kNN-box is an open-source toolkit to build kNN-MT models. We take inspiration from the code of kNN-LM and adaptive kNN-MT, and develope this more extensible toolkit based on fairseq. Via kNN-box, users can easily implement different kNN-MT baseline models and further develope new models.
- 🎯 easy-to-use: a few lines of code to deploy a kNN-MT model
- 🔭 research-oriented: provide implementations of various papers
- 🏗️ extensible: easy to develope new kNN-MT models with our toolkit.
- 📊 visualized: the whole translation process of the kNN-MT can be visualized
- python >= 3.7
- pytorch >= 1.10.0
- faiss-gpu >= 1.7.3
- sacremoses == 0.0.41
- sacrebleu == 1.5.1
- fastBPE == 0.1.0
- streamlit >= 1.13.0
- scikit-learn >= 1.0.2
- seaborn >= 0.12.1
You can install this toolkit by
git clone [email protected]:NJUNLP/knn-box.git
cd knn-box
pip install --editable ./Note: Installing faiss with pip is not suggested. For stability, we recommand you to install faiss with conda
CPU version only:
conda install faiss-cpu -c pytorch
GPU version:
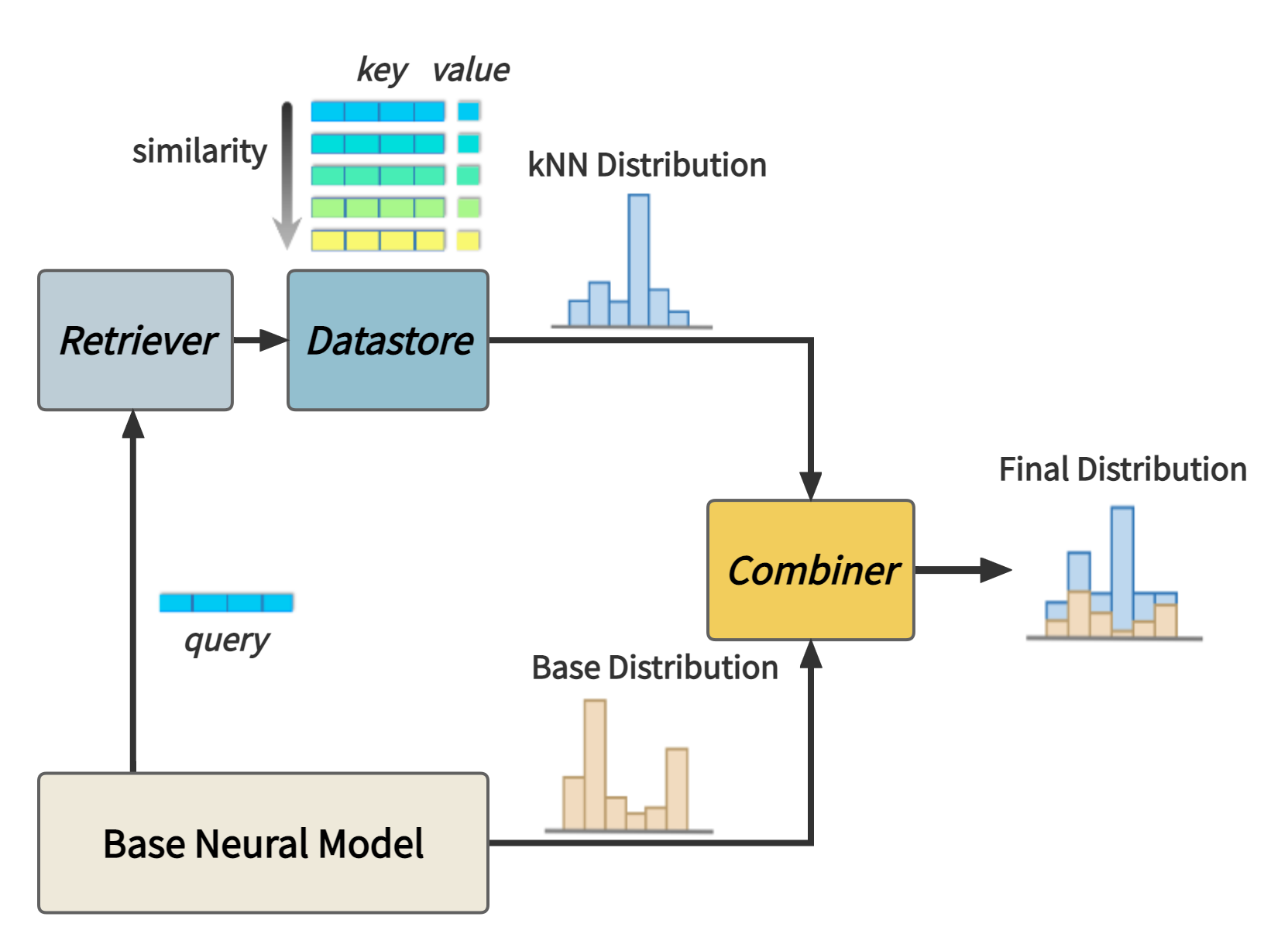
conda install faiss-gpu -c pytorch # For CUDABasically, there are two steps for runing a kNN-MT model: building datastore and translating with datastore. In this toolkit, we unify different kNN-MT variants into a single framework, albeit they manipulate datastore in different ways. Specifically, the framework consists of three modules (basic class):
- datastore: save translation knowledge as key-values pairs
- retriever: retrieve useful translation knowledge from the datastore
- combiner: produce final prediction based on retrieval results and NMT model
Preparation: download pretrained models and dataset
You can prepare pretrained models and dataset by executing the following command:
cd knnbox-scripts
bash prepare_dataset_and_model.shuse bash instead of sh. If you still have problem running the script, you can manually download the wmt19 de-en single model and multi-domain de-en dataset, and put them into correct directory (you can refer to the path in the script).
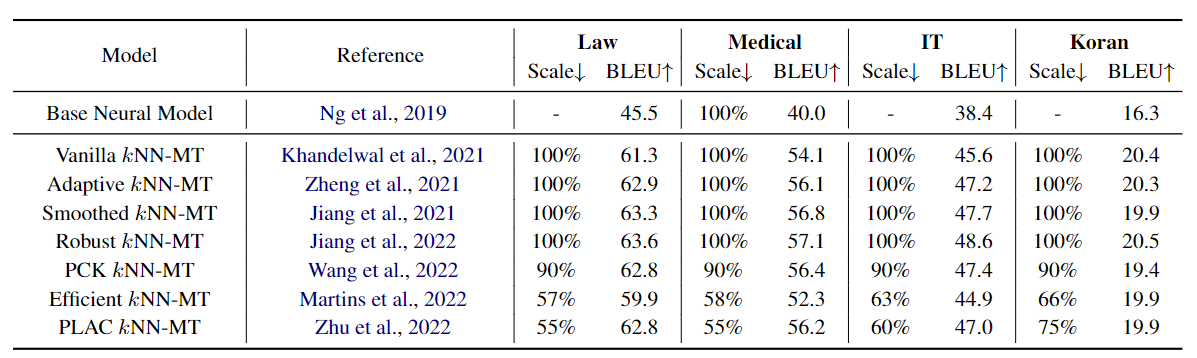
base neural machine translation model (our baseline)
To translate using base neural model, execute the following command:cd knnbox-scripts/base-nmt
bash inference.shNearest Neighbor Machine Translation
Implementation of Nearest Neighbor Machine Translation (Khandelwal et al., ICLR'2021)
To translate using vanilla knn-mt, execute the following command:
cd knnbox-scripts/vanilla-knn-mt
# step 1. build datastore
bash build_datastore.sh
# step 2. inference
bash inference.shAdaptive Nearest Neighbor Machine Translation
Implementation of Adaptive Nearest Neighbor Machine Translation (Zheng et al., ACL'2021)
To translate using adaptive knn-mt, execute the following command:
cd knnbox-scripts/adaptive-knn-mt
# step 1. build datastore
bash build_datastore.sh
# step 2. train meta-k network
bash train_metak.sh
# step 3. inference
bash inference.shLearning Kernel-Smoothed Machine Translation with Retrieved Examples
Implementation of Learning Kernel-Smoothed Machine Translation with Retrieved Examples (Jiang et al., EMNLP'2021)
To translate using kernel smoothed knn-mt, execute the following command:
cd knnbox-scripts/kernel-smoothed-knn-mt
# step 1. build datastore
bash build_datastore.sh
# step 2. train kster network
bash train_kster.sh
# step 3. inferece
bash inference.shEfficient Machine Translation Domain Adaptation
Implementation of Efficient Machine Translation Domain Adaptation (PH Martins et al., 2022)
To translate using Greedy Merge knn-mt, execute the following command:
cd knnbox-scripts/greedy-merge-knn-mt
# step 1. build datastore and prune using greedy merge method
bash build_datastore_and_prune.sh
# step 2. inferece (You can decide whether to use cache by --enable-cache)
bash inference.shEfficient Cluster-Based k-Nearest-Neighbor Machine Translation
Implementation of Efficient Cluster-Based k-Nearest-Neighbor Machine Translation (Wang et al., 2022)
To translate using pck knn-mt, execute the following command:
cd knnbox-scripts/pck-knn-mt
# step 1. build datastore
bash build_datastore.sh
# step 2. train reduction network
bash train_reduct_network.sh
# step 3. reduct datastore's key dimension using trained network
bash reduct_datastore_dim.sh
# step 4. train meta-k network
bash train_metak.sh
# step 5. inference
bash inference.sh[optional] In addition to reducing dimensions, you can use the method in the paper to reduce the number of entries in the datastore.
(after step 1.)
bash prune_datastore_size.shTowards Robust k-Nearest-Neighbor Machine Translation
Implementation of Towards Robust k-Nearest-Neighbor Machine Translation (Jiang et al., EMNLP'2022)
To translate using robust knn-mt, execute the following command:
cd knnbox-scripts/robust-knn-mt
# step 1. build datastore
bash build_datastore.sh
# step 2. train meta-k network
bash train_metak.sh
# step 3. inference
bash inference.shWhat Knowledge Is Needed? Towards Explainable Memory for kNN-MT Domain Adaptation
Implementation of What Knowledge Is Needed? Towards Explainable Memory for kNN-MT Domain Adaptation (Zhu et al., 2022)
PLAC is a datastore pruning method based on MT-model's knowledge. To prune a full datastore (vanilla or dimension-reduced), execute the following command:
cd knnbox-scripts/plac-knn-mt
# step 1. save MT-model predictions
bash save_mt_pred.sh
# step 2. save prunable indexes
bash save_drop_index.sh
# step 3. prune a full datastore and save the pruned datastore
bash prune_datastore.shSimple and Scalable Nearest Neighbor Machine Translation
Implementation of Simple and Scalable Nearest Neighbor Machine Translation
To translate using sk-mt, excute the following command:
cd knnbox-scripts/simple-scalable-knn-mt
# step 1. download elastic search
bash download_elasticsearch.sh
# step 2. start elastic search service on port 9200
./elasticsearch-8.6.1/bin/elasticsearch
# step 3. create elasticsearch index for corpus
bash create_elasticsearch_index.sh
# step 4. inference
bash inference.shIf there is an elasticsearch-related error when executing the script, you may need to open
./elaticsearch-8.6.1/config/elasticsearch.yml and disable the security features:
xpack.security.enabled: false
With kNN-box, you can even visualize the whole translation process of your kNN-MT model. You can launch the visualization service by running the following commands. Have fun with it!
cd knnbox-scripts/vanilla-knn-mt-visual
# step 1. build datastore for visualization (save more information for visualization)
bash build_datastore_visual.sh
# step 2. configure the model that you are going to visualize
vim model_configs.yml
# step 3. launch the web page
bash start_app.sh
# Optional: regist your own tokenize handler function in src/tokenizer.py
# and then use it as `--tokenizer` in model_configs.yml if necessary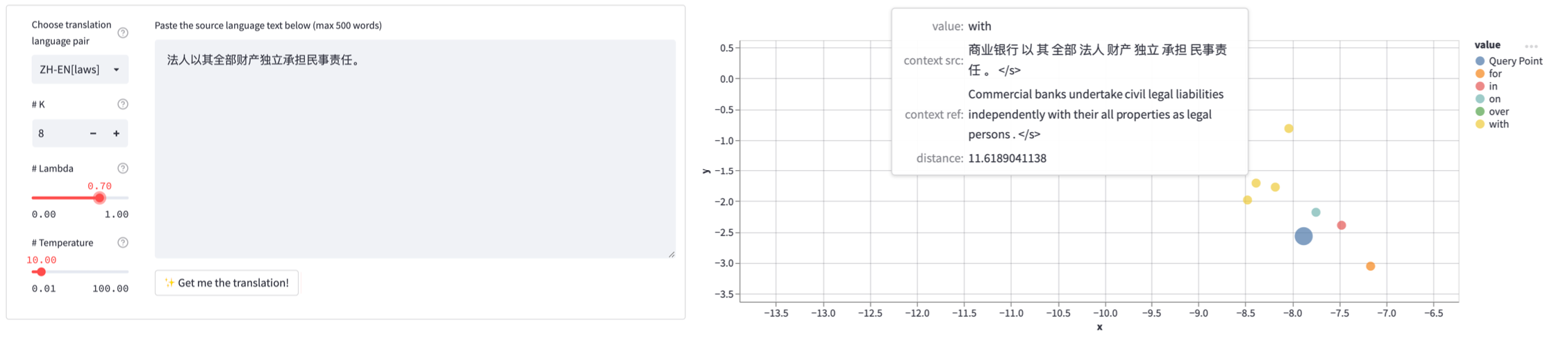
We now have a paper you can cite for the :card_file_box: knn-box toolkit:
@misc{zhu2023knnbox,
title={kNN-BOX: A Unified Framework for Nearest Neighbor Generation},
author={Wenhao Zhu and Qianfeng Zhao and Yunzhe Lv and Shujian Huang and Siheng Zhao and Sizhe Liu and Jiajun Chen},
year={2023},
eprint={2302.13574},
archivePrefix={arXiv},
primaryClass={cs.CL}
}