A curated list for Efficient Large Language Models
- Network Pruning / Sparsity
- Knowledge Distillation
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System
- Tuning
- Survey
- Leaderboard
Please check out all the papers by selecting the sub-area you're interested in. On this main page, only papers released in the past 90 days are shown.
- May 29, 2024: We've had this awesome list for a year now 🥰!
- Sep 6, 2023: Add a new subdirectory project/ to organize efficient LLM projects.
- July 11, 2023: A new subdirectory efficient_plm/ is created to house papers that are applicable to PLMs.
If you'd like to include your paper, or need to update any details such as conference information or code URLs, please feel free to submit a pull request. You can generate the required markdown format for each paper by filling in the information in generate_item.py and execute python generate_item.py. We warmly appreciate your contributions to this list. Alternatively, you can email me with the links to your paper and code, and I would add your paper to the list at my earliest convenience.
For each topic, we have curated a list of recommended papers that have garnered a lot of GitHub stars or citations.
Paper from July 13, 2024 - Now (see Full List from May 22, 2023 here)
- Network Pruning / Sparsity
- Knowledge Distillation
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System
- Tuning
- Survey
































































































































































| Title & Authors | Introduction | Links |
|---|---|---|
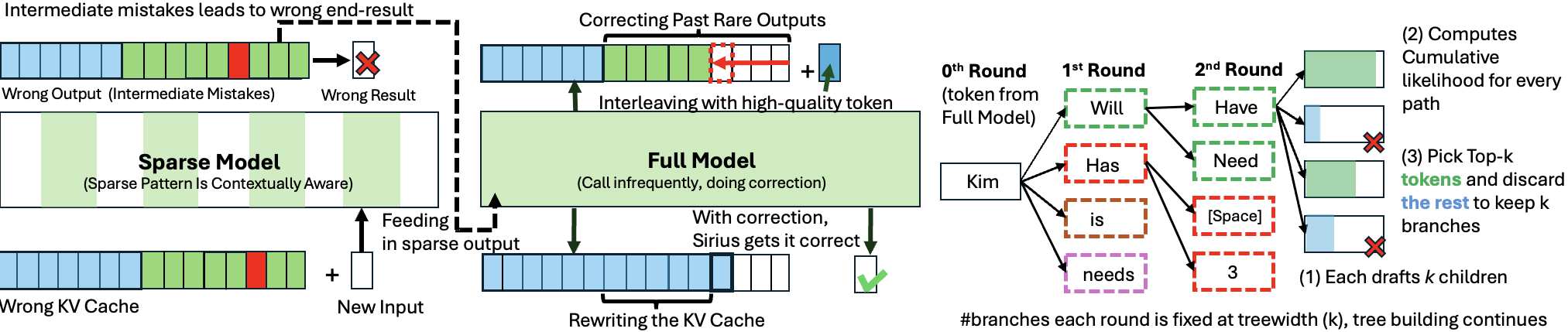
 ⭐ Fast Inference of Mixture-of-Experts Language Models with Offloading Artyom Eliseev, Denis Mazur |
 |
Github Paper |
| EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference Yulei Qian, Fengcun Li, Xiangyang Ji, Xiaoyu Zhao, Jianchao Tan, Kefeng Zhang, Xunliang Cai |
Paper | |
 MC-MoE: Mixture Compressor for Mixture-of-Experts LLMs Gains More Wei Huang, Yue Liao, Jianhui Liu, Ruifei He, Haoru Tan, Shiming Zhang, Hongsheng Li, Si Liu, Xiaojuan Qi |
 |
Github Paper |
| Diversifying the Expert Knowledge for Task-Agnostic Pruning in Sparse Mixture-of-Experts Zeliang Zhang, Xiaodong Liu, Hao Cheng, Chenliang Xu, Jianfeng Gao |
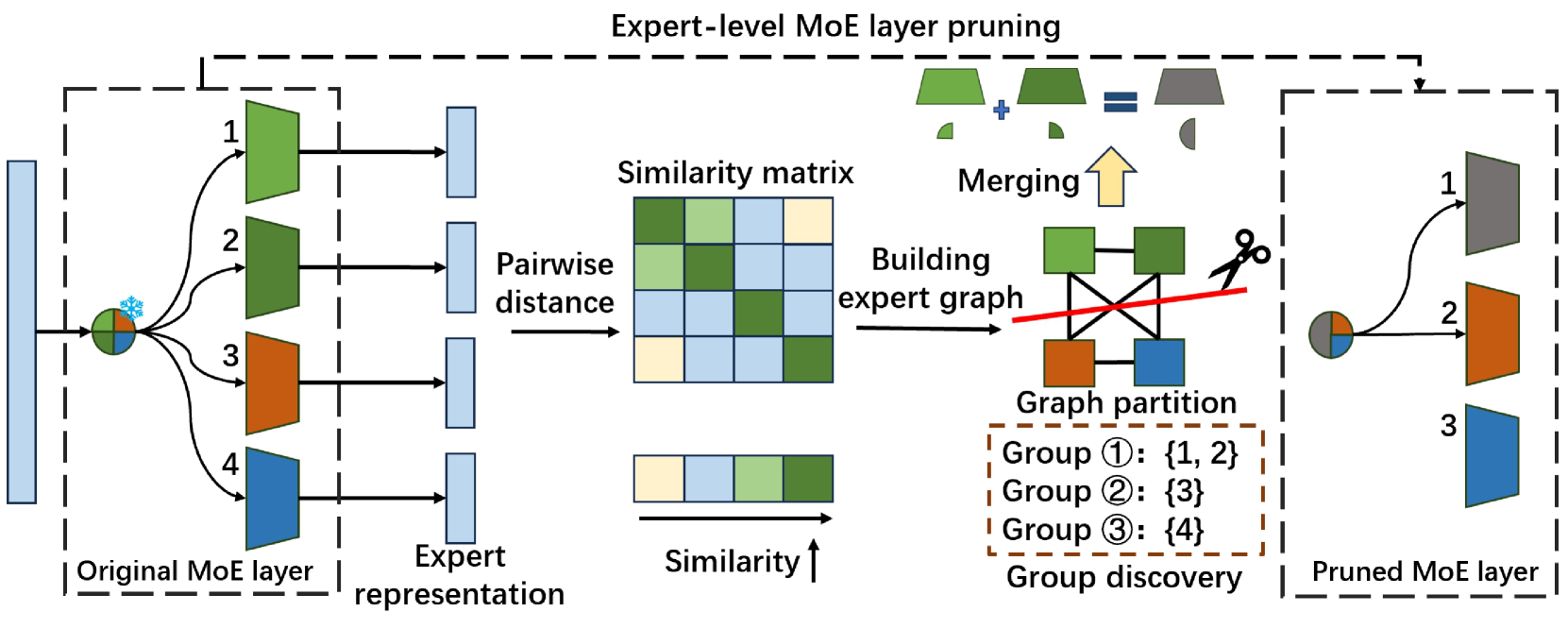 |
Paper |
























































| Title & Authors | Introduction | Links |
|---|---|---|
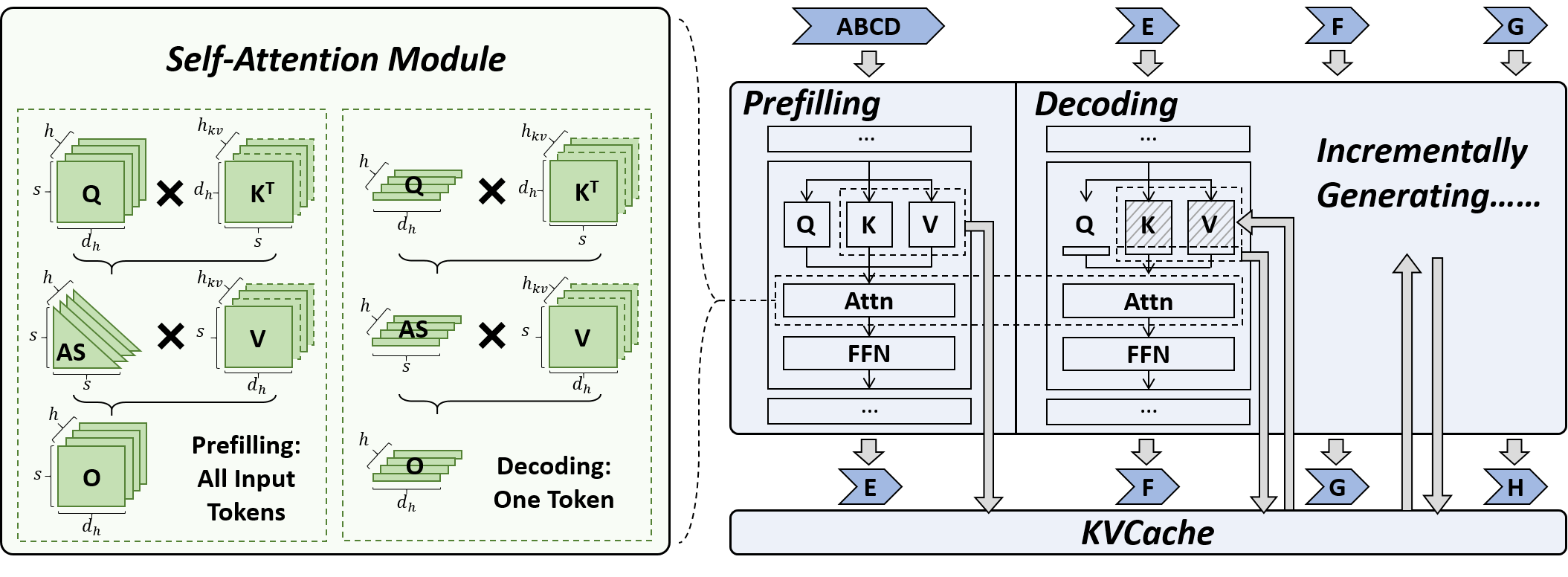
ESPACE: Dimensionality Reduction of Activations for Model Compression Charbel Sakr, Brucek Khailany |
 |
Paper |
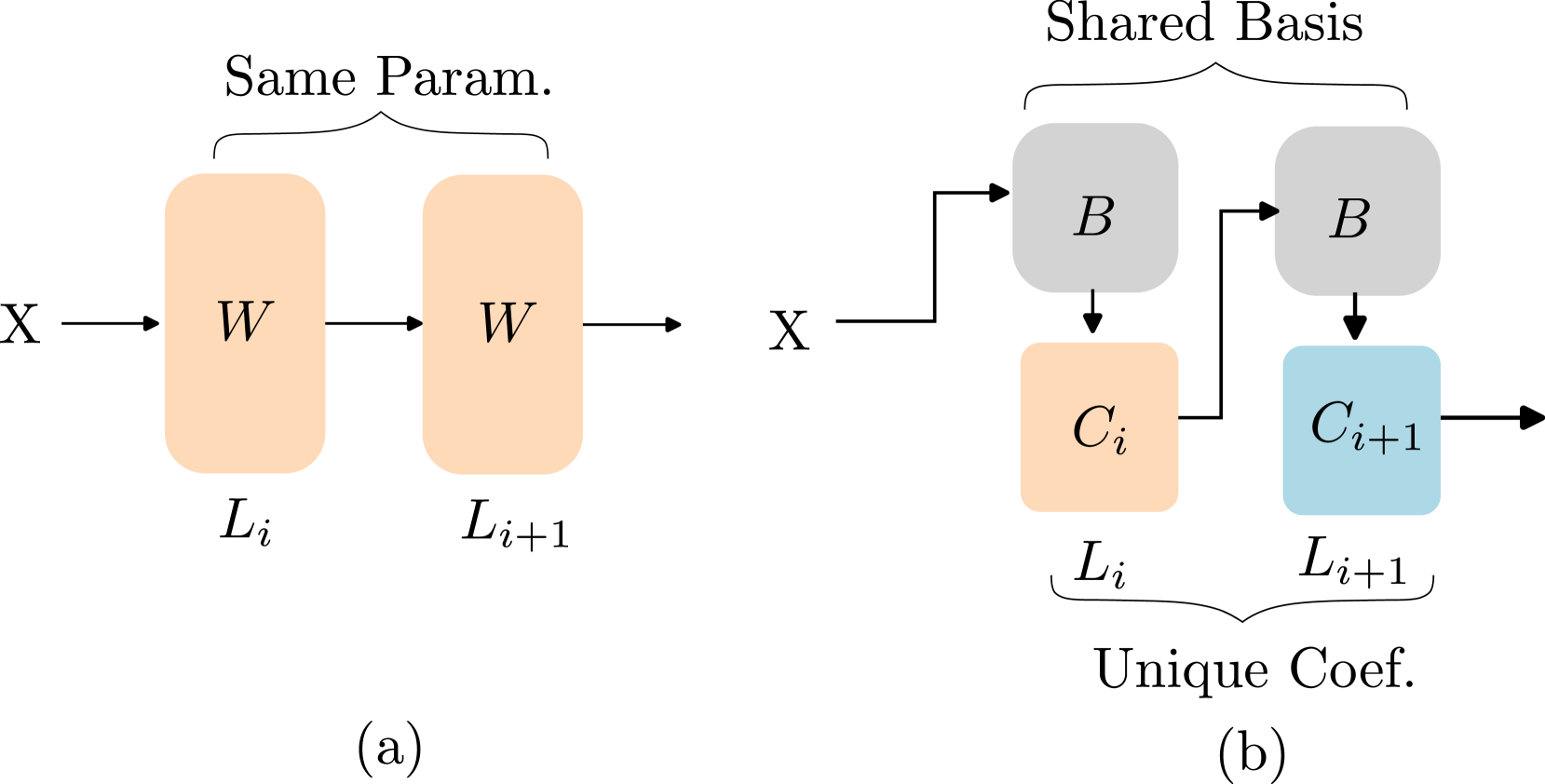
| MoDeGPT: Modular Decomposition for Large Language Model Compression Chi-Heng Lin, Shangqian Gao, James Seale Smith, Abhishek Patel, Shikhar Tuli, Yilin Shen, Hongxia Jin, Yen-Chang Hsu |
 |
Paper |


























| Title & Authors | Introduction | Links |
|---|---|---|
 Prompt Compression for Large Language Models: A Survey Zongqian Li, Yinhong Liu, Yixuan Su, Nigel Collier |
 |
Github Paper |
| Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective Jinhao Li, Jiaming Xu, Shan Huang, Yonghua Chen, Wen Li, Jun Liu, Yaoxiu Lian, Jiayi Pan, Li Ding, Hao Zhou, Guohao Dai |
 |
Paper |
| A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms Ruihao Gong, Yifu Ding, Zining Wang, Chengtao Lv, Xingyu Zheng, Jinyang Du, Haotong Qin, Jinyang Guo, Michele Magno, Xianglong Liu |
 |
Paper |
 Contextual Compression in Retrieval-Augmented Generation for Large Language Models: A Survey Sourav Verma |
 |
Github Paper |
| Art and Science of Quantizing Large-Scale Models: A Comprehensive Overview Yanshu Wang, Tong Yang, Xiyan Liang, Guoan Wang, Hanning Lu, Xu Zhe, Yaoming Li, Li Weitao |
Paper | |
| Hardware Acceleration of LLMs: A comprehensive survey and comparison Nikoletta Koilia, Christoforos Kachris |
Paper | |
| A Survey on Symbolic Knowledge Distillation of Large Language Models Kamal Acharya, Alvaro Velasquez, Houbing Herbert Song |
 |
Paper |
Inference Optimization of Foundation Models on AI Accelerators Youngsuk Park, Kailash Budhathoki, Liangfu Chen, Jonas Kübler, Jiaji Huang, Matthäus Kleindessner, Jun Huan, Volkan Cevher, Yida Wang, George Karypis |
Paper |