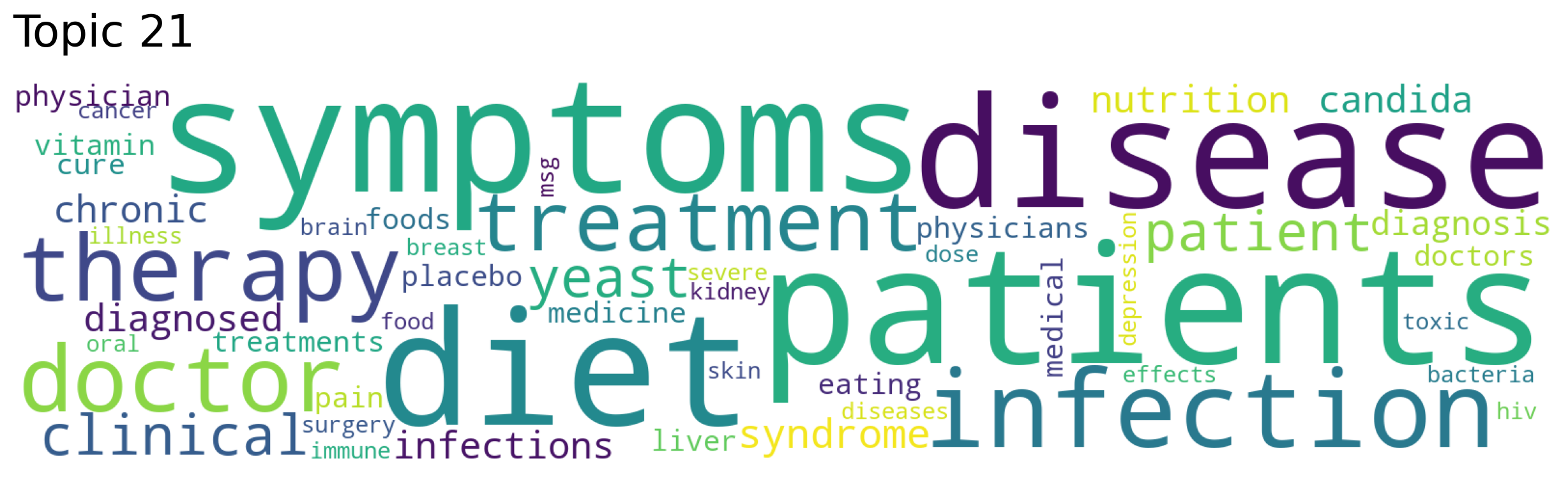




We are going to search by topic 48, a topic that appears to be about science.
documents, document_scores, document_ids = model.search_documents_by_topic(topic_num=48, num_docs=5)Returns:
-
documents: The documents in a list, the most similar are first. -
doc_scores: Semantic similarity of document to topic. The cosine similarity of the document and topic vector. -
doc_ids: Unique ids of documents. If ids were not given, the index of document in the original corpus.
For each of the returned documents we are going to print its content, score and document number.
documents, document_scores, document_ids = model.search_documents_by_topic(topic_num=48, num_docs=5)
for doc, score, doc_id in zip(documents, document_scores, document_ids):
print(f"Document: {doc_id}, Score: {score}")
print("-----------")
print(doc)
print("-----------")
print()Document: 15227, Score: 0.6322
-----------
Evolution is both fact and theory. The THEORY of evolution represents the
scientific attempt to explain the FACT of evolution. The theory of evolution
does not provide facts; it explains facts. It can be safely assumed that ALL
scientific theories neither provide nor become facts but rather EXPLAIN facts.
I recommend that you do some appropriate reading in general science. A good
starting point with regard to evolution for the layman would be "Evolution as
Fact and Theory" in "Hen's Teeth and Horse's Toes" [pp 253-262] by Stephen Jay
Gould. There is a great deal of other useful information in this publication.
-----------
Document: 14515, Score: 0.6186
-----------
Just what are these "scientific facts"? I have never heard of such a thing.
Science never proves or disproves any theory - history does.
-Tim
-----------
Document: 9433, Score: 0.5997
-----------
The same way that any theory is proven false. You examine the predicitions
that the theory makes, and try to observe them. If you don't, or if you
observe things that the theory predicts wouldn't happen, then you have some
evidence against the theory. If the theory can't be modified to
incorporate the new observations, then you say that it is false.
For example, people used to believe that the earth had been created
10,000 years ago. But, as evidence showed that predictions from this
theory were not true, it was abandoned.
-----------
Document: 11917, Score: 0.5845
-----------
The point about its being real or not is that one does not waste time with
what reality might be when one wants predictions. The questions if the
atoms are there or if something else is there making measurements indicate
atoms is not necessary in such a system.
And one does not have to write a new theory of existence everytime new
models are used in Physics.
-----------
...
Search documents for content semantically similar to cryptography and privacy.
documents, document_scores, document_ids = model.search_documents_by_keywords(keywords=["cryptography", "privacy"], num_docs=5)
for doc, score, doc_id in zip(documents, document_scores, document_ids):
print(f"Document: {doc_id}, Score: {score}")
print("-----------")
print(doc)
print("-----------")
print()Document: 16837, Score: 0.6112
-----------
...
Email and account privacy, anonymity, file encryption, academic
computer policies, relevant legislation and references, EFF, and
other privacy and rights issues associated with use of the Internet
and global networks in general.
...
Document: 16254, Score: 0.5722
-----------
...
The President today announced a new initiative that will bring
the Federal Government together with industry in a voluntary
program to improve the security and privacy of telephone
communications while meeting the legitimate needs of law
enforcement.
...
-----------
...
Search for similar words to space.
words, word_scores = model.similar_words(keywords=["space"], keywords_neg=[], num_words=20)
for word, score in zip(words, word_scores):
print(f"{word} {score}")space 1.0
nasa 0.6589
shuttle 0.5976
exploration 0.5448
planetary 0.5391
missions 0.5069
launch 0.4941
telescope 0.4821
astro 0.4696
jsc 0.4549
ames 0.4515
satellite 0.446
station 0.4445
orbital 0.4438
solar 0.4386
astronomy 0.4378
observatory 0.4355
facility 0.4325
propulsion 0.4251
aerospace 0.4226