主题模型(Topic Model)是以无监督学习的方式对文档的隐含语义结构进行聚类的统计模型,其中SLDA(Sentence-LDA)是主题模型的一种。SLDA是LDA主题模型的扩展,LDA假设每个单词对应一个主题,而SLDA假设每个句子对应一个主题。本Module基于的数据集为百度自建的网页领域数据集。
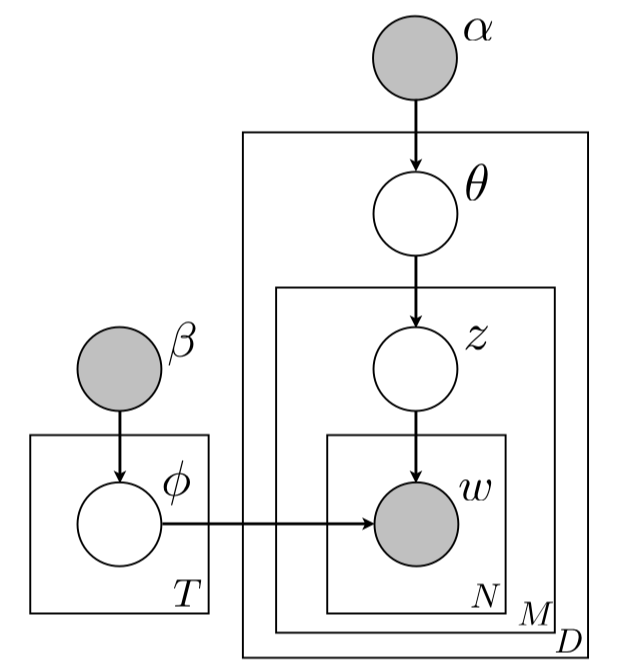
更多详情请参考SLDA论文。
注:该Module由第三方开发者DesmonDay贡献。
用于推理出文档的主题分布。
参数
- document(str): 输入文档。
返回
- results(list): 包含主题分布下各个主题ID和对应的概率分布。其中,list的基本元素为dict,dict的key为主题ID,value为各个主题ID对应的概率。
用于展示出每个主题下对应的关键词,可配合推理主题分布的API使用。
参数
- topic_id(int): 主题ID。
- k(int): 需要知道对应主题的前k个关键词。
返回
- results(dict): 返回对应文档的前k个关键词,以及各个关键词在文档中的出现概率。
这里展示API的使用示例。
import paddlehub as hub
slda_webpage = hub.Module(name="slda_webpage")
topic_dist = slda_webpage.infer_doc_topic_distribution("百度是全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。")
# [{'topic id': 4687, 'distribution': 0.38333333333333336},
# {'topic id': 2508, 'distribution': 0.31666666666666665},
# {'topic id': 2871, 'distribution': 0.15},
# {'topic id': 2292, 'distribution': 0.11666666666666667},
# {'topic id': 4410, 'distribution': 0.016666666666666666},
# {'topic id': 4676, 'distribution': 0.016666666666666666}]
keywords = slda_webpage.show_topic_keywords(topic_id=4687)
# {'市场': 0.07413332566788851,
# '增长': 0.045259383167567974,
# '规模': 0.030225253512468797,
# '用户': 0.02278765317990645,
# '超过': 0.019395970334729278,
# '份额': 0.019091932266952005,
# '全球': 0.018879934814238216,
# '手机': 0.01252139322404175,
# '美元': 0.01202885155424257,
# '收入': 0.011096560279140084}https://github.com/baidu/Familia
paddlepaddle >= 1.8.2
paddlehub >= 1.8.0
-
1.0.0
初始发布