本实验基于 Gym/CliffWalking-v0 实现
该环境是一个 4x12 的网格图,其中 [3,1..11] 是悬崖。一辆汽车从 S 出发,到达 G 则结束。其中,每移动一步的 Reward 为 -1,而如果汽车开到悬崖则回到 S 并获得 -100 的 Reward。环境示意图如下:
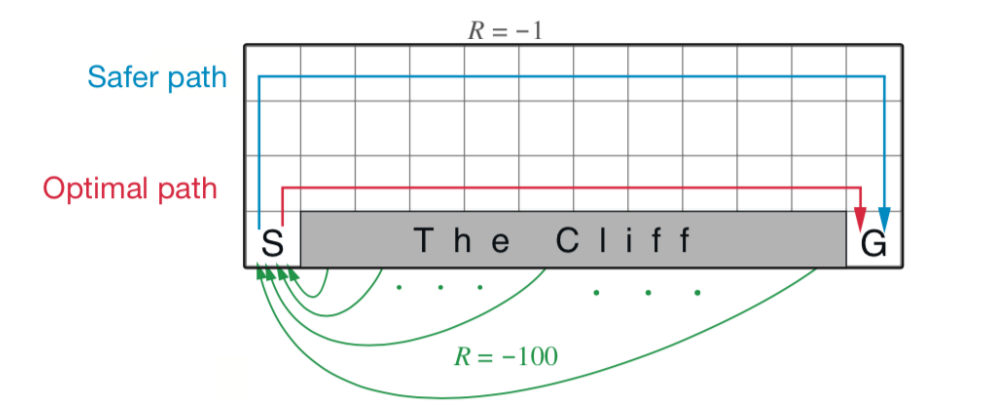
目标是汽车不掉下悬崖的情况下,从 S 出发到达 G。而此时有两条路线,一条是如上图所示的 Optimal Path,这条路是所有路线中最短的,但是更容易掉下悬崖;另一条是 Safer Path,顾名思义,这条路比 Optimal Path 更加安全,因为其距离悬崖更远,但是路线也更长。
本实验通过 Q-Learning 和 SARSA 两种算法对 Agent 进行训练,得出结果并进行比较。
动作如下:
- 0: UP
- 1: RIGHT
- 2: DOWN
- 3: LEFT
Q-Learning 和 SARSA 都会通过若干次 episode 维护出一张 Q-Table,最后进行测试时根据 Q-Table 贪心地进行策略选择。Q-Table 的维护会基于当前 Observation 对应的 Q-Table 进行策略选择。为了平衡与探索以及策略改进,在选取策略时需要基于
- 所有 action 的概率非零;
- 以
$1-\epsilon$ 选择当前局部最优的动作; - 剩下的
$\epsilon$ 均分给所有动作。
该部分代码如下:
def epsilon_greedy(obs, epsilon=0.1):
"""
根据 obs 选择 action
有 1-epsilon+(epsilon/|actions|) 的概率选择价值最大的action,其他的action则均分剩下的概率
"""
if np.random.uniform(0, 1) < (1.0 - epsilon):
now_Q = Q[obs, :]
max_Q = np.max(now_Q)
candidate_action = np.where(now_Q == max_Q)[0]
next_action = np.random.choice(candidate_action)
else:
next_action = np.random.choice(n_action)
return next_action(完整代码见 qlearning.py)
该算法是 off-policy 的,其采样基于 Bellman 最优方程,保证每个走法都有机会尝试,并且保证目前看来最好的走法应该得到更多的尝试。更新 Q-Table 的代码如下:
def update_Q(obs, act, now_reward, next_obs, is_done):
"""
通过这一次转移更新Q表
:param obs: 上一状态
:param act: 先前状态转移到当前状态采取的action
:param now_reward: 该状态对应的action下对应的reward
:param is_done: 该episode是否结束
:param next_obs: 转移到的下一状态
:return: void
"""
predict = Q[obs, act]
if is_done:
target = now_reward
else:
target = now_reward + gamma * np.max(Q[next_obs, :])
Q[obs, act] += learning_rate * (target - predict)实验设置的参数为:
learning_rate = 0.9 # 学习率
gamma = 0.9
max_episode_count = 200 # 训练使用的 episode 数
epsilon = 0.1 # epsilon-greedy 中的 epsilon
Q = np.zeros((n_observation, n_action)) # Q-Table 初始化为全0经过多次测试都得到相同的训练结果,具体见 result_QLearning.txt。
最后的路线为 Optimal Path,即沿着悬崖边缘的一排格子行走。
Action: 0 1 1 1 1 1 1 1 1 1 1 1 2
Total Reward: -13
Total Step: 13
(完整代码见 sarsa.py)
该算法是 on-policy 的,其采样基于 Bellman 期望方程,贪心改进是基本诉求, 但也不得不兼顾探索。更新 Q-Table 的代码如下:
def update_Q(obs, act, now_reward, next_obs, next_action, is_done):
"""
通过这一次转移更新Q表
:param obs: 上一状态
:param act: 先前状态转移到当前状态采取的action
:param now_reward: 该状态对应的action下对应的reward
:param is_done: 该episode是否结束
:param next_obs: 转移到的下一状态
:param next_action: 下一动作
:return: void
"""
predict = Q[obs, act]
if is_done:
target = now_reward
else:
target = now_reward + gamma * Q[next_obs, next_action]
Q[obs, act] += learning_rate * (target - predict)训练部分代码如下:
def train_running():
"""
进行训练,训练得出一张 Q-Table
:return:void
"""
observation = env.reset() # 创建新的 episode
train_total_reward = 0
train_total_step = 0
action = epsilon_greedy(observation, epsilon=0.1)
while True:
next_observation, reward, done, _ = env.step(action)
next_action = epsilon_greedy(next_observation, epsilon=0.1)
update_Q(observation, action, reward, next_observation, next_action, done)
observation = next_observation
action = next_action
train_total_reward += reward
train_total_step += 1
if done:
break
return train_total_reward, train_total_step最后测试结果见 result_SARSA.txt。值得一提的是,这次的测试效果不相同,下面是部分测试结果:
Actions: [0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 2, 2]
Total Reward: -17
Total Step: 17Actions: [0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2]
Total Reward: -15
Total Step: 15Actions: [0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2]
Total Reward: -17
Total Step: 17Actions: [0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2]
Total Reward: -17
Total Step: 17测试结果的 Reward 都比用 Q-Learning 要差,但是路线上基本都保证更加安全(即远离悬崖)
真实环境中一般都会选择远离悬崖,这里尝试修改 Reward 为如下:
- 汽车走到悬崖,$\text{reward}=-100$ 并回到 S;
- 汽车转移之后的格子,设其坐标为
$(x,y)$ ,那么$\text{reward}=-1-x$ - 该意义为:汽车越远离悬崖,reward 越高;反之,reward 越低
此时修改超参数:
-
Q-Learning 超参数调整如下:
learning_rate = 0.9 # 学习率 gamma = 0.9 max_episode_count = 200 # 训练使用的 episode 数 epsilon = 0.1
-
SARSA 超参数调整如下:
learning_rate = 0.3 # 学习率 gamma = 1.0 max_episode_count = 500 # 训练使用的 episode 数 epsilon = 0.1
最后训练结果如下:
Actions: [0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2]
Total Reward: -26
Total Step: 17多次测试之后结果保持一致,这条路线也就是 Safer Path。
具体结果参考 result_fixed_reward_SARSA.txt 和 result_fixed_reward_QLearning.txt