This is release v2.0.1 of Intel® Open VKL. For changes and new features see the changelog. Visit http://www.openvkl.org for more information.
Intel® Open Volume Kernel Library (Intel® Open VKL) is a collection of high-performance volume computation kernels, developed at Intel. The target users of Open VKL are graphics application engineers who want to improve the performance of their volume rendering applications by leveraging Open VKL’s performance-optimized kernels, which include volume traversal and sampling functionality for a variety of volumetric data formats. Open VKL supports x86 CPUs under Linux, macOS, and Windows; ARM CPUs on macOS; as well as Intel® GPUs under Linux and Windows (currently in beta).
Open VKL contains kernels optimized for the latest x86 processors with support for SSE, AVX, AVX2, and AVX-512 instructions, and for ARM processors with support for NEON instructions. Open VKL supports Intel GPUs based on the Xe HPG microarchitecture (Intel® Arc™ GPU) under Linux and Windows and Xe HPC microarchitecture (Intel® Data Center GPU Flex Series and Intel® Data Center GPU Max Series) under Linux. Intel GPU support leverages the SYCL open standard programming language; SYCL allows one to write C++ code that can be run on various devices, such as CPUs and GPUs. Open VKL is part of the Intel® oneAPI Rendering Toolkit and is released under the permissive Apache 2.0 license.
Open VKL provides a C-based API on CPU and GPU, and also supports applications written with the Intel® Implicit SPMD Program Compiler (Intel® ISPC) for CPU by also providing an ISPC interface to the core volume algorithms. This makes it possible to write a renderer in ISPC that automatically vectorizes and leverages SSE, AVX, AVX2, AVX-512, and NEON instructions. ISPC also supports runtime code selection, thus ISPC will select the best code path for your application.
In addition to the volume kernels, Open VKL provides tutorials and example renderers to demonstrate how to best use the Open VKL API.
- Removed ISPC runtime dependency and level zero loader requirement
- Add DEPENDENTLOADFLAG linker parameter for Windows binaries, restricting DLL loading behavior
- Superbuild updates to latest versions of dependencies
- This Open VKL release adds support for Intel® Arc™ GPUs, Intel® Data
Center GPU Flex Series and Intel® Data Center GPU Max Series through
SYCL.
- The SYCL support of Open VKL is in beta phase. Current functionality, quality, and GPU performance may not reflect that of the final product.
- Open VKL CPU support in this release remains at Gold level, incorporating the same quality and performance as previous releases.
- API changes:
- Handle types are now passed by pointer in the following APIs:
vklComputeSample*()vklComputeGradient*()vklGet*IteratorSize*()vklInit*Iterator*()vklIterate*()
vklLoadModule()has been removed; compile-time linkage to an Open VKL device implementation (cpuorgpu) is now required- Added
vklInit()API, which must be called to initialize the library VKL_FILTER_[TRILINEAR,TRICUBIC]are renamed toVKL_FILTER_[LINEAR,CUBIC]VKLAMRMethodenum is nowuint32_tstructuredSphericalvolumes: thegridSpacingdefault now results in the volume occupying a full sphere
- Handle types are now passed by pointer in the following APIs:
- Added new examples demonstrating GPU usage:
vklExamplesGPUandvklTutorialGPU - Superbuild updates to latest versions of dependencies
- Move to and require latest versions of RenderKit dependencies: Embree v4.0.0 and rkcommon v1.11.0
- ARM support: expose ISPC neon-i32x8 target via OPENVKL_ISA_NEON2X CMake option
- Superbuild updates to latest versions of dependencies
- Superbuild updates to latest versions of dependencies
- Note that the update to zlib v1.2.13 remedies CVE-2022-37434
- Added AVX512 8-wide CPU device mode, enabled via the
OPENVKL_ISA_AVX512SKX_8_WIDECMake option - VDB volumes: added support for packed / contiguous data layouts for
temporally constant volumes, which can provide improved performance
(
nodesPackedDense,nodesPackedTileparameters) - VDB utility library: added
repackNodesflag to toggle usage of packed data layouts - Particle volumes: general memory efficiency and performance improvements
- Superbuild updates to latest versions of dependencies
- Minimum ISPC version is now v1.18.0
- Added
vklSetParam()API function which can set parameters of any supported type - Structured regular volumes:
- Added support for cell-centered data via the
cellCenteredparameter; vertex-centered remains the default - Added support for more general transformations via the
indexToObjectparameter - Added
indexOriginparameter which applies an index-space vec3i translation
- Added support for cell-centered data via the
- VDB volumes:
- Added
indexClippingBoundsparameter, which can restrict the active voxel bounding box - The
indexToObjectparameter can now be provided as aVKL_AFFINE3F - Corrected bounding box computations in
InnerNodeobserver
- Added
- Particle volumes:
- Now ignoring particles with zero radius
- VDB utility library: added
commitflag (default true) to volume creation methods, allowing apps to set additional parameters before first commit - Examples:
- Added new set of minimal examples, which step through creation of basic volume and isosurface renderers
- Exposing
intervalResolutionHintparameter invklExamplesapplication
- Superbuild updates to latest versions of dependencies
- vklExamples improvements: asynchronous rendering, multiple viewports, docking, and more
- Fixed bug in
openvkl_utility_vdbwhich could lead to crashes when creating VDB volumes with temporally constant tiles - Superbuild updates to latest versions of dependencies
- Minimum rkcommon version is now 1.8.0
- Fixed issue in
structuredRegularandvdbinterval iterators that could lead to erroneous initial intervals for certain ray inputs - Fixed handling of
intervalResolutionHintinterval iterator context parameter foramr,particle, andunstructuredvolumes with small numbers of cells / primitives
- The version 1.0 release marks long term API stability (until v2.0)
- Open VKL can now be built for ARM CPUs that support Neon
- Iterator API updates:
- Introducing interval and hit iterator contexts, which hold iterator-specific configuration (eliminates value selector objects)
- Interval and hit iteration is now supported on any volume attribute
- Interval iterators now include a
timeparameter - Interval iterators now support the
intervalResolutionHintparameter, replacingmaxIteratorDepthandelementaryCellIteration
- Supporting configurable background values; default is now
VKL_BACKGROUND_UNDEFINED(NaN) for all volume types vklGetValueRange()now supports all volume attributes- Added ISPC-side API bindings for
vklGetNumAttributes()andvklGetValueRange() - Structured regular volumes:
- Added support for tricubic filtering
- More accurate gradient computations respecting filter mode
- Hit iteration robustness improvements
- VDB volumes:
- Interval and hit iteration robustness improvements
- Corrected interval iterator
nominalDeltaTcomputation for non-normalized ray directions and non-uniform object-space grid spacings - Fixed bug which could cause incorrect value range computations for temporally varying volumes
- vklExamples additions demonstrating:
- Multi-attribute interval / hit iteration
- Configurable background values
- Temporally varying volumes
- Superbuild updates to latest versions of dependencies
- Now requiring minimum versions:
- Embree 3.13.1
- rkcommon 1.7.0
- ISPC 1.16.0
- Driver (now device) API changes:
- Renamed
VKLDrivertoVKLDeviceand updated associated device setup APIs - Use of multiple concurrent devices is now supported; therefore
vklNewVolume()andvklNewData()now require a device handle - Renamed the
ispc_devicemodule andispcdevice tocpu_deviceandcpu, respectively - The
OPENVKL_CPU_DEVICE_DEFAULT_WIDTHenvironment variable can now be used to change thecpudevice’s default SIMD width at run time
- Renamed
- Added new
VKLTemporalFormatenum used for temporally varying volume parameterization - VDB volumes:
- Support for temporally structured and temporally unstructured (TUV) attribute data, which can be used for motion blurred rendering
- Supporting tricubic filtering via
VKL_FILTER_TRICUBICfilter type - Added support for half precision float-point (FP16) attribute data
via
VKL_HALFdata type - Added a new
InnerNodeobserver and associated utility functions which allows applications to introspect inner nodes of the internal tree structure, including bounding boxes and value ranges - Renamed
VKL_FORMAT_CONSTANT_ZYXtoVKL_FORMAT_DENSE_ZYX
- Structured regular and spherical volumes:
- Added support for half precision float-point (FP16) attribute data
via
VKL_HALFdata type
- Added support for half precision float-point (FP16) attribute data
via
- Unstructured volumes:
- Added support for elementary cell iteration via the
elementaryCellIterationparameter - Robustness improvements for hit iteration
- Added support for elementary cell iteration via the
- AMR volumes:
- Improved interval iterator implementation, resolving issues with
returned interval
nominalDeltaTvalues - Interval iterators now support
maxIteratorDepthparameter
- Improved interval iterator implementation, resolving issues with
returned interval
- Interval and hit iteration performance improvements when multiple values ranges / values are selected
- Added new temporal compression utilities which applications can use for processing temporally unstructured attribute data
- vklExamples additions demonstrating:
- Motion blurred rendering on temporally structured and temporally
unstructured
vdbvolumes - Tricubic filtering on
vdbvolumes - Half-precision floating-point (FP16) support for
structuredRegular,structuredSpherical, andvdbvolumes - Elementary cell interval iteration on
unstructuredvolumes - Use of the
InnerNodeobserver onvdbvolumes
- Motion blurred rendering on temporally structured and temporally
unstructured
- Superbuild updates to:
- Embree 3.13.0
- rkcommon 1.6.1
- Minimum rkcommon version is now 1.6.1
- Fixed bug in VDB volume interval iterator implementation which could lead to missed intervals or incorrect value ranges in returned intervals
- Added support for temporally varying volumes with associated API changes for sampling, gradients, and hit iteration. This feature can be used to enable motion blurred rendering
- Structured regular volumes:
- Support for temporally structured and temporally unstructured (TUV) input data
- Improved
nominalDeltaTfor interval iteration - Interval iterator robustness improvements for axis-aligned rays
- Sampling performance improvements
- VDB volumes:
- Multi-attribute support (including three-component float grids)
- Interval iterator robustness improvements for axis-aligned rays
- Performance improvements for scalar sampling
- Now restricting volumes to exactly four levels
- Allowing leaf nodes on the lowest level only
- Unstructured volumes:
- Improved
nominalDeltaTfor interval iteration
- Improved
vdb_utilupdates:- Support for loading multi-attribute .vdb files (
floatandVec3sgrids) - Fix order of rotation matrix coefficients loaded from .vdb files
- Support for loading multi-attribute .vdb files (
- vklExamples additions demonstrating:
- Motion blurred rendering on temporally structured and temporally
unstructured volumes (
structuredRegularonly) - Support for
vdbmulti-attribute volumes - Hit iterator time support
- Motion blurred rendering on temporally structured and temporally
unstructured volumes (
- Superbuild updates to:
- Embree 3.12.2
- rkcommon 1.6.0
- ISPC 1.15.0
- OpenVDB 8.0.0
- Minimum rkcommon version is now 1.6.0
- Introduced API support for multi-attribute volumes, including APIs for
sampling multiple attributes simultaneously
- Initially only
structuredRegularandstructuredSphericalvolume types support multi-attribute data
- Initially only
- Iterator APIs now work on sampler objects rather than volumes, supporting finer-grained configurability
- Observers can now be created for both volume and sampler objects
LeafNodeAccessobservers must now be created on sampler objects
- Log and error callbacks now support a user pointer
vdbvolume interval iterators:- Added support for elementary cell iteration when
maxIteratorDepthis set toVKL_VDB_NUM_LEVELS-1 - Up to 2x faster iteration
- Added support for elementary cell iteration when
unstructuredandparticlevolume interval iterators:- Improved interior empty space skipping behavior
- Added support for configurable iterator depth via the
maxIteratorDepthparameter
- Added support for filter modes in
structuredRegularandstructuredSphericalvolumes amrvolumes now supportmethodparameter on sampler objects- Added new
interval_iterator_debugrenderer invklExamplesto visualize interval iteration behavior - Hit iterator accuracy improvements for
unstructuredvolumes - Fixed bugs in
amrandvdbvolume bounding box computations - Fixed bug in
unstructuredvolume gradient computations near empty regions - Minimum ISPC version is now v1.14.1
- Added new
particlevolume type supporting Gaussian radial basis functions - Introduced
VKLSamplerobjects allowing configuration of sampling and gradient behavior - Added stream-wide sampling and gradient APIs
- Introduced a new way to allocate iterators, giving the user more freedom in choosing allocation schemes and reducing iterator size
- Added support for strided data arrays
- Added gradient implementations for
amrandvdbvolumes - Hit iterator accuracy improvements for
amr,structuredSpherical,unstructured, andvdbvolumes - Up to 4x performance improvement for
structuredRegularandstructuredSphericalsampling for volumes in the 1-2GB range - Up to 2x performance improvement for
structuredRegularinterval iteration - Improved commit speed for
unstructuredvolumes - Improved value range computation in
vdbvolumes - Improved isosurface shading in
vklExamples - Improved parameter validation across all volume types
- Aligned
VKLHit[4,8,16]andVKLInterval[4,8,16]structs - Added hit epsilon to
VKLHit[4,8,16] - Updated parameter names for
vdbvolumes - Renamed
VKLVdbLeafFormattoVKLFormat - Fixed incorrect use of system-installed CMake in superbuild while building dependencies
- Fixed various memory leaks
- Fixed crashes which could occur in
VdbVolume::cleanup()andvklShutdown() - Moved from ospcommon to rkcommon v1.4.1
- Added support for VDB sparse structured volumes (
"vdb"volume type) - Added
vdb_utillibrary to simplify instantiation of VDB volumes, and support loading of .vdb files using OpenVDB - Added
VKLObserverand associated APIs, which may used by volume types to pass information back to the application- A
LeafNodeAccessobserver is provided for VDB volumes to support on-demand loading of leaf nodes
- A
- Structured regular volumes:
- Up to 6x performance improvement for scalar iterator initialization
- Up to 2x performance improvement for scalar iterator iteration
- General improvements to the CMake Superbuild for building Open VKL and all associated dependencies
- Allowing instantiation of ISPC driver for any supported SIMD width (in addition to the default automatically selected width)
- Volume type names are now camelCase (legacy snake_case type names are
deprecated), impacting
structuredRegularandstructuredSphericalvolumes - Enabling
flushDenormalsdriver mode by default - Aligning public
vkl_vvec3f[4,8,16]andvkl_vrange1f[4,8,16]types - Added
VKL_LOG_NONElog level - Fixed bug in
vklExampleswhich could lead to improper rendering on macOS Catalina - Fixed bug in unstructured volume interval iterator which could lead to errors with some combinations of lane masks
- Now providing binary releases for Linux, macOS, and Windows
- Added support for structured volumes on spherical grids
(
"structured_spherical"volume type) - Structured regular volumes:
- Up to 8x performance improvement for scalar (single-wide) sampling
- Fixed hit iterator bug which could lead to isosurfacing artifacts
- Renamed
voxelDataparameter todata
- Unstructured volumes:
- Up to 4x performance improvement for scalar (single-wide) sampling
- Improved interval iterator implementation for more efficient space skipping and tighter value bounds on returned intervals
- Now using Embree for BVH builds for faster build times / volume commits
- Renamed
vertex.valueandcell.valueparameters tovertex.dataandcell.data, respectively
- AMR volumes:
- renamed
block.cellWidthparameter tocellWidth, and clarified API documentation
- renamed
- Added
vklGetValueRange()API for querying volume value ranges - Added new driver parameters, APIs, and environment variables allowing user control of log levels, log / error output redirection, number of threads, and other options
vklIterateHit[4,8,16]()andvklIterateInterval[4,8,16]()calls now only populate hit / interval data for active lanes- Changed
VKLDataTypeenum values for better forward compatibility - ISPC-side hit and interval iterator objects must now be declared
varying - More flexible ISA build configuration through
OPENVKL_MAX_ISAandOPENVKL_ISA_*CMake build options - Minimum ospcommon version is now 1.1.0
- Initial public alpha release, with support for structured, unstructured, and AMR volumes.
Open VKL is under active development, and though we do our best to guarantee stable release versions a certain number of bugs, as-yet-missing features, inconsistencies, or any other issues are still possible. Should you find any such issues please report them immediately via Open VKL’s GitHub Issue Tracker (or, if you should happen to have a fix for it, you can also send us a pull request); you may also contact us via email at [email protected].
Join our mailing list to receive release announcements and major news regarding Open VKL.
The Open VKL API is provided in two parts: a host-side API which is responsible for object creation and configuration (e.g. instantiating new volumes and providing data from the application), and a device-side API which provides access to low-level kernels such as volume sampling and iteration. The host-side API is identical for all Open VKL device implementations, while the device-side API varies slightly between device implementations.
To access the Open VKL host-side API you first need to include the Open VKL header. For C99 or C++:
#include <openvkl/openvkl.h>Additionally, the device-side APIs are provided through a device-specific header provided by the currently linked-to device:
#include <openvkl/device/openvkl.h>CPU applications using the Intel® Implicit SPMD Program Compiler (Intel® ISPC) can include the host- and device-side APIs similarly via:
#include <openvkl/openvkl.isph>
#include <openvkl/device/openvkl.isph>This documentation will discuss the C99/C++ API. The ISPC version has
the same functionality and flavor. Looking at the headers, the
vklTutorialISPC example, and this documentation should be enough to
figure it out.
To use the API, one of the implemented backends must be linked at compile time. Currently both a CPU and GPU device are available. To link one of these devices within CMake, use for example:
target_link_libraries(myApp PRIVATE openvkl::openvkl openvkl::openvkl_module_cpu_device)or
target_link_libraries(myApp PRIVATE openvkl::openvkl openvkl::openvkl_module_gpu_device)The application code must then first initialize Open VKL:
vklInit();A device then needs to be instantiated, either via:
VKLDevice device = vklNewDevice("cpu");or
VKLDevice device = vklNewDevice("gpu");By default, the CPU device selects the maximum supported SIMD width (and
associated ISA) for the system. Optionally, a specific width may be
requested using the cpu_4, cpu_8, or cpu_16 device names. Note
that the system must support the given width (SSE4.1 for 4-wide, AVX for
8-wide, and AVX512 for 16-wide).
Once a device is created, you can call
void vklDeviceSetInt(VKLDevice, const char *name, int val);
void vklDeviceSetString(VKLDevice, const char *name, const char *val);to set parameters on the device. The following parameters are understood by all devices:
| Type | Name | Description |
|---|---|---|
| int | logLevel | logging level; valid values are VKL_LOG_DEBUG, VKL_LOG_INFO, VKL_LOG_WARNING, VKL_LOG_ERROR and VKL_LOG_NONE |
| string | logOutput | convenience for setting where log messages go; valid values are cout, cerr and none |
| string | errorOutput | convenience for setting where error messages go; valid values are cout, cerr and none |
| int | numThreads | number of threads which Open VKL can use |
| int | flushDenormals | sets the Flush to Zero and Denormals are Zero mode of the MXCSR control and status register (default: 1); see Performance Recommendations section for details |
Parameters shared by all devices.
Additionally, the following parameters are understood by the gpu
device:
| Type | Name | Description |
|---|---|---|
| void * | syclContext | REQUIRED: pointer to a valid SYCL context |
Parameters understood by the gpu device
Once parameters are set, the device must be committed with
vklCommitDevice(device);The newly committed device is then ready to use. Users may change parameters on a device after initialization. In this case the device would need to be re-committed.
All Open VKL objects are associated with a device. A device handle must
be explicitly provided when creating volume and data objects, via
vklNewVolume() and vklNewData() respectively. Other object types are
automatically associated with a device via transitive dependency on a
volume.
On CPU, Open VKL provides vector-wide versions for several APIs. To determine the native vector width for a given device, call:
int width = vklGetNativeSIMDWidth(VKLDevice device);When the application is finished with an Open VKL device or shutting down, release the device via:
vklReleaseDevice(VKLDevice device);The generic device parameters can be overridden via environment
variables for easy changes to Open VKL’s behavior without needing to
change the application (variables are prefixed by convention with
“OPENVKL_”):
| Variable | Description |
|---|---|
| OPENVKL_LOG_LEVEL | logging level; valid values are debug, info, warning, error and none |
| OPENVKL_LOG_OUTPUT | convenience for setting where log messages go; valid values are cout, cerr and none |
| OPENVKL_ERROR_OUTPUT | convenience for setting where error messages go; valid values are cout, cerr and none |
| OPENVKL_THREADS | number of threads which Open VKL can use |
| OPENVKL_FLUSH_DENORMALS | sets the Flush to Zero and Denormals are Zero mode of the MXCSR control and status register (default: 1); see Performance Recommendations section for details |
Environment variables understood by all devices.
Note that these environment variables take precedence over values set
through the vklDeviceSet*() functions.
Additionally, the CPU device’s default SIMD width can be overriden at
run time with the OPENVKL_CPU_DEVICE_DEFAULT_WIDTH environment
variable. Legal values are 4, 8, or 16. This setting is only applicable
when the generic cpu device is instantiated; if a specific width is
requested via the cpu_[4,8,16] device names then the environment
variable is ignored.
The following errors are currently used by Open VKL:
| Name | Description |
|---|---|
| VKL_NO_ERROR | no error occurred |
| VKL_UNKNOWN_ERROR | an unknown error occurred |
| VKL_INVALID_ARGUMENT | an invalid argument was specified |
| VKL_INVALID_OPERATION | the operation is not allowed for the specified object |
| VKL_OUT_OF_MEMORY | there is not enough memory to execute the command |
| VKL_UNSUPPORTED_CPU | the CPU is not supported (minimum ISA is SSE4.1) |
Possible error codes, i.e., valid named constants of type VKLError.
These error codes are either directly returned by some API functions, or are recorded to be later queried by the application via
VKLError vklDeviceGetLastErrorCode(VKLDevice);A more descriptive error message can be queried by calling
const char* vklDeviceGetLastErrorMsg(VKLDevice);Alternatively, the application can also register a callback function of type
typedef void (*VKLErrorCallback)(void *, VKLError, const char* message);via
void vklDeviceSetErrorCallback(VKLDevice, VKLErrorFunc, void *);to get notified when errors occur. Applications may be interested in messages which Open VKL emits, whether for debugging or logging events. Applications can register a callback function of type
typedef void (*VKLLogCallback)(void *, const char* message);via
void vklDeviceSetLogCallback(VKLDevice, VKLLogCallback, void *);which Open VKL will use to emit log messages. Applications can clear
either callback by passing nullptr instead of an actual function
pointer. By default, Open VKL uses cout and cerr to emit log and
error messages, respectively. The last parameter to
vklDeviceSetErrorCallback and vklDeviceSetLogCallback is a user data
pointer. Open VKL passes this pointer to the callback functions as the
first parameter. Note that in addition to setting the above callbacks,
this behavior can be changed via the device parameters and environment
variables described previously.
Open VKL defines 3-component vectors of integer and float types:
typedef struct
{
int x, y, z;
} vkl_vec3i;
typedef struct
{
float x, y, z;
} vkl_vec3f;Vector versions of these are also defined in structure-of-array format for 4, 8, and 16 wide types.
typedef struct
{
float x[WIDTH];
float y[WIDTH];
float z[WIDTH];
} vkl_vvec3f##WIDTH;
typedef struct
{
float lower[WIDTH], upper[WIDTH];
} vkl_vrange1f##WIDTH;1-D range and 3-D ranges are defined as ranges and boxes, with no vector versions:
typedef struct
{
float lower, upper;
} vkl_range1f;
typedef struct
{
vkl_vec3f lower, upper;
} vkl_box3f;Objects in Open VKL are exposed to the APIs as handles with internal
reference counting for lifetime determination. Objects are created with
each particular type’s vklNew... API entry point. For example,
vklNewData and vklNewVolume.
In general, modifiable parameters to objects are modified using
vklSet... functions based on the type of the parameter being set. The
parameter name is passed as a string. Below are variants of vklSet....
void vklSetBool(VKLObject object, const char *name, int b);
void vklSetFloat(VKLObject object, const char *name, float x);
void vklSetVec3f(VKLObject object, const char *name, float x, float y, float z);
void vklSetInt(VKLObject object, const char *name, int x);
void vklSetVec3i(VKLObject object, const char *name, int x, int y, int z);
void vklSetData(VKLObject object, const char *name, VKLData data);
void vklSetString(VKLObject object, const char *name, const char *s);
void vklSetVoidPtr(VKLObject object, const char *name, void *v);A more generic parameter setter is also available, which allows setting parameters beyond the explicit types above:
void vklSetParam(VKLObject object,
const char *name,
VKLDataType dataType,
const void *mem);Note that mem must always be a pointer to the object, otherwise
accidental type casting can occur. This is especially true for pointer
types (VKL_VOID_PTR and VKLObject handles), as they will implicitly
cast to void\ *, but be incorrectly interpreted.
After parameters have been set, vklCommit must be called on the object
to make them take effect.
Open VKL uses reference counting to manage the lifetime of all objects. Therefore one cannot explicitly “delete” any object. Instead, one can indicate the application does not need or will not access the given object anymore by calling
void vklRelease(VKLObject);This decreases the object’s reference count. If the count reaches 0
the object will automatically be deleted.
Large data is passed to Open VKL via a VKLData handle created with
vklNewData:
VKLData vklNewData(VKLDevice device,
size_t numItems,
VKLDataType dataType,
const void *source,
VKLDataCreationFlags dataCreationFlags,
size_t byteStride);Data objects can be created as Open VKL owned
(dataCreationFlags = VKL_DATA_DEFAULT), in which the library will make
a copy of the data for its use, or shared
(dataCreationFlags = VKL_DATA_SHARED_BUFFER), which will try to use
the passed pointer for usage. The library is allowed to copy data when a
volume is committed. Note that for the gpu device, shared data buffers
only support source data from USM shared allocations.
The distance between consecutive elements in source is given in bytes
with byteStride. If the provided byteStride is zero, then it will be
determined automatically as sizeof(type). Open VKL owned data will be
compacted into a naturally-strided array on copy, regardless of the
original byteStride.
As with other object types, when data objects are no longer needed they
should be released via vklRelease.
The enum type VKLDataType describes the different element types that
can be represented in Open VKL. The types accepted vary per volume; see
the volume section for specifics. Valid constants are listed in the
table below.
| Type/Name | Description |
|---|---|
| VKL_DEVICE | API device object reference |
| VKL_DATA | data reference |
| VKL_OBJECT | generic object reference |
| VKL_VOLUME | volume object reference |
| VKL_STRING | C-style zero-terminated character string |
| VKL_CHAR, VKL_VEC[234]C | 8 bit signed character scalar and [234]-element vector |
| VKL_UCHAR, VKL_VEC[234]UC | 8 bit unsigned character scalar and [234]-element vector |
| VKL_SHORT, VKL_VEC[234]S | 16 bit unsigned integer scalar and [234]-element vector |
| VKL_USHORT, VKL_VEC[234]US | 16 bit unsigned integer scalar and [234]-element vector |
| VKL_INT, VKL_VEC[234]I | 32 bit signed integer scalar and [234]-element vector |
| VKL_UINT, VKL_VEC[234]UI | 32 bit unsigned integer scalar and [234]-element vector |
| VKL_LONG, VKL_VEC[234]L | 64 bit signed integer scalar and [234]-element vector |
| VKL_ULONG, VKL_VEC[234]UL | 64 bit unsigned integer scalar and [234]-element vector |
| VKL_HALF, VKL_VEC[234]H | 16 bit half precision floating-point scalar and [234]-element vector (IEEE 754 binary16) |
| VKL_FLOAT, VKL_VEC[234]F | 32 bit single precision floating-point scalar and [234]-element vector |
| VKL_DOUBLE, VKL_VEC[234]D | 64 bit double precision floating-point scalar and [234]-element vector |
| VKL_BOX[1234]I | 32 bit integer box (lower + upper bounds) |
| VKL_BOX[1234]F | 32 bit single precision floating-point box (lower + upper bounds) |
| VKL_LINEAR[23]F | 32 bit single precision floating-point linear transform ([23] vectors) |
| VKL_AFFINE[23]F | 32 bit single precision floating-point affine transform (linear transform plus translation) |
| VKL_VOID_PTR | raw memory address |
Valid named constants for VKLDataType.
Open VKL currently supports structured volumes on regular and spherical
grids; unstructured volumes with tetrahedral, wedge, pyramid, and
hexahedral primitive types; adaptive mesh refinement (AMR) volumes;
sparse VDB volumes; and particle volumes. Volumes are created with
vklNewVolume with a device and appropriate type string:
VKLVolume vklNewVolume(VKLDevice device, const char *type);In addition to the usual vklSet...() and vklCommit() APIs, the
volume bounding box can be queried:
vkl_box3f vklGetBoundingBox(VKLVolume volume);The number of attributes in a volume can also be queried:
unsigned int vklGetNumAttributes(VKLVolume volume);Finally, the value range of the volume for a given attribute can be queried:
vkl_range1f vklGetValueRange(VKLVolume volume, unsigned int attributeIndex);Structured volumes only need to store the values of the samples, because
their addresses in memory can be easily computed from a 3D position.
Data can be provided either per cell or per vertex (the default),
selectable via the cellCentered parameter. This parameter also affects
the interpretation of the volume’s dimensions, which will be in units of
cells or vertices, respectively. A volume with
A common type of structured volumes are regular grids, which are created
by passing a type string of "structuredRegular" to vklNewVolume. The
parameters understood by structured regular volumes are summarized in
the table below.
| Type | Name | Default | Description |
|---|---|---|---|
| vec3i | dimensions | number of values in each dimension |
|
| VKLData VKLData[] | data | VKLData object(s) of volume data, supported types are: | |
VKL_UCHAR |
|||
VKL_SHORT |
|||
VKL_USHORT |
|||
VKL_HALF |
|||
VKL_FLOAT |
|||
VKL_DOUBLE |
|||
| Multiple attributes are supported through passing an array of VKLData objects. | |||
| bool | cellCentered | false | indicates if data is provided per cell (true) or per vertex (false) |
| vec3f | gridOrigin | origin of the grid in object space | |
| vec3f | gridSpacing | size of the grid cells in object space | |
| affine3f | indexToObject | 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0 | Defines the transformation from index space to object space. In index space, the grid is an axis-aligned regular grid, and grid cells have size (1,1,1). This parameter takes precedence over gridOrigin and gridSpacing, if provided. |
| vec3i | indexOrigin | Defines the index space origin of the volume. This translation is applied before any (gridOrigin, gridSpacing) or indexToObject transformation. |
|
| uint32 | temporalFormat | VKL_TEMPORAL_FORMAT_CONSTANT |
The temporal format for this volume. Use VKLTemporalFormat for named constants. Structured regular volumes support VKL_TEMPORAL_FORMAT_CONSTANT, VKL_TEMPORAL_FORMAT_STRUCTURED, and VKL_TEMPORAL_FORMAT_UNSTRUCTURED. |
| int | temporallyStructuredNumTimesteps | For temporally structured variation, number of timesteps per voxel. Only valid if temporalFormat is VKL_TEMPORAL_FORMAT_STRUCTURED. |
|
| uint32[] uint64[] | temporallyUnstructuredIndices | For temporally unstructured variation, indices to data time series beginning per voxel. Only valid if temporalFormat is VKL_TEMPORAL_FORMAT_UNSTRUCTURED. |
|
| float[] | temporallyUnstructuredTimes | For temporally unstructured variation, time values corresponding to values in data. Only valid if temporalFormat is VKL_TEMPORAL_FORMAT_UNSTRUCTURED. |
|
| float[] | background | VKL_BACKGROUND_UNDEFINED |
For each attribute, the value that is returned when sampling an undefined region outside the volume domain. |
Configuration parameters for structured regular ("structuredRegular")
volumes.
Structured regular volumes support temporally structured and temporally unstructured temporal variation. See section ‘Temporal Variation’ for more detail.
The following additional parameters can be set both on
"structuredRegular" volumes and their sampler objects. Sampler object
parameters default to volume parameters.
| Type | Name | Default | Description |
|---|---|---|---|
| int | filter | VKL_FILTER_LINEAR |
The filter used for reconstructing the field. Use VKLFilter for named constants. |
| int | gradientFilter | filter |
The filter used for reconstructing the field during gradient computations. Use VKLFilter for named constants. |
Configuration parameters for structured regular ("structuredRegular")
volumes and their sampler objects.
Structured regular volumes support the filter types
VKL_FILTER_NEAREST, VKL_FILTER_LINEAR, and VKL_FILTER_CUBIC for
both filter and gradientFilter.
Note that when gradientFilter is set to VKL_FILTER_NEAREST,
gradients are always
Structured spherical volumes are also supported, which are created by
passing a type string of "structuredSpherical" to vklNewVolume. The
grid dimensions and parameters are defined in terms of radial distance
(
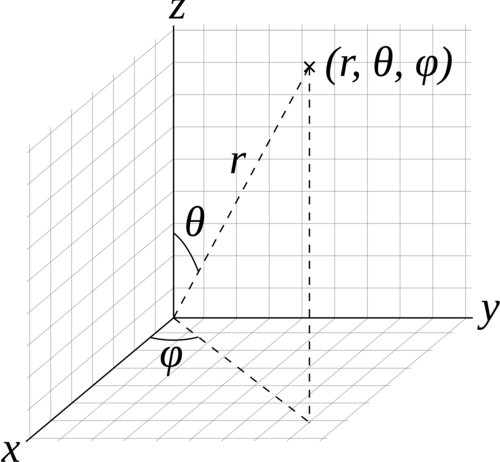
| Type | Name | Default | Description |
|---|---|---|---|
| vec3i | dimensions | number of voxels in each dimension |
|
| VKLData VKLData[] | data | VKLData object(s) of voxel data, supported types are: | |
VKL_UCHAR |
|||
VKL_SHORT |
|||
VKL_USHORT |
|||
VKL_HALF |
|||
VKL_FLOAT |
|||
VKL_DOUBLE |
|||
| Multiple attributes are supported through passing an array of VKLData objects. | |||
| vec3f | gridOrigin | origin of the grid in units of |
|
| vec3f | gridSpacing | size of the grid cells in units of |
|
| float[] | background | VKL_BACKGROUND_UNDEFINED |
For each attribute, the value that is returned when sampling an undefined region outside the volume domain. |
Configuration parameters for structured spherical
("structuredSpherical") volumes.
These grid parameters support flexible specification of spheres,
hemispheres, spherical shells, spherical wedges, and so forth. The grid
extents (computed as
$r \geq 0$ $0 \leq \theta \leq 180$ $0 \leq \phi \leq 360$
The following additional parameters can be set both on
"structuredSpherical" volumes and their sampler objects. Sampler
object parameters default to volume parameters.
| Type | Name | Default | Description |
|---|---|---|---|
| int | filter | VKL_FILTER_LINEAR |
The filter used for reconstructing the field. Use VKLFilter for named constants. |
| int | gradientFilter | filter |
The filter used for reconstructing the field during gradient computations. Use VKLFilter for named constants. |
Configuration parameters for structured spherical
("structuredSpherical") volumes and their sampler objects.
Open VKL currently supports block-structured (Berger-Colella) AMR volumes. Volumes are specified as a list of blocks, which exist at levels of refinement in potentially overlapping regions. Blocks exist in a tree structure, with coarser refinement level blocks containing finer blocks. The cell width is equal for all blocks at the same refinement level, though blocks at a coarser level have a larger cell width than finer levels.
There can be any number of refinement levels and any number of blocks at any level of refinement.
Blocks are defined by three parameters: their bounds, the refinement level in which they reside, and the scalar data contained within each block.
Note that cell widths are defined per refinement level, not per block.
AMR volumes are created by passing the type string "amr" to
vklNewVolume, and have the following parameters:
| Type | Name | Default | Description |
|---|---|---|---|
| float[] | cellWidth | [data] array of each level’s cell width | |
| box3i[] | block.bounds | [data] array of each block’s bounds (in voxels) | |
| int[] | block.level | [data] array of each block’s refinement level | |
| VKLData[] | block.data | [data] array of each block’s VKLData object containing the actual scalar voxel data. Currently only VKL_FLOAT data is supported. |
|
| vec3f | gridOrigin | origin of the grid in object space | |
| vec3f | gridSpacing | size of the grid cells in object space | |
| float | background | VKL_BACKGROUND_UNDEFINED |
The value that is returned when sampling an undefined region outside the volume domain. |
Configuration parameters for AMR ("amr") volumes.
Note that the gridOrigin and gridSpacing parameters act just like
the structured volume equivalent, but they only modify the root
(coarsest level) of refinement.
The following additional parameters can be set both on "amr" volumes
and their sampler objects. Sampler object parameters default to volume
parameters.
| Type | Name | Default | Description |
|---|---|---|---|
VKLAMRMethod |
method | VKL_AMR_CURRENT |
VKLAMRMethod sampling method. Supported methods are: |
VKL_AMR_CURRENT |
|||
VKL_AMR_FINEST |
|||
VKL_AMR_OCTANT |
Configuration parameters for AMR ("AMR") volumes and their sampler
objects.
Open VKL’s AMR implementation was designed to cover Berger-Colella [1]
and Chombo [2] AMR data. The method parameter above determines the
interpolation method used when sampling the volume.
VKL_AMR_CURRENTfinds the finest refinement level at that cell and interpolates through this “current” levelVKL_AMR_FINESTwill interpolate at the closest existing cell in the volume-wide finest refinement level regardless of the sample cell’s levelVKL_AMR_OCTANTinterpolates through all available refinement levels at that cell. This method avoids discontinuities at refinement level boundaries at the cost of performance
Gradients are computed using finite differences, using the method
defined on the sampler.
Details and more information can be found in the publication for the implementation [3].
- M. J. Berger, and P. Colella. “Local adaptive mesh refinement for shock hydrodynamics.” Journal of Computational Physics 82.1 (1989): 64-84. DOI: 10.1016/0021-9991(89)90035-1
- M. Adams, P. Colella, D. T. Graves, J.N. Johnson, N.D. Keen, T. J. Ligocki. D. F. Martin. P.W. McCorquodale, D. Modiano. P.O. Schwartz, T.D. Sternberg and B. Van Straalen, Chombo Software Package for AMR Applications - Design Document, Lawrence Berkeley National Laboratory Technical Report LBNL-6616E.
- I. Wald, C. Brownlee, W. Usher, and A. Knoll. CPU volume rendering of adaptive mesh refinement data. SIGGRAPH Asia 2017 Symposium on Visualization on - SA ’17, 18(8), 1–8. DOI: 10.1145/3139295.3139305
Unstructured volumes can have their topology and geometry freely defined. Geometry can be composed of tetrahedral, hexahedral, wedge or pyramid cell types. The data format used is compatible with VTK and consists of multiple arrays: vertex positions and values, vertex indices, cell start indices, cell types, and cell values.
Sampled cell values can be specified either per-vertex (vertex.data)
or per-cell (cell.data). If both arrays are set, cell.data takes
precedence.
Similar to a mesh, each cell is formed by a group of indices into the
vertices. For each vertex, the corresponding (by array index) data value
will be used for sampling when rendering, if specified. The index order
for a tetrahedron is the same as VTK_TETRA: bottom triangle
counterclockwise, then the top vertex.
For hexahedral cells, each hexahedron is formed by a group of eight
indices into the vertices and data values. Vertex ordering is the same
as VTK_HEXAHEDRON: four bottom vertices counterclockwise, then top
four counterclockwise.
For wedge cells, each wedge is formed by a group of six indices into the
vertices and data values. Vertex ordering is the same as VTK_WEDGE:
three bottom vertices counterclockwise, then top three counterclockwise.
For pyramid cells, each cell is formed by a group of five indices into
the vertices and data values. Vertex ordering is the same as
VTK_PYRAMID: four bottom vertices counterclockwise, then the top
vertex.
To maintain VTK data compatibility, the index array may be specified
with cell sizes interleaved with vertex indices in the following format:
index array
layout can be enabled through the indexPrefixed flag (in which case,
the cell.type parameter should be omitted).
Gradients are computed using finite differences.
Unstructured volumes are created by passing the type string
"unstructured" to vklNewVolume, and have the following parameters:
| Type | Name | Default | Description |
|---|---|---|---|
| vec3f[] | vertex.position | [data] array of vertex positions | |
| float[] | vertex.data | [data] array of vertex data values to be sampled | |
| uint32[] / uint64[] | index | [data] array of indices (into the vertex array(s)) that form cells | |
| bool | indexPrefixed | false | indicates that the index array is provided in a VTK-compatible format, where the indices of each cell are prefixed with the number of vertices |
| uint32[] / uint64[] | cell.index | [data] array of locations (into the index array), specifying the first index of each cell | |
| float[] | cell.data | [data] array of cell data values to be sampled | |
| uint8[] | cell.type | [data] array of cell types (VTK compatible). Supported types are: | |
VKL_TETRAHEDRON |
|||
VKL_HEXAHEDRON |
|||
VKL_WEDGE |
|||
VKL_PYRAMID |
|||
| bool | hexIterative | false | hexahedron interpolation method, defaults to fast non-iterative version which could have rendering inaccuracies may appear if hex is not parallelepiped |
| bool | precomputedNormals | false | whether to accelerate by precomputing, at a cost of 12 bytes/face |
| float | background | VKL_BACKGROUND_UNDEFINED |
The value that is returned when sampling an undefined region outside the volume domain. |
Configuration parameters for unstructured ("unstructured") volumes.
VDB volumes implement a data structure that is very similar to the data structure outlined in Museth [1].
The data structure is a hierarchical regular grid at its core: Nodes are regular grids, and each grid cell may either store a constant value (this is called a tile), or child pointers.
Nodes in VDB trees are wide: Nodes on the first level have a resolution of 32^3 voxels by default, on the next level 16^3, and on the leaf level 8^3 voxels. All nodes on a given level have the same resolution. This makes it easy to find the node containing a coordinate using shift operations (cp. [1]).
VDB leaf nodes are implicit in Open VKL: they are stored as pointers to user-provided data.

VDB volumes interpret input data as constant cells (which are then
potentially filtered). This is in contrast to structuredRegular
volumes, which can have either a vertex-centered or cell-centered
interpretation.
The VDB implementation in Open VKL follows the following goals:
-
Efficient data structure traversal on vector architectures.
-
Enable the use of industry-standard .vdb files created through the OpenVDB library.
-
Compatibility with OpenVDB on a leaf data level, so that .vdb files may be loaded with minimal overhead.
VDB volumes are created by passing the type string "vdb" to
vklNewVolume, and have the following parameters:
| Type | Name | Default | Description |
|---|---|---|---|
| affine3f float[] | indexToObject | 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0 | Defines the transformation from index space to object space. In index space, the grid is an axis-aligned regular grid, and leaf voxels have size (1,1,1). A vkl_affine3f can be provided; alternatively an array of 12 values of type float can be used, where the first 9 values are interpreted as a row-major linear transformation matrix, and the last 3 values are the translation of the grid origin. |
| uint32[] | node.format | For each input node, the data format. Currently supported are VKL_FORMAT_TILE for tiles, and VKL_FORMAT_DENSE_ZYX for nodes that are dense regular grids. |
|
| uint32[] | node.level | For each input node, the level on which this node exists. Tiles may exist on levels [1, VKL_VDB_NUM_LEVELS-1], all other nodes may only exist on level VKL_VDB_NUM_LEVELS-1. |
|
| vec3i[] | node.origin | For each input node, the node origin index. | |
| VKLData[] | node.data | For each input node, the attribute data. Single-attribute volumes may have one array provided per node, while multi-attribute volumes require an array per attribute for each node. Nodes with format VKL_FORMAT_TILE are expected to have single-entry arrays per attribute. Nodes with format VKL_FORMAT_DENSE_ZYX are expected to have arrays with vklVdbLevelNumVoxels(level[i]) entries per attribute. VKL_HALF and VKL_FLOAT data is currently supported; all nodes for a given attribute must be the same data type. |
|
| uint32[] | node.temporalFormat | VKL_TEMPORAL_FORMAT_CONSTANT |
The temporal format for this volume. Use VKLTemporalFormat for named constants. VDB volumes support VKL_TEMPORAL_FORMAT_CONSTANT, VKL_TEMPORAL_FORMAT_STRUCTURED, and VKL_TEMPORAL_FORMAT_UNSTRUCTURED. |
| int[] | node.temporallyStructuredNumTimesteps | For temporally structured variation, number of timesteps per voxel. Only valid if temporalFormat is VKL_TEMPORAL_FORMAT_STRUCTURED. |
|
| VKLData[] | node.temporallyUnstructuredIndices | For temporally unstructured variation, beginning per voxel. Supported data types for each node are VKL_UINT and VKL_ULONG. Only valid if temporalFormat is VKL_TEMPORAL_FORMAT_UNSTRUCTURED. |
|
| VKLData[] | node.temporallyUnstructuredTimes | For temporally unstructured variation, time values corresponding to values in node.data. For each node, the data must be of type VKL_FLOAT. Only valid if temporalFormat is VKL_TEMPORAL_FORMAT_UNSTRUCTURED. |
|
| VKLData[] | nodesPackedDense | Optionally provided instead of node.data, for each attribute a single array of all dense node data (VKL_FORMAT_DENSE_ZYX only) in a contiguous layout, provided in the same order as the corresponding node.* parameters. This packed layout may be more performant. Supported for temporally constant data only. |
|
| VKLData[] | nodesPackedTile | Optionally provided instead of node.data, for each attribute a single array of all tile node data (VKL_FORMAT_TILE only) in a contiguous layout, provided in the same order as the corresponding node.* parameters. This packed layout may be more performant. Supported for temporally constant data only. |
|
| float[] | background | VKL_BACKGROUND_UNDEFINED |
For each attribute, the value that is returned when sampling an undefined region outside the volume domain. |
| box3i | indexClippingBounds | Clips the volume to the specified index-space bounding box. This is useful for volumes with dimensions that are not even multiples of the leaf node dimensions, or .vdb files with restrictive active voxel bounding boxes. |
Configuration parameters for VDB ("vdb") volumes.
The level, origin, format, and data parameters must have the same size,
and there must be at least one valid node or commit() will fail. The
nodesPackedDense and nodesPackedTile parameters may be provided
instead of node.data; this packed data layout may provide better
performance.
VDB volumes support temporally structured and temporally unstructured temporal variation. See section ‘Temporal Variation’ for more detail.
The following additional parameters can be set both on vdb volumes and
their sampler objects (sampler object parameters default to volume
parameters).
| Type | Name | Default | Description |
|---|---|---|---|
| int | filter | VKL_FILTER_LINEAR |
The filter used for reconstructing the field. Use VKLFilter for named constants. |
| int | gradientFilter | filter |
The filter used for reconstructing the field during gradient computations. Use VKLFilter for named constants. |
| int | maxSamplingDepth | VKL_VDB_NUM_LEVELS-1 |
Do not descend further than to this depth during sampling. |
Configuration parameters for VDB ("vdb") volumes and their sampler
objects.
VDB volume objects support the following observers:
| Name | Buffer Type | Description |
|---|---|---|
| InnerNode | float[] | Return an array of bounding boxes, along with value ranges, of inner nodes in the data structure. The bounding box is given in object space. For a volume with M attributes, the entries in this array are (6+2*M)-tuples (minX, minY, minZ, maxX, maxY, maxZ, lower_0, upper_0, lower_1, upper_1, ...). This is in effect a low resolution representation of the volume. The InnerNode observer can be parametrized using int maxDepth to control the depth at which inner nodes are returned. Note that the observer will also return leaf nodes or tiles at lower levels if they exist. |
Observers supported by VDB ("vdb") volumes.
VDB sampler objects support the following observers:
| Name | Buffer Type | Description |
|---|---|---|
| LeafNodeAccess | uint32[] | This observer returns an array with as many entries as input nodes were passed. If the input node i was accessed during traversal, then the ith entry in this array has a nonzero value. This can be used for on-demand loading of leaf nodes. |
Observers supported by sampler objects created on VDB ("vdb") volumes.
VDB volumes support the filter types VKL_FILTER_NEAREST,
VKL_FILTER_LINEAR, and VKL_FILTER_CUBIC for both filter and
gradientFilter.
Note that when gradientFilter is set to VKL_FILTER_NEAREST,
gradients are always
-
Open VKL implements sampling in ISPC, and can exploit wide SIMD architectures.
-
VDB volumes in Open VKL are read-only once committed, and designed for rendering only. Authoring or manipulating datasets is not in the scope of this implementation.
-
The only supported field types are
VKL_HALFandVKL_FLOATat this point. Other field types may be supported in the future. Note that multi-attribute volumes may be used to represent multi-component (e.g. vector) fields. -
The root level in Open VKL has a single node with resolution 64^3 (cp. [1]. OpenVDB uses a hash map, instead).
-
Open VKL supports four-level vdb volumes. The resolution of each level can be configured at compile time using CMake variables.
-
VKL_VDB_LOG_RESOLUTION_0sets the base 2 logarithm of the root level resolution. This variable defaults to 6, which means that the root level has a resolution of$(2^6)^3 = 64^3$ . -
VKL_VDB_LOG_RESOLUTION_1andVKL_VDB_LOG_RESOLUTION_2default to 5 and 4, respectively. This matches the default Open VDB resolution for inner levels. -
VKL_VDB_LOG_RESOLUTION_3set the base 2 logarithm of the leaf level resolution, and defaults to 3. Therefore, leaf nodes have a resolution of$8^3$ voxels. Again, this matches the Open VDB default. The default settings lead to a domain resolution of$2^18^3=262144^3$ voxels.
-
Files generated with OpenVDB can be loaded easily since Open VKL vdb
volumes implement the same leaf data layout. This means that OpenVDB
leaf data pointers can be passed to Open VKL using shared data buffers,
avoiding copy operations.
An example of this can be found in
utility/vdb/include/openvkl/utility/vdb/OpenVdbGrid.h, where the class
OpenVdbFloatGrid encapsulates the necessary operations. This class is
also accessible through the vklExamples application using the -file
and -field command line arguments.
To use this example feature, compile Open VKL with OpenVDB_ROOT
pointing to the OpenVDB prefix.
- Museth, K. VDB: High-Resolution Sparse Volumes with Dynamic Topology. ACM Transactions on Graphics 32(3), 2013. DOI: 10.1145/2487228.2487235
Particle volumes consist of a set of points in space. Each point has a position, a radius, and a weight typically associated with an attribute. A radial basis function defines the contribution of that particle. Currently, we use the Gaussian radial basis function,
phi(P) = w * exp( -0.5 * ((P - p) / r)^2 )
where P is the particle position, p is the sample position, r is the radius and w is the weight.
At each sample, the scalar field value is then computed as the sum of each radial basis function phi, for each particle that overlaps it. Gradients are similarly computed, based on the summed analytical contributions of each contributing particle.
Particles with a radius less than or equal to zero are ignored. At least one valid particle (radius greater than zero) must be provided.
The Open VKL implementation is similar to direct evaluation of samples in Reda et al.[2]. It uses an Embree-built BVH with a custom traversal, similar to the method in [1].
Particle volumes are created by passing the type string "particle" to
vklNewVolume, and have the following parameters:
| Type | Name | Default | Description |
|---|---|---|---|
| vec3f[] | particle.position | [data] array of particle positions | |
| float[] | particle.radius | [data] array of particle radii | |
| float[] | particle.weight | null | [data] (optional) array of particle weights, specifying the height of the kernel. |
| float | radiusSupportFactor | 3.0 | The multipler of the particle radius required for support. Larger radii ensure smooth results at the cost of performance. In the Gaussian kernel, the the radius is one standard deviation (sigma), so a radiusSupportFactor of 3 corresponds to 3*sigma. |
| float | clampMaxCumulativeValue | 0 | The maximum cumulative value possible, set by user. All cumulative values will be clamped to this, and further traversal (RBF summation) of particle contributions will halt when this value is reached. A value of zero or less turns this off. |
| bool | estimateValueRanges | true | Enable heuristic estimation of value ranges which are used in internal acceleration structures for interval and hit iterators, as well as for determining the volume’s overall value range. When set to false, the user must specify clampMaxCumulativeValue, and all value ranges will be assumed [0, clampMaxCumulativeValue]. Disabling this may improve volume commit time, but will make interval and hit iteration less efficient. |
Configuration parameters for particle ("particle") volumes.
-
Knoll, A., Wald, I., Navratil, P., Bowen, A., Reda, K., Papka, M.E. and Gaither, K. (2014), RBF Volume Ray Casting on Multicore and Manycore CPUs. Computer Graphics Forum, 33: 71-80. doi:10.1111/cgf.12363
-
K. Reda, A. Knoll, K. Nomura, M. E. Papka, A. E. Johnson and J. Leigh, “Visualizing large-scale atomistic simulations in ultra-resolution immersive environments,” 2013 IEEE Symposium on Large-Scale Data Analysis and Visualization (LDAV), Atlanta, GA, 2013, pp. 59-65.
Open VKL supports two types of temporal variation: temporally structured and temporally unstructured. When one of these modes is enabled, the volume can be sampled at different times. In both modes, time is assumed to vary between zero and one. This can be useful for implementing renderers with motion blur, for example.
Temporal variation is generally configured through a parameter
temporalFormat, which accepts constants from the VKLTemporalFormat
enum, though not all modes may be supported by all volumes. On volumes
that expect multiple input nodes, the parameter is an array
node.temporalFormat, and must provide one value per node. Multiple
attributes in a voxel share the same temporal configuration. Please
refer to the individual volume sections above to find out supported for
each volume type.
temporalFormat defaults to VKL_TEMPORAL_FORMAT_CONSTANT for all
volume types. This means that no temporal variation is present in the
data.
Temporally structured variation is configured by setting
temporalFormat to VKL_TEMPORAL_FORMAT_STRUCTURED. In this mode, the
volume expects an additional parameter
[node.]temporallyStructuredNumTimesteps, which specifies how many time
steps are provided for all voxels, and must be at least 2. A volume, or
node, with
Temporally unstructured variation supports differing time step counts
and sample times per voxel. For temporallyUnstructuredIndices is an array of temporallyUnstructuredTimes specifies the times corresponding to the
sample values; the time values for each voxel must be between zero and
one and strictly increasing:
Computing the value of a volume at an object space coordinate is done using the sampling API, and sampler objects. Sampler objects can be created using
VKLSampler vklNewSampler(VKLVolume volume);Sampler objects may then be parametrized with traversal parameters.
Available parameters are defined by volumes, and are a subset of the
volume parameters. As an example, filter can be set on both vdb
volumes and their sampler objects. The volume parameter is used as the
default for sampler objects. The sampler object parameter provides an
override per ray. More detail on parameters can be found in the sections
on volumes. Use vklCommit() to commit parameters to the sampler
object.
The scalar API takes a volume and coordinate, and returns a float value.
The volume’s background value (by default VKL_BACKGROUND_UNDEFINED) is
returned for probe points outside the volume. The attribute index
selects the scalar attribute of interest; not all volumes support
multiple attributes. The time value, which must be between 0 and 1,
specifies the sampling time. For temporally constant volumes, this value
has no effect.
For the cpu device, the scalar sampling API is:
float vklComputeSample(const VKLSampler *sampler,
const vkl_vec3f *objectCoordinates,
unsigned int attributeIndex,
float time);while on the gpu device, it is:
float vklComputeSample(const VKLSampler *sampler,
const vkl_vec3f *objectCoordinates,
unsigned int attributeIndex,
float time,
const VKLFeatureFlags featureFlags);Note that the gpu sampling API introduces an additional featureFlags
argument. These provided “feature flags” allow Open VKL to prune
unnecessary code during just-in-time (JIT) compilation on GPU, providing
potentially significant performance gains. See section ‘Feature flag
usage on GPU’ for details.
On the cpu device, vector-wide and stream-wide sampling APIs are also
provided.
Vector versions allow sampling at 4, 8, or 16 positions at once.
Depending on the machine type and Open VKL device implementation, these
can give greater performance. An active lane mask valid is passed in
as an array of integers; set 0 for lanes to be ignored, -1 for active
lanes. An array of time values corresponding to each object coordinate
may be provided; a NULL value indicates all times are zero.
void vklComputeSample4(const int *valid,
const VKLSampler *sampler,
const vkl_vvec3f4 *objectCoordinates,
float *samples,
unsigned int attributeIndex,
const float *times);
void vklComputeSample8(const int *valid,
const VKLSampler *sampler,
const vkl_vvec3f8 *objectCoordinates,
float *samples,
unsigned int attributeIndex,
const float *times);
void vklComputeSample16(const int *valid,
const VKLSampler *sampler,
const vkl_vvec3f16 *objectCoordinates,
float *samples,
unsigned int attributeIndex,
const float *times);A stream version allows sampling an arbitrary number of positions at once. While the vector version requires coordinates to be provided in a structure-of-arrays layout, the stream version allows coordinates to be provided in an array-of-structures layout. Thus, the stream API can be used to avoid reformatting of data by the application. As with the vector versions, the stream API can give greater performance than the scalar API.
void vklComputeSampleN(const VKLSampler *sampler,
unsigned int N,
const vkl_vec3f *objectCoordinates,
float *samples,
unsigned int attributeIndex,
const float *times);All of the above sampling APIs can be used, regardless of the device’s native SIMD width.
Open VKL provides additional APIs for sampling multiple scalar
attributes in a single call through the vklComputeSampleM*()
interfaces. Beyond convenience, these can give improved performance
relative to the single attribute sampling APIs. As with the single
attribute APIs, sampling time values may be specified; note that these
are provided per object coordinate only (rather than separately per
attribute).
A scalar API supports sampling M attributes specified by
attributeIndices on a single object space coordinate:
For the cpu device, the scalar sampling API is:
void vklComputeSampleM(const VKLSampler *sampler,
const vkl_vec3f *objectCoordinates,
float *samples,
unsigned int M,
const unsigned int *attributeIndices,
float time);while on the gpu device, it is:
void vklComputeSampleM(const VKLSampler *sampler,
const vkl_vec3f *objectCoordinates,
float *samples,
unsigned int M,
const unsigned int *attributeIndices,
float time,
const VKLFeatureFlags featureFlags);Again, see section ‘Feature flag usage on GPU’ for details on feature flags.
On the cpu device, vector-wide and stream-wide sampling APIs are also
provided.
Vector versions allow sampling at 4, 8, or 16 positions at once across
the M attributes:
void vklComputeSampleM4(const int *valid,
const VKLSampler *sampler,
const vkl_vvec3f4 *objectCoordinates,
float *samples,
unsigned int M,
const unsigned int *attributeIndices,
const float *times);
void vklComputeSampleM8(const int *valid,
const VKLSampler *sampler,
const vkl_vvec3f8 *objectCoordinates,
float *samples,
unsigned int M,
const unsigned int *attributeIndices,
const float *times);
void vklComputeSampleM16(const int *valid,
const VKLSampler *sampler,
const vkl_vvec3f16 *objectCoordinates,
float *samples,
unsigned int M,
const unsigned int *attributeIndices,
const float *times);The [4, 8, 16] * M sampled values are populated in the samples array
in a structure-of-arrays layout, with all values for each attribute
provided in sequence. That is, sample values s_m,n for the mth
attribute and nth object coordinate will be populated as
samples = [s_0,0, s_0,1, ..., s_0,N-1,
s_1,0, s_1,1, ..., s_1,N-1,
...,
s_M-1,0, s_M-1,1, ..., s_M-1,N-1]A stream version allows sampling an arbitrary number of positions at
once across the M attributes. As with single attribute stream
sampling, the N coordinates are provided in an array-of-structures
layout.
void vklComputeSampleMN(const VKLSampler *sampler,
unsigned int N,
const vkl_vec3f *objectCoordinates,
float *samples,
unsigned int M,
const unsigned int *attributeIndices,
const float *times);The M * N sampled values are populated in the samples array in an
array-of-structures layout, with all attribute values for each
coordinate provided in sequence as
samples = [s_0,0, s_1,0, ..., s_M-1,0,
s_0,1, s_1,1, ..., s_M-1,1,
...,
s_0,N-1, s_1,N-1, ..., s_M-1,N-1]All of the above sampling APIs can be used, regardless of the device’s native SIMD width.
In a very similar API to vklComputeSample, vklComputeGradient
queries the value gradient at an object space coordinate. Again, a
scalar API, now returning a vec3f instead of a float. NaN values are
returned for points outside the volume. The time value, which must be
between 0 and 1, specifies the sampling time. For temporally constant
volumes, this value has no effect.
For the cpu device, the scalar sampling API is:
vkl_vec3f vklComputeGradient(const VKLSampler *sampler,
const vkl_vec3f *objectCoordinates,
unsigned int attributeIndex,
float time);while on the gpu device, it is:
vkl_vec3f vklComputeGradient(const VKLSampler *sampler,
const vkl_vec3f *objectCoordinates,
unsigned int attributeIndex,
float time,
const VKLFeatureFlags featureFlags);As with the sampling APIs, on the cpu device vector-wide and
stream-wide gradient APIs are also provided.
The vector versions are:
void vklComputeGradient4(const int *valid,
const VKLSampler *sampler,
const vkl_vvec3f4 *objectCoordinates,
vkl_vvec3f4 *gradients,
unsigned int attributeIndex,
const float *times);
void vklComputeGradient8(const int *valid,
const VKLSampler *sampler,
const vkl_vvec3f8 *objectCoordinates,
vkl_vvec3f8 *gradients,
unsigned int attributeIndex,
const float *times);
void vklComputeGradient16(const int *valid,
const VKLSampler *sampler,
const vkl_vvec3f16 *objectCoordinates,
vkl_vvec3f16 *gradients,
unsigned int attributeIndex,
const float *times);Finally, a stream version is provided:
void vklComputeGradientN(const VKLSampler *sampler,
unsigned int N,
const vkl_vec3f *objectCoordinates,
vkl_vec3f *gradients,
unsigned int attributeIndex,
const float *times);All of the above gradient APIs can be used, regardless of the device’s native SIMD width.
Open VKL has APIs to search for particular volume values along a ray.
Queries can be for ranges of volume values (vklIterateInterval) or for
particular values (vklIterateHit).
Interval iterators require a context object to define the sampler and parameters related to iteration behavior. An interval iterator context is created via
VKLIntervalIteratorContext vklNewIntervalIteratorContext(VKLSampler sampler);The parameters understood by interval iterator contexts are defined in the table below.
| Type | Name | Default | Description |
|---|---|---|---|
| int | attributeIndex | 0 | Defines the volume attribute of interest. |
| vkl_range1f[] | valueRanges | [-inf, inf] | Defines the value ranges of interest. Intervals not containing any of these values ranges may be skipped during iteration. |
| float | intervalResolutionHint | 0.5 | A value in the range [0, 1] affecting the resolution (size) of returned intervals. A value of 0 yields the lowest resolution (largest) intervals while 1 gives the highest resolution (smallest) intervals. This value is only a hint; it may not impact behavior for all volume types. |
Configuration parameters for interval iterator contexts.
Most volume types support the intervalResolutionHint parameter that
can impact the size of intervals returned duration iteration. These
include amr, particle, structuredRegular, unstructured, and
vdb volumes. In all cases a value of 1.0 yields the highest resolution
(smallest) intervals possible, while a value of 0.0 gives the lowest
resolution (largest) intervals. In general, smaller intervals will have
tighter bounds on value ranges, and more efficient space skipping
behavior than larger intervals, which can be beneficial for some
rendering methods.
For structuredRegular, unstructured, and vdb volumes, a value of
1.0 will enable elementary cell iteration, such that each interval spans
an individual voxel / cell intersection. Note that interval iteration
can be significantly slower in this case.
As with other objects, the interval iterator context must be committed before being used.
To query an interval, a VKLIntervalIterator of scalar or vector width
must be initialized with vklInitIntervalIterator. Time value(s) may be
provided to specify the sampling time. These values must be between 0
and 1; for the vector versions, a NULL value indicates all times are
zero. For temporally constant volumes, the time values have no effect.
On a gpu device, interval iterators may be initialized via:
VKLIntervalIterator vklInitIntervalIterator(const VKLIntervalIteratorContext *context,
const vkl_vec3f *origin,
const vkl_vec3f *direction,
const vkl_range1f *tRange,
float time,
void *buffer,
const VKLFeatureFlags featureFlags);Note again the featureFlags argument; see section ’Feature flag usage
on GPU` for details.
On a cpu device, interval iterators can be initialized via:
VKLIntervalIterator vklInitIntervalIterator(const VKLIntervalIteratorContext *context,
const vkl_vec3f *origin,
const vkl_vec3f *direction,
const vkl_range1f *tRange,
float time,
void *buffer);
VKLIntervalIterator4 vklInitIntervalIterator4(const int *valid,
const VKLIntervalIteratorContext *context,
const vkl_vvec3f4 *origin,
const vkl_vvec3f4 *direction,
const vkl_vrange1f4 *tRange,
const float *times,
void *buffer);
VKLIntervalIterator8 vklInitIntervalIterator8(const int *valid,
const VKLIntervalIteratorContext *context,
const vkl_vvec3f8 *origin,
const vkl_vvec3f8 *direction,
const vkl_vrange1f8 *tRange,
const float *times,
void *buffer);
VKLIntervalIterator16 vklInitIntervalIterator16(const int *valid,
const VKLIntervalIteratorContext *context,
const vkl_vvec3f16 *origin,
const vkl_vvec3f16 *direction,
const vkl_vrange1f16 *tRange,
const float *times,
void *buffer);Open VKL places the iterator struct into a user-provided buffer, and the returned handle is essentially a pointer into this buffer. This means that the iterator handle must not be used after the buffer ceases to exist. Copying iterator buffers is currently not supported.
The required size, in bytes, of the buffer can be queried with
size_t vklGetIntervalIteratorSize(const VKLIntervalIteratorContext *context);
size_t vklGetIntervalIteratorSize4(const VKLIntervalIteratorContext *context);
size_t vklGetIntervalIteratorSize8(const VKLIntervalIteratorContext *context);
size_t vklGetIntervalIteratorSize16(const VKLIntervalIteratorContext *context);The values these functions return may change depending on the parameters
set on sampler.
Open VKL also provides a conservative maximum size over all volume types
as a preprocessor definition (VKL_MAX_INTERVAL_ITERATOR_SIZE). For
ISPC use cases, Open VKL will attempt to detect the native vector width
using TARGET_WIDTH, which is defined in recent versions of ISPC, to
provide a less conservative size.
Intervals can then be processed by calling vklIterateInterval as long
as the returned lane masks indicates that the iterator is still within
the volume.
On a gpu device this is done via:
int vklIterateInterval(VKLIntervalIterator iterator,
VKLInterval *interval,
const VKLFeatureFlags featureFlags);while on a cpu device, iteration is via:
int vklIterateInterval(VKLIntervalIterator iterator,
VKLInterval *interval);
void vklIterateInterval4(const int *valid,
VKLIntervalIterator4 iterator,
VKLInterval4 *interval,
int *result);
void vklIterateInterval8(const int *valid,
VKLIntervalIterator8 iterator,
VKLInterval8 *interval,
int *result);
void vklIterateInterval16(const int *valid,
VKLIntervalIterator16 iterator,
VKLInterval16 *interval,
int *result);The intervals returned have a t-value range, a value range, and a
nominalDeltaT which is approximately the step size (in units of ray
direction) that should be used to walk through the interval, if desired.
The number and length of intervals returned is volume type
implementation dependent. There is currently no way of requesting a
particular splitting.
typedef struct
{
vkl_range1f tRange;
vkl_range1f valueRange;
float nominalDeltaT;
} VKLInterval;
typedef struct
{
vkl_vrange1f4 tRange;
vkl_vrange1f4 valueRange;
float nominalDeltaT[4];
} VKLInterval4;
typedef struct
{
vkl_vrange1f8 tRange;
vkl_vrange1f8 valueRange;
float nominalDeltaT[8];
} VKLInterval8;
typedef struct
{
vkl_vrange1f16 tRange;
vkl_vrange1f16 valueRange;
float nominalDeltaT[16];
} VKLInterval16;Querying for particular values is done using a VKLHitIterator in much
the same fashion. This API could be used, for example, to find
isosurfaces. As with interval iterators, time value(s) may be provided
to specify the sampling time. These values must be between 0 and 1; for
the vector versions, a NULL value indicates all times are zero. For
temporally constant volumes, the time values have no effect.
Hit iterators similarly require a context object to define the sampler and other iteration parameters. A hit iterator context is created via
VKLHitIteratorContext vklNewHitIteratorContext(VKLSampler sampler);The parameters understood by hit iterator contexts are defined in the table below.
| Type | Name | Default | Description |
|---|---|---|---|
| int | attributeIndex | 0 | Defines the volume attribute of interest. |
| float[] | values | Defines the value(s) of interest. |
Configuration parameters for hit iterator contexts.
The hit iterator context must be committed before being used.
Again, a user allocated buffer must be provided, and a VKLHitIterator
of the desired width must be initialized.
On a gpu device this is done via:
VKLHitIterator vklInitHitIterator(VKLHitIteratorContext context,
const vkl_vec3f *origin,
const vkl_vec3f *direction,
const vkl_range1f *tRange,
float time,
void *buffer,
const VKLFeatureFlags featureFlags);while on a cpu device initialization is via:
VKLHitIterator vklInitHitIterator(VKLHitIteratorContext context,
const vkl_vec3f *origin,
const vkl_vec3f *direction,
const vkl_range1f *tRange,
float time,
void *buffer);
VKLHitIterator4 vklInitHitIterator4(const int *valid,
VKLHitIteratorContext context,
const vkl_vvec3f4 *origin,
const vkl_vvec3f4 *direction,
const vkl_vrange1f4 *tRange,
const float *times,
void *buffer);
VKLHitIterator8 vklInitHitIterator8(const int *valid,
VKLHitIteratorContext context,
const vkl_vvec3f8 *origin,
const vkl_vvec3f8 *direction,
const vkl_vrange1f8 *tRange,
const float *times,
void *buffer);
VKLHitIterator16 vklInitHitIterator16(const int *valid,
VKLHitIteratorContext context,
const vkl_vvec3f16 *origin,
const vkl_vvec3f16 *direction,
const vkl_vrange1f16 *tRange,
const float *times,
void *buffer);Buffer size can be queried with
size_t vklGetHitIteratorSize(VKLHitIteratorContext context);
size_t vklGetHitIteratorSize4(VKLHitIteratorContext context);
size_t vklGetHitIteratorSize8(VKLHitIteratorContext context);
size_t vklGetHitIteratorSize16(VKLHitIteratorContext context);Open VKL also provides the macro VKL_MAX_HIT_ITERATOR_SIZE as a
conservative estimate.
Hits are then queried by looping a call to vklIterateHit as long as
the returned lane mask indicates that the iterator is still within the
volume.
On a gpu device, this is done via:
int vklIterateHit(VKLHitIterator iterator,
VKLHit *hit,
const VKLFeatureFlags featureFlags);while on a cpu device, the APIs are:
int vklIterateHit(VKLHitIterator iterator, VKLHit *hit);
void vklIterateHit4(const int *valid,
VKLHitIterator4 iterator,
VKLHit4 *hit,
int *result);
void vklIterateHit8(const int *valid,
VKLHitIterator8 iterator,
VKLHit8 *hit,
int *result);
void vklIterateHit16(const int *valid,
VKLHitIterator16 iterator,
VKLHit16 *hit,
int *result);Returned hits consist of a t-value, a volume value (equal to one of the requested values specified in the context), and an (object space) epsilon value estimating the error of the intersection:
typedef struct
{
float t;
float sample;
float epsilon;
} VKLHit;
typedef struct
{
float t[4];
float sample[4];
float epsilon[4];
} VKLHit4;
typedef struct
{
float t[8];
float sample[8];
float epsilon[8];
} VKLHit8;
typedef struct
{
float t[16];
float sample[16];
float epsilon[16];
} VKLHit16;For both interval and hit iterators, only the vector-wide API for the
native SIMD width (determined via vklGetNativeSIMDWidth can be called.
The scalar versions are always valid. This restriction will likely be
lifted in the future.
Volumes and samplers in Open VKL may provide observers to communicate
data back to the application. Please note that observers are currently
only allowed for the cpu device. Observers may be created with
VKLObserver vklNewSamplerObserver(VKLSampler sampler,
const char *type);
VKLObserver vklNewVolumeObserver(VKLVolume volume,
const char *type);The object passed to vklNew*Observer must already be committed. Valid
observer type strings are defined by volume implementations (see section
‘Volume types’ below).
vklNew*Observer returns NULL on failure.
To access the underlying data, an observer must first be mapped using
const void * vklMapObserver(VKLObserver observer);If this fails, the function returns NULL. vklMapObserver may fail on
observers that are already mapped. On success, the application may query
the underlying type, element size in bytes, and the number of elements
in the buffer using
VKLDataType vklGetObserverElementType(VKLObserver observer);
size_t vklGetObserverElementSize(VKLObserver observer);
size_t vklGetObserverNumElements(VKLObserver observer);On failure, these functions return VKL_UNKNOWN and 0, respectively.
Possible data types are defined by the volume that provides the observer
, as are the semantics of the observation. See section ‘Volume types’
for details.
The pointer returned by vklMapObserver may be cast to the type
corresponding to the value returned by vklGetObserverElementType to
access the observation. For example, if vklGetObserverElementType
returns VKL_FLOAT, then the pointer returned by vklMapObserver may
be cast to const float * to access up to vklGetObserverNumElements
consecutive values of type float.
Once the application has finished processing the observation, it should unmap the observer using
void vklUnmapObserver(VKLObserver observer);so that the observer may be mapped again.
When an observer is no longer needed, it should be released using
vklRelease.
The observer API is not thread safe, and these functions should not be called concurrently on the same object.
Feature flags are used extensively throughout the device-side APIs
defined by the gpu device. These flags identify the required feature
set for a given volume and sampler, and are used internally by Open VKL
to prune unnecessary code during just-in-time (JIT) compilation on the
GPU. Thus, using feature flags can provide a significant performance
gain on GPU, both for the one-time JIT compilation time and of course
for kernel execution times.
Feature flags must be populated separately for each VKLSampler used in
an application, via:
VKLFeatureFlags vklGetFeatureFlags(VKLSampler sampler);The resulting VKLFeatureFlags can be passed to sampling, gradient,
interval iterator, and hit iterator APIs.
It is strongly recommended to have the Flush to Zero and
Denormals are Zero mode of the MXCSR control and status register
enabled for each thread before calling the sampling, gradient, or
interval API functions. Otherwise, under some circumstances special
handling of denormalized floating point numbers can significantly reduce
application and Open VKL performance. The device parameter
flushDenormals or environment variable OPENVKL_FLUSH_DENORMALS can
be used to toggle this mode; by default it is enabled. Alternatively,
when using Open VKL together with the Intel® Threading Building Blocks,
it is sufficient to execute the following code at the beginning of the
application main thread (before the creation of the
tbb::task_scheduler_init object):
#include <xmmintrin.h>
#include <pmmintrin.h>
...
_MM_SET_FLUSH_ZERO_MODE(_MM_FLUSH_ZERO_ON);
_MM_SET_DENORMALS_ZERO_MODE(_MM_DENORMALS_ZERO_ON);If using a different tasking system, make sure each thread calling into Open VKL has the proper mode set.
vklInitIntervalIterator and vklInitHitIterator expect a user
allocated buffer. While this buffer can be allocated by any means, we
expect iterators to be used in inner loops and advise against heap
allocation in that case. Applications may provide high performance
memory pools, but as a preferred alternative we recommend stack
allocated buffers.
In C99, variable length arrays provide an easy way to achieve this:
const size_t bufferSize = vklGetIntervalIteratorSize(context);
char buffer[bufferSize];Note that the call to vklGetIntervalIteratorSize or
vklGetHitIteratorSize should not appear in an inner loop as it is
relatively costly. The return value depends on the volume type, target
architecture, and parameters to context.
In C++, variable length arrays are not part of the standard. Here, users
may rely on alloca and similar functions:
#include <alloca.h>
const size_t bufferSize = vklGetIntervalIteratorSize(context);
void *buffer = alloca(bufferSize);Similarly for ISPC, variable length arrays are not supported, but
alloca may be used:
const uniform size_t bufferSize = vklGetIntervalIteratorSizeV(context);
void *uniform buffer = alloca(bufferSize);Users should understand the implications of alloca. In particular,
alloca does check available stack space and may result in stack
overflow. buffer also becomes invalid at the end of the scope. As one
consequence, it cannot be returned from a function. On Windows,
_malloca is a safer option that performs additional error checking,
but requires the use of _freea.
Applications may instead rely on the VKL_MAX_INTERVAL_ITERATOR_SIZE
and VKL_MAX_HIT_ITERATOR_SIZE macros. For example, in ISPC:
uniform unsigned int8 buffer[VKL_MAX_INTERVAL_ITERATOR_SIZE];These values are majorants over all devices and volume types. Note that
Open VKL attempts to detect the target SIMD width using TARGET_WIDTH,
returning smaller buffer sizes for narrow architectures. However, Open
VKL may fall back to the largest buffer size over all targets.
Open VKL provides flexible managed data APIs that allow applications to
specify input data in various formats and layouts. When shared buffers
are used (dataCreationFlags = VKL_DATA_SHARED_BUFFER), Open VKL will
use the application-owned memory directly, respecting the input data
layout. Shared buffers therefore allow applications to strategically
select the best layout for multi-attribute volume data and expected
sampling behavior.
For volume attributes that are sampled individually (e.g. using
vklComputeSample[4,8,16,N]()), it is recommended to use a
structure-of-arrays layout. That is, each attribute’s data should be
compact in contiguous memory. This can be accomplished by simply using
Open VKL owned data objects (dataCreationFlags = VKL_DATA_DEFAULT), or
by using a natural byteStride for shared buffers.
For volume attributes that are sampled simultaneously (e.g. using
vklComputeSampleM[4,8,16,N]()), it is recommended to use an
array-of-structures layout. That is, data for these attributes should be
provided per voxel in a contiguous layout. This is accomplished using
shared buffers for each attribute with appropriate byte strides. For
example, for a three attribute structured volume representing a velocity
field, the data can be provided as:
// used in Open VKL shared buffers, so must not be freed by application
std::vector<vkl_vec3f> velocities(numVoxels);
for (auto &v : velocities) {
v.x = ...;
v.y = ...;
v.z = ...;
}
std::vector<VKLData> attributes;
attributes.push_back(vklNewData(device,
velocities.size(),
VKL_FLOAT,
&velocities[0].x,
VKL_DATA_SHARED_BUFFER,
sizeof(vkl_vec3f)));
attributes.push_back(vklNewData(device,
velocities.size(),
VKL_FLOAT,
&velocities[0].y,
VKL_DATA_SHARED_BUFFER,
sizeof(vkl_vec3f)));
attributes.push_back(vklNewData(device,
velocities.size(),
VKL_FLOAT,
&velocities[0].z,
VKL_DATA_SHARED_BUFFER,
sizeof(vkl_vec3f)));
VKLData attributesData =
vklNewData(device, attributes.size(), VKL_DATA, attributes.data());
for (auto &attribute : attributes)
vklRelease(attribute);
VKLVolume volume = vklNewVolume(device, "structuredRegular");
vklSetData(volume, "data", attributesData);
vklRelease(attributesData);
// set other volume parameters...
vklCommit(volume);These are general recommendations for common scenarios; it is still recommended to evaluate performance of different volume data layouts for your application’s particular use case.
Open VKL ships with simple tutorial applications demonstrating the basic usage of the API, as well as full renderers showing recommended usage.
Simple tutorials can be found in the
examples/
directory. These are:
vklTutorialCPU.c: usage of the C API with a CPU devicevklTutorialISPC.cppandvklTutorialISPC.ispc: combined usage of the C and ISPC APIs with a CPU devicevklTutorialGPU.cpp: usage of the SYCL API with a GPU device
Open VKL also ships with interactive example applications,
vklExamples[CPU,GPU].
The interactive viewer demonstrates multiple example renderers including
a path tracer, isosurface renderer (using hit iterators), and ray
marcher. The viewer UI supports switching between renderers
interactively.
For CPU, each renderer has both a C++ and ISPC implementation showing
recommended API usage. These implementations are available in the
examples/interactive/renderer/
directory. On GPU, the example renderers are written in SYCL.

For quick reference, the contents of
vklTutorialCPU.c
are shown below.
#include <openvkl/openvkl.h>
#include <openvkl/device/openvkl.h>
#include <stdio.h>
#if defined(_MSC_VER)
#include <malloc.h> // _malloca
#include <windows.h> // Sleep
#endif
void demoScalarAPI(VKLDevice device, VKLVolume volume)
{
printf("demo of 1-wide API\n");
VKLSampler sampler = vklNewSampler(volume);
vklCommit(sampler);
// bounding box
vkl_box3f bbox = vklGetBoundingBox(volume);
printf("\tbounding box\n");
printf("\t\tlower = %f %f %f\n", bbox.lower.x, bbox.lower.y, bbox.lower.z);
printf("\t\tupper = %f %f %f\n\n", bbox.upper.x, bbox.upper.y, bbox.upper.z);
// number of attributes
unsigned int numAttributes = vklGetNumAttributes(volume);
printf("\tnum attributes = %d\n\n", numAttributes);
// value range for all attributes
for (unsigned int i = 0; i < numAttributes; i++) {
vkl_range1f valueRange = vklGetValueRange(volume, i);
printf("\tvalue range (attribute %u) = (%f %f)\n",
i,
valueRange.lower,
valueRange.upper);
}
// coordinate for sampling / gradients
vkl_vec3f coord = {1.f, 2.f, 3.f};
printf("\n\tcoord = %f %f %f\n\n", coord.x, coord.y, coord.z);
// sample, gradient (first attribute)
unsigned int attributeIndex = 0;
float time = 0.f;
float sample = vklComputeSample(&sampler, &coord, attributeIndex, time);
vkl_vec3f grad = vklComputeGradient(&sampler, &coord, attributeIndex, time);
printf("\tsampling and gradient computation (first attribute)\n");
printf("\t\tsample = %f\n", sample);
printf("\t\tgrad = %f %f %f\n\n", grad.x, grad.y, grad.z);
// sample (multiple attributes)
unsigned int M = 3;
unsigned int attributeIndices[] = {0, 1, 2};
float samples[3];
vklComputeSampleM(&sampler, &coord, samples, M, attributeIndices, time);
printf("\tsampling (multiple attributes)\n");
printf("\t\tsamples = %f %f %f\n\n", samples[0], samples[1], samples[2]);
// interval iterator context setup
vkl_range1f ranges[2] = {{10, 20}, {50, 75}};
int num_ranges = 2;
VKLData rangesData =
vklNewData(device, num_ranges, VKL_BOX1F, ranges, VKL_DATA_DEFAULT, 0);
VKLIntervalIteratorContext intervalContext =
vklNewIntervalIteratorContext(sampler);
vklSetInt(intervalContext, "attributeIndex", attributeIndex);
vklSetData(intervalContext, "valueRanges", rangesData);
vklRelease(rangesData);
vklCommit(intervalContext);
// hit iterator context setup
float values[2] = {32, 96};
int num_values = 2;
VKLData valuesData =
vklNewData(device, num_values, VKL_FLOAT, values, VKL_DATA_DEFAULT, 0);
VKLHitIteratorContext hitContext = vklNewHitIteratorContext(sampler);
vklSetInt(hitContext, "attributeIndex", attributeIndex);
vklSetData(hitContext, "values", valuesData);
vklRelease(valuesData);
vklCommit(hitContext);
// ray definition for iterators
vkl_vec3f rayOrigin = {0, 1, 1};
vkl_vec3f rayDirection = {1, 0, 0};
vkl_range1f rayTRange = {0, 200};
printf("\trayOrigin = %f %f %f\n", rayOrigin.x, rayOrigin.y, rayOrigin.z);
printf("\trayDirection = %f %f %f\n",
rayDirection.x,
rayDirection.y,
rayDirection.z);
printf("\trayTRange = %f %f\n", rayTRange.lower, rayTRange.upper);
// interval iteration. This is scoped
{
// Note: buffer will cease to exist at the end of this scope.
#if defined(_MSC_VER)
// MSVC does not support variable length arrays, but provides a
// safer version of alloca.
char *buffer = _malloca(vklGetIntervalIteratorSize(&intervalContext));
#else
char buffer[vklGetIntervalIteratorSize(&intervalContext)];
#endif
VKLIntervalIterator intervalIterator = vklInitIntervalIterator(
&intervalContext, &rayOrigin, &rayDirection, &rayTRange, time, buffer);
printf("\n\tinterval iterator for value ranges {%f %f} {%f %f}\n",
ranges[0].lower,
ranges[0].upper,
ranges[1].lower,
ranges[1].upper);
for (;;) {
VKLInterval interval;
int result = vklIterateInterval(intervalIterator, &interval);
if (!result)
break;
printf(
"\t\ttRange (%f %f)\n\t\tvalueRange (%f %f)\n\t\tnominalDeltaT "
"%f\n\n",
interval.tRange.lower,
interval.tRange.upper,
interval.valueRange.lower,
interval.valueRange.upper,
interval.nominalDeltaT);
}
#if defined(_MSC_VER)
_freea(buffer);
#endif
}
// hit iteration
{
#if defined(_MSC_VER)
// MSVC does not support variable length arrays, but provides a
// safer version of alloca.
char *buffer = _malloca(vklGetHitIteratorSize(&hitContext));
#else
char buffer[vklGetHitIteratorSize(&hitContext)];
#endif
VKLHitIterator hitIterator = vklInitHitIterator(
&hitContext, &rayOrigin, &rayDirection, &rayTRange, time, buffer);
printf("\thit iterator for values %f %f\n", values[0], values[1]);
for (;;) {
VKLHit hit;
int result = vklIterateHit(hitIterator, &hit);
if (!result)
break;
printf("\t\tt %f\n\t\tsample %f\n\t\tepsilon %f\n\n",
hit.t,
hit.sample,
hit.epsilon);
}
#if defined(_MSC_VER)
_freea(buffer);
#endif
}
vklRelease(hitContext);
vklRelease(intervalContext);
vklRelease(sampler);
}
void demoVectorAPI(VKLVolume volume)
{
printf("demo of 4-wide API (8- and 16- follow the same pattern)\n");
VKLSampler sampler = vklNewSampler(volume);
vklCommit(sampler);
// structure-of-array layout
vkl_vvec3f4 coord4;
int valid[4];
for (int i = 0; i < 4; i++) {
coord4.x[i] = i * 3 + 0;
coord4.y[i] = i * 3 + 1;
coord4.z[i] = i * 3 + 2;
valid[i] = -1; // valid mask: 0 = not valid, -1 = valid
}
for (int i = 0; i < 4; i++) {
printf(
"\tcoord[%d] = %f %f %f\n", i, coord4.x[i], coord4.y[i], coord4.z[i]);
}
// sample, gradient (first attribute)
unsigned int attributeIndex = 0;
float time4[4] = {0.f};
float sample4[4];
vkl_vvec3f4 grad4;
vklComputeSample4(valid, &sampler, &coord4, sample4, attributeIndex, time4);
vklComputeGradient4(valid, &sampler, &coord4, &grad4, attributeIndex, time4);
printf("\n\tsampling and gradient computation (first attribute)\n");
for (int i = 0; i < 4; i++) {
printf("\t\tsample[%d] = %f\n", i, sample4[i]);
printf(
"\t\tgrad[%d] = %f %f %f\n", i, grad4.x[i], grad4.y[i], grad4.z[i]);
}
// sample (multiple attributes)
unsigned int M = 3;
unsigned int attributeIndices[] = {0, 1, 2};
float samples[3 * 4];
vklComputeSampleM4(
valid, &sampler, &coord4, samples, M, attributeIndices, time4);
printf("\n\tsampling (multiple attributes)\n");
printf("\t\tsamples = ");
for (unsigned int j = 0; j < M; j++) {
printf("%f %f %f %f\n",
samples[j * 4 + 0],
samples[j * 4 + 1],
samples[j * 4 + 2],
samples[j * 4 + 3]);
printf("\t\t ");
}
printf("\n");
vklRelease(sampler);
}
void demoStreamAPI(VKLVolume volume)
{
printf("demo of stream API\n");
VKLSampler sampler = vklNewSampler(volume);
vklCommit(sampler);
// array-of-structure layout; arbitrary stream lengths are supported
vkl_vec3f coord[5];
for (int i = 0; i < 5; i++) {
coord[i].x = i * 3 + 0;
coord[i].y = i * 3 + 1;
coord[i].z = i * 3 + 2;
}
for (int i = 0; i < 5; i++) {
printf("\tcoord[%d] = %f %f %f\n", i, coord[i].x, coord[i].y, coord[i].z);
}
// sample, gradient (first attribute)
printf("\n\tsampling and gradient computation (first attribute)\n");
unsigned int attributeIndex = 0;
float time[5] = {0.f};
float sample[5];
vkl_vec3f grad[5];
vklComputeSampleN(&sampler, 5, coord, sample, attributeIndex, time);
vklComputeGradientN(&sampler, 5, coord, grad, attributeIndex, time);
for (int i = 0; i < 5; i++) {
printf("\t\tsample[%d] = %f\n", i, sample[i]);
printf("\t\tgrad[%d] = %f %f %f\n", i, grad[i].x, grad[i].y, grad[i].z);
}
// sample (multiple attributes)
unsigned int M = 3;
unsigned int attributeIndices[] = {0, 1, 2};
float samples[3 * 5];
vklComputeSampleMN(&sampler, 5, coord, samples, M, attributeIndices, time);
printf("\n\tsampling (multiple attributes)\n");
printf("\t\tsamples = ");
for (int i = 0; i < 5; i++) {
for (unsigned int j = 0; j < M; j++) {
printf("%f ", samples[i * M + j]);
}
printf("\n\t\t ");
}
printf("\n");
vklRelease(sampler);
}
int main()
{
vklInit();
VKLDevice device = vklNewDevice("cpu");
vklCommitDevice(device);
const int dimensions[] = {128, 128, 128};
const int numVoxels = dimensions[0] * dimensions[1] * dimensions[2];
const int numAttributes = 3;
VKLVolume volume = vklNewVolume(device, "structuredRegular");
vklSetVec3i(
volume, "dimensions", dimensions[0], dimensions[1], dimensions[2]);
vklSetVec3f(volume, "gridOrigin", 0, 0, 0);
vklSetVec3f(volume, "gridSpacing", 1, 1, 1);
float *voxels = malloc(numVoxels * sizeof(float));
if (!voxels) {
printf("failed to allocate voxel memory!\n");
return 1;
}
// volume attribute 0: x-grad
for (int k = 0; k < dimensions[2]; k++)
for (int j = 0; j < dimensions[1]; j++)
for (int i = 0; i < dimensions[0]; i++)
voxels[k * dimensions[0] * dimensions[1] + j * dimensions[2] + i] =
(float)i;
VKLData data0 =
vklNewData(device, numVoxels, VKL_FLOAT, voxels, VKL_DATA_DEFAULT, 0);
// volume attribute 1: y-grad
for (int k = 0; k < dimensions[2]; k++)
for (int j = 0; j < dimensions[1]; j++)
for (int i = 0; i < dimensions[0]; i++)
voxels[k * dimensions[0] * dimensions[1] + j * dimensions[2] + i] =
(float)j;
VKLData data1 =
vklNewData(device, numVoxels, VKL_FLOAT, voxels, VKL_DATA_DEFAULT, 0);
// volume attribute 2: z-grad
for (int k = 0; k < dimensions[2]; k++)
for (int j = 0; j < dimensions[1]; j++)
for (int i = 0; i < dimensions[0]; i++)
voxels[k * dimensions[0] * dimensions[1] + j * dimensions[2] + i] =
(float)k;
VKLData data2 =
vklNewData(device, numVoxels, VKL_FLOAT, voxels, VKL_DATA_DEFAULT, 0);
VKLData attributes[] = {data0, data1, data2};
VKLData attributesData = vklNewData(
device, numAttributes, VKL_DATA, attributes, VKL_DATA_DEFAULT, 0);
vklRelease(data0);
vklRelease(data1);
vklRelease(data2);
vklSetData(volume, "data", attributesData);
vklRelease(attributesData);
vklCommit(volume);
demoScalarAPI(device, volume);
demoVectorAPI(volume);
demoStreamAPI(volume);
vklRelease(volume);
vklReleaseDevice(device);
free(voxels);
printf("complete.\n");
#if defined(_MSC_VER)
// On Windows, sleep for a few seconds so the terminal window doesn't close
// immediately.
Sleep(3000);
#endif
return 0;
}Precompiled Open VKL packages for Linux, macOS, and Windows are available via Open VKL GitHub releases. Packages with “sycl” in the name include support for both x86 CPUs and Intel® GPUs, while the other packages only include x86 CPU support. Open VKL can be compiled from source (needed for ARM platforms) following the compilation instructions below.
To run Open VKL on Intel® GPUs you will need to first have drivers installed on your system.
Install the latest GPGPU drivers for your Intel® GPU from: https://dgpu-docs.intel.com/. Follow the driver installation instructions for your graphics card.
Install the latest GPGPU drivers for your Intel® GPU from: https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html. Follow the driver installation instructions for your graphics card.
The latest Open VKL sources are always available at the Open VKL GitHub
repository. The default master
branch should always point to the latest tested bugfix release.
Open VKL currently supports Linux, Mac OS X, and Windows on CPU; and Linux and Windows on Intel® GPUs. Before you can build Open VKL you need the following prerequisites:
-
You can clone the latest Open VKL sources via:
git clone https://github.com/openvkl/openvkl.git -
To build Open VKL you need CMake, any form of C++11 compiler (we recommend using GCC, but also support Clang and MSVC), and standard Linux development tools. To build the examples, you should also have some version of OpenGL.
-
Additionally you require a copy of the Intel® Implicit SPMD Program Compiler (Intel® ISPC), version 1.18.0 or later. Please obtain a release of ISPC from the ISPC downloads page.
-
Open VKL depends on the Intel RenderKit common library, rkcommon. rkcommon is available at the rkcommon GitHub repository.
-
Open VKL depends on Embree, which is available at the Embree GitHub repository.
Depending on your Linux distribution you can install these dependencies
using yum or apt-get. Some of these packages might already be
installed or might have slightly different names.
In addition, if you would like to build Open VKL for Intel® GPUs on Linux or Windows, you need the following additional prerequisites:
-
CMake version 3.25.3 or higher
-
Download the oneAPI DPC++ Compiler 2023-10-26; please note this specific version has been validated and used in our releases.
-
On Linux, the compiler can be simply extracted, then set up using the following commands in bash (where
path_to_dpcpp_compilershould point to the root directory of unpacked package):export SYCL_BUNDLE_ROOT=path_to_dpcpp_compiler export PATH=$SYCL_BUNDLE_ROOT/bin:$PATH export CPATH=$SYCL_BUNDLE_ROOT/include:$CPATH export LIBRARY_PATH=$SYCL_BUNDLE_ROOT/lib:$LIBRARY_PATH export LD_LIBRARY_PATH=$SYCL_BUNDLE_ROOT/lib:$LD_LIBRARY_PATH export LD_LIBRARY_PATH=$SYCL_BUNDLE_ROOT/linux/lib/x64:$LD_LIBRARY_PATH -
On Windows, you will also need an installed version of Visual Studio that supports the C++17 standard, e.g. Visual Studio 2019. Then, download and unpack the DPC++ compiler package and open the “x64 Native Tools Command Prompt” of Visual Studio. Execute the following lines to properly configure the environment to use the oneAPI DPC++ compiler (where
path_to_dpcpp_compilershould point to the root directory of unpacked package):set "DPCPP_DIR=path_to_dpcpp_compiler" set "PATH=%DPCPP_DIR%\bin;%PATH%" set "PATH=%DPCPP_DIR%\lib;%PATH%" set "CPATH=%DPCPP_DIR%\include;%CPATH%" set "INCLUDE=%DPCPP_DIR%\include;%INCLUDE%" set "LIB=%DPCPP_DIR%\lib;%LIB%"
-
For convenience, Open VKL provides a CMake Superbuild script which will pull down Open VKL’s dependencies and build Open VKL itself. The result is an install directory, with each dependency in its own directory.
Run with:
mkdir build
cd build
cmake [<VKL_ROOT>/superbuild]
cmake --build .If you wish to enable GPU support, additional flags must be passed to the superbuild. On Linux:
```
export CC=clang
export CXX=clang++
cmake -D OPENVKL_EXTRA_OPTIONS="-DOPENVKL_ENABLE_DEVICE_GPU=ON" \
[<VKL_ROOT>/superbuild]
```
And on Windows:
```
cmake -L -G Ninja \
-D CMAKE_CXX_COMPILER=clang-cl -D CMAKE_C_COMPILER=clang-cl \
-D OPENVKL_EXTRA_OPTIONS="-DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DOPENVKL_ENABLE_DEVICE_GPU=ON" \
[<VKL_ROOT>/superbuild]
```
The resulting install directory (or the one set with
CMAKE_INSTALL_PREFIX) will have everything in it, with one
subdirectory per dependency.
CMake options to note (all have sensible defaults):
CMAKE_INSTALL_PREFIXwill be the root directory where everything gets installed.BUILD_JOBSsets the number given tomake -jfor parallel builds.INSTALL_IN_SEPARATE_DIRECTORIEStoggles installation of all libraries in separate or the same directory.BUILD_TBB_FROM_SOURCEspecifies whether TBB should be built from source or the releases on Gitub should be used. This must be ON when compiling for ARM.OPENVKL_ENABLE_DEVICE_GPUspecifies if GPU support should be enabled. Note this defaults toOFF.- For the full set of options, run
ccmake [<VKL_ROOT>/superbuild].
Assuming the above prerequisites are all fulfilled, building Open VKL through CMake is easy:
-
Create a build directory, and go into it
mkdir openvkl/build cd openvkl/build(We do recommend having separate build directories for different configurations such as release, debug, etc.).
-
The compiler CMake will use will default to whatever the
CCandCXXenvironment variables point to. Should you want to specify a different compiler, run cmake manually while specifying the desired compiler. The default compiler on most linux machines isgcc, but it can be pointed toclanginstead by executing the following:cmake -DCMAKE_CXX_COMPILER=clang++ -DCMAKE_C_COMPILER=clang ..CMake will now use Clang instead of GCC. If you are ok with using the default compiler on your system, then simply skip this step. Note that the compiler variables cannot be changed after the first
cmakeorccmakerun. -
Open the CMake configuration dialog
ccmake .. -
Make sure to properly set build mode and enable the components you need, etc.; then type ’c’onfigure and ’g’enerate. When back on the command prompt, build it using
make -
You should now have
libopenvkl.soas well as the tutorial / example applications.
This page gives a brief (and incomplete) list of other projects that make use of Open VKL, as well as a set of related links to other projects and related information.
If you have a project that makes use of Open VKL and would like this to be listed here, please let us know.
- Intel® OSPRay, a ray tracing based rendering engine for high-fidelity visualization
-
The Intel® Embree Ray Tracing Kernel Framework