
Deep Vision-Based Framework for Coastal Flood Prediction Under Climate Change Impacts and Shoreline Adaptations
Areg Karapetyan, Aaron Chung Hin Chow, Samer Madanat
In light of growing threats posed by climate change in general and sea level rise (SLR) in particular, the necessity for computationally efficient means to estimate and analyze potential coastal flood hazards has become increasingly pressing. Data-driven supervised learning methods serve as promising candidates that can dramatically expedite the process, thereby eliminating the computational bottleneck associated with traditional physics-based hydrodynamic simulators. Yet, the development of accurate and reliable coastal flood prediction models, especially those based on Deep Learning (DL) techniques, has been plagued with two major issues: (1) the scarcity of training data and (2) the high-dimensional output required for detailed inundation mapping. To reinforce the arsenal of coastal inundation metamodeling techniques, we present a data-driven framework for synthesizing accurate and reliable DL-based coastal flood prediction models in low-resource learning settings. The core idea behind the framework, which is graphically summarized in Fig. 1 below, is to recast the underlying multi-output regression problem as a computer vision task of translating a two-dimensional segmented grid into a matching grid with real-valued entries corresponding to water depths.

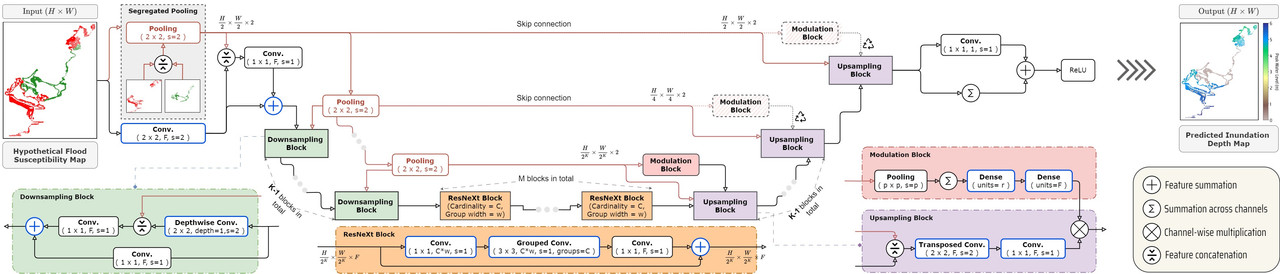
The proposed methodology was tested on different neural networks, including two existing vision models: a fully transformer-based architecture (SWIN-Unet) and a Convolutional Neural Network (CNN) with additive attention gates (Attention U-net). Additionally, we introduce a deep CNN architecture, dubbed Cascaded Pooling and Aggregation Network (CASPIAN), stylized explicitly for the coastal flood prediction problem at hand. The introduced model, illustrated in Fig. 2 below, was designed with a particular focus on its compactness and practicality to cater to resource-constrained scenarios and accessibility aspects. Specifically, featuring as little as
Lastly, we provide a carefully curated database of synthetic flood inundation maps of Abu Dhabi's coast for
This repository contains the complete source code and data for reproducing the results reported in the paper. The proposed framework and models were implemented in tensorflow.keras (v 2.1). The weights of all the trained DL models are included.
The implementations of the SWIN-Unet and Attention U-net were adapted from the keras-unet-collection repository of Yingkai (Kyle) Sha.
For citing this work or the dataset, please use the below references.
@article{karapetyan2024,
title={{Deep Vision-Based Framework for Coastal Flood Prediction Under Climate Change Impacts and Shoreline Adaptations}},
author={Karapetyan,Areg and Chow, Chung Hin Aaron and Madanat, Samer},
journal={arXiv preprint},
year={2024}
}
@data{DVN/M9625R_2024,
author = {Karapetyan, Areg and Chow, Chung Hin Aaron and Madanat, Samer },
publisher = {Harvard Dataverse},
title = {{Simulated Flood Inundation Maps of Abu Dhabi's Coast Under Different Shoreline Protection Scenarios}},
year = {2024},
version = {V1},
doi = {10.7910/DVN/M9625R},
url = {https://doi.org/10.7910/DVN/M9625R}
}
dataincludes the raw data, as well as the datasets (intf.data.Datasetformat) created from it, based on which the coastal flood prediction models were trained, validated and tested.modelscontains the implementation of the models (intensorflow.kerasv 2.1 ) along with the weights of the trained models (inh5format).model_training.ipynbprovides a sample code for training Deep Vision-based coastal flood prediction models with the proposed approach.performance_evaluation.ipynbincludes a sample code for assessing the performance of the developed models and visualizing predictions (see alsoIllustrations.ipynb).
To re-train the aforementioned three models (SWIN-Unet, Attention U-net, CASPIAN):
1: Open model_training.ipynb, select the model and define your desired hyperparameters:
grid_size = 1024
AUTOTUNE = tf.data.AUTOTUNE
batch_size = 2
split = 1
output_1d = False
EPOCHS = 200
MODEL_NAME = "CASPIAN"
LR = 0.0008
MIN_LR = LR/10
WARMUP_EPOCHS = 202: Load the dataset:
ds = {
'train': tf.data.Dataset.load("./data/train_ds_aug_split_%d" % split).map(lambda f,x,y,yf: tf.py_function(clear_ds,
inp=[f,x,y,yf, output_1d],
Tout=[tf.float32, tf.float32])),
'val': tf.data.Dataset.load("./data/val_ds_aug_split_%d" % split).map(lambda f,x,y,yf: tf.py_function(clear_ds,
inp=[f,x,y,yf, output_1d],
Tout=[tf.float32, tf.float32]))
}In the current implementation, the models are trained on pre-augmented datasets. To recreate these datasets run the data/Dataset_construction.ipynb notebook. For a more memory-efficient implementation the augmentation can be performed on the fly during the training by passing a data generator to the model.fit() function.
3: Select the remaining hyperparameters and run the notebook.
TBA