브라우저 화면에 웹을 그리는 전체적인 과정

-
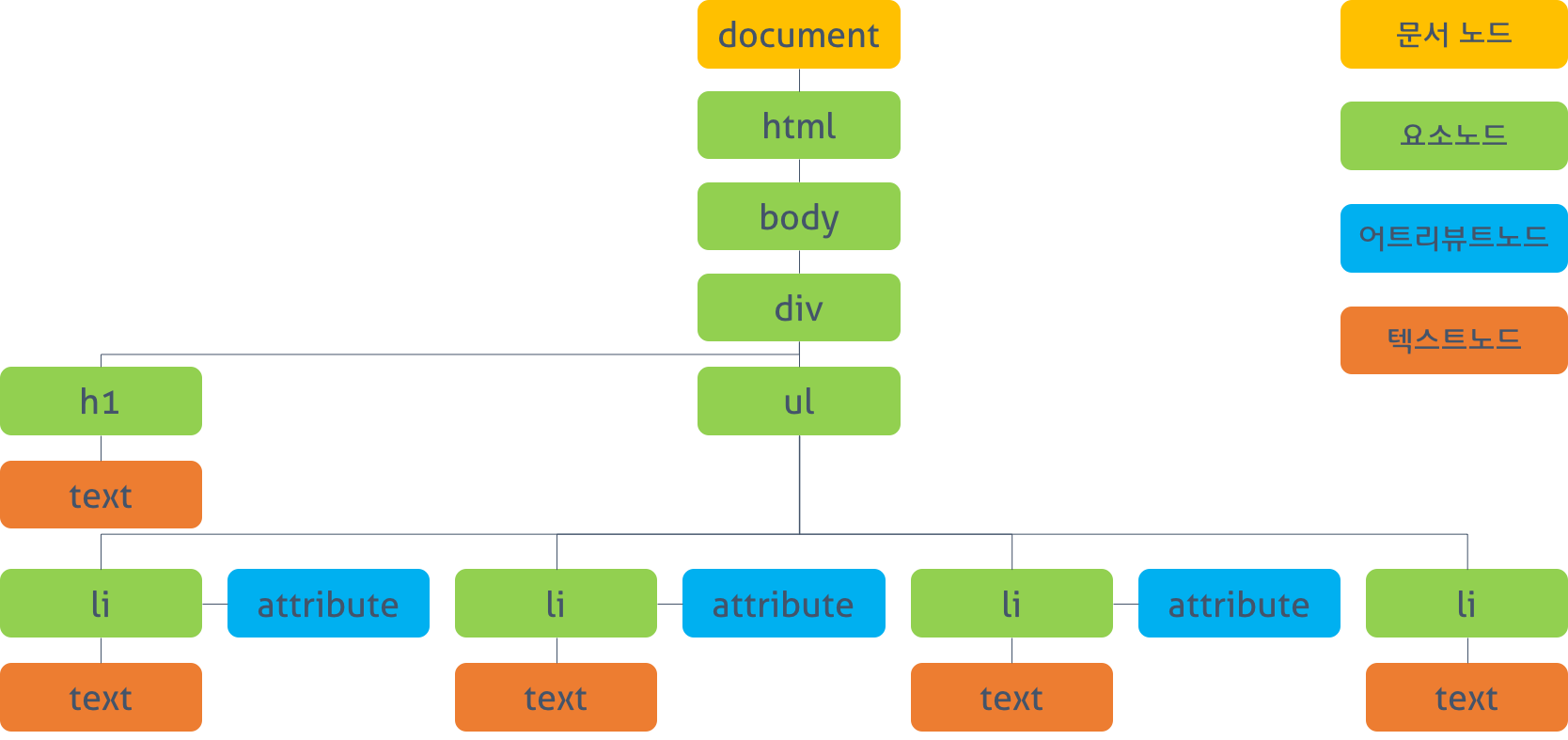
DOM(Document Object Model) 생성
-
Document Node : 최상위에 존재하며 DOM 트리에 접근하기 위한 Root Node
-
Element Node : h1, div 같은 태그를 가리키는 Node
-
Attribute Node : class, id , href, style 같은 속성에 대한 Node
-
Text Node :
<div> Hello World </div>에서 태그 안에 감싸진 Hello Wolrd를 가리키는 Node
다음 네 단계를 거쳐서, 트리 구조 모양의 DOM이 생성된다.
1. Conversion(변환) : HTML의 raw bytes(원시 바이트)형태로 서버에서 받아온다. 해당 파일의 인코딩(예:UTF-8)에 따라 문자로 변환한다. 2. Tokenizing(토큰화) : 브라우저가 변환된 문자열을 HTML5 표준에 따라 고유 토큰으로 변환한다. 3. Lexing(렉싱) : 이 토큰들은 다시 각각의 특성과 규칙을 정의한 object(객체) “노드”로 변환된다. 4. DOM 생성 : HTML 마크업이 여러 태그 간의 관계를 나타내기 때문에 DOM은 트리 구조를 가진다. 따라서, DOM에 포함된 노드 또한 서로 관계를 가지게 된다. 다시 말해서, 노드의 상대적인 관계를 이용하면, 하나의 노드를 기준으로 모든 노드에 접근할 수 있다.DOM 트리는 문서 마크업의 속성과 관계를 포함하지만, 렌더링될 때 표시되는 모습에 대해서는 CSSOM이 관여한다.
-
-
CSSOM(CSS Object Model) 생성
- 1.에서 DOM을 생성할 때 거쳤던 과정을 그대로 CSS에 반복한다. 그 결과로 브라우저가 이해하고 처리할 수 있는 형식(Style Rules)으로 변환된다.
- CSSOM 역시 트리 구조를 가지는데, 그 이유는, ‘하향식’으로 규칙을 적용하기 때문이다. 루트(body)부터 시작해서, 트리를 만들어 가는 방식이다. 모든 요소의 최종 스타일을 확정할 때 브라우저는 해당 노드에 적용 가능한 가장 일반적인 규칙으로 시작한 후에 더욱 구체적인 규칙을 적용한다.
-
Render Tree(DOM + CSSOM) 생성 - Attachment
- DOM 트리의 루트(html)에서 시작해서, 페이지에 표시되는 각각의 노드에 일치하는 CSSOM 규칙을 찾아 붙인다.
- 이때, 렌더링 트리에는 페이지를 렌더링하는 데 필요한 가시적인 노드만 포함된다. 따라서, 메타 태그나 스크립트 태그 같은 노드나
display : none으로 스타일이 지정된 노드는 제외된다. 그러나,visibility : hidden스타일이 적용된 노드는 보이지는 않지만 공간을 차지하므로, 렌더링 트리에 포함된다. - 이 렌더링 트리가 화면에서 최종적으로 그리는 내용이 된다.
-
Render Tree 배치 - Layout
- 지금까지의 과정을 요약하면, 브라우저가 화면에 표시할 노드와 해당 노드의 스타일을 계산하면서, 하나의 그룹으로 묶어서 렌더링 트리를 만든 것이다.
- 레이아웃은 브라우저가 화면에 그리기 전에, 이 노드들을 정확한 위치와 크기로 나타내기 위해서 계산하는 과정이다. 이때, 모든 상대적인 값(예:%단위)은 절대적인 값(예:px단위)로 변환된다.
-
Render Tree 그리기 - Painting
- 렌더링 트리의 각 노드를 화면의 픽셀로 나타내는 작업이다.

-
head안에 script 포함
→ html parsing이 blocking되어 사용자가 웹 사이트를 보는 데까지 많은 시간이 걸림
-
body 끝부분에 script 포함
→ 웹사이트가 js에 많이 의존적이라면 정상적인 페이지를 보기까지 시간이 많이 걸림
-
async
→ fetching이 병렬적으로 일어나기때문에 다운로드 시간을 절약할 수 있음.
html파싱전에 실행이 되기때문에 위험할 수 있음
여전히 blocking이 있기때문에 웹페이지 보여주는데에 시간이 걸림
순서에 의존적인 스크립트라면 제대로 실행 알될수도...
-
defer ✪
→ fetching이 병렬적으로 일어난 후 parsing 끝에 실행
다운로드 순서에 상관없이 정의된 순서대로 실행
-
동적 스크립트
자바스크립트를 사용하면 문서에 스크립트를 동적으로 추가하는 것
let script = document.createElement('script'); script.src = "/article/script-async-defer/long.js"; document.body.append(script); // (*)*
관련 요소가 문서에 추가되자 마자 다운로드가 시작됨
동적 스크립트는 기본적으로 ‘async’ 스크립트처럼 행동함
하지만 script.async=false가 있으면 실행은 '문서에 추가된 순서’대로 됨