Проект признан лучшим в окружном хакатоне "Цифровой прорыв: Сезон Искуственный интеллект" 2024 г.

Официальный результат на странице Хакатона
Мы разработали систему прогнозирования отказов дисков на основе машинного обучения, которая позволяет оперативно управлять запасами оборудования в ЦОД. В основе решения лежит регрессионная модель AutoML Gluon, обученная на исторических данных о дисках. Решение включает удобный интерфейс командной строки (CLI) для запуска обучения, дообучения и предсказаний, обеспечивая гибкость и адаптивность системы. Мы проводили кросс-валидацию для повышения точности модели и использовали негативное семплирование для дисков, проработавших более двух лет без отказов.
- Модель: AutoML Gluon, задача регрессии.
- Стратегия семплирования: Негативное семплирование для дисков, не вышедших из строя за более чем 2 года.
- Генерация фичей: На основе статистических данных, собранных с дисков (среднее время работы, количество ошибок, нагрузка и т.д.).
- Кросс-валидация: Использовалась для повышения стабильности и точности модели.
- UI-сервис: Утилита командной строки (CLI), позволяющая запускать обучение, дообучение на новых данных и делать прогнозы по дискам.
- Мониторинг и логирование: Система ведет журнал работы модели, отслеживая точность предсказаний и обновления модели.
Интеграция кросс-валидации, негативного семплирования и автоматической генерации фичей в единую платформу с удобным интерфейсом для предсказания отказов оборудования.
Этот скрипт представляет собой CLI (Command Line Interface) инструмент для обучения и предсказания моделей с использованием библиотеки AutoGluon. Он позволяет пользователю выполнять три основные операции: обучение модели, предсказание результатов и комбинацию этих двух операций (обучение и предсказание).
Перед использованием скрипта убедитесь, что у вас установлены все необходимые зависимости. Вы можете установить их с помощью pip:
pip install -r requirements.txt- file_path: (обязательный аргумент) Путь к входному файлу, который будет использоваться для обучения или предсказания.
- second_file_path: (опциональный аргумент) Путь ко второму входному файлу, который используется только в случае вызова метода fit_predict.
- --fit: (опция) Флаг, указывающий на необходимость вызова метода обучения модели.
- --predict: (опция) Флаг, указывающий на необходимость вызова метода предсказания модели.
- --fit_predict: (опция) Флаг, указывающий на необходимость вызова метода обучения и предсказания модели.
- --preprocessing: (опция) Флаг, указывающий на необходимость обработки данных, подается папка с ежедневными наблюдениями.
- --help: (опция) Флаг, вызов функции помощи.
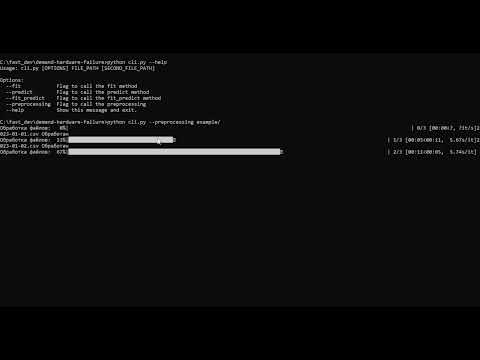
python cli.py path/to/folder_data --preprocessing
Этот пример запускает процесс обработки данных для модели, используя данные из папки path/to/folder_data, на выходе получаем computing_target_data.csv
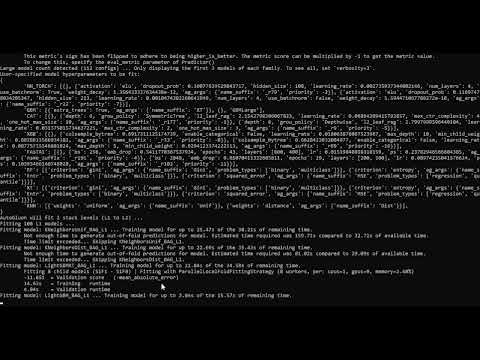
python cli.py path/to/train_data.csv --fit
Этот пример запускает процесс обучения модели, используя данные из файла train_data.csv. На выходе ожидается путь к файлу с сохраненными весами.
python cli.py path/to/test_data.csv --predict
Этот пример запускает процесс предсказания результатов, используя данные из файла test_data.csv. Прежде запускается локальная модель, её результат сохраняется в папку и запускает глобальную модель, её результат выводться в консоль.
python cli.py path/to/train_data.csv path/to/test_data.csv --fit_predict
Этот пример запускает процесс обучения и предсказания, используя данные из файлов train_data.csv и test_data.csv. Обратите внимание, что для этой операции оба пути к файлам являются обязательными.


Генерирует строки из CSV-файла
Генерирует строки из папки с CSV-файлов
Генерирует модели FailureInfo() по всем CSV-файлам в папке folder
@dataclass
class FailureInfo:
serial_number: str
model: str
start_date: datetime
failure_date: datetimeИнициализация SQLite3 базы данных и таблицы failure_info, содержащая четыре колонки:
serial_number- серийный номерmodel- модельstart_date- дата начала работыfailure_date- дата отказа
Заполняет таблицу failure_info соответствующими сущностями
Используется как обучение или дообучение
Получает список перцентилей дней отказов по каждой модели, опираясь на таблицу failure_info
Используется как предсказание