- ref:
-
- 论文反复强调understandability,在选择算法组成时优先从这个方面考虑,但不免主观,使用下面两个技术让其更合适
- Decomposing the problem问题划分:比如Raft将其划分成领导选举、日志变更、安全和成员变更几个子问题
- Simplifying the state space
- trade-off:比如Raft引入随机性,虽然会增加不确定情况,但是简化了状态空间
- 论文反复强调understandability,在选择算法组成时优先从这个方面考虑,但不免主观,使用下面两个技术让其更合适
-
raft theory:Raft作者之一的博士论文,据说是说了Raft的更多细节,但是规模太大看不了。
-
可视化:
- majority:集群中的server在Raft启动时就相互注册,如果出现网络分区,小分区的server永远达不到majority的条件,因为这里的大多数是对当初注册进整个集群的server的数量的。
-
Raft是一个管理Replicated Log的Consensus Algorithm
-
什么是Replication:笔记
-
什么是Consensus:笔记
-
什么是Paxos:在Raft之前,Paxos几乎是一致性算法的代名词
- 缺点:
- 很难准确理解,即使是对专业研究者和领域教授
- Paxos复杂难懂但是又没有其他适合教学的替代算法
- 很难正确实现,本身复杂加上某些理论描述模糊
- Paxos本身是点对点模型,最后为了性能考虑建议弱领导力的模型,但是在实际应用中通常是中心式的,所以There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system. . . . the final system will be based on an un-proven protocol(注意Paxos的正确性是得到证明的,这里的un-proven是因为实现和理论的gap太大了)
- 很难准确理解,即使是对专业研究者和领域教授
从工业界和学术界需求出发,斯坦福大学博士生Diego Ongaro及其导师John Ousterhout提出了Raft算法(2013年),它的最大设计目标是可理解性understandability
- 但是由于Raft是中心式的,所以理论上其性能是比不上Paxos的
- 缺点:
-
Raft的安全性已经得到证明和验证,Raft的性能已经得到比较。
-
Raft会以库的形式存在于服务中。
- 约定:
- 我们称集群中的机器为server,集群外的我们服务的就是client。
- server有三个状态:leader,follower,candidate
- 一般情况下:只有一个leader,其他的都是follower
通常集群server数量为5,这样系统可以tolerate two failures。
-
leader简介:
- handle all client requests
如果client向follower发请求,follower会将其重定向到leader
- handle all client requests
-
follower简介:
- passive的,不发request,只response to request from leader and candidates
-
candidate简介:
转换如下图
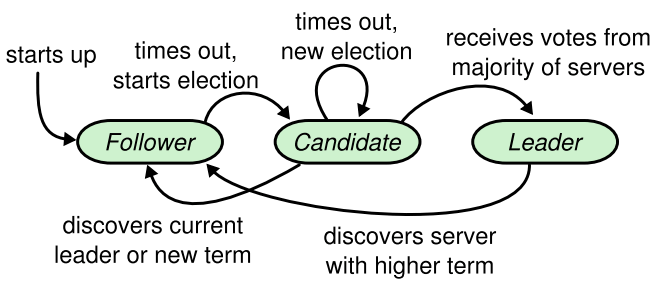
-
terms任期:
从下图可以看到
-
term由连续的整数表示
-
有两种类型term
- election -> normal operation:一个及以上candidate尝试变成leader,其中一个candidate赢得选举,对应的server变成leader
- no emerging leader:发生split vote,即没有leader。很快的开始新一个term
Reft保证每段Term做多只有一个leader
term在raft中发挥一个逻辑锁的作用:每个server维护一个current term数字,其单调增长,当server通信时则进行exchanged
- 如果一个server的current term比另一个小,则小的更新
- 如果candidate或者leader发现它的current term out of date,它们立刻变成follower
- 如果一个server收到request的term小于它的current term,则拒收。
-
-
RPC:没有收到答复则重复,通过并发以提高性能。
RequestVoteRPC:candidate as serverAppendEntrieRPC:leader as server:- replicate log entry
- heartbeat
- 在快照章节还有第三个RPC

-
heartbeat机制:
- server启动时是follower,只有持续从leader收到heartbeat(没有log entry的
AppendEntries),就一直是follower - 如果一个follower在election timeout时间内没有收到heartbeat则开启一个新的term
- server启动时是follower,只有持续从leader收到heartbeat(没有log entry的
-
选举流程:
- Follower增大自己的current term,并切换到candidate状态,选举自己作为leader,并发地向集群中的其他结点发送
RequestVote
该Candidate一直持续到:自己或其他赢得选举或者选举分裂/选举超时
-
当一个Candidate收到
AppendEntries,对方的term大于等于自己,则承认其地位,退回到follower,否则拒绝,继续。 -
获胜条件:获得集群中大多数server对同一term的vote
-
选举规则:对于给定的term,一个follower只能投递一票,follower投票的标准是First-Come-First-Served
保证一个term只有一个leader
- 当一个Candidate赢得选举,其变成Leader,并向其他server发送heatbbeat
-
readomized election timeout随机选举超时:
选举分裂:如果有多个follower几乎同时发起选举,此时选票很分散,每个人都不能达成获胜条件,如果同时进入下一个任期,很可能还是这样(甚至更差),需要引入其他机制。
- 在follower等待heartbeat期也保证大部分只有一个follower变成Candidate
- 用于选举期间,论文推荐使用150–300ms
- Follower增大自己的current term,并切换到candidate状态,选举自己作为leader,并发地向集群中的其他结点发送
一个leader被选举出来后,它就开始服务client的request,leader有职责将log entry复制到集群的servers上。
-
Pre:
- cmd:即command,每个client request包含一个cmd,是client给到cluster的
- log entry(或者简称entry):leader将client给的cmd包装进log entry中作为raft的处理单位
- logs(有时用log):即日志文件,由Log Entry组成,每个server上都有
-
Log Entry数据结构:
- Index:log entry在logs中的唯一递增正整数编号(从1开始)
- Term:创建该log entry的leader的term number
- Command(以下简称cmd,但是代码中使用成员名Command):如上
-
复制流程:
-
leader将client request中的cmd包装成log entry并追加到自己的logs中,然后并发地使用
AppendEntries将其发送给集群中的其他结点。- leader会无限重发(即使它已经给client response了)直到所有的follower都存储了所有log entris
follower crash, follower sun 慢, 网络丢包
- leader会无限重发(即使它已经给client response了)直到所有的follower都存储了所有log entris
-
当这个entry已经被safely replicated时,leader将这个entry应用到自己的状态机中,并将结果返回给client
-
commited提交:如果leader觉得一个entry是safe时则将其应用到状态机中,此即为提交。
- Raft保证entry是持久的且最终被应用到集群中所有的可用的状态机中
- 当leader创建的entry被集群中大多数server复制时提交
- 提交也提交了leader log中所有之前的entry,包括之前任期的entry。
-
leader的heartbeat会携带其已经提交的index最大的entry的index,follower会将对应的在自己logs的entry依次应用到它的状态机中
-
-
-
Log Matching Property保证high level of coherency,保证
-
election safety:最多一个leader可以被选举在一个给定的term
-
leader append-only:leader从来补充覆盖写或者删除entry in its log(leader和它自己)
-
log matching:如果两个logs包含一个entry有同样的index和term,then the logs are identical in all entries up through the given index.
- 如果两个entry在不同的logs中有同样的index和term
-
它们的cmd一样:
证明:对于给定term和给定index,一个leader只会创建一个entry -
它们之前的entry都一样
-
实现:
AppendEntries的consistency check一致性检查:leader带上entry前一个entry的index和term,follower如果没有这个”前面的entry“,则拒绝 -
证明:归纳
- 一个空的logs时safety的
- 当logs extend时,一致性检查保证Log Matching Property
所以当
AppendEntries成功返回时,leader就知道follower的log是identical to its own log up through the new entries.
-
-
- 如果两个entry在不同的logs中有同样的index和term
-
Leader Completeness:如果一个entry被commited,则其将会出现在任何一个term更高的leader的logs中
-
state machine safety:如果server已经将一个entry(它有一个index)应用,则其他server不会有任何一个将不同的entry去应用使用同一个index
-
-
Log Inconsistent
-
什么时候会发生:Leader Crash
-
在
AppendEntries的一致性检查失败时暴力全覆盖:- leader找到两者一样的最后一个entry
- 删除follower这个点之后的任何entry
- 发送leader这个点之后的所有entry
-
nextIndex:leader为每个follower维护一个nextIndex表示leader将会发送给follower的下一个entry的index当一个leader初始化时,该值为它自己的下一个entry索引,如果follower log inconsistent,则
AppendEntries的一致性检查会错误,此时leader则减少对应的nextIndex然后重发Appendentries,最终nextIndex将会变成上面提到的那个点,算法逻辑闭环。 -
优化:follower不仅返回失败,还返回失败的entry的term,leader则跳过该term的所有entry,不知道怎么证明。
-
-
选举限制:为实现日志匹配属性的“如果一个entry已经被commited了,那么它将出现在任何一个term更高的leader的log中”
ref: paper.5.4.1
-
up-to-data:
def up_to_data(lhs: log, rhs: log) { if (lhs[-1].term == rhs[-1].term) { return len(lhs) > len(rhs) } return lhs[-1].term > rhs[-1].term }
-
在领导选举的
RequestVote中,其包含candidate的log的info,如果follower的log较于candidate的更up-to-data,则不给其投票。
-
ref: paper.6
ref: paper.7
-
Snapshot
-
Snapshot metadata:
last included indexandlast included term所以它依然可以支持
AppendEntries的一致性检测。 -
InstallSnapshotRPC:Invoked by leader to send chunks of a snapshot a follower.- Leaders always send chunks in order.
ref: paper.8
-
find the cluster leader:client开始会随机选择一个server连接,如果是follower,则拒绝request并返回leader信息(most recent leader is has heard from(
AppendEntriesrequests include the network address of the leader))- 在follower视角下,它可能向client返回错误的leader info,比如
heartbear -> client request -> leader crash -> follower response,此时就会发生client向一个crash的leader发送消息。这样的情况在client request time-out时,它会再随机选择server进行连接。至此闭环。
- 在follower视角下,它可能向client返回错误的leader info,比如
-
support linearizable semantics:
-
什么是linearizable semantics?client's opeator应该在发起invocation和得到response之间的某个点被精准的执行一次。
-
可能出现的问题:leader在committed之后、response之前crash,则会导致response重发,新的leader会有两个同样的命令。
-
解决方案:client为每一个cmd设置一个unique serial number,然后状态机跟踪最新的serial number和其res,如果收到一个cmd它的serial number已经被执行了,则立刻回答而不重新执行
这里有个问题,就是状态机只track最新的,但是收到的cmd可能不是最新的,难道直接返回最新的res么?还是说其他的一致性保证正确性?或者这么理解,这是linearizable的保证,Linearizable reads must not return stale data.
-
read-only cmd怎么保证linearizable?
- 可能出现的问题,leader在response时不知道自己已经被取代了,则返回了脏数据
两个机制保证
- leader在它的任期开始时向log中committed a blank no-op entry
- leader在response rand-only request之前先和集群中的majority进行一个exchange heartbeat
这步可以融合在普通的heartbeat中,但是那样需要依赖时序来保证安全。
-