The indexing of website endpoints in web archives services such as web archive, URLscan, or Alien Vault raises concerns over privacy and security, as it can expose sensitive information. This article examines the responsibility and measures that can be taken to prevent such incidents.
As a bug hunter, I've experienced firsthand the difficulties in effectively communicating my viewpoint on this subject to program owners and platform triagers. To address this challenge, I've decided to write a comprehensive explanation of my understanding of this topic to provide a standard solution for all bug hunters in the community. In this post, we'll explore the reality that all websites on the internet are exposed to automated crawls and scanners, regardless of whether website owners exposed by mistake some hidden endpoints. We'll use the example of a subdomain containing sensitive information, such as invoices, to illustrate the potential for information exposure.
Web archiving is the process of gathering data that has been recorded on the World Wide Web, storing it, ensuring the data is preserved in an archive, and making the collected data available for future research. The Internet Archive and several national libraries initiated web archiving practices in 1996.
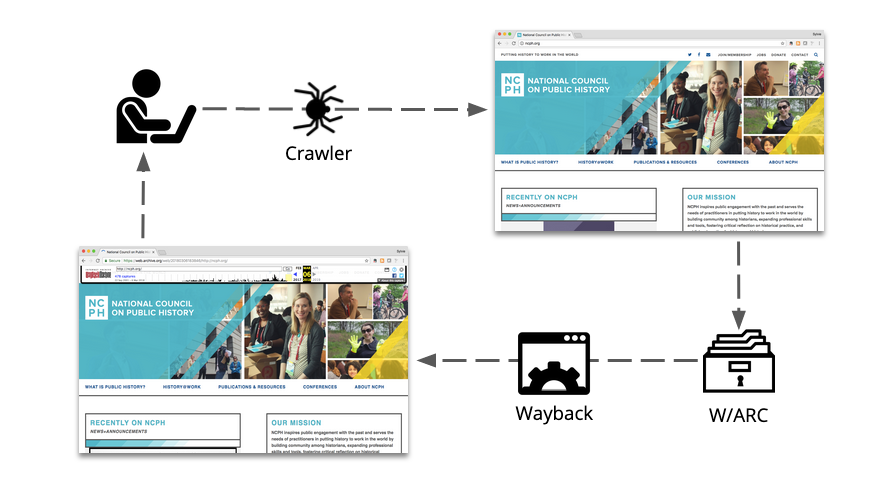
Web archiving is an intricate process that creates a digital snapshot of a website, preserving its appearance and content for future reference. The process involves three key components: capture, storage, and replay. Each step utilizes different technologies to achieve the final goal of revisiting a website as it appeared on a specific date.
The first step of the process involves sending out a web crawler, also known as a robot or bot, to gather all the necessary elements of a website, including text, images, CSS, and javascript. The crawler then stores the collected data and metadata in a web archive file, commonly known as a WARC. As the WARC file size has limitations, multiple WARCs are often needed to preserve an entire website.
To replay the archived website, the WARC files must be processed using a replay mechanism, such as Wayback, which is part of the Archive-It system. This allows the website to be viewed as it appeared on the day it was archived, providing a historical record of its content and design. Web archiving is also helpful for data mining, but its primary purpose is to allow users to interact with a website as it was initially published.
The endpoint, https://subdomain.example.com/1122.pdf/?access_token=jwt, serves as an illustration of the potential for information exposure. This endpoint is a billing invoice that can be downloaded in PDF format by the user. The probability of this endpoint being scanned and crawled ranges from 80-90%. This increases the likelihood of caching or spidering by indexing sites, leading to the potential storage of the confidential PDF. The following subdomain serving this content should have a strict /robots.txt on https://subdomain.example.com/robots.txt and should be restricted for crawling/ spidering from Indexing sites. Please make sure you have a strict Indexing policy on robots.txt file which is honored by web crawlers. If you are still getting Indexed please follow the mentioned steps below to eliminate this risk.
Failing to configure the robots.txt file on subdomains properly can result in serious security issues. To keep sensitive information protected, it is necessary to have a separate and strict robots.txt file for each subdomain that contains confidential content. For example, if the main domain is https://www.example.com, then each subdomain like https://subdomain.example.com should have its specific robots.txt file to ensure that search engines do not index sensitive information.
It is important to note that relying solely on the primary domain robots.txt file is not effective in preventing indexing by scanners and crawlers. These entities do not abide by the primary domain file when indexing subdomains and their contents.
It is advisable to configure the robots.txt file to mitigate indexing issues. The recommended configuration is as follows:
# https://www.robotstxt.org/robotstxt.html
User-agent: *
Disallow: /To prevent sensitive information from being indexed and potentially leaked, monitoring and updating the robots.txt file regularly is crucial. If this is not enough, there are further measures to remove the website from online archives, such as the Internet Archive, Wayback Machine, and Archive.org.
Here's how to do it:
- Block the archives' crawlers in the website's
robots.txtfile and verify the copyright information. - Compose a DMCA Takedown Notice with detailed links to the pages you want removed from the archives.
- Obtain proof of domain ownership, such as an old invoice showing the earliest date of ownership.
- Send a polite email to the archives' crawler with the attached DMCA Takedown Notice and proof of domain ownership.
- Allow 3-5 days for the removal process to take place.
I have outlined the steps for removing your website from Archive.org and have included additional information for each step to make it as easy as possible. However, I have experienced inconsistent results in the past with the Internet Archive, which can be frustrating. Sometimes, updating my site leads to the deletion of my robots.txt file, resulting in my website being re-archived on Archive.org. It would be great if Archive.org offered a verification system for publishers to request a takedown or a webmaster tool like those found on Google and Bing.
Protecting Your Copyright through Robots.txt and Compliance: Blocking Archive.org Service Access
Blocking Archive.org archive service from accessing your website is straightforward with the use of the robots.txt file. To prevent Archive.org from accessing your site, add the following code to the end of your robots.txt file:
User-agent: ia_archiver
Disallow: /If you are not comfortable editing the robots.txt file, you can use a WordPress plugin, such as the Archive.org Blocker, to do this for you. This plugin will automatically block Archive.org from archiving your website.

When making changes to your website, it is also important to consider the copyright notice. A copyright notice is a statement that indicates who holds the exclusive rights to the content on your site. It acts as a warning to others that they may not use your content without permission.
Content management systems usually automatically add a copyright notice to your website. It is essential to ensure that this notice is accurate and up-to-date, as it serves as legal protection for your content. You may need to update the notice if you have made any changes to the content, such as adding new information or images.
Including the date of publication on your copyright notice is also a good practice. This helps to establish when the content was first published and provides a time frame for when the copyright will expire.
To summarize, checking your website's copyright notice is an important step when making changes to your site. Ensure that it is accurate, up-to-date, and includes the date of publication to provide proper legal protection for your content.
Sending a DMCA Takedown Notice to the Internet Archive / Wayback Machine / Archive.org
If you have found archived content on the Internet Archive that violates your intellectual property rights, you can send a DMCA takedown notice to have it removed. A DMCA takedown notice is a legal document, so it is important to make sure you understand what you are doing before proceeding with this step.
To generate a DMCA takedown notice, you can use a free generator tool, such as the one from Who Is Hosting This or Intellectual Property HQ. Make sure to paste in the website addresses from Archive.org that correspond to the dates you owned the domain and the content you want to be removed.
It is important to note that this step should only be taken if you have a serious issue with archived content and have consulted with legal counsel. If you are unsure or nervous about sending a DMCA takedown notice, it may be best to seek the advice of a legal expert.
Step 1: Robots.txt to Block a site from the Internet Archive / Wayback Machine / Archive.org / Check Copyright Notice
If you’re super interested, you can learn more about robots.txt here.
Archive.org has a mixed attitude to robots.txt but they do honor them.
Make sure you add this to the end of your existing robots.txt file, don’t delete any existing entries.
User-agent: ia_archiver
Disallow: /
If you’re not sure how to edit your robots.txt then talk to your hosting provider or website developer.
If you use WordPress, this free Archive.org Blocker WordPress plugin does everything you need to block Archive.org from WordPress. Install, activate, and you’re done. If you already use a robots.txt plugin, you can add the above code to the end of your existing robots.txt file.
While you’re making these changes, it’s also a good time to check that there is a current Copyright Notice on your website. Most content management systems put this on your site automatically.
Step 2: DMCA Takedown Notice for the Internet Archive / Wayback Machine / Archive.org
The DMCA is short for the Digital Millennium Copyright Act. It’s a piece of US legislation to help copyright holders protect their intellectual property. Even if you don’t live in the US you can use a DMCA notice to have content remove from the Internet Archive / Wayback Machine / Archive.org.
I am #NotALawyer so if you’re dealing with a serious issue with archived content, get your own legal counsel. This is also not legal advice, so if this step makes you nervous best to ask an expert. I have been told by others who have read these instructions that you can skip this DMCA step and still have success. Your mileage may vary.
To generate a DMCA takedown notice, I used this free DMCA Generator tool from Who Is Hosting This. Otherwise, use this DMCA Takedown Notice generator from the Intellectual Property HQ.
I am going to stress again, DMCA notices are legal documents so make sure you’re fully aware of what you’re doing.
The DMCA form is straightforward, but make sure you paste in as many website addresses from Archive.org that match the dates you owned the domain and the content you want to be removed.
Step 3: Demonstrating a History of Domain Ownership to the Internet Archive / Wayback Machine / Archive.org
If you’re requesting the removal of a whole domain or website from Archive.org may ask for proof of domain ownership. Archive.org provides no automated verification of ownership such as a DNS record change, website code, or uploading of a file. You will need to find an old invoice / receipt from your domain host proving ownership.
Most hosting providers do provide access to a history of invoices, so you will need to log in to your account to get these. Worst case, it might require an email to the accounts department of your hosting company.
If you’re in a hurry, you can try and skip this step and see how Archive.org responds but be prepared for them to ask for this information. One way to try and avoid the issue is to send the request from an email address associated with the domain.
That said, I strongly encourage you to send proof of ownership as part of the request. Archive.org can be frustrating if your domain has switched hosts, registrars, etc. during the request period which they verify against public domain records. If you forget your original register or host, I’d do a free domain history check to jog your memory.
If you do not own the domain you will not be able to get the site deleted from the Internet Archive.
Step 4: Email Requesting the Internet Archive / Wayback Machine / Archive.org remove your website
The email address for Archive.org takedown requests is [email protected] but do not email them unless you have done Steps 1-3.
It is better if your email comes from the domain you’re emailing about. For example, if you want Google.com removed, you should have an @google.com email. In my experience, Archive.org will respond to a request from an email address other than the domain you are requesting but they may require additional verification steps.
Sending a request from a free email service like Gmail, Outlook.com, etc. is almost guaranteed to slow things down. This is one of the reasons I recommend Step 3, because it provides additional information when you make the request.
Here’s some suggested wording for an Archive.org Takedown Request / Removal of Domain where:
- [Your_Name] should be replaced with your name and
- [Your_Domain] with your relevant domain name.
- [Start_Date] that has the date from which you want the domain removed and can prove ownership of the domain.
I recommend sending a separate notice for each domain, don’t try and do it all at once.
Subject
Formal Request To Remove [Your_Domain] From Internet Archive Wayback MachineCopy
Body
Hello
I am [Your_Name] owner of [Your_Domain].
I’m officially requesting the immediate removal of [Your_Domain] site/domain from web.archive.org and the Internet Archive Wayback Machine.
The User-agent: ia_archiver Disallow: / code in our robots.txt file is not being followed. The Copyright Notice on this site can be found here [Your_Domain]
I am requesting removal of [Your_Domain] from [Start_Date] up to and including today and all days going forward.
Attached is formal DMCA notice as well as evidence that I am the owner of [Your_Domain].
Thank you for your prompt attention.
[Your_Name]
Don’t Forget! to attach the DMCA notice you generated in Step 2 and proof of ownership in Step 3.
Step 5: Wait and Track Archive.org
Once you send your email you will need to wait. I’ve had response times as fast as 24 hours and some that take a few days. Archive.org will reply, just remember that they are US-based (California) so make sure you allow for US Pacific Time, weekends, and major US holidays. Be patient, polite, but firm. If you don’t hear after 3 days, a polite follow-up email may be warranted.
In my experience, if you do everything above, you will get a response within 5 days. It takes about a week after they respond for content to be purged from Archive.org
Other Tips
- The Internet Archive / Wayback Machine / Archive.org will only delete pages and sites from when you took ownership, not just because you now have ownership. This is really important. So if you have bought an old domain, you’re out of luck for anything older than the day you commenced ownership.
- I have found the people from Internet Archive / Wayback Machine / Archive.org friendly. So please be polite. They do want to help and anything they ask is to clarify an issue. They do only respond during US business hours. So it pays to be patient (3 working days minimum).
- There is no urgent process. There’s not much else I can say other than if you need this done fast, I share your frustration. If there’s a legal reason why you need something removed quickly, you should really get legal counsel involved.
- I have no experience having content removed from Archive.org where you are not the domain owner, for example, if a domain has breached your copyright and now your content is in the archive. I am #NotALawyer and recommend you get legal advice if your issue relates to your content but not your domain.
- This last piece of advice is as much for me as it is for everyone else. If you want to always block the Internet Archive / Wayback Machine / Archive.org make sure you keep your robots.txt up to date. It’s a lot easier to keep robots.txt updated and block Archive.org than get pages removed.
- There is value to the Internet Archive, so don’t remove your site unless you really feel it’s necessary. It may be better to just remove specific pages.
- If you want to remove your personal information and data from data brokers, then you will need to use something like OneRep.
- I do not provide any support or assistance in removing your site or page. I also cannot remove your site.
- I am not affiliated with the Internet Archive.
The folllowing contents were copied from joshualowcock Huge thanks to him for creating this. I copied the entire steps from him because I think nobody can better explain this the way he did.
Once you remove the site or file a email to do so, your website will no longer be Indexed and will be listed as Not allowed to indexed or forbidden. Just like this

I hope it was easy to understand, And I look forward to all companies to Implement this and not blame any users or any facts for Indexing and take it as a serious security issue.
Thanks you for reading and I hope you have blessed rest of your day/ night. tess
Follow me on Twitter, If you want to reach me out with further questions.