DSC160 Data Science and the Arts - Midterm Project Repository - Spring 2020
Project Team Members:
- Mizuki Kadowaki, [email protected]
- Anurag Pamuru, [email protected]
- Shutong Li, [email protected]
- Rakesh Senthilvelan, [email protected]
- Praveen Nair, [email protected]
(10 points)
For the project proposal, please write a short abstract addressing the questions below. You should replace the entire contents of this section with one to two paragraphs addressing the following:
- What is the data set that you are going to analyze?
- What is your research question?
- What is your hypothesis about the results?
- What features of the data will you use to address your question?
- What techniques and software tools will you use to extract these features?
- What analytic techniques will you use?
- What forms will your results take? (graphs, charts, images, sonification, Wordles, etc)
- How are you expanding on topics we have covered in class?
- Why is it interesting? (personally, culturally, politically, other)
For this project, we are going to analyze a broad group of influential hip-hop songs from the 1970s to today. The goal of the project is to cluster hip-hop songs based on a variety of audio features to quantify their similarities and differences, and to determine whether popular terms for classifying hip hop (based on factors like period, geography, and subgenre) are visible in these audio features. Our hypothesis is that artists and songs that share these sorts of qualitative similarities will also be considered more similar in audio analysis, but also that stylistic groupings (such as soul rap and trap music) will be stronger than identity-based groupings (for example, East vs. West Coast).
In order to conduct this analysis, we will use the Python package librosa, which will allow us to extract features such as mel-frequency cepstral coefficients (MFCC’s), chroma features, zero crossing rate, and other spectral features. Then, using a dimensionality reduction technique such as PCA, we can use the package sklearn to cluster and classify our data based on the extracted features. The results of this clustering should be available as graphs based on the dimensional reduction, within which we can make distinctions for different clusters. This project expands on the feature extraction we did in class by harnessing the domain knowledge we have about hip-hop classification and history to determine whether the sorts of classifications that listeners of hip-hop make have an underlying basis in measurable audio features. This analysis is also valuable in that it provides a quantitative way to understand high-level trends in hip-hop from its inception until today, and to also understand what previously unrecognized similarities there might be between works that we would previously not associate together.
(10 points)
This section will describe your data and its origins. Each item should contain a name of the data source, a link to the source, and any necessary background information such as:
- What is your cultural data source?
- When was it made?
- Who created the works?
- Is it digital native, or is it some kind of scan, recording, photo, etc., of an analog form?
The cultural data source we went with is a the top 2 hip-hop songs for each year from 1980 to 2020 as streamed on Spotify, a music streaming application. Alongside all of these songs, we added in songs from influential artists such as Kanye West, Jay-Z, 2Pac, and Travis Scott who did not show up on the Spotify data in order to further show differentiable features of different eras of music within the eras and account for highly influential figures in the era who were very popular during the years analyzed but do not perform as well on Spotify. The dataset was made on May 1, 2020 by drawing from the Spotify API and manual research done on different highly influential artists in the genre. The manual data analysis largely draws from Billboard charts from the years 2002 to 2020 and research on hip-hop centric websites such as VH1. The works were created by a wide variety of hip-hop artists who produced the music between 1980 and 2020. The dataset encompasses numerous subgenres and styles within hip-hop through the artists represented within the set. The music is all digital native: it has been recorded and released in the form, which allows for more accurate analysis of the audio data that will be drawn from these songs for this project. The music itself was extracted from YouTube using youtube-dl. In the /data/ subfolder, however, since it would be undesirable to put all the songs up on GitHub, we instead just used a csv of the extracted features, full_data.csv.
(20 points)
This section will link to the various code for your project (stored within this repository). Your code should be executable on datahub, should we choose to replicate your result. This includes code for:
- data acquisition/scraping
- cleaning
- analysis
- generating results.
Link each of your notebooks or .py files within this section, and provide a brief explanation of what the code does. Reading this section we should have a sense of how to run your code.
Data acquisition and cleaning is handled by the feature_extraction.ipynb. This code first utilizes Spotify's API in order to obtain streaming data on hip-hop songs released between 1980 and 2020. This notebook isn't runnable because it requires use of Spotify's API, as well as the local song data downloaded earlier. Using the JSON data, it is formatted into a Pandas Dataframe. The first cleaning step was to replace any duplicate songs. Then, we needed to replace any songs that were not hip-hop, as Spotify tended to mix in R&B and funk songs into the mix as well, with the 3rd most popular song in the genre from that year. To further develop the dataset, we added in songs that were very representative of hip-hop in their years but did not make the Spotify list: songs by artists such as Kendrick Lamar, Kanye West, Jay-Z, 2Pac, Dr. Dre, Travis Scott, Lil Pump, Lil Nas X, and Pete Rock. Using Spotify's built-in API, we then extracted audio features with the purpose of augmenting future features. From here, we started matching audio files with their respective entries in the dataset then created a function to get features such as MFCCs, chroma features, zero crossing rate, spectral bandwidth, spectral centroid, and spectral rolloff. Now, we had the dataset we needed to move forward.
For analysis, in music_PCA.ipynb, we worked to look and see if there were any clusters, trends, or associations within the data. The first step taken was to use PCA dimensionality reduction to reduce the data to two dimensions. This was then graphed in order to generate the results that are discussed later on. Next, we used PCA again to reduce the data down further to one dimension that plots against song year to see if any associations could be related to the year of the song's release. Finally, in results/bokeh_plots.ipynb, we plotted the associations between the features we extracted from the songs using librosa tools as well as those given to us by Spotify's API. In this case, we developed a scatter matrix to display this. The results are discussed in the next section.
(30 points)
Interactive versions of all charts are in /results/bokeh_plots.
The following is the result of clustering the 1st and 2nd PCA dimension of our feature space. There is little apparent cluster among the points.

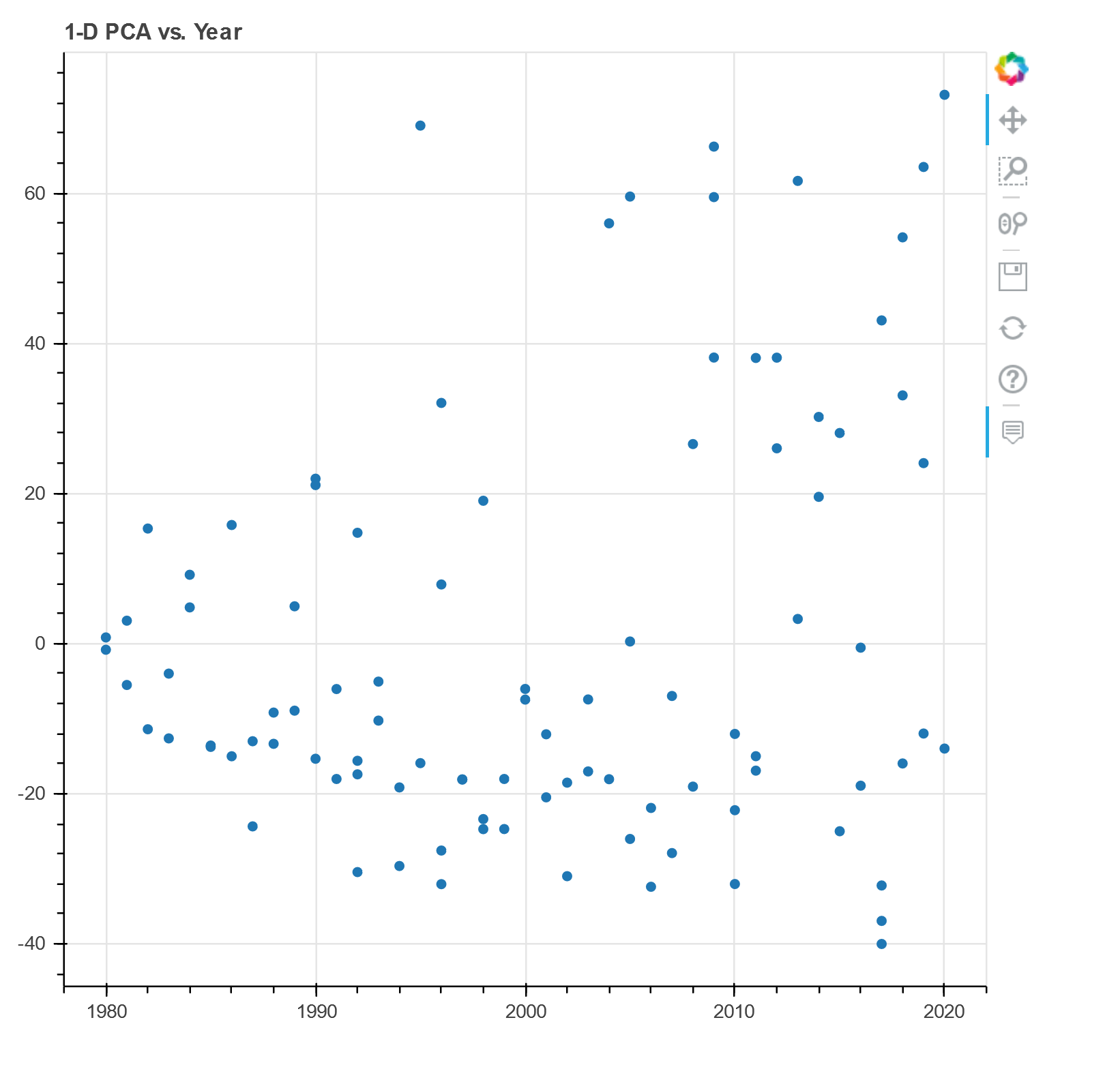
This next plot uses PCA once again to reduce our data to one dimension, then plots that dimension against song year. We observe an association between the two. Subsequently, we verify the correlation with a correlation coefficient of 0.3583 and a p-value of 0.0003.
In order to determine some more usable insights, we compared the associations between all of the named features (the spectral features and Spotify's song attributes). This yields the following scatter matrix:
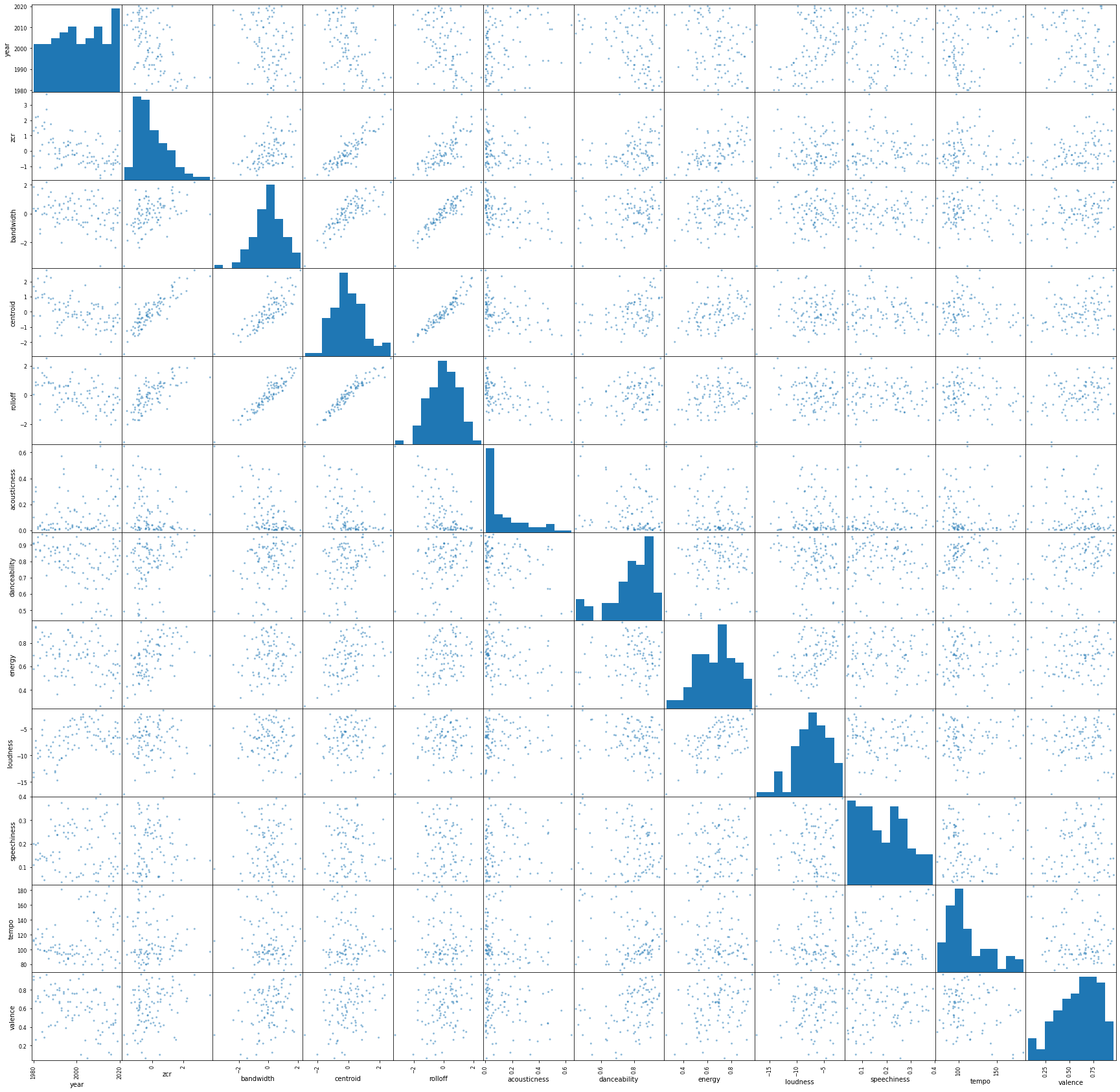
Interactive plots discussing some of the more interesting associations are in results/bokeh_plots. Please run and look at this notebook -- it's actually where most of the actual results work is (bokeh plots aren't embeddable in this readme or in the Github view of .ipynb files).
(30 points, three to five paragraphs)
As a first step to visualize the music from our dataset, we used the bokeh library for all of the named features (in other words, everything except for the MFCC and chroma features.)
This is a culturally relevant analysis of the evolution of Hip Hop. In the 1960s, New York was affected by the white flight and a decline in industry and commerce and in the 1970s, New York City entered a fiscal crisis. The emergence of early hip hop artists like Afrika Bambaataa and the Sugarhill Gang led to the birth of an East Coast-centric sound in the late 1970s. As Hip Hop gained popularity and spread to South Central LA, there was a rivalry between rappers of the east and the west coast. With rappers such as Snoop Dogg, Easy E, Ice Cube, and, most famously, 2Pac playing into a budding rivalry between the East’s distinct flow and the West’s preferred “gangsta rap”. Hip-Hop styles evolved separately in the East and West. Although these two were the first major divide, countless sub-movements, such as Mos Def and Talib Kweli’s “Conscious Rap”, Black Street’s “new jack swing”, Afrocentrism, and Native Tongues, constantly redefined what it meant to be a hip hop artist. Artists like Puff Daddy, Biggie Smalls, and Eminem brought hip-hop into the norm in the late 90s with increased presence in the 2000s.Since its inception, hip hop has become a borderless and universal cultural experience as a form of celebration, protest, and culture. In its journey from Harlem to the globe at large, we will analyze several key artists through hip hop’s many eras. Whether it be the aforementioned East vs. West divide, the eclectic beats and flow of the 90s, or the sample heavy tracks of contemporary artists like Drake and Kanye West.
Our final results seemed to display no characteristics of similarity, distinct style patterns over time or any clustering, despite the vast array of features used for analysis. By using PCA ( principal component analysis) to project the data down to lower dimensions, we minimized the data footprint to facilitate processing. Our first type of analysis revolved around using the two features generated by PCA to see if any clusters emerged. Our clustering algorithm of choice was k-Means. Our chosen k was 4 and yielded clusters that seemed to show no correlation with a certain decade or any recognizable movement. However, this may have more to do with our methods of analysis than it does with hip hop itself. The fact that a song from the late 1990s can be clustered with a song released only months ago suggests that there is a vast amount of “conversation” in hip hop. For example, Drake’s hit “Nice for What” off his Scorpion album heavily samples Lauryn Hill’s 90s hit “Ex Factor”. As such, hip hop is dynamic and changing but also deeply cognizant of its past. Furthermore, concepts like zero crossing, spectral rolloff and the other features generated by bokeh might be considered less important in the analysis of rap than NLP. Some NLP analysis could be a feature that greatly adds to future research. The use of dated slang could point to an older song while the same can be said for contemporary rap. Additionally, since rap is closer to spoken word perhaps the instrumental tracks could distract the algorithm from analyzing the actual flow of the artist and instead focus on the beat of the song. This noise is a possible confounding factor that may have affected our research.
The cultural relevance of this is that it shows the diversity that exists within hip-hop, even within the relatively small subset we looked into within this project. There are numerous different subgenres of hip-hop that are represented within this dataset, and there are many more that exist that were not covered here like drill, crunk, and battle rap amongst others. It indicates that hip-hop is a genre that is incredibly diverse and a genre that is often not completely derivative of other things within that genre within the year. The type of analysis we did looking for clusters based on years might be more effective within each individual subgenre, but hip-hop as a whole is too diverse and unique.
Our computational approach to this differs from a lot of computational approaches to the topic as it is focused a lot on the audio data of hip-hop, rather than the lyrics. There are numerous blog posts that look into the lyrics of hip-hop and run analysis based off of those, but we have not seen many that look into the audio features. While there are many who subjectively go into the details of aspects of hip-hop song like beats, samples, etc., we have seen few who go into the audio features such as MFCCs and chroma features.
The first paragraph should be a short summary describing your results.
The subsequent paragraphs could address questions including:
- Why is this culturally relevant?
- How does your computational approach differ from the traditional art historical, musicological, manuel/subjective approach to analyzing your cultural subject?
- How do you think the original artists/musicians would respond to this type of analysis? Would it change/inform their practice in some way?
- How do your results relate to broader social, cultural, economic political, etc., issues?
- In what future directions could you expand this work?
Provide an account of individual members and their efforts/contributions to the specific tasks you accomplished.
-
Praveen: Created dataset from Spotify API, downloaded data, extracted features, and visualized in Bokeh.
-
Shutong: EDA, Dim reduciton, and clustering.
-
Rakesh: Data, Code, Results, and parts of Discussion section
-
Anurag: Discussion, parts of Cultural Analysis, Confounding factors argument
-Mizuki: Discussion, Historical context, parts of Cultural Analysis
Any implementation details or notes we need to repeat your work.
Spotipy is used in this, which requires access to Spotify's API in order properly run the project. You would also need to generate a Spotify API token in order to use the API -- we've cut ours out since it's private information, so the code/feature_extraction.ipynb notebook is not actually runnable right now. We also used Bokeh for visualization, Librosa for extracting audio features, scikit-learn for dimensionality reduction, and pandas for pretty much everything. All code was run within Jupyter notebooks.
References to any papers, techniques, repositories you used:
- Papers
- Repositories
- Blog posts
In addition to the lectures and exercises from this class that we used to direct the workflow of this project, we also utilized Spotify's API documentation, Bokeh documentation, Librosa documentation, and scikit-learn documentation. We also couldn't have extracted the data without youtube-dl.
In doing research on how our work differs from others, we consulted the following projects and people: