Program Structure
Analysis is performed over the tool's own internal IR, BASIL IR. To do so, we need a way to take a program (assumed: binary), and transform it into this IR. To do this we use a tool to lift the Binary into an ADT (Abstract Data Type) - BAP lifts the ARM binary into its own IR, which it can then output as an ADT. We parse this ADT into an internal representation of what BAP lifted, and then translate this into our IR. This is then what is used to perform analysis on, and later translate into Boogie. An overview of the translating processes is given here.
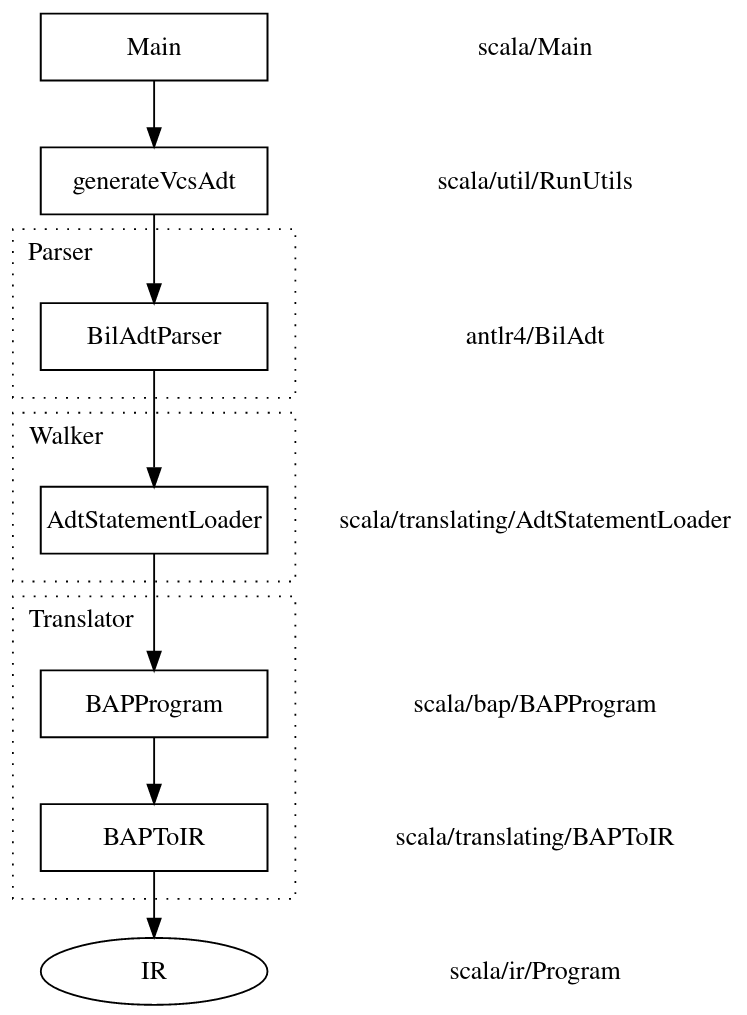
ANTLR is a tool which takes a grammar file (BilAdt.g4) and creates a parser in Java that exposes tokens of the grammar through classes. The parser is autogenerated at runtime here.
val adtLexer = BilAdtLexer(CharStreams.fromFileName(fileName))
val tokens = CommonTokenStream(adtLexer)
val parser = BilAdtParser(tokens)The parser object then stores the parsed ADT (Abstract Data Tree) of the program. We then walk the ADT in AdtStatementLoader, which happens here.
val program = AdtStatementLoader.visitProject(parser.project())As the ADT is walked we transform tokenised ADT nodes into internal BAP IR structures, all defined here. For example, a parsed direct call, stored by the parser as a DirectCallContext, will be converted into a BAPDirectCall.
These are all collated into a BAPProgram, which is essentially a list of functions in the program, and known memory sections, as represented by BAP.
We now have an internal representation of the program we want to analyse, stored as a mapping of how BAP lifted it. Instead of performing analysis on this, we translate this into our own IR. The BASIL IR was designed to be easily translated into Boogie, meaning any transformations of the program structure resulting from analyses should not hamper our ability to translate into Boogie.
With the ADT parsed, we then match up symbol names with procedures in the ADT via the output of readelf, stored in the associated .relf. This helps us identify external functions, internal functions, and global variables.
The BAPProgram is then translated into an IR Program via BAPToIR.
We then remove external functions that we wish to ignore for analysis (such as printf), and clean up some BAP naming artefacts. At this point we have a BASIL IR of the program which we can then perform analyses over, and later translate to Boogie IVL.
The grammar of the parser is inspired by the existing parser found at BinaryAnalysisPlatform/bap-python, in particular, the nodes found in adt.py, br.py and bil.py. The grammar attempts to reflect the inheritance hierarchy - the alternatives of a token are its subclasses.
For example, exp and term are subclasses of ADT, and thus in the grammar we have adt : exp | term | ....
- Negative numbers are encoded somewhat strangely. It takes the 2's complement representation of the number, and interprets the binary string as if it were an unsigned integer.
- For example, the number -2 in 64 bits is 1111111111111111111111111111111111111111111111111111111111111110, which is interpreted in the ADT as Int(18446744073709551614, 64).
The internal IR is designed such that it will translate easily to Boogie's IVL. The structure of the IR is given:
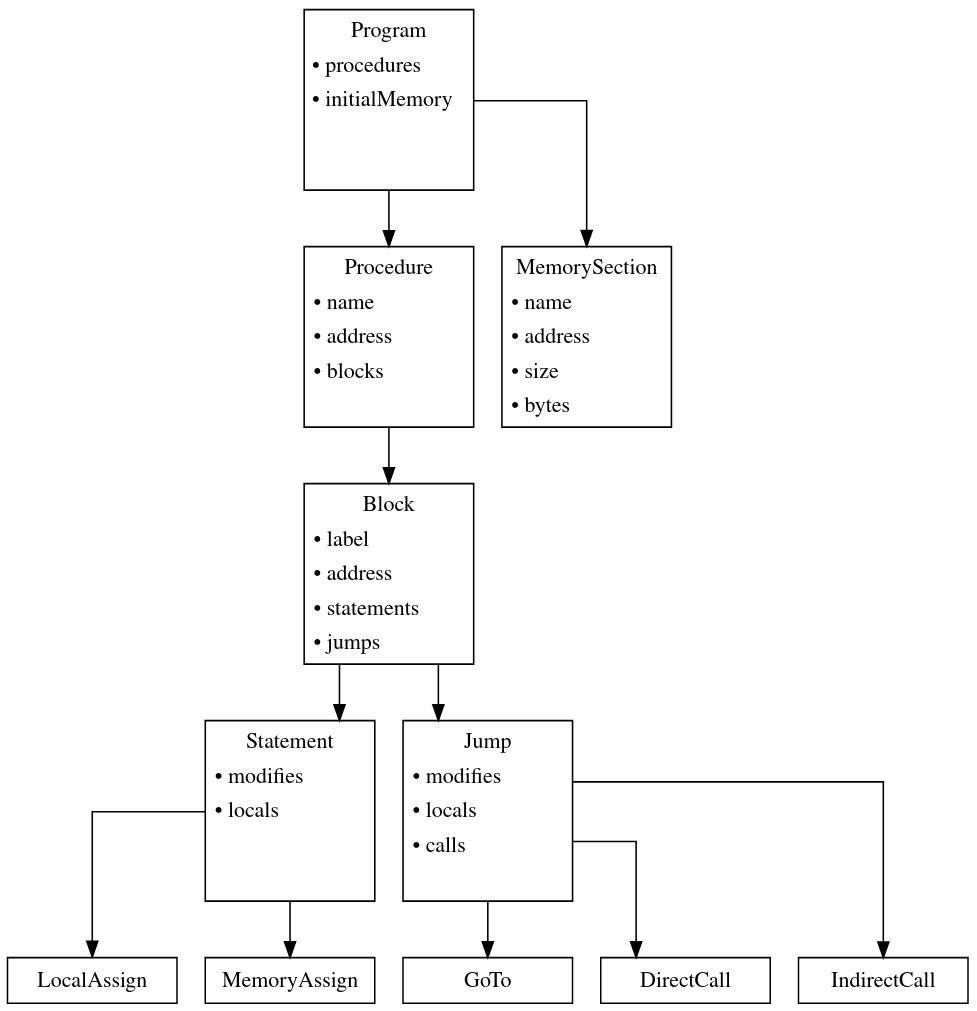
Similar to BAP, this simply stores a list of known functions (procedures) and memory regions.
A procedure is a representation of a function call, e.g. __libc_start_main. It stores
-
name: the function's string representation (e.g."__libc_start_main"). -
address: offset into the binary. -
blocks: a list of blocks in the procedure. See Block for an explanation of what constitutes a block. -
calls: a list of function calls made by blocks in this procedure.
Represents an abstract region of memory. It has an address and a number of bytes in size. It can also store a sequence of bytes, representing data in the memory region.
A basic block. Basic blocks in the context of this IR are consecutive sequences of instructions without a jump.
-
label: unique identifier for this block. This is the label that BAP gave it which has propagated through (its effectively a "BAP Address"). -
address: offset of the start of this block in the binary. -
statements: sequence of statements in the block. -
jumps: a sequence of one or more jumps from this block to other blocks or procedures. A jump will either be a (direct|indirect) call to a procedure or aGoTostatement to another block.
These sets are calculated and stored in the block also:
-
calls: names of functions (jumps) from this block which have been resolved (i.e. direct calls). -
modifies: memory regions that are modified within this block. -
locals: registers accessed during this block.
An expression (rhs) which is evaluated and stored into a register (lhs). For example, R2 := 3bv32 + 20bv32 is a statement, with lhs: R2 and rhs: Expression(3bv32 + 20bv32).
-
modifies: memory regions that this statement modifies. -
locals: registers that this statement accesses (writing or reading).
Assigning a value to a local variable. Local in this context means local to the procedure scope.
-
lhs: variable (local) which stores the evaluation of therhsis stored in -
rhs: expression to be evaluated and stored inlhs -
modifies: empty for local. -
locals: registers that this statement accesses (writing or reading).
Assigning a value to some memory region. A memory region can be on the stack, in the heap, or global.
-
lhs: memory region that the evaluation of therhsis stored in -
rhs:MemoryStoreexpression to be evaluated and stored at memory region specified inlhs -
modifies:Memoryregions that this statement modifies (lhsof statement). -
locals: registers that this statement accesses (writing or reading).
A jump from this point in the program to another part in the program.
-
modifies: currently unused. NOTE: is this deprecated? -
locals: dependencies for this jump. For example, agotoinstruction will depend on some expression involving CPU flags. For procedure calls, these are parameters passed to the function call. -
calls: currently unused. NOTE: is this deprecated?
A jump directly to a specified address (Block in this instance), without any form of stack preparation or function prologue. Used in loops and conditionals.
-
target: theBlockto jump to. -
condition: if this is a conditional jump, the expression being evaluated to decide whether to jump -
modifies: currently unused. -
locals: anyVariableused by the conditional expression, if this is a conditional jump.
Call to a procedure which is known.
-
target: theProcedureto jump to. -
condition: if this is a conditional jump, the expression being evaluated to decide whether to jump. -
returnTarget: theBlockto jump back to upon execution finish. -
locals: anyVariableused by the conditional expression, if this is a conditional jump. -
calls: anyProcedurethat is called within the target of this call.
Call to a procedure given by an expression which has not been resolved / evaluated yet.
-
target: theVariablestoring the address to jump to. -
condition: if this is a conditional jump, the expression being evaluated to decide whether to jump. -
returnTarget: theBlockto jump back to upon execution finish. -
locals: anyVariableused by the conditional expression, if this is a conditional jump.
All the above then depend Expressions, which contain representations for instructions to be evaluated / left symbolic, such as literals and binary operations. Boogie uses BitVectors for register values, and so operations in the BASIL IR are also represented as BitVector operations.
Here we'll discuss the use of an internal CFG, how it is structured, how it is constructed, and the reasoning for some of the design choices.
We take in a binary, which is lifted to some intermediary language, which is then translated to our Basil IR. The purpose of the IR is to provide a representation of the semantics of a program, with as little modification as possible. However, when we perform an analysis, we may wish to make some modifications to the structure we're analysing. Additionally we wish to perform analyses at an instruction level, whereas by default an IR operates at a basic block level and does not provide an easy way to traverse it in a more granular way - this in effect actually makes the "CFG" we use not technically a CFG, as our nodes are not basic blocks as is traditional, but individual instructions.
Using a CFG also means we can track results of analyses without modifying the IR - for example, if we perform a value set analysis that can then feed into another analysis, we can do so without affecting the underlying semantics of the program, which later is translated to Boogie.
Nodes are distinguished by a few factors, with the hierarchy given:

We'll breakdown what each represents:
This is the base upon which all other node types are built. All CFG nodes store:
-
predIntra: the nodes preceeding this one that are walked by an intra-procedural analysis -
predInter: as above, but for inter-procedural analysis -
succIntra: the nodes proceeding this one that are walked by an intra-procedural analysis -
succInter: as above, but for inter-procedural analysis -
pred(intra: Boolean): accessor returning predecessor nodes. Ifintrais true, then only walk intra-procedural edges. Otherwise, only walk inter-procedural edges. -
predEdges(intra: Boolean): accessor that instead of returning nodes, returns the associated edge. -
predConds(intra: Boolean): accessor that instead of returning nodes, returns a tuples of (node, condition) representing a condition associated with the node, if one exists (TrueLiteralif no condition exists). -
succ(intra: Boolean): as above, but for successor nodes. -
succEdges(intra: Boolean): as above, but for successor edges. -
succConds(intra: Boolean): as above, but for successor nodes with conditions. -
id: a unique identifier for this node. -
copyNode: this duplicates the current node, but clears stored edges. A unique node ID is created for the new node.
Used for indirect calls which are identified as returning from this procedure to the caller. e.g. if f calls g, and then g wants to return from its context back to f. This then links straight to the CfgFunctionExitNode associated with the current context.
Some calls don't have a specified return block. In large these are erroneous reportings from the lifter (e.g. missed indirect calls or weird compiler optimisations), though can arise in cases where it's not expected a procedure call will return (e.g. a call to a function with an infinite loop, or a fork). This node is a convenience for analyses to signify this behaviour. It links straight to the CfgFunctionExitNode as well.
Most calls (direct or indirect) will specify an address which is to be returned to after the target of the call has returned. This node is used as a stepping stone between the return of a target's execution and that return address - it is a convenience for analyses to be able to update upon restoring a context.
This is a parent trait which enables implementers to store data. Nodes which subtype this are associated with some part of the IR, and thus store the "data" they're representing, and their originating block.
-
data: what this node is representing (e.g. a statement in the IR) -
block: the block in the IR that thisdatacomes from
This represents the start of a procedure.
-
data: theProcedurethat this node is the start of.
This represents the end of a procedure.
-
data: theProcedurethat this node is the end of.
A parent trait joining nodes that represent commands in a procedure together.
CFG representation of a statement in the IR.
-
data:Statement
CFG representation of a jump in the IR. This really on represents DirectCalls and IndirectCalls, as GoTos are resolved as edges (with one notable exception, for which CfgGhostNode exists)
-
data:Jump
This is a general purpose node that can provide CFG convenience, but which has no semantic meaning in terms of the IR.
For example, in the specific case that a block has no statements, but has for its jump a GoTo call, we use this as the "start" of the block. If we didn't, then there would be no node in the CFG for which other jumps would jump to if they wanted to jump to this "block" in that case.
-
data: NOP
We distinguish between some edges to enable us to store the inter and intra procedural CFG in the same data structure.
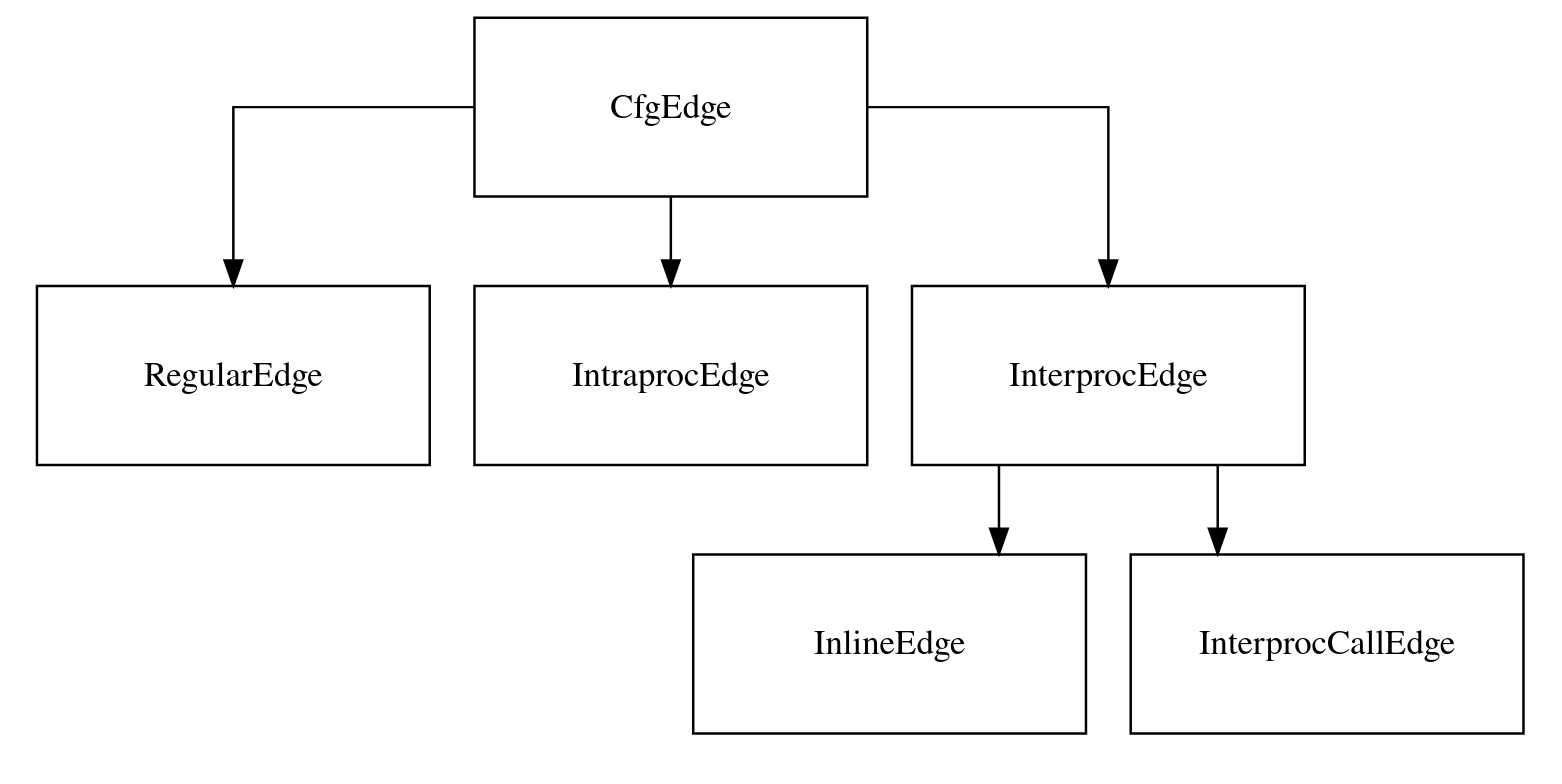
The parent trait. CFG edges are directed, and all edges must contain:
-
from: the originating CFG node. -
to: the destination CFG node. -
cond: the condition connectingfromtoto. This is by default aTrueLiteral, which encodes the fact the edge is "unconditional".
Regular edges encode "normal" instruction flow, i.e., where the distinction between intra and inter is not important. Most statement nodes will be connected via a regular edge.
In the CFG representation, these are depicted as solid black lines.
These encode an intraprocedural connection. This is used to connect a call node with its return node directly, so that if an analysis does not wish to follow calls, it can "skip" over it - i.e., walk the intraprocedural CFG.
In the CFG representation, these are depicted as dashed blue lines.
This is a parent type, as we distinguish between two tyes of interprocedural edges: inlined edges, and calls.
These are used to connect a call with an inlined copy of its target procedure. These are a type of interprocedural edge as we wish to skip inlined procedures if walking the intra-procedural CFG.
In the CFG representation, these are depicted as dashed red lines.
These connect a call with the intra-procedural CFG of its target. We don't add an edge coming back to the calling context, as that would require a stateful CFG - thus the analysis must track where it called from, and when it comes to the callee's exit, return to the context it came from.
In the CFG representation, these are depicted as dashed green lines. Note though that these are by default disabled in the .dot generation as they can make the visualisation hard to look at. To enable them, uncomment this.
The CFG takes a Basil IR as input. The start of this process is in fromIR, and the rough algorithm is given below, though it's best to read through the code simultaneously:
-
For each known procedure in the IR, produce an intra-procedural CFG for that procedure
a. Start with
CfgFunctionEntryNodeb. If this procedure has no contents, then connect it directly to an
CfgFunctionExitNode. If this happens it is likely the case that we choose to treat this function as a stub (e.g., in the case of library functions such asprintf)c. Recursively visit blocks within this procedure.
ci. If the block has no statements, then treat its jump as the start of the block. If this is a GoTo then use a ghost node as the start of the block.
cii. If the block has at least 1 statement, then iterate through them, linking each statement to the next via
RegularEdges. Link the last statement in the sequence to the jump.ciii. After processing statements (if there were any), resolve the call. Targets of calls are blocks: if we have visited the target before, then create an edge between this call and the start of that block and return. Otherwise, visit that node - thus the recursive nature.
-
While not at the specified in-line depth, for each leaf call node, inline that call
-
For all leftover leaf call nodes, link the calls to their associated target procedures via an
InterprocCallEdge
Below are some explanations for features of the CFG.
Many inter-procedural analyses require a notion of context, to track how "deep" into procedure calls you are (e.g., a call stack). This lets them analyse calls to the same function that may affect memory / registers differently, and analyse those effects.
To accomplish this, we can either have the CFG keep track of how deep into a function call it is, or we can require analyses to implement some form of context tracking. The decision was that this would be the job of analyses (with the notable exception of in-lining, which is a form of context creation done at the CFG level, though this is inefficient and not depended upon).
There are a couple reasons for this:
-
If the CFG were to implement this, then it would need to be stateful, and it would need to provide a way for analyses to walk the CFG. This has two detractors:
a. The CFG's state would need to be reset on each analysis run - this is akin to recreating the CFG for each run of analyses, which is one of the problems we had before that this CFG structure sought to solve.
b. The API for walking the CFG would change considerably - it would require a refactor of how both the analyses and CFG work in a way that deviates from TIP, which is a tool we seek to align ourselves with.
(a.) and (b.) are dependent on each other
-
By moving this responsibility from the CFG to the analyses we permit different notions of context sensitivity to be implemented. Analyses which function better with specific ideas of context sensitivity can then be supported, and these can be fine tuned for the situation. If this were done in the CFG, then different APIs would have to be exposed, and the CFG would potentially become cumbersome.
As of writing, nodes store four distinct sets - one each of intra and inter procedural edges for outgoing and incoming edges. There is an immediate problem with this on the amount of space it takes to store these, and why they couldn't be combined. The answer is that they can be combined, though this creates its own problems. We could instead store all intra / inter procedural edges for a node in the same outgoing / incoming set and upon request filter these out dependent on whether we walk the intra- or inter- procedural CFG. The complication with this is that the accessors succ and pred which would perform this filter are called quite frequently within analyses, and filter can be a computationally expensive function. Thus it was chosen to cache these results to save on extra computations - this can be changed in future if need be.
TODO: this will change when the analyses are restructured.
https://uq-pac.github.io/bil-to-boogie-translator/analysis/solvers/LatticeSolver.html