斗牛短视频后端基于go-zero框架开发的一款微服务Web端短视频应用,本项目使用七牛云对象存储(Kodo) 对视频,图片进行存储,智能多媒体服务(Dora)对视频进行处理,Redis作为缓存,Kafka进行异步处理和流量削峰,Etcd作为服务发现与注册中心。同时项目还具有良好的可观测性,使用Jaeger进行全链路追踪,Promethues+Grafana对服务进行性能监控,filebeat+go-stash+elasticsearch+kibana采集日志并且进行可视化呈现,使用docker-compose、Github Action进行CI/CD流程,最后使用traefik作为网关对服务进行负载均衡和转发
- 手机号+验证码一键注册/登录,手机号+密码登录
- 能查看自己和其他用户的基本信息
- 能修改自己的昵称、头像、背景图
- 忘记密码了能重置,登录后能修改自己的密码
- 视频feed流响应速度要快
- 用户能自己上传视频和删除视频
- 能根据热度或者时间对视频排序
- 关键词搜索视频
- 对视频进行分区展示
- 能对视频点赞/取消赞
- 点赞/取消赞不能卡顿
- 用户能对视频评论和嵌套评论其他用户的评论
- 评论的内容要做管控
- 用户能关注/取关其他用户
- 用户能查看自己的关注列表
- 用户能与好友(互相关注)进行简易聊天
后端:
| 功能 | 实现 |
|---|---|
| http框架 | go-zero |
| rpc框架 | go-zero |
| 数据库 | MySQL,Redis |
| 搜索引擎 | elasticsearch |
| 注册中心 | etcd |
| 对象存储 | 七牛云Kodo |
| 视频处理 | 七牛云Dora |
| 链路追踪 | jaeger |
| 服务监控 | prometheus,grafana |
| 消息队列 | kafka |
| 日志搜集 | filebeat,go-stash,elasticsearch,kibana |
| 网关 | traefik |
| 部署 | Docker,docer-compose |
| CI/CD | Github Action |
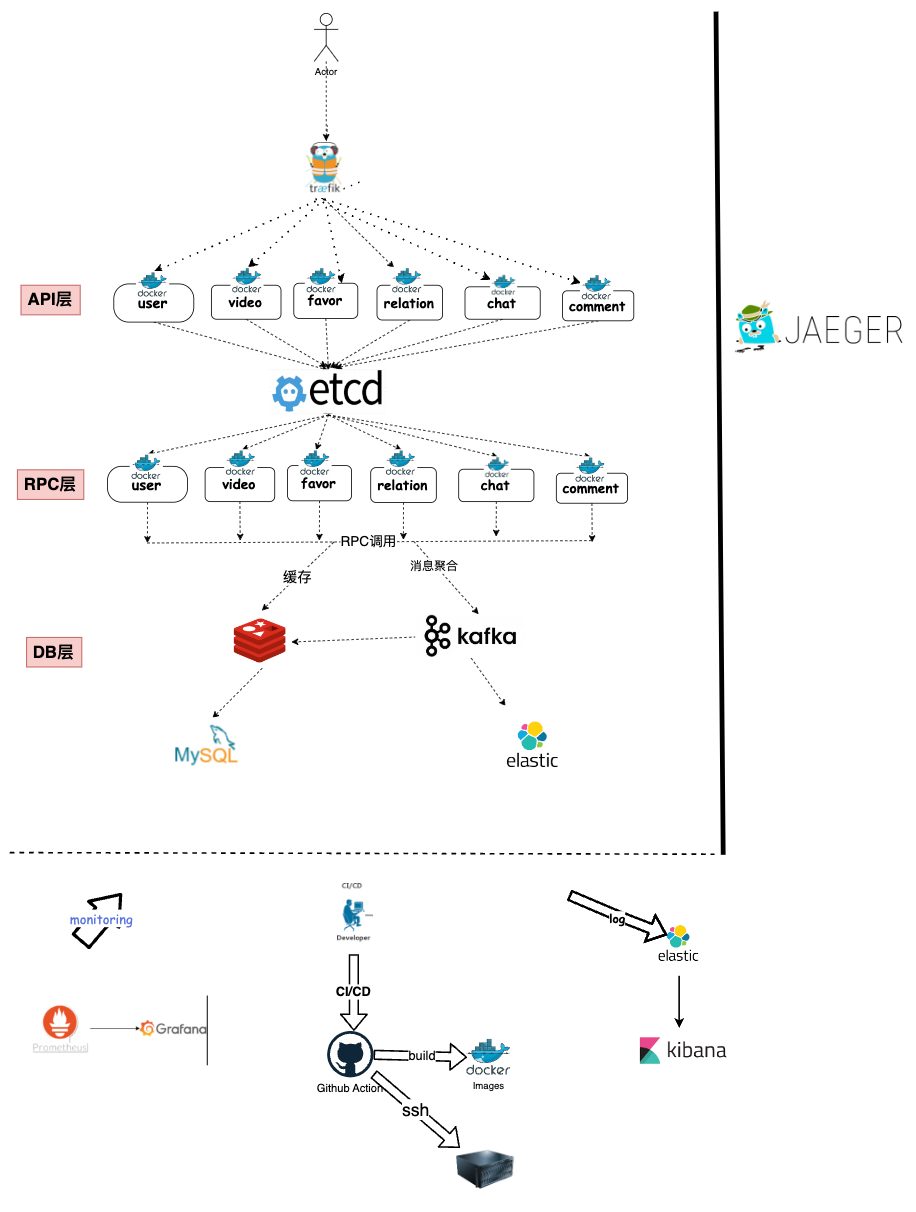
)
使用jaeger作为链路追踪,jaeger专门设计用于跟踪分布式应用程序中的请求,可以帮助理解多个服务之间的交互,并可视化请求在不同服务之间的流动
)
日志是故障排查中非常重要的数据来源。当系统出现故障时,管理员可以通过查看日志文件来定位问题所在。也可以帮助管理员对系统进行性能调优。通过分析日志数据,管理员可以了解系统的瓶颈所在。
)
filebeat收集业务日志,然后将日志输出到kafka中作为缓冲,go-stash获取kafka
中日志根据配置过滤字段,然后将过滤后的字段输出到elasticsearch中,最后由kibana负责呈现日志
)
Prometheus和Grafana的结合提供了实时多维度性能监控,使用简单且高度可扩展的工具,Prometheus收集并存储数据,支持警报和通知,而Grafana提供强大的数据可视化功能,这一组合使开发人员能够迅速发现问题、优化性能,同时保持系统的稳定性和可靠性。
grafana进行可视化呈现
)
垂直分库,根据微服务的设计将不同的服务拆分到多个库中,创建了合适的索引,提高整体系统的安全性和性能
)
支持了用户手机号一键注册/登录,提升了用户体验感
将用户上传的视频存储到Kodo,再利用Doro对视频进行转码和截帧等相关操作
利用redis的Zset结构,其中Score存储时间戳/热度值,就可以做到相应的排序规则
热度是基于评论、点赞、收藏、时间,各取权值,来合成热度的
实现了用户评论嵌套的功能
将视频信息存储到ElasticSearch中,为用户提供一个搜索界面,以便他们可以执行关键字搜索,同时支持排序和分页
使用go-zero设计的缓存系统,使用redis对mysql中的信息做了缓存,减少了对后端存储的访问,减轻了数据库和服务器的压力
使用go-zero提供的缓存系统既提高了开发效率,又避免了缓存击穿、缓存穿透、缓存雪崩等问题
利用zset+协程批量并发查询缓存,极大提高了系统响应速度
对于多个可以并行请求处理的逻辑,比如请求rpc,写入mysql、redis、es。我们均采用了协程并发调用,使串行变为并行,极大缩短了响应时间。
因此我们使用go-zero提供的并发组件mapreduce进行并发操作,将响应时间大大降低
对视频feed流、关注列表、点赞/收藏视频列表、评论均做了分页处理,显著降低页面加载时间
当用户上传视频到Kodo进行处理后,前端返回视频的相关信息给后端,此时使用kafka异步存储视频信息的方式,避免用户继续等待视频信息存入db的时间
在高并发场景下,当大量用户同时进行点赞操作时,Redis作为一个常用的内存数据库可能会面临性能瓶颈和承受能力限制。为了解决这个问题,我们采取了一种策略,首先将点赞流量写入Kafka中,从而实现流量削峰和分流的效果。
)
之前每向kafka发送一条消息就会产生一次网络 IO 和一次磁盘 IO,做消息聚合后,比如聚合 100 条消息后再发送给 Kafka,这个时候
100 条消息才会产生一次网络 IO 和磁盘 IO,这样大大提高 Kafka
的吞吐和性能。并且有聚合时间兜底,就算消息数量达不到聚合要求,超过聚合最大时间也会聚合当前所有消息发送给Kafka
针对于没有要求保障消息顺序的业务,在从kafka拉取消息后,会放入本地的channel中,然后会创建多协程并发消费,提高性能
)
采用access token和fresh token实现无感刷新,同时也降低了token泄露造成的风险
根据盐值使用特定的加密算法对用户的密码进行加密,盐值由服务器保存,保障了密码的安全性
u := model.User{
Username: in.Username,
// 加盐加密
Password: utils.Md5Password(in.Password, l.svcCtx.Config.Salt),
}使用traefik的faile2ban 插件,识别出恶意高频率请求ip并且进行封禁
插件地址:https://plugins.traefik.io/plugins/628c9ebcffc0cd18356a979f/fail2-ban
在项目中启动中,异步构建敏感词前缀树,可从数据库中读取敏感词。可大量节省内存占用,对评论,聊天,标题进行管控,遵守了网络相关法律
// SensitiveTrie 敏感词前缀树
type SensitiveTrie struct {
replaceChar rune // 敏感词替换的字符
root *TrieNode
}
func (st *SensitiveTrie) Filter(content string) string {
re := regexp.MustCompile(`<[^>]*>`)
content = re.ReplaceAllString(content, "") // 去除html标签
content = strings.Replace(content, " ", "", -1) // 去除空格
_, replaceText := st.Match(content) // 过滤敏感词
return replaceText
}
// NewSensitiveTrie 构造敏感词前缀树实例
func NewSensitiveTrie() *SensitiveTrie {
return &SensitiveTrie{
replaceChar: '*',
root: &TrieNode{End: false},
}
}
// FilterSpecialChar 过滤特殊字符
func (st *SensitiveTrie) FilterSpecialChar(text string) string {
text = strings.ToLower(text)
text = strings.Replace(text, " ", "", -1) // 去除空格
// 过滤除中英文及数字以外的其他字符
otherCharReg := regexp.MustCompile("[^\u4e00-\u9fa5a-zA-Z0-9]")
text = otherCharReg.ReplaceAllString(text, "")
return text
}
// AddWord 添加敏感词
func (st *SensitiveTrie) AddWord(sensitiveWord string) {
// 添加前先过滤一遍
sensitiveWord = st.FilterSpecialChar(sensitiveWord)
// 将敏感词转换成utf-8编码后的rune类型(int32)
tireNode := st.root
sensitiveChars := []rune(sensitiveWord)
for _, charInt := range sensitiveChars {
// 添加敏感词到前缀树中
tireNode = tireNode.AddChild(charInt)
}
tireNode.End = true
tireNode.Data = sensitiveWord
}使用volidator包对用户输入进行限制,防止出现不合理的情况
通过go-zero自带的限流开关进行流量控制
RestConf struct {
...
MaxConns int `json:",default=10000"` // 最大并发连接数,默认值为 10000 qps
...
}采用滑动窗口来进行数据采集,目前是以 10s 为一个窗口,单个窗口有40个桶,然后将窗口内采集的数据采用的是 google sre 算法计算是否开启熔断,详情可参考 https://landing.google.com/sre/sre-book/chapters/handling-overload/#eq2101
api调用rpc时采用负载均衡策略调用,请求分发给不同的 gRPC 服务端,采用的是 P2C 算法。 详情见 p2c.go
使用Github Action作为CI/CD,操作流程如下
- 使用github action运行test,进行自动化测试
- go build所有服务看是否能正常build
- 根据dockerfile构建镜像并推送到dockerhub
- 使用ssh登录远程服务器,执行脚本重新部署容器
jobs:
# user-api
build-and-push-user-api:
runs-on: ubuntu-latest
steps:
- name: Checkout the repository
uses: actions/checkout@v2
- name: Login to Docker Hub
uses: docker/login-action@v1
with:
username: ${{ secrets.DOCKER_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
- name: Set up QEMU
uses: docker/setup-qemu-action@v1
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v1
- name: Create and push user-api Docker image
uses: docker/build-push-action@v2
with:
context:.
file:./server/user/api/Dockerfile
push: true
tags: ${{ secrets.DOCKERHUB_IMAGE }}user-api:latest
platforms: linux/amd64, linux/arm64 # 构建多个架构的镜像
- name: executing remote ssh commands using password
uses: appleboy/ssh-action@v0.1.10
with:
host: ${{ secrets.HOST }}
username: ${{ secrets.USERNAME }}
password: ${{ secrets.PASSWORD }}
port: ${{ secrets.PORT }}
script: |
cd /home/douniu
docker-compose.yaml stop user-api
docker-compose.yaml rm -f user-api
docker image rm ${{ secrets.DOCKERHUB_IMAGE }}user-api:latest
docker-compose -f docker-compose.yaml up -d user-api