| Title & Authors | Introduction | Links |
|---|---|---|
| Efficient Hybrid Inference for LLMs: Reward-Based Token Modelling with Selective Cloud Assistance Adarsh MS, Jithin VG, Ditto PS @Bud Ecosystem |
 |
Paper |
 Rethinking Optimization and Architecture for Tiny Language Models Yehui Tang, Fangcheng Liu, Yunsheng Ni, Yuchuan Tian, Zheyuan Bai, Yi-Qi Hu, Sichao Liu, Shangling Jui, Kai Han, Yunhe Wang |
 |
Github Paper |
| Tandem Transformers for Inference Efficient LLMs Aishwarya P S, Pranav Ajit Nair, Yashas Samaga, Toby Boyd, Sanjiv Kumar, Prateek Jain, Praneeth Netrapalli |
 |
Paper |
| Scaling Efficient LLMs B.N. Kausik |
 |
Paper |
| MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra |
 |
Paper |
| Think Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding Benjamin Bergner, Andrii Skliar, Amelie Royer, Tijmen Blankevoort, Yuki Asano, Babak Ehteshami Bejnordi |
 |
Paper |
 MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan |
 |
Github Paper Model |
| Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models Soham De, Samuel L. Smith, Anushan Fernando, Aleksandar Botev, George Cristian-Muraru, Albert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, Srivatsan Srinivasan, Guillaume Desjardins, Arnaud Doucet, David Budden, Yee Whye Teh, Razvan Pascanu, Nando De Freitas, Caglar Gulcehre |
 |
Paper |
 DiJiang: Efficient Large Language Models through Compact Kernelization Hanting Chen, Zhicheng Liu, Xutao Wang, Yuchuan Tian, Yunhe Wang |
 |
Github Paper |
 Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, Chunting Zhou |
 |
Github Paper |
 Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs Woomin Song, Seunghyuk Oh, Sangwoo Mo, Jaehyung Kim, Sukmin Yun, Jung-Woo Ha, Jinwoo Shin |
 |
Github Paper |
Block Transformer: Global-to-Local Language Modeling for Fast Inference Namgyu Ho, Sangmin Bae, Taehyeon Kim, Hyunjik Jo, Yireun Kim, Tal Schuster, Adam Fisch, James Thorne, Se-Young Yun |
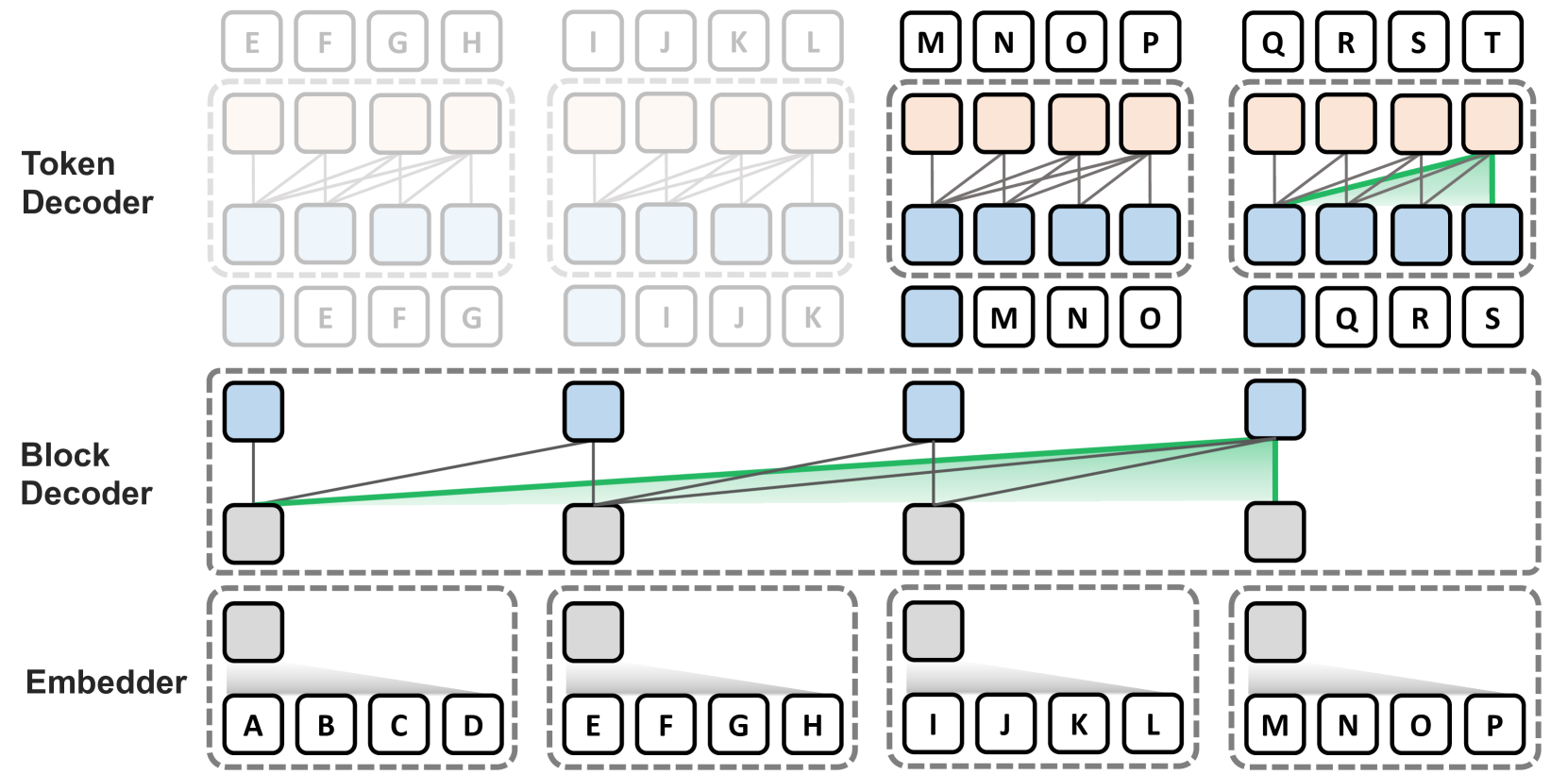 |
Github Paper |
 Beyond KV Caching: Shared Attention for Efficient LLMs Bingli Liao, Danilo Vasconcellos Vargas |
 |
Github Paper |
 Efficient LLM Training and Serving with Heterogeneous Context Sharding among Attention Heads Xihui Lin, Yunan Zhang, Suyu Ge, Barun Patra, Vishrav Chaudhary, Xia Song |
 |
Github Paper |
| SentenceVAE: Enable Next-sentence Prediction for Large Language Models with Faster Speed, Higher Accuracy and Longer Context Hongjun An, Yifan Chen, Zhe Sun, Xuelong Li |
 |
Paper |
| Rodimus*: Breaking the Accuracy-Efficiency Trade-Off with Efficient Attentions Zhihao He, Hang Yu, Zi Gong, Shizhan Liu, Jianguo Li, Weiyao Lin |
 |
Paper |
 Basis Sharing: Cross-Layer Parameter Sharing for Large Language Model Compression Jingcun Wang, Yu-Guang Chen, Ing-Chao Lin, Bing Li, Grace Li Zhang |
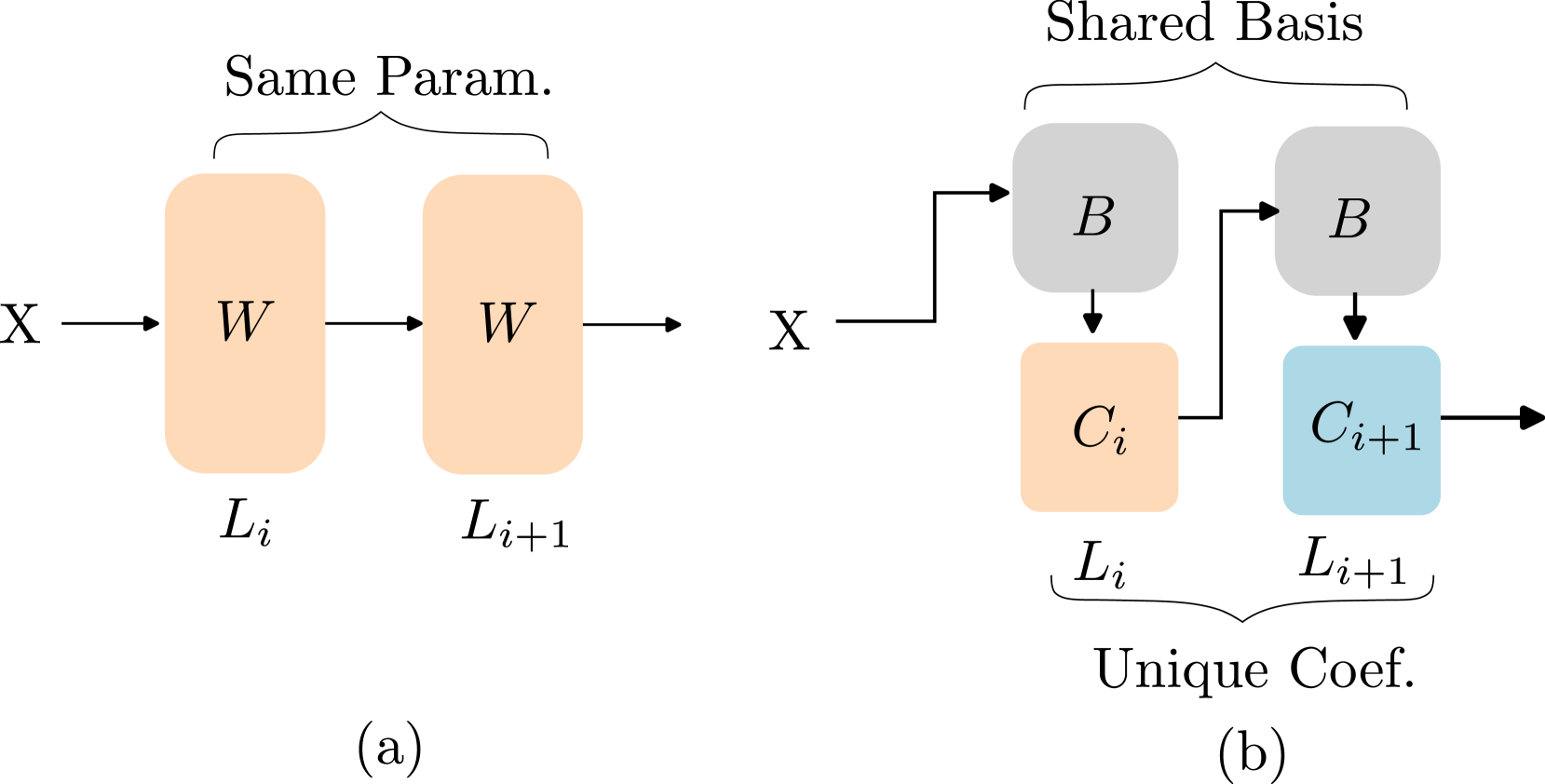 |
Github Paper |
 SeerAttention: Learning Intrinsic Sparse Attention in Your LLMs Yizhao Gao, Zhichen Zeng, Dayou Du, Shijie Cao, Hayden Kwok-Hay So, Ting Cao, Fan Yang, Mao Yang |
 |
Github Paper |