爬取B站up视频详细信息,并进行可视化
由于本项目的爬虫是单线程,所以选择的up主数据量建议小于3000,如果你能优化到多线程加速,欢迎pull request
前端:HTML, CSS, JavaScript
后端:flask
爬虫:python
数据库:MySQL
深度学习:BiRNN->LSTM训练模型,情感分类仓库:https://github.com/Nomination-NRB/SentimentClassify
-
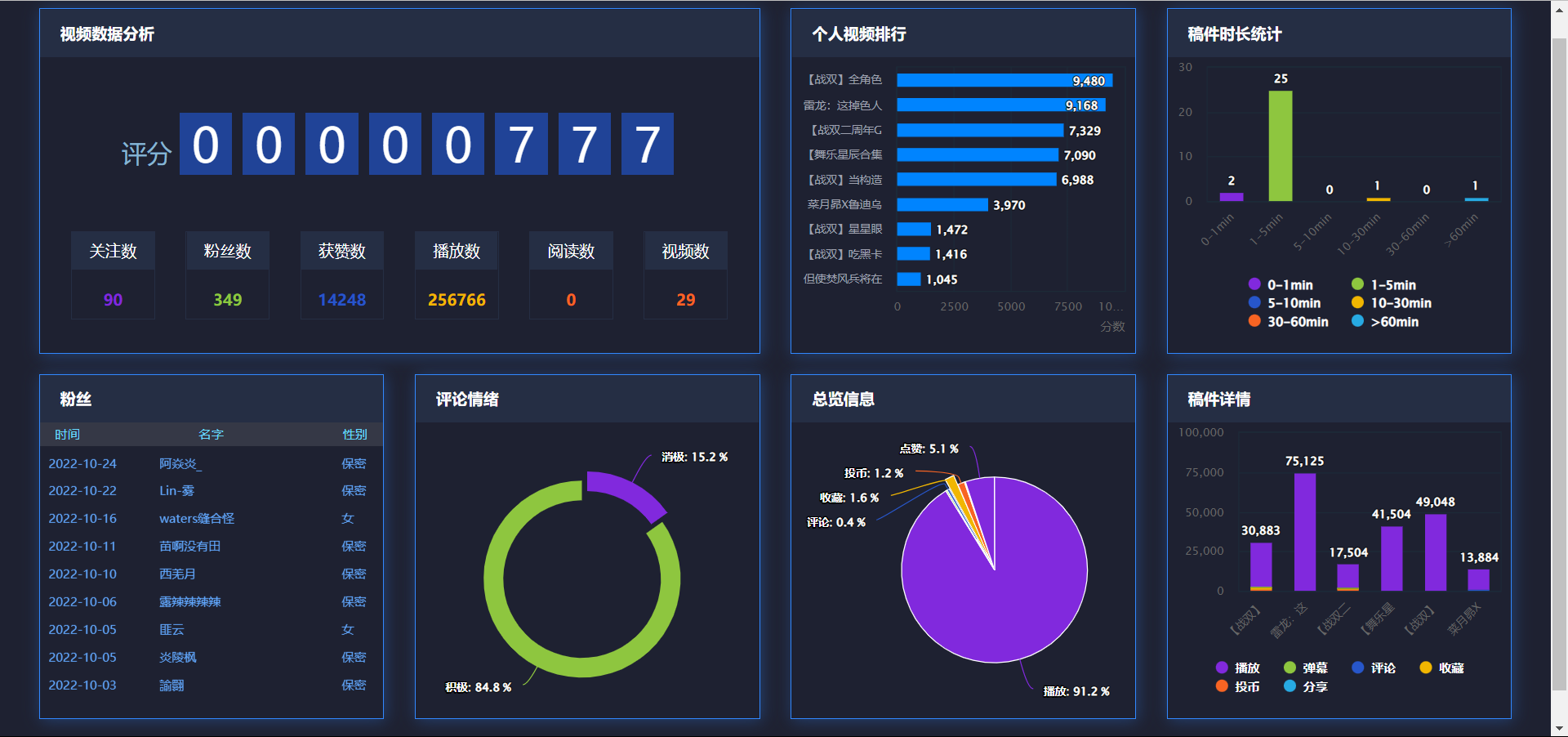
视频数据分析
- 数据来源:up主个人主页统计
- 关注数,粉丝数,获赞数,播放数,阅读数,视频数
-
个人视频排行
- 综合评分前9个视频(降序)
- 评分算法:0.1*view+barrage+reply+2*favorite+2*coin+1.5*share+0.5*like
-
稿件时长分区
-
粉丝
- 信息:名字,关注时间,性别
-
评论情绪
- 数据来源:所有投稿视频
- 积极/消极
-
总览信息
- 所有视频的点赞,投币,收藏,评论,播放
-
稿件详情
- 评分前6的稿件的详细数据
- 可以点击分区进行单独查看数据权重
VisualBilibili
├─ Data
│ ├─ fansData·································//爬取的粉丝数据
│ │ └─ 237733293_fans_data.csv
│ ├─ overViewData·····························//爬取的个人主页的总览数据
│ │ └─ 237733293_overview_data.csv
│ ├─ reviewData·······························//爬取的所有视频详细信息数据,此处仅列出2个
│ │ ├─ BV12Q4y1C7VK.csv
│ │ ├─ BV12S4y1r7Hv.csv
│ ├─ reviewForInfer···························//深度学习所需数据
│ │ ├─ result.csv·····························//result.csv: 预测的结果
│ │ ├─ review.csv·····························//review.csv: 用于预测的评论
│ │ └─ reviewResult.csv·······················//review与result的合并结果
│ ├─ sumData··································//所有视频评论的汇总
│ │ └─ sumReviewData.csv
│ ├─ videoData································//所有视频的简介信息
│ │ └─ 237733293_video_data.csv
│ └─ videoDetailData··························//所有视频的详细信息
│ └─ 237733293_videoDetail_data.csv
│
├─ collect_data·······························//爬虫文件夹
│ ├─ Trash.py·································//清空Data文件夹下所有的csv文件
│ ├─ getBVid.py·······························//获得所有视频的BV号
│ ├─ getReview.py·····························//获得所有视频的评论
│ ├─ getUserInfo.py···························//获得所有视频信息及用户信息
│ ├─ getfans.py·······························//获得up的粉丝信息
│ └─ main.py··································//爬虫执行总文件,会执行以上四个get.py文件
│
├─ flask······································//前后端文件夹
│ ├─ data·····································//用于测试前后端的数据
│ │ ├─ 237733293_fans_data.csv
│ │ ├─ 237733293_follow_data.csv
│ │ ├─ 237733293_videoDetail_data.csv
│ │ └─ 237733293_video_data.csv
│ ├─ datavisualization.sql····················//样例uid的数据,直接存入数据库,可不用执行爬虫main.py
│ ├─ linkSQL.py·······························//若使用样例uid,则运行次文件(可测试函数)
│ ├─ linkSQLData.py···························//若使用自定义uid,则该运行此文件(将数据写入数据库)
│ ├─ manage.py································//前后端执行总文件
│ ├─ static···································//前端静态样式,后端的js逻辑
│ │ ├─ css
│ │ ├─ fonts
│ │ └─ js
│ └─ templates
│ └─ index.html·····························//可视化页面
│
├─ motion_classification······················//深度学习情感分类文件夹
│ ├─ Data·····································//用于测试的文本数据
│ │ ├─ reviewTest.csv
│ │ └─ test.txt
│ ├─ data_utils.py····························//情感预测所需的函数
│ ├─ inference.py·····························//情感预测
│ ├─ models
│ │ └─ BiRNN.py·······························//深度神经网络
│ └─ output
│ ├─ model.pt·······························//训练好的模型
│ └─ model.vocab····························//词汇表
├─ README.md
└─ requirements.txt···························//本项目所需的依赖包
git clone https://github.com/Nomination-NRB/VisualBilibili在vscode或者其他编译器打开项目文件夹
激活本项目具体使用的环境,切换到requirements.txt目录下在终端执行该命令即可
pip install -r requirements.txt-
使用样例uid=237733293的数据
-
在本地mysql中创建一个数据库:
CREATE DATABASE visualization DEFAULT CHARSET utf8 COLLATE utf8_general_ci; -
将flask文件夹下的datavisualization.sql文件导入到数据库中:
-
mysql 默认以gbk编码连接数据库,导出备份文件是utf8编码,编码不一致导致出现错误
解决:
mysql -u root -p --default-character-set=utf8以utf8编码连接 -
use visualization; -
source C:\Users\76608\Desktop\Study\Subject\Program\DataVisualization\flask\datavisualization.sql -
source后面的地址请根据自己的路径填写
-
-
在flask文件夹下的linkSQL.py文件中,根据自己的mysql修改get_conn函数的默认参数值(user, passwd, db)
-
运行manage.py文件,打开本地连接即可
-
-
使用自定义uid数据
-
在collect_data文件夹下修改main.py中的uid的值
-
由于爬虫需要用的cookie是存在生存期限的,所以在爬取数据之前需要重新获取cookie更新
- 在自己的B站个人空间中,右击鼠标选择检测或者直接F12
- 根据1,2,3,4步骤,其中步骤2的选择不唯一,在列表中随便选择一个都可以,然后将cookie的值赋值得到(为了复制准确,请右键cookie,选择copy value)
- 将getfans.py, getUserInfo.py中的headers里面的cookie的值替换为刚刚复制的cookie即可(getReview.py里的cookie可以不用改,如果爬取评论时出现连接失败,则再将其cookie修改)
-
运行collect_data文件夹下的main.py,爬取的数据都会保存在Data文件夹下,文件夹具体包含内容如上目录
-
在motion_classification文件夹下运行inference.py进行评论的积极消极情绪预测,其预测结果也会保存在Data文件夹下
- 若Data文件夹下的内容需要清空,可以运行collect_data文件夹下的Trash.py统一清理Data文件夹下所有的csv文件
-
在flask文件夹下,运行linkSQLData.py(根据自己的mysql修改get_conn函数的默认参数值user, passwd, db),将Data文件夹下的数据导入到mysql中
-
在flask文件夹下,运行manage.py,打开本地连接即可
-
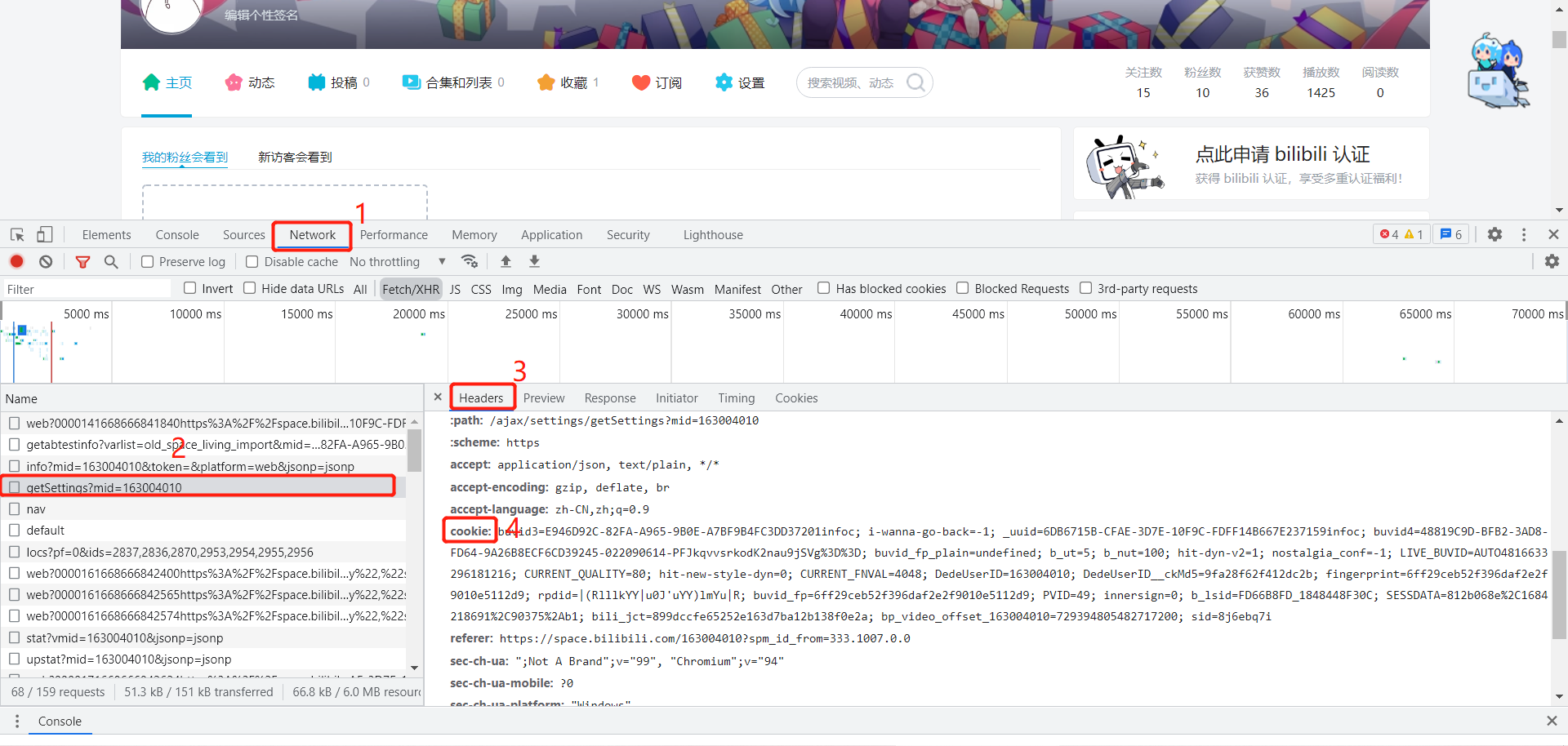
更多api请参考https://github.com/SocialSisterYi/bilibili-API-collect
相关接口,mid是账号的uid,样例mid采取163004010
- 获取用户详细信息(只需修改mid的值)
https://api.bilibili.com/x/space/acc/info?mid=163004010
- 获取uid的粉丝列表(只需修改vmid的值)
https://api.bilibili.com/x/relation/followers?vmid=163004010&pn=1&ps=200
- 获取该uid关注列表中的用户(只需修改vmid的值)
https://api.bilibili.com/x/relation/followings?vmid=163004010&pn=1
- 获取用户个人主页右上角的总览信息(只需修改mid的值)
https://api.bilibili.com/x/space/upstat?mid=163004010&jsonp=jsonp
https://api.bilibili.com/x/relation/stat?vmid=163004010&jsonp=jsonp