![]()
![]()
nf-core/crisprseq is a bioinformatics best-practice analysis pipeline for the analysis of CRISPR edited data. It allows the evaluation of the quality of gene editing experiments using targeted next generation sequencing (NGS) data (targeted) as well as the discovery of important genes from knock-out or activation CRISPR-Cas9 screens using CRISPR pooled DNA (screening).
nf-core/crisprseq can be used to analyse:
- CRISPR gene knockouts (KO)
- CRISPR knock-ins (KI)
- Base editing (BE) and prime editing (PE) experiments
- CRISPR screening experiments (KO, CRISPRa (activation) or CRISPRi (interference))
The pipeline is built using Nextflow, a workflow tool to run tasks across multiple compute infrastructures in a very portable manner. It uses Docker/Singularity containers making installation trivial and results highly reproducible. The Nextflow DSL2 implementation of this pipeline uses one container per process which makes it much easier to maintain and update software dependencies. Where possible, these processes have been submitted to and installed from nf-core/modules in order to make them available to all nf-core pipelines, and to everyone within the Nextflow community!
On release, automated continuous integration tests run the pipeline on a full-sized dataset on the AWS cloud infrastructure. This ensures that the pipeline runs on AWS, has sensible resource allocation defaults set to run on real-world datasets, and permits the persistent storage of results to benchmark between pipeline releases and other analysis sources. The results obtained from the full-sized test can be viewed on the nf-core website.
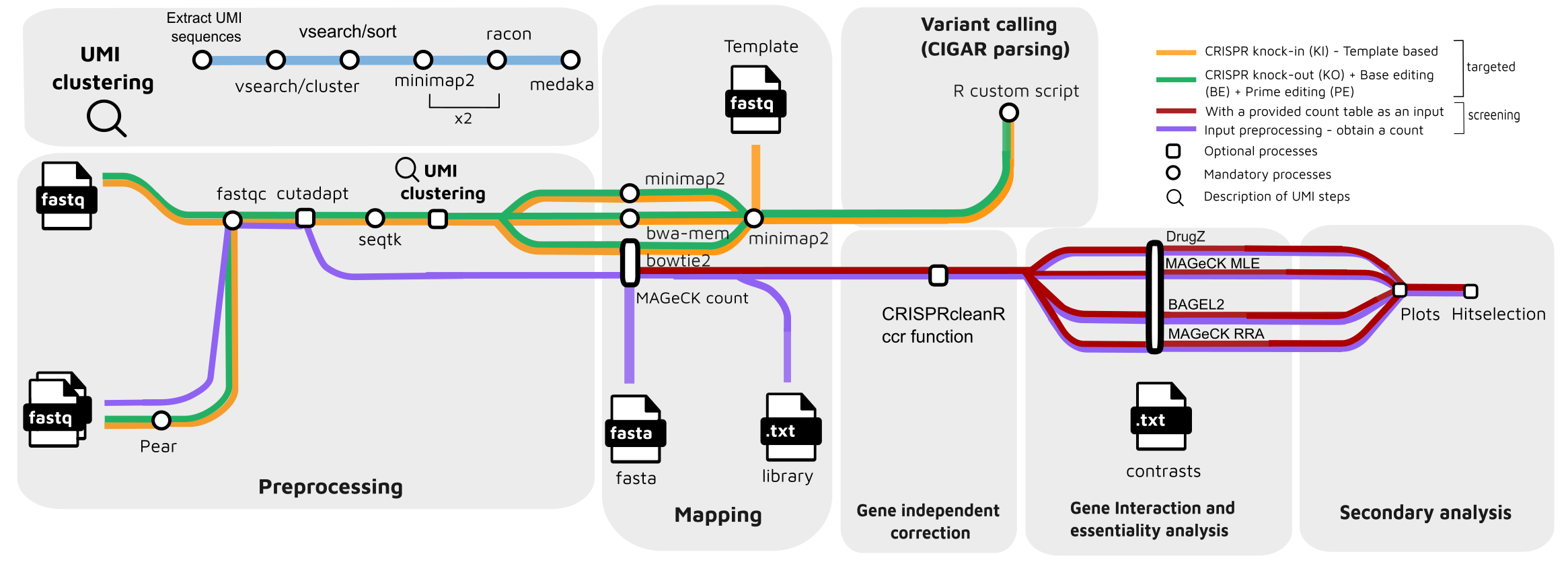
For crispr targeting :
- Merge paired-end reads (
Pear) - Read QC (
FastQC) - Adapter trimming (
Cutadapt) - Quality filtering (
Seqtk) - UMI clustering (optional):
a. Extract UMI sequences (Python script)
b. Cluster UMI sequences (
Vsearch) c. Obtain the most abundant UMI sequence for each cluster (Vsearch) d. Obtain a consensus for each cluster (minimap2) e. Polish consensus sequence (racon) f. Repeat a second rand of consensus + polishing (minimap2+racon) g. Obtain the final consensus of each cluster (Medaka) - Read mapping:
- CIGAR parsing for edit calling (
R)
For crispr screening:
- Read QC (
FastQC) - Read mapping (
MAGeCK count)- (
MAGeCK count, default) - (
bowtie2)
- (
- Optional: CNV correction and normalization with (
CRISPRcleanR) - Rank sgRNAs and genes ; a. (MAGeCK test) b. (MAGeCK mle) c. (BAGEL2)
- Visualize analysis
Note
If you are new to Nextflow and nf-core, please refer to this page on how to set-up Nextflow. Make sure to test your setup with -profile test before running the workflow on actual data.
First, prepare a samplesheet with your input data that looks as follows:
sample,fastq_1,fastq_2,reference,protospacer,template
SAMPLE1,SAMPLE1_R1.fastq.gz,SAMPLE1_R2.fastq.gz,ACTG,ACTG,ACTG
or
sample,fastq_1,fastq_2,condition
SAMPLE1,SAMPLE1_R1.fastq.gz,SAMPLE1_R2.fastq.gz,control
For more details on how to build a sample sheet, please refer to the usage documentation
Now, you can run the pipeline using:
nextflow run nf-core/crisprseq --input samplesheet.csv --analysis <targeted/screening> --outdir <OUTDIR> -profile <docker/singularity/podman/shifter/charliecloud/conda/institute>Warning
Please provide pipeline parameters via the CLI or Nextflow -params-file option. Custom config files including those provided by the -c Nextflow option can be used to provide any configuration except for parameters;
see docs.
For more details and further functionality, please refer to the usage documentation and the parameter documentation.
To see the results of an example test run with a full size dataset refer to the results tab on the nf-core website pipeline page. For more details about the output files and reports, please refer to the output documentation.
nf-core/crisprseq targeted is based on CRISPR-A [Sanvicente-García, et.al. (2023)], originally written by Marta Sanvicente García at Translational Synthetic Biology from Universitat Pompeu Fabra. It was re-written in Nextflow DSL2 and is primarily maintained by Júlia Mir Pedrol (@mirpedrol) at Quantitative Biology Center (QBiC) from Universität Tübingen.
nf-core/crisprseq screening was written and is primarly maintained by Laurence Kuhlburger (@LaurenceKuhl) at Quantitative Biology Center (QBiC) from Universität Tübingen.
Main developers:
We thank the following people for their extensive assistance in the development of this pipeline:
If you would like to contribute to this pipeline, please see the contributing guidelines.
For further information or help, don't hesitate to get in touch on the Slack #crisprseq channel (you can join with this invite).
If you use nf-core/crisprseq for your analysis, please cite it using the following doi: 10.5281/zenodo.7598496
An extensive list of references for the tools used by the pipeline can be found in the CITATIONS.md file.
You can cite the nf-core publication as follows:
The nf-core framework for community-curated bioinformatics pipelines.
Philip Ewels, Alexander Peltzer, Sven Fillinger, Harshil Patel, Johannes Alneberg, Andreas Wilm, Maxime Ulysse Garcia, Paolo Di Tommaso & Sven Nahnsen.
Nat Biotechnol. 2020 Feb 13. doi: 10.1038/s41587-020-0439-x.
Crispr-Analytics:
Sanvicente-García M, García-Valiente A, Jouide S, Jaraba-Wallace J, Bautista E, Escobosa M, et al. (2023) CRISPR-Analytics (CRISPR-A): A platform for precise analytics and simulations for gene editing. PLoS Comput Biol 19(5): e1011137. https://doi.org/10.1371/journal.pcbi.1011137