Home
Welcome to the Knowledge Base wiki!
Knowledge Base: Leverage IBM Cloud, Watson services, Data Science Experience and Open source technologies to derive insights from unstructured text content generated in various business domains.
Build a knowledge graph from documents.
One of the biggest challenge in the industry today is, how to make the machines understand the data in the documents just like a human can understand the context and intent of the document by reading it. The first step towards it is to somehow convert the unstructured information (free-floating text and tables text) to somewhat structured format and then process it further. That’s where Graphs play a major role in giving shape and structure to the unstructured information present in the documents. In this Code pattern, we address the problem of extracting knowledge out of text and tables in domain-specific word documents. A domain-specific knowledge graph is built on the knowledge extracted making the knowledge queryable. This Code Pattern is intended to help Developers, Data Scientists to give structure to the unstructured data. This can be used to shape their analysis significantly and use the data for further processing to get better Insights.
Cognitive
In any business, word documents are a common occurrence. They contain information in the form of raw text, tables, and images. All of them contain important facts. In this Code pattern, we address the problem of extracting knowledge out of text and tables in domain-specific word documents. A knowledge graph is built on the knowledge extracted making the knowledge queryable. The best of both worlds - training and rules-based approach is used to extract knowledge out of documents.
What makes this Code Pattern valuable:
- The ability to process the tables in .docx files along with the free-floating text.
- And also the strategy on combining the results of the real-time analysis by Watson NLU and the results from the rules defined by a Subject matter expert or Domain expert.
By Neha Setia, Vishal Chahal, Manjula Hosurmath
N/A
In this Code pattern, we address the problem of extracting knowledge out of text and tables in word documents. A knowledge graph is built on the knowledge extracted making the knowledge queryable.
This pattern demonstrates a methodology to derive insights from the document containing raw text, information in tables with IBM Cloud, Watson services, Python package Mammoth, Python NLTK and IBM Data Science experience. The best of both worlds - training and rules-based approach is used to extract knowledge out of documents.

- The unstructured text data from the .docx files(HTML tables and free floating text) that need to be analyzed and correlated is extracted from the documents using custom python code.
- The text is classified using NLU and also tagged using the code pattern - Extend Watson text classification
- The text is correlated with other text using the code pattern - Correlate documents
- The results are filtered using custom python code.
- The knowledge graph is constructed.
-
IBM Data Science Experience: Analyze data using RStudio, Jupyter, and Python in a configured, collaborative environment that includes IBM value-adds, such as managed Spark.
-
IBM Cloud Object Storage: An IBM Cloud service that provides an unstructured cloud data store to build and deliver cost-effective apps and services with high reliability and fast speed to market.
-
Watson Natural Language Understanding: An IBM Cloud service that can analyze text to extract meta-data from content such as concepts, entities, keywords, categories, sentiment, emotion, relations, semantic roles, using natural language understanding.
-
Data Science: Systems and scientific methods to analyze structured and unstructured data in order to extract knowledge and insights.
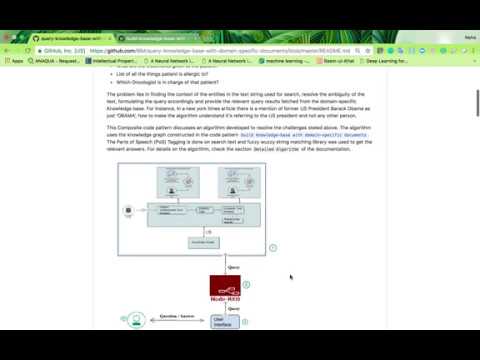
Title - Walkthrough on building a knowledge base by mining information stored in the documents.
One of the biggest challenge in the industry today is, how to make the machines understand the data in the documents just like a human can understand the context and intent of the document by reading it. The first step towards it is to somehow convert the unstructured information(free-floating text and tables text) to semi-structured format and then process it further. That’s where Graphs play a major role in giving shape and structure to the unstructured information present in the documents.
This code pattern has been designed to give a detailed description to developers who are keen on building the domain-specific Knowledge Graph. The Code Pattern covers and addresses all the aspects to it, right from the challenges that one can come across while building the knowledge graph and how to resolve them, how to fine-tuning this code pattern to meet their requirements. This Code pattern makes use of the Watson NLU, Extend Watson text Classification Code Pattern to augment the entities picked by [Watson NLU] (https://developer.ibm.com/code/patterns/extend-watson-text-classification/) , and correlate documents from different sources to augment the relations picked by Watson NLU. Basically, it makes the best of both the worlds- rule-based and dynamic Watson NLU. Then the results are filtered to meet the needs of that domain.
View the entire Knowledge graph Journey, including demos, code, and more!
-
(Watson NLU)[https://natural-language-understanding-demo.ng.bluemix.net/]
-
(Watson Studio)[https://dataplatform.ibm.com/]
-
(Python NLTK)[https://www.nltk.org/]
-
(Ultimate Guide to Understand & Implement Natural Language Processing)[https://www.analyticsvidhya.com/blog/2017/01/ultimate-guide-to-understand-implement-natural-language-processing-codes-in-python/]