[Project page] [Arxiv paper] [Dataset]

The official PyTorch implementation of our ACM Multimedia 2020 paper. With our proposed framework, we can stylized the given image with another condition music piece.
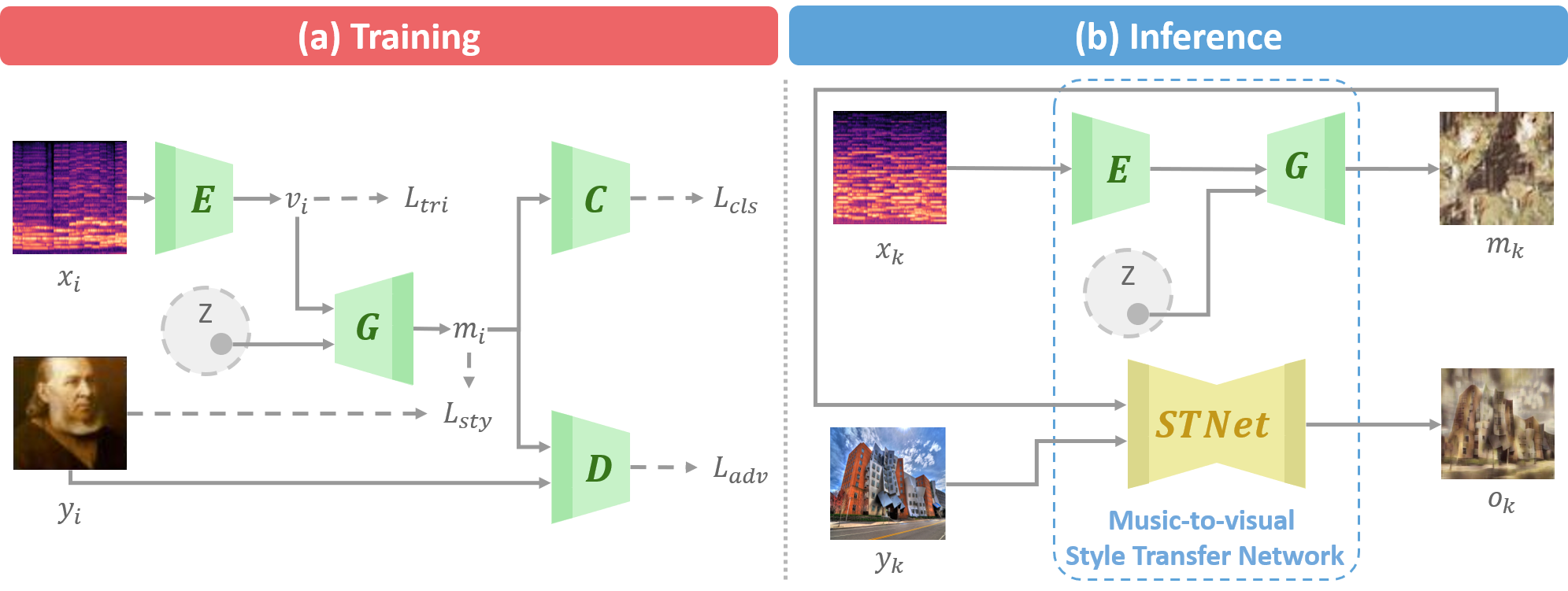
Music-to-visual style transfer is a challenging yet important cross-modal learning problem in the practice of creativity. Its major difference from the traditional image style transfer problem is that the style information is provided by music rather than images. Assuming that musical features can be properly mapped to visual contents through semantic links between the two domains, we solve the music-to-visual style transfer problem in two steps: music visualization and style transfer. The music visualization network utilizes an encoder-generator architecture with a conditional generative adversarial network to generate image-based music representations from music data. This network is integrated with an image style transfer method to accomplish the style transfer process. Experiments are conducted on WikiArt-IMSLP, a newly compiled dataset including Western music recordings and paintings listed by decades. By utilizing such a label to learn the semantic connection between paintings and music, we demonstrate that the proposed framework can generate diverse image style representations from a music piece, and these representations can unveil certain art forms of the same era. Subjective testing results also emphasize the role of the era label in improving the perceptual quality on the compatibility between music and visual content.
Please cite our paper if you think our research or dataset for your research. * indicates equal contributions
Cheng-Che Lee*, Wan-Yi Lin*, Yen-Ting Shih, Pei-Yi Patricia Kuo, and Li Su, "Crossing You in Style: Cross-modal Style Transfer from Music to Visual Arts", in ACM International Conference on Multimedia, 2020.
@inproceedings{lee2020crossing,
title={Crossing You in Style: Cross-modal Style Transfer from Music to Visual Arts},
author={Lee, Cheng-Che and Lin, Wan-Yi and Shih, Yen-Ting and Kuo, Pei-Yi and Su, Li},
booktitle={Proceedings of the 28th ACM International Conference on Multimedia},
pages={3219--3227},
year={2020}
}
- torch 0.4.1
- torchvision 0.2.1
- librosa 0.7.1
- python 3.5.2
- cupy (for linear style transfer)
- pynvrtc (for linear style transfer)
- Download the pretrained model; place the model in
./Source. - Place the target
.wavfile to./Source; - Generate
./Source/clips.json, which contains:[ { "third": <Start reading at this time> "name": <The name of the audio> "seg_idx": <The unique index of this segment. The music style representation of this segment will be <seg_idx>.jpg> "path": <The path to the audio> }, {...}, ...c ] bash evaluate.sh <base> <count>
- Parameters:
base: Integer. Music style representations will be inferenced for<count>times, and results will be saved toResults/<wav name>/Style_sample<base+count>count: Integer. Music representations will be inferenced for<count>times, and results will be saved toResults/<wav name>/Style_sample<base+count>
- Output:
Results/<wav name>/Style_sample<base+count>
Example
> Folder structure:
Source/Spring.wav
Source/last2.pth
Source/clips.json
// The content of Source/clips.json
[
{
"third": 2.14,
"name": "Spring",
"seg_idx": 1,
"path": ./Source/spring.wav
},
{
"third": 5.72,
"name": "Spring",
"seg_idx": 2,
"path": ./Source/spring.wav
},
...
]
> bash evaluate.sh 0 2
> Output
Results/Spring/Style_sample00
Results/Spring/Style_sample01
- We use
ESRGANto raise the resolution of the music style representation. Clone the repository and follow the instruction to download the pretrained model. - Download the modified
test.pyand replace the original one.
- Clone the repository and follow the instruction to download the pretrained model and compile the pytorch_spn repository.
- Download the modified
TestPhotoReal.pyand replace the original one. - Download the modified
LoaderPhotoReal.pyand replace the original one located inlibs
python batch_paint.py --content_image <path1> --style_images <path2>
- Parameters:
--content_image: The path of the content image.--style_images: The path to the folder where the music style representations stay.
- Output:
<image name>/Content: The content image.<image name>/LR: Music representations in low resolution.<image name>/HR: Music representations in high resolution.<image name>/Result: The result of phto-realistic style transfer.<image name>/filtered: Copies of<image name>/Result/*_filtered.jpg.<image name>/smooth: Copies of<image name>/Result/*_smooth.jpg.<image name>/transfer: Copies of<image name>/Result/*_transfer.jpg.
Example
> Folder structure:
./Source/
./ESRGAN/
./LinearStyleTransfer/
./Results/
./content.jpg
> python batch_paint.py --content_image content.jpg --style_images Results/Spring/Style_sample00
> Output
content/Content/
content/LR/
content/HR/
content/LR/
content/Result/
content/filtered/
content/smooth/
content/transfer/